CubePart: An Open-Vocabulary Part-Controllable 3D Generator
Abstract: Interactive 3D assets used in games and simulation are typically decomposed into specific semantic parts to support animation, physics, and scripted behaviors, yet most generative 3D models produce either monolithic meshes or arbitrary part decompositions that cannot be aligned with application-specific requirements. We present CubePart, a generative framework for open-vocabulary, part-controllable 3D mesh generation that exposes part structure as an explicit inference-time control signal. Given a global text prompt and a user-defined parts schema expressed as an open-ended list of part names, our method generates a set of meshes - one per schema element - that assemble into a coherent object while respecting the specified semantic structure. To enable this capability, we introduce a scalable data pipeline to construct a large open-vocabulary, part-labeled 3D dataset, along with a two-stage generative architecture that separates global shape synthesis from part-level decoding. We demonstrate that the resulting assets can be directly integrated into game engines and driven by animation and behavior scripts without manual post-processing. Project Page: https://cubepart.github.io/





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces CubePart, a computer system that can create 3D objects—like cars, robots, or drones—from a text description, and do it in separate, meaningful pieces (parts) that you choose. For example, you can say “make a jellyfish-themed race car with a body, four wheels, headlights, and an exhaust pipe,” and it will generate one 3D mesh for each part. Because the parts are separate and named, game engines can immediately animate them (wheels spin, doors open) without extra manual work.
The main questions the paper asks
- How can we let users tell a 3D generator exactly which parts an object should have, using normal text, not a fixed menu?
- How can we make sure all those parts fit together into a clean, believable object?
- How can we build a big enough dataset of 3D objects with named parts to train such a system?
- Can the result plug directly into games and simulations so objects can move and behave as expected?
How the system works (in simple terms)
Think of building a Lego model:
- First you make the full shape (what the final model looks like).
- Then you snap it into the exact pieces you care about (wheels, doors, wings), based on a list.
CubePart follows that idea with two stages and a large training dataset.
A big, smart training set of 3D parts
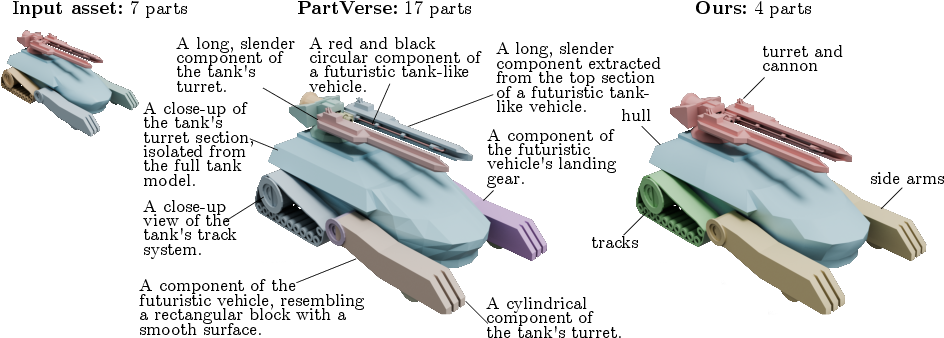
To teach the system what parts are and what they’re called, the authors built a very large dataset: about 462,000 3D objects with around 2 million parts in total. Many existing datasets are much smaller. They used an AI “vision-LLM” (a model that can look at images and understand text) to help name and group parts.
- They rendered each 3D object from several angles like a photo shoot.
- They overlaid colored outlines and little numbered “stickers” on each part in the images. This is like placing color-coded labels on the parts so the AI can tell which piece is which across different views.
- The AI then grouped tiny sub-parts into meaningful pieces and gave each a clear, short name (like “front left wheel” instead of a vague caption).
- Finally, they made sure each part is a clean, solid mesh the system can learn from.
This makes the dataset “open-vocabulary,” meaning it uses everyday words for parts rather than a limited, fixed checklist.
