SegviGen: Repurposing 3D Generative Model for Part Segmentation
Abstract: We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “SegviGen: Repurposing 3D Generative Model for Part Segmentation”
What is this paper about?
This paper is about teaching a computer to automatically “cut” a 3D object into its meaningful parts—like separating a car into wheels, doors, and windows—quickly and accurately. The authors introduce a new method called SegviGen that uses a powerful 3D “imagination” model (a 3D generative model) and cleverly turns the problem of finding parts into a simple coloring task.
What questions are the researchers trying to answer?
The paper focuses on a few clear goals:
- Can we use a 3D model that already knows a lot about shapes and textures (because it was trained to create 3D objects) to help split objects into parts?
- Can we avoid the problems of older methods that rely on 2D images from many camera views, which often don’t line up well in 3D?
- Can we make part segmentation work with very little labeled training data and still get sharp, accurate boundaries between parts?
- Can one system handle different ways of working: single-click part selection (interactive), automatic full-part breakdown, and full-part breakdown guided by a simple 2D color map?
How does SegviGen work? (Explained simply)
Think of a 3D object like a digital sculpture made of tiny 3D “pixels” called voxels.
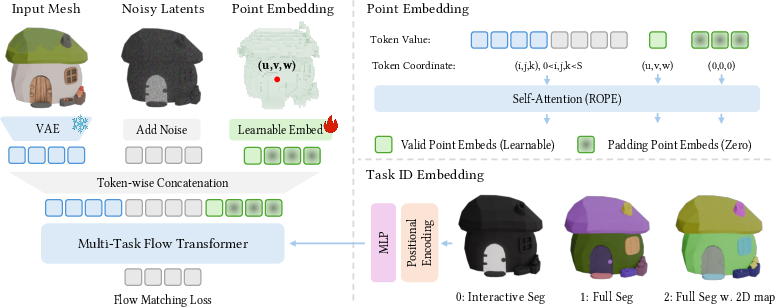
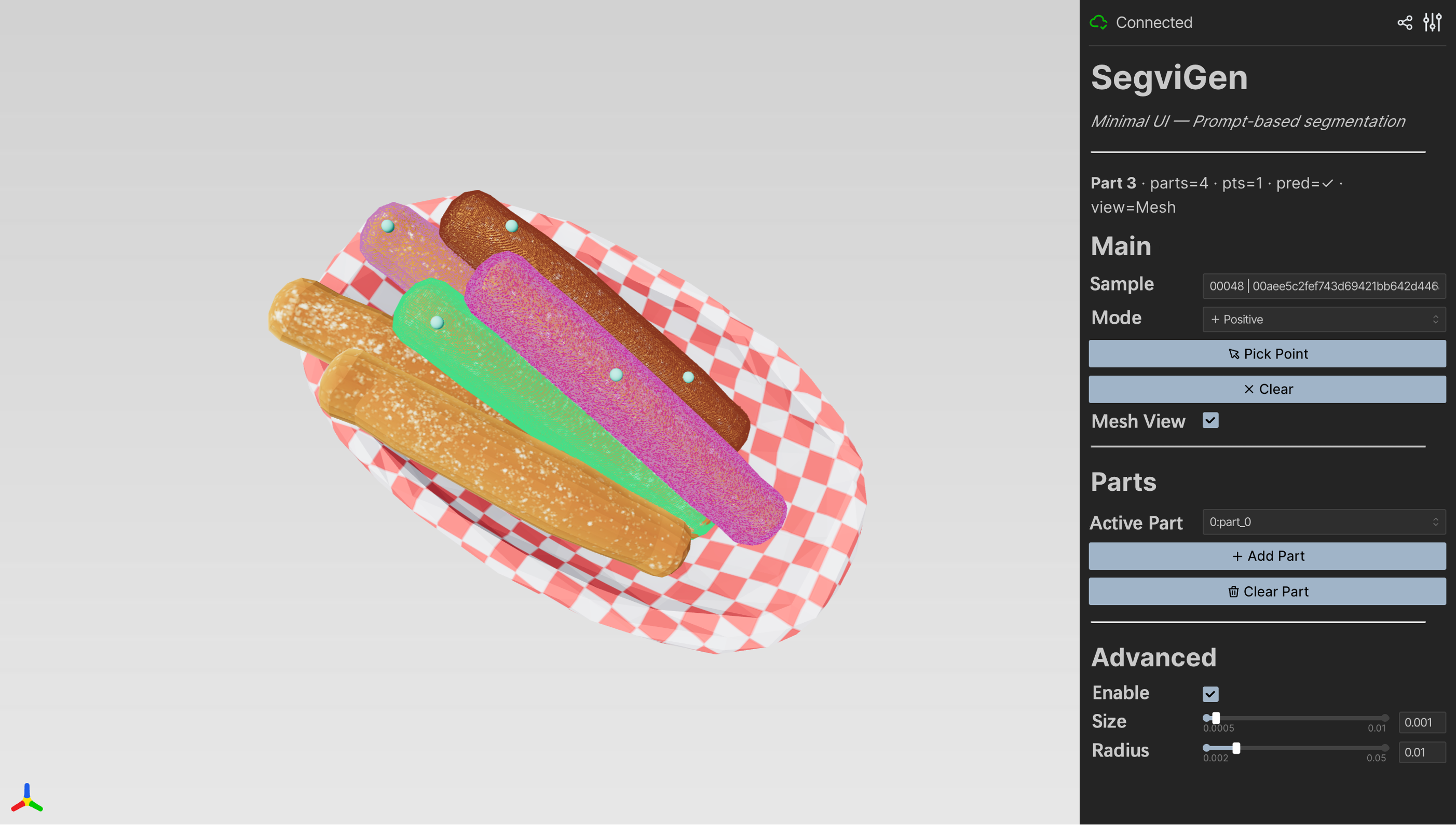
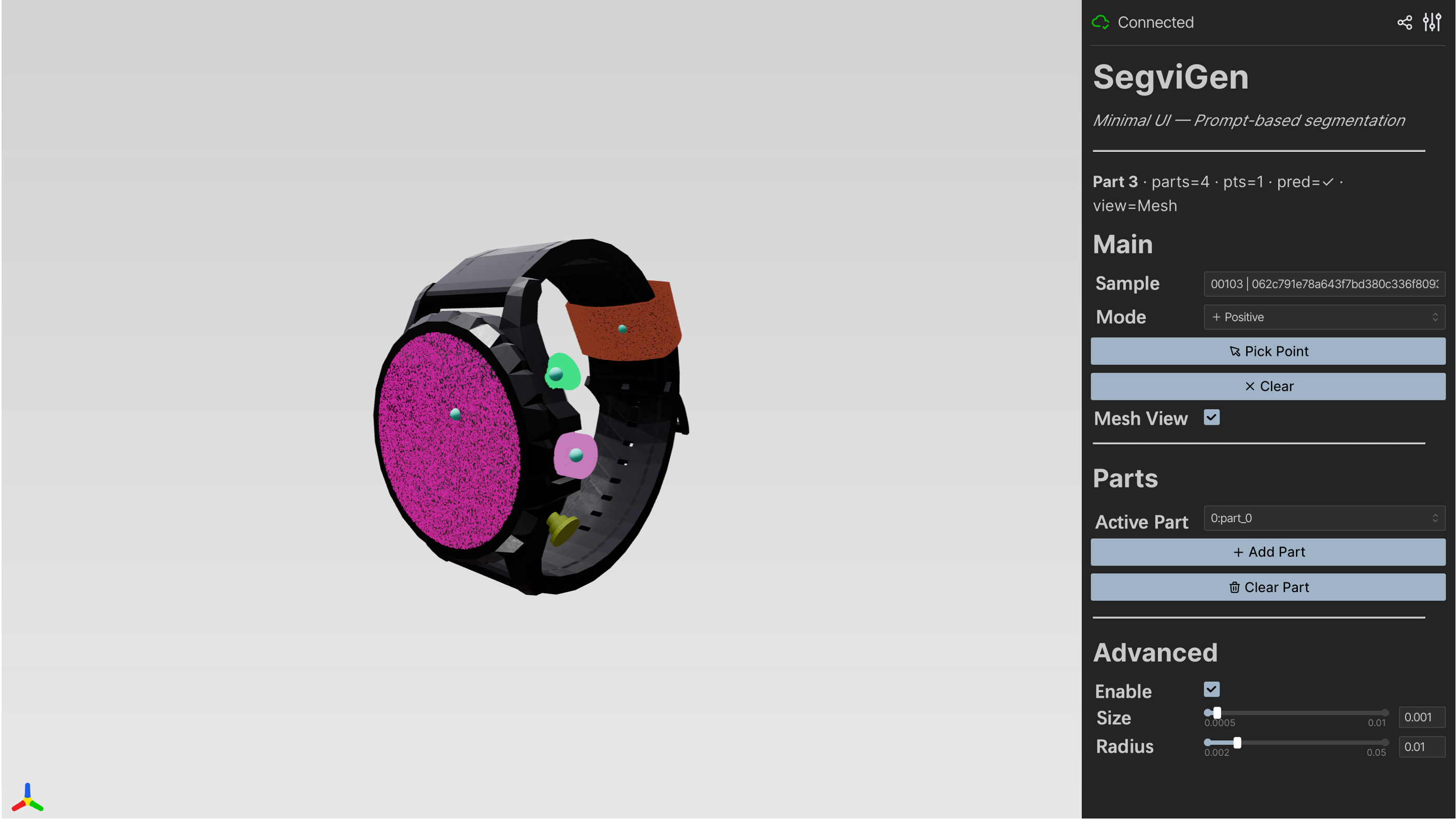
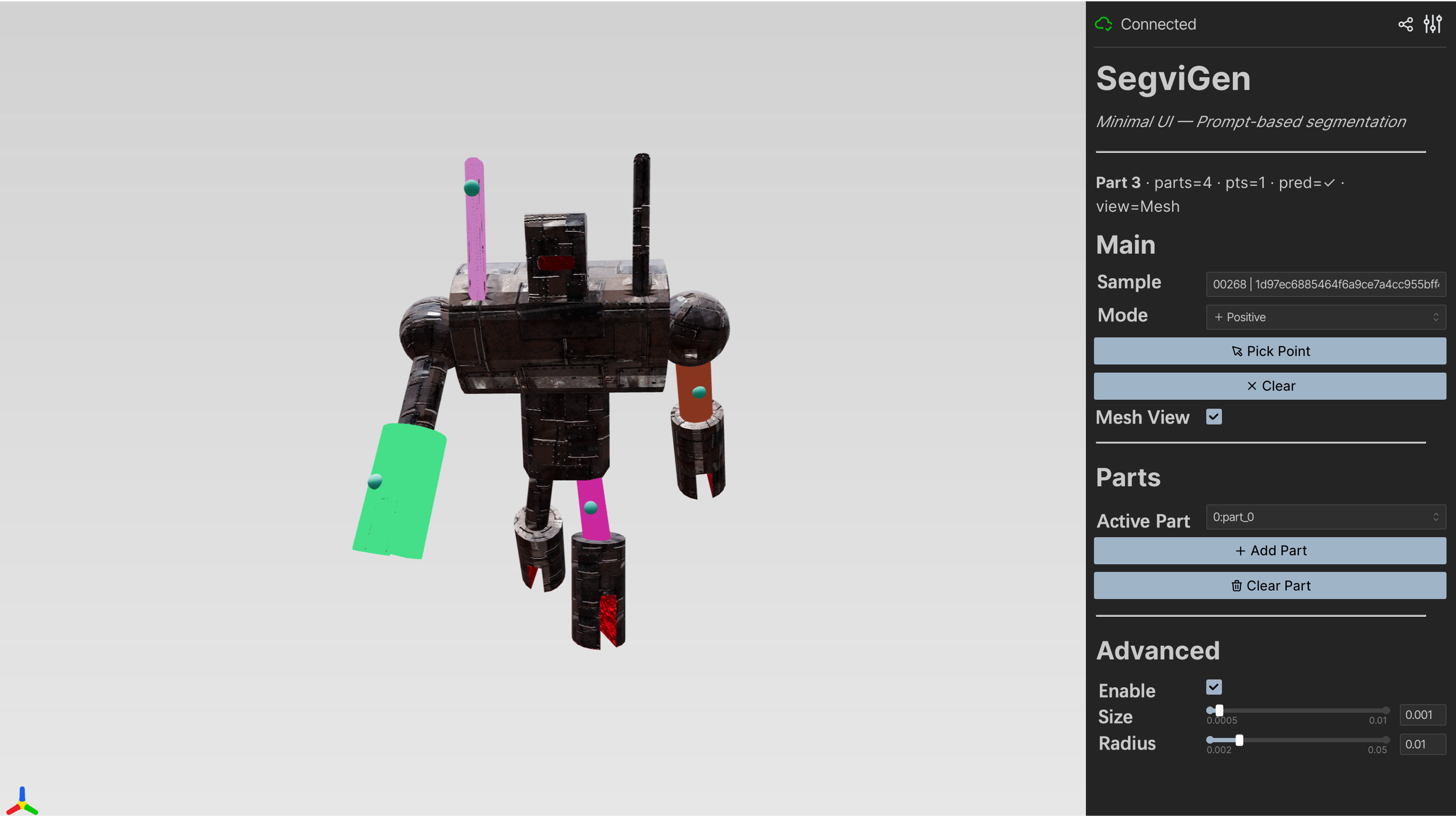
- The big idea: turn segmentation into “coloring.” Instead of predicting part IDs (like “wheel = 3”), SegviGen assigns different colors to different parts. If two voxels have the same color, they belong to the same part. It’s like filling in a 3D coloring book.
