- The paper introduces Xetrieval, a two-stage framework that combines reasoning internalization with a sparse autoencoder to decompose dense retrieval embeddings into interpretable features.
- It demonstrates that injecting chain-of-thought signals into embeddings improves sparse feature coherence and retains retrieval performance across diverse benchmarks.
- Empirical results confirm that the approach offers efficient, scalable, and locally causal explanations, enabling task-level feature interventions and robust debugging of dense retrievers.
Mechanistically Explaining Dense Retrieval with Xetrieval
Introduction
Dense retrieval (DR) has become essential in information retrieval (IR) through the widespread adoption of neural embedding-based methods. Despite major advances in retrieval accuracy and robustness, the opacity of embedding-based similarity computations has become a key obstacle for transparency, accountability, and error analysis. Traditional explanation protocols typically focus on post-hoc lexical evidence or produce attributions to high-dimensional representations, failing to answer which latent features drive retrieval. "Xetrieval: Mechanistically Explaining Dense Retrieval" (2605.29507) addresses this limitation by introducing Xetrieval, an embedding-level framework for decomposing dense retrieval decisions into sparse, interpretable features that mechanistically explain query-document relevance.
Figure 1: Dense retrieval offers limited insight into the rationales underlying individual retrieval results.
The Xetrieval Framework
The Xetrieval framework consists of two core architectural components: a reasoning internalizer and a mechanistic explainer, both targeting embedding-level representations. The reasoning internalizer injects LLM-style Chain-of-Thought (CoT) reasoning signals directly into sentence embeddings via a lightweight, single-forward MLP pathway. This leverages prompt-constructed LLM-generated summaries, intent clarifications, and QA pairs, training a set of mapping networks to project raw embeddings into reasoning-enriched representations. This method fundamentally avoids the high compute cost associated with autoregressive CoT generation at inference.
The mechanistic explainer leverages a sparse autoencoder (SAE), with a direct focus on TopK-SAE due to its favorable trade-off between reconstruction error, semantic mono-dimensionality, and retention of retrieval performance. This module is trained on both raw and reasoned embeddings, allowing the explainer to produce sparse codes, each aligned to a latent direction. Crucially, each activated feature can be mapped to a human-readable semantic description using large-scale semi-automated LLM summarization.
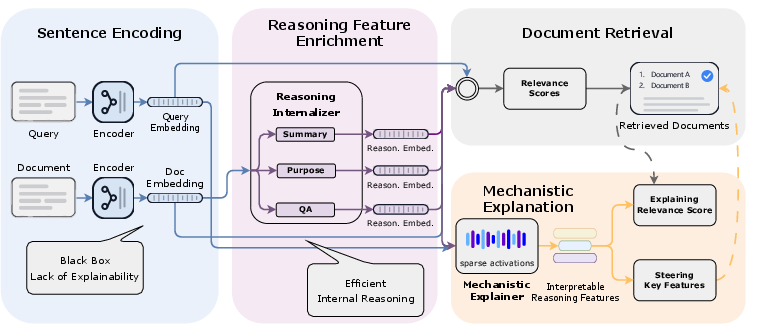
Figure 2: Overview of the Xetrieval framework. The reasoning internalizer injects reasoning-oriented signals into sentence embeddings, while the mechanistic explainer decomposes these enriched embeddings into sparse, human-readable features for feature-level analysis and intervention on retrieval behavior.
Sparse Feature Discovery and Quantitative Evaluation
A major result in the study is the empirical demonstration of trade-offs in sparse decomposition. By varying the allowed number of active features (L0), the authors show that increasing sparsity improves semantic purity but degrades faithfulness to the original embedding, while looser sparsity thresholds improve retention but dilute feature coherence. Across a variety of autoencoder baselines, the TopK variant is shown to achieve low MSE, high mono-semanticity (as measured by automated intruder detection protocols), and minimal retrieval accuracy drop at moderate sparsity.