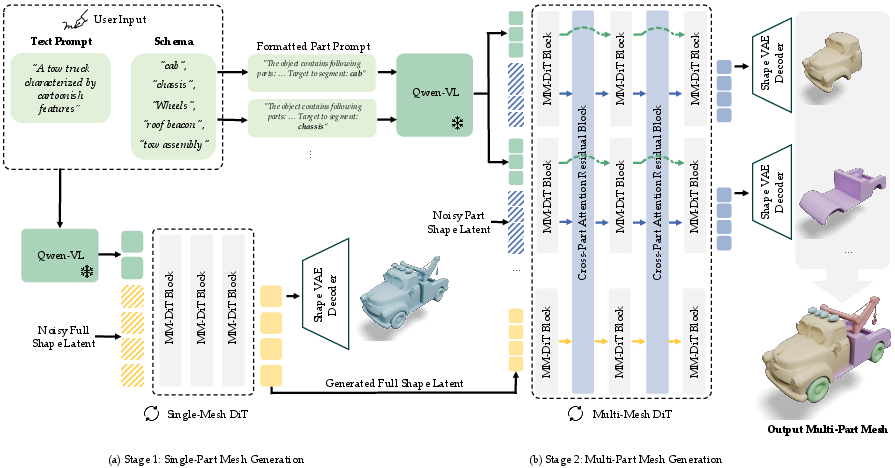
Stage 1: Make the whole object from text
Stage 1 reads your global prompt (for example, “a jellyfish-themed race car”) and learns to create a complete 3D shape. It does not split the object yet. Technically, it uses a modern “diffusion” model in a 3D-friendly format that represents a shape as a set of vectors (“vecset”), learned by an autoencoder (think of it as compressing and decompressing shape information). It also uses a strong text encoder so it understands your words.
In simple terms: Stage 1 is the sculptor. You describe the thing, and it sculpts the full object.
They fine-tune this stage to pay attention to the list of intended parts in the text so the final object actually contains room/structure for those parts.
Stage 2: Split the object into the parts you asked for
Stage 2 takes the full object from Stage 1 and divides it into the exact parts you listed in your “schema” (your part list). You can think of the schema as a blueprint: “body, front left wheel, front right wheel, rear left wheel, rear right wheel, headlights, exhaust pipe,” etc.
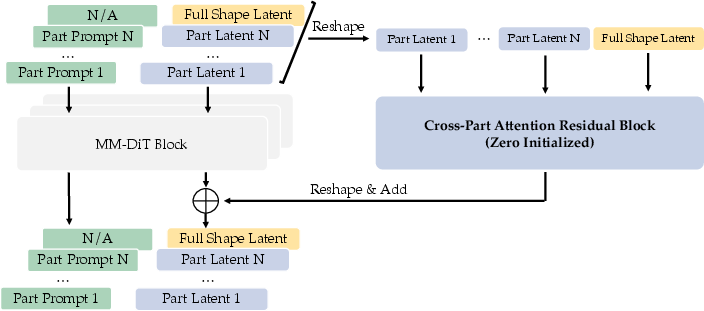
A key trick here is a special “cross-part attention” component. Imagine the parts “talk” to each other so they don’t overlap or leave gaps when separating. The authors added a small set of special attention blocks that start off “quiet” (zero-initialized) so they don’t ruin what Stage 1 learned, but then learn how parts should coordinate while training. This keeps the whole object consistent when it’s sliced into parts.
In simple terms: Stage 2 is the “part splitter” that uses your blueprint to cut the sculpture into clean, separate pieces that fit together perfectly.