- Why coloring helps: The underlying 3D generative model is very good at understanding object shapes and their appearance (because it was trained to generate realistic 3D shapes). Using color fits naturally with what that model already knows, so we don’t have to teach it from scratch.
- A simple analogy for the tech:
- A “3D generative model” is like an artist who has seen millions of sculptures and can imagine new ones.
- A “VAE” is a smart compressor that turns a 3D object into a compact “recipe” (called a latent) and can rebuild it later.
- “Denoising/flow” is like starting with a messy, slightly noisy color version and gradually cleaning it up into crisp, correct part colors—guided by the object’s 3D shape and any hints you provide.
- One model, three modes:
- Interactive segmentation: You click on a part (like tapping a wheel), and the system colors that whole part for you.
- Full segmentation: The system automatically colors all parts differently, no extra hints needed.
- 2D-guided segmentation: You provide a simple 2D colored map (like painting regions on an image), and the system uses it to produce an even more precise 3D part breakdown.
- Key pieces explained simply:
- Voxels: tiny cubes that make up the 3D object (like 3D pixels).
- Latent: a compact code that summarizes the 3D object, used by the model to make predictions.
- Colorization: assigning colors to voxels; each unique color = one part.
What did they find, and why is it important?
The authors tested SegviGen on standard collections of 3D models and compared it to other top methods.
Here are the main results, in plain terms:
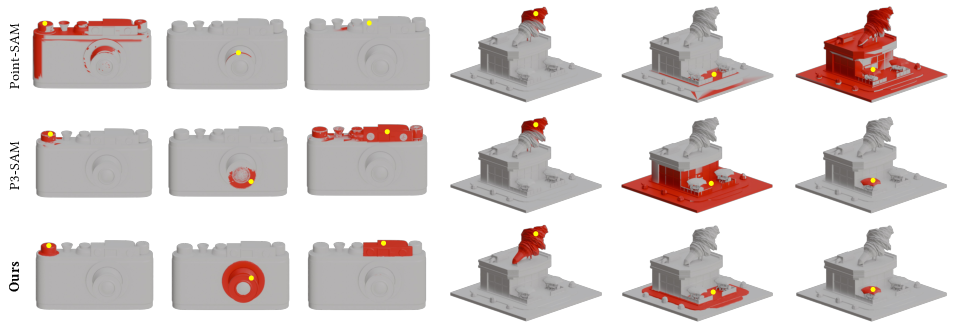
- Much better interactive results with fewer clicks: With just one click, SegviGen was about 40% better (in a standard accuracy measure called IoU@1) than a strong previous system (P3-SAM). That means it’s great at guessing the whole part from minimal user input.