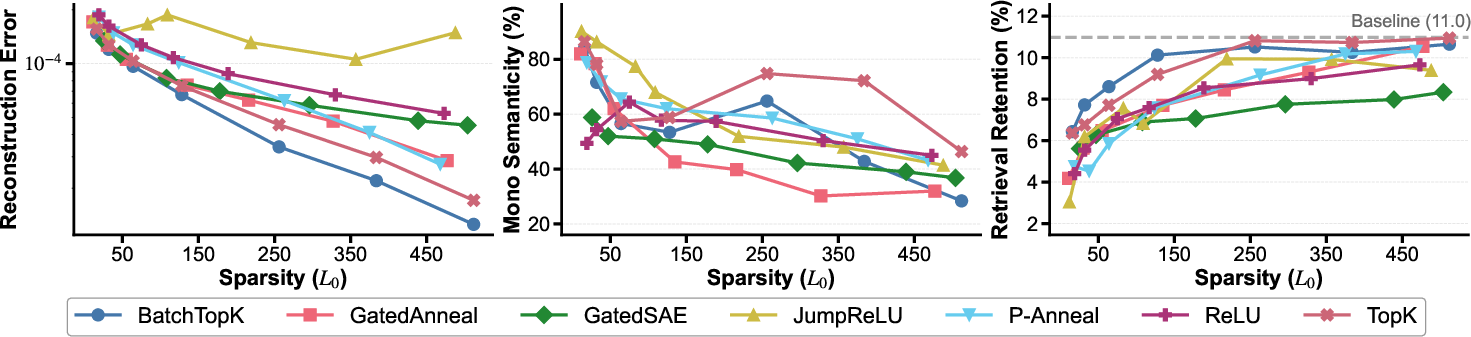
Figure 3: SAEs comparison across sparsity levels (L0), measured by reconstruction error, mono-semanticity, and retrieval retention.
Xetrieval’s internalized reasoning embeddings are more amenable to sparse decomposition—activating more features and yielding lower reconstruction error—relative to raw embeddings (Figure 4). This produces more distinctive, semantically coherent sparse features on downstream interpretability metrics.
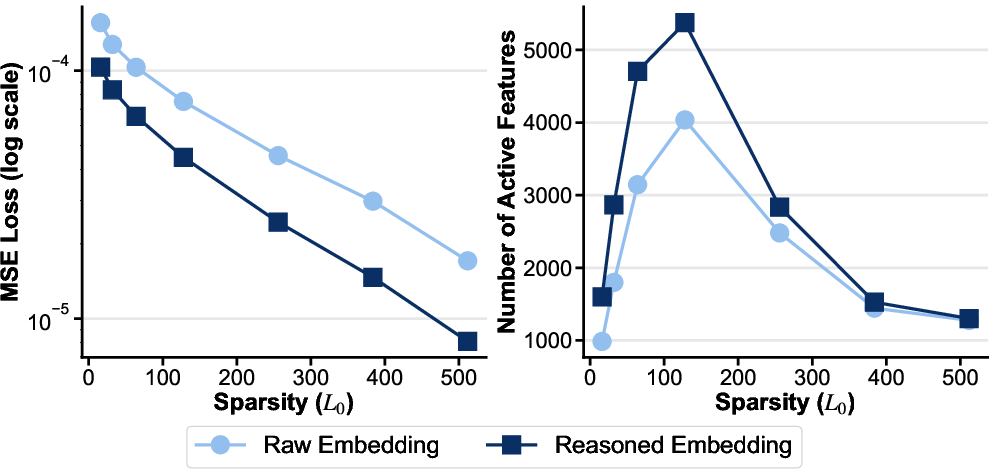
Figure 4: Comparison of reconstruction error (Left side) and the number of active features (Right side) between raw and reasoned embeddings.