What they found and why it matters
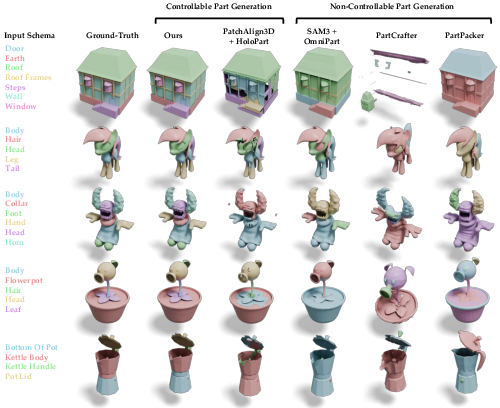
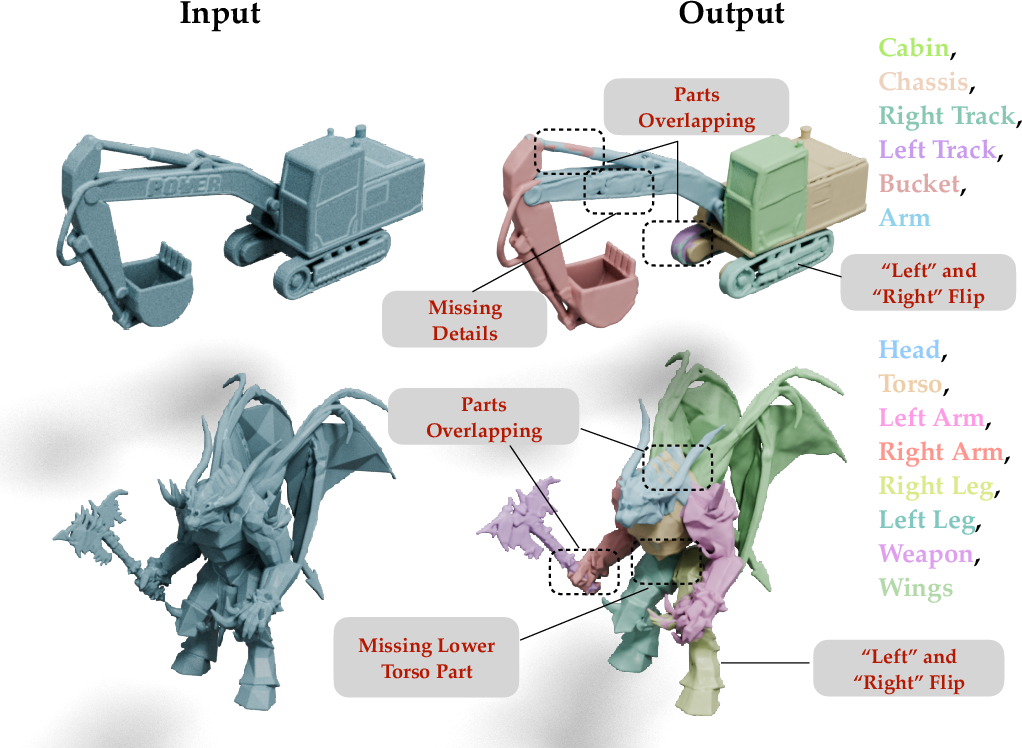
- Better part control and cleaner splits: Compared to other methods, CubePart more reliably creates the exact parts you ask for, with less overlap and better boundaries between parts. In side-by-side tests, it produced shapes closer to ground truth and cleaner part geometry.
- Open-vocabulary control: You can name parts freely in plain language (like “hood,” “left arm,” “propeller”) rather than picking from a fixed list. This makes it more flexible for different games and apps.
- Works with new objects or existing meshes: CubePart can generate a completely new multi-part object from text, or take a single mesh you already have and split it into parts according to your schema.
- Game-ready assets: Because parts are separate and named, developers can plug them into game engines and attach scripts. The paper shows cars with spinning wheels, drones with rotating propellers, and characters with moving arms and heads—all without manual mesh cleanup.
These results are important because they let artists and developers spend less time slicing models into pieces and more time designing and animating. It also opens the door to rapid prototyping of interactive objects from just a few lines of text.
Why this could be a big deal
- Faster content creation: Studios and hobbyists can quickly create complex, interactive 3D objects that are ready to animate, saving lots of time.
- Flexible for many uses: Different games might need different parts for the same type of object. CubePart lets you specify exactly what you need per project.
- Better training data practices: The dataset pipeline shows how to scale up clean, named 3D parts automatically, which can help future research and tools.
Limits and what’s next
- Mostly rigid parts: It focuses on solid pieces (good for cars, robots, props). It doesn’t yet handle stretchy, bendy parts like skin and muscles with skeletons (character rigs). Future work could add that.
- Occasional overlaps or mix-ups: Parts can still bump into each other at edges, and sometimes left/right or front/back can get confused, especially if the training labels had small mistakes.
- Spatial naming is tricky: Terms like “front-left” can be ambiguous depending on viewpoint. The system works well on average but isn’t perfect.
A quick example to tie it together
If you type: “Make a jellyfish-themed race car with body, front left wheel, front right wheel, rear left wheel, rear right wheel, headlights, and exhaust pipe,” CubePart will:
- Stage 1: Sculpt a jellyfish-like car that fits your description.
- Stage 2: Split it into the seven parts you listed, each as its own mesh.
- In a game: You can now animate the wheels to spin, turn the headlights on/off, and trigger exhaust effects—without manual cutting or renaming.
In short, CubePart turns your words into a 3D model that’s already sliced into the pieces you need to bring it to life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide follow-up research and engineering.
- Deformable characters and rigs are unsupported: no prediction of skeletal hierarchies, joint locations/axes, or skinning weights; generating rig-ready meshes with consistent deformation semantics is left open.
- No explicit enforcement of non-interpenetration: parts still intersect at contacts; there is no contact-aware loss, collision penalty, or shared-interface constraint to guarantee disjoint, snug fits.
- Spatial referencing ambiguity persists: “left/right/front/back” misassignments arise from VLM label noise and view-frame confusion; canonical object-frame definition, spatially grounded supervision, and dedicated evaluation metrics are not provided.
- Dataset annotation quality is unquantified: the VLM-based clustering/naming lacks error rates, human validation, or inter-annotator agreement; failure modes and systematic biases are unreported.
- Reproducibility is unclear: large portions of the dataset are proprietary/commercial and clustering relies on GPT-5; there is no release plan, making replication and benchmarking difficult.
- Open-vocabulary generalization is unmeasured: behavior on rare classes, long-tail part names, synonyms, and multi-lingual schemas is not evaluated; vocabulary canonicalization and synonym mapping are undeveloped.
- Schema adherence lacks semantic metrics: evaluation relies on CD/F-score; there is no metric for correct part-to-name assignment, cardinality satisfaction (e.g., exactly four wheels), or left/right correctness.
- Handling partial, contradictory, or overly granular schemas is unspecified: how the model behaves when parts are omitted, duplicated, or conflict (e.g., “single wheel” and “four wheels”) is not defined or evaluated.
- Cardinality constraints and repeated parts are not formalized: there is no mechanism to enforce counts (e.g., “8 spokes,” “3 legs”) or to guarantee exactly the requested multiplicities.
- Geometric control is limited to names: users cannot supply bounding boxes, relative transforms, size constraints, or attachment hints to steer part locations and scales.
- Robustness to non-watertight or noisy inputs is unknown: Stage 2 expects watertight meshes; performance on raw scans, non-manifold meshes, or high-noise assets is untested.
- Production asset readiness is incomplete: UVs, materials, textures, LODs, and retopology controls (polycount, quads) are not generated; pipelines to create fully game-ready assets are not addressed.
- Physical plausibility is not ensured: hinge alignments, wheel axes, tolerances, and mass/inertia or unit-scale consistency are absent; generating physics-ready parameters remains open.
- Hierarchical structure is missing: outputs are flat sets of meshes without parent–child relationships, joints, constraints, or animation-friendly hierarchies.
- Scalability to very large assemblies is untested: the dataset filters to 2–32 parts; performance for complex objects (e.g., engines with dozens/hundreds of parts) is unknown.
- Category and source biases are unexamined: dataset composition, class balance, style diversity, and their effects on generalization are not analyzed.
- Evaluation breadth is limited: results focus on PartObjaverse-Tiny and geometric metrics; human studies on semantic correctness, usability in engines, and behavior compatibility are absent.
- Stability and repeatability are unreported: variance across random seeds, prompt perturbations, and fine-tuning checkpoints, as well as determinism controls, are not studied.
- Content provenance and IP risks are not discussed: potential for memorization or stylistic cloning of training assets, and safeguards for ethical use, are unaddressed.
- Hardware accessibility is unclear: inference times are reported on H200s; performance, memory footprint, and throughput on commodity GPUs or CPUs are not provided.
- Cross-part attention design lacks analysis: theoretical justification, sensitivity to the number/placement of zero-initialized blocks, and behavior with varying numbers of parts are not explored.
- Token allocation per part is fixed: adaptive token budgets for parts of varying complexity and associated trade-offs (quality vs. compute) are not investigated.