Interpretability and Local Attribution
Sparse feature explanations are linked to natural language hypotheses via LLM-based summarization of top activating samples. On intruder-detection evaluations (Detection Score), Xetrieval’s features are significantly more discriminable compared to dense/unaligned baselines and random controls (Figure 5). Feature-level explanations are also locally causal. When intervening by erasing or retaining the directions aligned with Xetrieval-identified overlap features, retrieval scores are most affected, indicating tight local attribution.
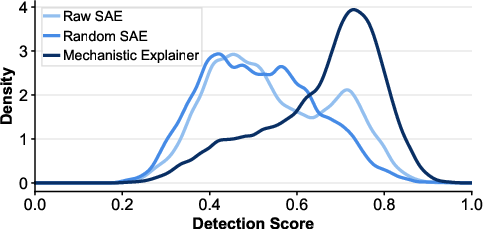
Figure 5: Detection score distribution of Raw SAE, Random SAE, and Mechanistic Explainer estimated using kernel density estimation.
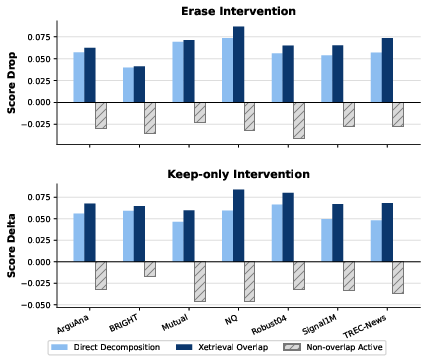
Figure 6: Pair-level document-side intervention results. We report cosine-similarity changes after erasing or retaining selected feature spans for Xetrieval, direct decomposition, and non-overlap active features.
Explanation Efficiency and Comparison with LLM-based Reasoning
A critical bottleneck in retrieval explainability research is scalability. Xetrieval’s embeddings-based architecture circumvents the prohibitive cost of large-scale autoregressive LLM generation. The explanation time remains nearly constant with corpus size, in contrast to LLM pipeline methods whose runtime grows linearly (Figure 7, left). On retrieval performance, Xetrieval closely tracks CoT-augmented systems, delivering substantial improvements over vanilla retrievers while remaining practical for corpus-scale workflows (Figure 7, right).
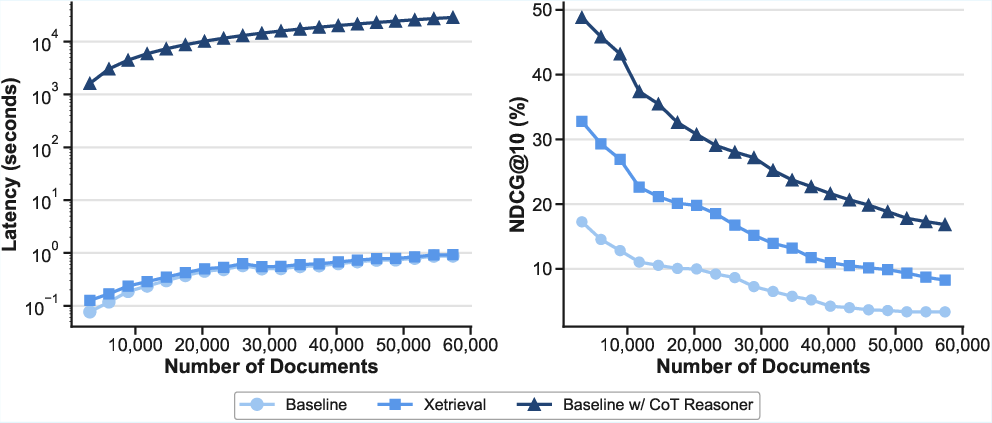
Figure 7: Left side: Comparison of explanation time trends between the CoT reasoner and the Xetrieval on the Biology subset of BRIGHT. Right side: Comparison of retrieval performance trends between the base retriever, the retriever with CoT reasoner, and Xetrieval.