- Occluded/internal part generation is under-evaluated: how the model infers hidden components, and metrics for correctness of non-visible parts, are not presented.
- Multimodal conditioning beyond text is not studied: combining images/sketches/layouts with schemas, or switching modalities at inference, remains unexplored.
- Symmetry handling and canonical orientation are not solved: consistent left/right mapping across assets and categories, and automatic canonicalization, are missing.
- Automatic schema induction is absent: mapping from a global prompt or engine-specific behavior requirements to a compatible parts schema (and its granularity) is not addressed.
- Post-generation QC and repair tools are lacking: automatic detection and correction of overlaps, missing parts, mislabels, or spatial misplacements are not provided.
- Licensing and compliance auditing is unspecified: while “permissively-licensed” filtering is claimed, audit procedures and provenance tracking for large-scale aggregation are not detailed.
Practical Applications
Immediate Applications
The following applications can be deployed today with modest engineering effort, leveraging the paper’s two-stage, schema-driven 3D generation and the accompanying automated dataset pipeline.
- Bold: Game-ready asset generation with part schemas
- Generate 3D objects from text plus a user-defined parts schema, outputting separate meshes per part that assemble coherently; directly hook parts to animation, physics, and scripts.
- Sectors: Gaming, AR/VR, VFX previs.
- Tools/Products/Workflows: Engine plugins for Unity/Unreal/Roblox Studio that accept “prompt + schema” and export GLTF/FBX with named parts; automatic collider generation; auto-joint binding (e.g., “wheel” → hinge joint).
- Assumptions/Dependencies: Robust schema naming (synonyms mapping), occasional left/right or overlap errors; rigid parts only (no skinning); cloud inference or high-end GPU (e.g., H200); content moderation for prompts.
- Bold: Retrofitting existing meshes for interactivity
- Provide a target schema and decompose monolithic meshes into named parts to enable behaviors (e.g., openable doors, detachable props) without manual re-meshing.
- Sectors: Gaming, UGC platforms, asset marketplaces.
- Tools/Products/Workflows: Blender/engine add-ons that apply a schema to existing models to produce per-part meshes; auto-generate behaviors from part names.
- Assumptions/Dependencies: Works best on watertight or clean meshes; potential interpenetration at part boundaries; ambiguous geometry can cause missing parts.
- Bold: Behavior template libraries bound to part names
- Ship reusable scripts (e.g., “vehicle-driving,” “hinge-door,” “prop-rotation”) that auto-bind to parts by name (e.g., body/wheel/door).
- Sectors: Gaming, AR/VR prototyping, education.
- Tools/Products/Workflows: Lua/C#/Blueprint behavior packs keyed to canonical part schemas; wizard that suggests schemas needed by chosen behaviors.
- Assumptions/Dependencies: Conventions for part naming; fallbacks for synonym resolution (e.g., “front left wheel” vs. “FL wheel”); physics settings tuned per engine.
- Bold: Rapid prototyping of interactive AR/VR scenes
- Create “good enough” interactive placeholders with accurate part separation for UX tests and experiential design.
- Sectors: AR/VR, design prototyping, VFX previs.
- Tools/Products/Workflows: One-click import to Unity/Unreal; auto-LOD and colliders per part; basic rigging for rigid groups.
- Assumptions/Dependencies: Not production-quality rigging; occasional part overlap; export pipeline (GLTF/FBX) in place.
- Bold: Robotics simulation assets with articulation
- Generate articulated props (drawers, hinges, wheels) and simple robots with named parts for URDF/SDFormat export and physics simulation.
- Sectors: Robotics, RL simulation.
- Tools/Products/Workflows: URDF exporter that maps part names to joints; automatic inertial approximations; import to Gazebo/MuJoCo/Isaac Sim.
- Assumptions/Dependencies: Rigid parts only; mass/inertia are approximations; ensure non-interpenetration for stability; naming-to-joint mapping templates.
- Bold: Interactive product/retail concept visuals
- Produce interactive 3D concept visuals (e.g., furniture with doors/drawers/lids) for web viewers where parts can be manipulated.
- Sectors: E-commerce visualization, marketing.
- Tools/Products/Workflows: WebGL viewers using GLTF with named parts; configurable schema templates (e.g., “drawer,” “door,” “legs”).
- Assumptions/Dependencies: Not dimensionally accurate; use for concept/marketing visuals only; potential brand/IP constraints; moderation.
- Bold: Classroom and lab demos for STEM
- Quickly create interactive teaching aids (e.g., gear-in-a-box, wheeled carts) with movable parts to demonstrate physics and mechanics.
- Sectors: Education.
- Tools/Products/Workflows: Education packs with preset schemas and behaviors; simple engine-based playgrounds (e.g., Roblox Studio, Unity).
- Assumptions/Dependencies: Safety and age-appropriate content filters; rigid parts suffice for many demos; compute access for generation.
- Bold: Asset library curation via open-vocab part naming
- Use the Set-of-Mark VLM pipeline to cluster and standardize part names across large libraries, improving search and reuse (e.g., “front left wheel,” “hull,” “tracks”).
- Sectors: Content platforms, studios, marketplaces.
- Tools/Products/Workflows: Offline batch processing pipeline; metadata indexing by part names and functions; library deduplication.
- Assumptions/Dependencies: Good multi-view renders; VLM quality; occasional spatial naming errors; licensing check for annotations.
- Bold: Previsualization and blocking for animation/VFX
- Quickly generate multi-part props and vehicles for previs blocking, where separate parts enable simple rigging and timing beats.
- Sectors: Film, TV, advertising.
- Tools/Products/Workflows: Maya/Blender importers; rigid rigs from part names; animator-friendly naming conventions.
- Assumptions/Dependencies: Not skinned or production-rig-ready; manual cleanup for hero shots.
- Bold: Academic benchmarking and data creation
- Use the dataset and task (open-vocab, schema-controlled multi-mesh generation) as a benchmark for 3D generative models and part understanding.
- Sectors: Academia.
- Tools/Products/Workflows: Open datasets and leaderboards; ablations on cross-part attention; experiments with multilingual schemas.
- Assumptions/Dependencies: Dataset availability and licensing; reproducibility of VLM-based annotation pipeline.
Long-Term Applications
These applications are feasible with further research, scaling, or integration—particularly around deformables, physics, precision constraints, and governance.
- Bold: Auto-rigging and skinning with skeletal weights
- Predict skeletal structure and skin weights from prompt + schema to support deformable characters and organic motion.
- Sectors: Gaming, film/animation, AR/VR.
- Tools/Products/Workflows: Rig and weight prediction module; export to FBX with bones; auto-retargeting.
- Assumptions/Dependencies: Large-scale rigged data; supervision for skinning; evaluation for deformation quality.
- Bold: Physics-aware generation (no interpenetration, joints, masses)
- Generate parts that respect contact surfaces and clearances, with joint types/limits and mass/inertia tuned for stability.
- Sectors: Robotics, simulation, game physics.
- Tools/Products/Workflows: Physics-informed diffusion; joint inference; post-generation validation/repair tools.
- Assumptions/Dependencies: New training signals for contact/joint constraints; higher-fidelity physical priors.
- Bold: CAD/engineering-grade assemblies
- Output parametric, constraint-driven assemblies (with tolerances, BOM), not just meshes—bridging into CAD ecosystems.
- Sectors: Manufacturing, industrial design.
- Tools/Products/Workflows: STEP/Parasolid export; parametric constraints from schema; mechanical fit validation.
- Assumptions/Dependencies: Precision geometry and constraints data; integration with CAD kernels; compliance and certification.
- Bold: Anatomically and scientifically accurate models
- Open-vocab part-controlled generation of anatomical or scientific structures with verifiable accuracy for training and planning.
- Sectors: Healthcare, scientific visualization, education.
- Tools/Products/Workflows: Domain-specific datasets; structured ontologies and standardized schemas; validation pipelines.
- Assumptions/Dependencies: Medical/scientific data access and consent; regulatory compliance; rigorous QA.
- Bold: Digital twins and maintenance training content
- Generate machine assemblies with named parts and logical connections aligned with manuals/schematics for training and diagnostics.
- Sectors: Industrial training, field service, aerospace.
- Tools/Products/Workflows: Schema-to-procedure linking; simulated faults; AR overlays for instructions.