Task-level Feature Steering
Beyond local attribution, Xetrieval enables task-level feature interventions. The Retrieval Utility Score (RUS) identifies key features with high positive co-activation on relevant query-document pairs. Downstream experiments confirm that amplifying these directions improves ranking, while suppression degrades it. Notably, Xetrieval’s key features are more effective for steering than those identified by direct SAE decomposition on the raw embedding space (Figure 8).
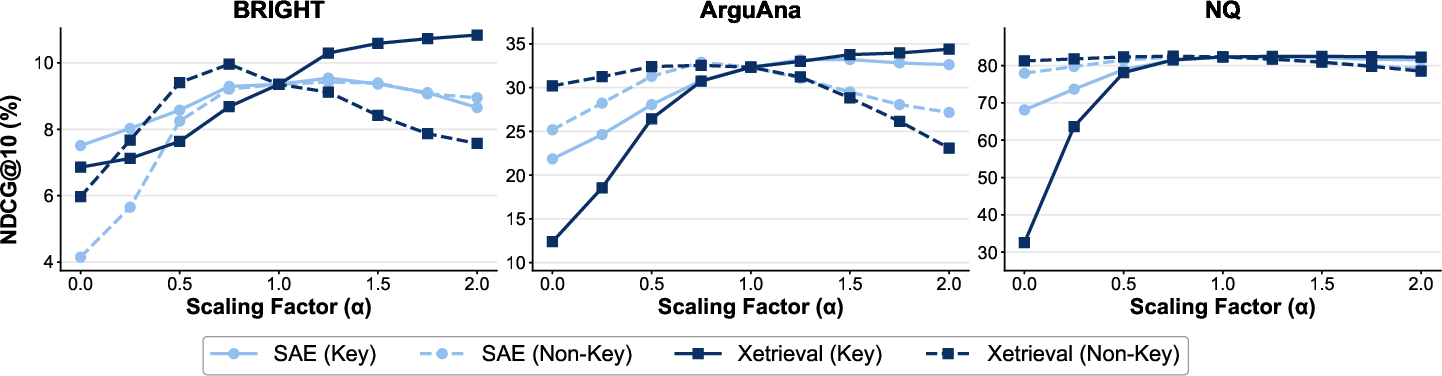
Figure 8: Retrieval results when steering key features and non-key features identified by basic SAE and Xetrieval.
Empirical Results
Xetrieval is tested across several benchmarks spanning open-domain QA, reasoning-intensive retrieval (BRIGHT, NQ, MuTual, TREC-NEWS, etc.), and on diverse state-of-the-art dense retrievers (E5, GTE, Qwen3, Snowflake). On retrieval performance (NDCG@10), the reasoning internalizer consistently improves over the base retriever, closely matches CoT reasoner results, and generalizes across underlying embedding architectures and LLMs used for supervision. Feature analysis shows strong mono-semanticity, high detection accuracy, and effective local attribution and task-level interventions across all tested domains.
Implications and Future Work
Practically, Xetrieval makes it tractable to audit, debug, and interventionally analyze dense retrievers at corpus scale, with direct applicability to IR transparency and downstream RAG systems. Theoretically, it demonstrates that reasoning-centric representations can be internalized and decomposed, providing evidence that embedding-based models do in fact learn latent, interpretable circuits. The approach sets the stage for further research on integrating multi-modal and cross-lingual reasoning, adaptively routing reasoning signals, and constructing even more granular interpretation protocols, possibly leveraging advancements such as Transcoder [dunefsky2024transcoders/transcoder].
Conclusion
Xetrieval demonstrates that mechanistic, interpretable explanations for dense retrieval decisions are attainable using a two-stage architecture that combines reasoning internalization with sparse autoencoder-based decomposition. The method yields sparse, human-readable features that not only attribute decisions but are interventionally and globally tied to retrieval outcomes. These findings inform both the scientific modeling of embedding spaces and the engineering of explainable, controllable IR systems.