- Assumptions/Dependencies: High semantic fidelity; integration with enterprise asset data; safety and IP protections.
- Bold: Procedural game/world generation with behavior-aware assets
- From a high-level spec, synthesize entire scenes populated with interactive, schema-consistent assets and pre-bound behaviors.
- Sectors: Gaming, UGC platforms.
- Tools/Products/Workflows: World-gen orchestrators; behavior graph libraries keyed to schemas; validation harnesses.
- Assumptions/Dependencies: Scalable generation and moderation; dependency management across thousands of assets.
- Bold: Personalized 3D products and on-demand manufacturing
- Co-design personalized, part-based products and export them for fabrication (3D print, CNC), with automatic assembly guidance.
- Sectors: Consumer products, maker communities.
- Tools/Products/Workflows: Manufacturability-aware generation; printability and tolerance checks; assembly instructions.
- Assumptions/Dependencies: Precise geometry and fit; materials and safety compliance; liability considerations.
- Bold: Schema-aware 3D search and retrieval
- Search large libraries by desired part composition (e.g., “car with four wheels and a deployable spoiler”) and assemble/modify results.
- Sectors: Marketplaces, studios, enterprise asset management.
- Tools/Products/Workflows: Indexing by inferred schemas; hybrid retrieval + generation; automatic part substitutions.
- Assumptions/Dependencies: Consistent part naming and ontology; scalable indexing.
- Bold: Multilingual and domain-adapted schemas
- Robustly handle localized and domain-specific taxonomies (e.g., automotive, aerospace), mapping synonyms and spatial descriptors.
- Sectors: Global platforms, industry verticals.
- Tools/Products/Workflows: Multilingual VLMs; domain ontologies; synonym/spatial disambiguation modules.
- Assumptions/Dependencies: Training data across languages/domains; handling of coordinate frame ambiguities.
- Bold: Governance, provenance, and safety controls for 3D generation
- Policy frameworks and tooling for dataset provenance, output watermarking, and content moderation (e.g., restricted items).
- Sectors: Platforms, policy, legal/compliance.
- Tools/Products/Workflows: Watermarking at mesh/part level; audit trails; user-level safety filters; license tagging.
- Assumptions/Dependencies: Alignment with emerging regulations; clarity on training data rights; platform enforcement mechanisms.
- Bold: On-device or real-time interactive generation
- Distill models for consumer GPUs or consoles to support near-real-time, in-editor generation and iteration.
- Sectors: Gaming tools, AR/VR creation.
- Tools/Products/Workflows: Model compression, caching, incremental updates; streaming inference.
- Assumptions/Dependencies: Optimization research; quality-performance trade-offs; memory constraints.
- Bold: Cross-modal pipelines (text → parts → behaviors → code)
- Extend schema-driven generation to emit behavior graphs and script stubs, auto-wiring parts to code and effects.
- Sectors: Game dev tools, education, UGC.
- Tools/Products/Workflows: LLM-assisted codegen tied to part schemas; validation tests; auto-debugging workflows.
- Assumptions/Dependencies: Reliable schema-to-code mapping; human-in-the-loop review; safety and sandboxing.
Notes on Feasibility and Risks
- Naming and spatial ambiguity: Open-vocab part names and left/right/front/back labels can be misinterpreted if coordinate frames and viewpoints aren’t standardized. Synonym handling and axis conventions are required.
- Rigid-only support (today): Deformable parts, skinning, and high-end rigging are not yet supported; plan for manual rigging for characters.
- Geometric reliability: Occasional interpenetration or missing parts can occur; add validation and simple geometric repairs in pipelines.
- Compute and latency: Inference is a few seconds on H200-class GPUs; production deployment will likely use cloud inference or optimized variants.
- Data governance: Automated VLM labeling pipelines should be audited; ensure licenses of source assets; add output moderation and provenance tracking.
Glossary
- 3DShape2VecSet: A transformer-based autoencoder that encodes 3D meshes into compact vector-set latents for generative modeling. "using 3DShape2VecSet~\cite{3dshape2vecset}"
- AdamW: An adaptive gradient optimizer with decoupled weight decay commonly used for training deep networks. "We adopt AdamW as the optimizer, with values set to 0.9 and 0.99, and weight decay disabled."
- Chamfer Distance (CD): A bidirectional distance metric between point sets used to evaluate geometric similarity of 3D shapes. "We employ two geometric metrics to measure shape quality: Chamfer Distance (CD) and F-score."
- Cross-attention: An attention mechanism that conditions one sequence (e.g., shape latents) on another (e.g., text or image features). "injected via cross-attention mechanisms in transformer blocks."
- Cross-Part Attention Residual Blocks: Additional transformer blocks enabling information exchange across generated parts to maintain global coherence. "inject Cross-Part Attention Residual Blocks to enable structural interaction among parts."
- Dual Marching Cubes: A surface extraction algorithm used to convert implicit fields to meshes with better topology preservation. "convert each part to a watertight mesh using Dual Marching Cubes on a unsigned distance field"
- F-score: The harmonic mean of precision and recall applied to point-set evaluation with a distance threshold. "We employ two geometric metrics to measure shape quality: Chamfer Distance (CD) and F-score."
- Flow matching: A training objective that learns continuous-time flows to transport noise to data distributions for generative modeling. "We adopt the flow matching training objective, following \cite{liu2023flow, ma2024sit, stable-diffusion-3}."
- Logit-normal distribution: A probability distribution for variables in (0,1), obtained by applying the logistic function to a normal variable. "the timestep is sampled from a logit-normal distribution and shifted with a factor of 4.0, following \cite{timeshift}."
- Multi-Modal DiT (MM-DiT): A diffusion transformer architecture that integrates multiple modalities (e.g., text) for conditioned generation. "Single Mesh Generation synthesizes a holistic shape latent using a Multi-Modal DiT (MM-DiT)~\cite{stable-diffusion-3}, conditioned on the prompt and schema encoded by Qwen-VL~\cite{qwen-vl}."
- Open-vocabulary: Allowing free-form natural language labels rather than restricting to a fixed taxonomy. "open-vocabulary, part-controllable 3D mesh generation"
- Parts schema: A user-specified list of semantic part names defining the desired decomposition of a 3D object. "a user-defined parts schema expressed as an open-ended list of part names"
- Qwen-VL: A vision-LLM used here to encode text prompts for conditioning the diffusion model. "we employ Qwen-VL~\cite{qwen-vl} to encode the text prompt"
- Score Distillation Sampling (SDS): A technique that distills priors from 2D diffusion models to optimize 3D representations. "which introduced Score Distillation Sampling (SDS) to optimize implicit 3D representations"
- Set-of-Mark (SoM): A prompting method that overlays numbered markers for visual grounding; adapted here for multi-view 3D part annotation. "Inspired by the Set-of-Mark (SoM) prompting technique~\cite{setofmark}, which enables visual grounding in VLMs by overlaying numeric identifiers on image regions,"
- Signed Distance Function (SDF): An implicit representation giving the distance to the closest surface, with sign indicating inside/outside. "The VAE decoder employs a Signed Distance Function (SDF) representation, which enables sharper geometry reconstruction."
- Variational Autoencoder (VAE): A generative model that learns probabilistic encoders/decoders for latent-variable representations. "encoding 3D meshes into latent vector sets using a transformer-based Variational Autoencoder (VAE)"
- Vecset diffusion: A family of diffusion models that generate unordered sets of latent vectors encoding 3D shapes. "Vecset diffusion models~\cite{craftsman3d,triposg,clay,hunyuan3d-2-1} represent a class of latent diffusion models designed to generate sets of unordered vectors (vecsets) that implicitly encode 3D shapes."
- Vision-LLM (VLM): A model jointly trained on visual and textual data for tasks like captioning, grounding, and labeling. "leverages vision-LLMs (VLMs) and a novel 3D-aware "Set-of-Mark" annotation strategy"
- Watertight mesh: A mesh without holes or gaps, suitable for reliable surface operations and simulation. "convert each part to a watertight mesh"
- Zero-initialized Transformer block: A transformer layer initialized to zero so it initially preserves pretrained behavior while enabling new interactions. "A dedicated zero-initialized Transformer block is designed for cross-part global attention."
Collections
Sign up for free to add this paper to one or more collections.