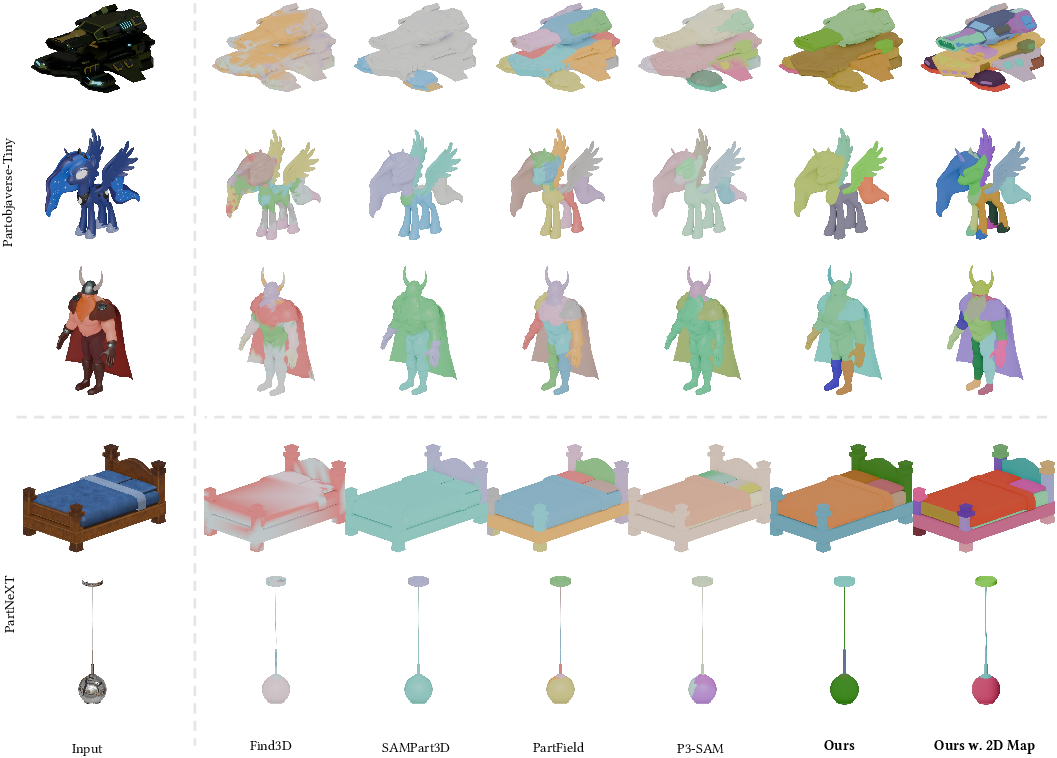
- Strong automatic full-part breakdown: On average, SegviGen improved full segmentation by about 15% compared to the best previous methods.
- Works with very little labeled data: It reached these results using only about 0.32% of the usual amount of hand-labeled training data. That’s a huge reduction in the effort needed to prepare training examples.
- Sharper, cleaner boundaries: Parts are more neatly separated, avoiding the blurry, inconsistent edges that happen when you try to combine many 2D views into a 3D result.
- Even better with a simple 2D hint: When given a single 2D colored map as guidance, SegviGen got an extra boost in accuracy and let users control how detailed the part breakdown should be.
Why this matters:
- Less data, better results: Training with far fewer labels saves a lot of time and money.
- More reliable part boundaries: Clean, sharp part edges are critical for tasks like 3D editing, animation rigging, and 3D printing.
- Flexible control: Users can interact (click), run it fully automatic, or guide it with a 2D sketch—whatever suits the task.
What could this change in the real world?
This research could make 3D work faster and easier:
- 3D creators can quickly select and edit specific parts (like swapping a chair’s legs or recoloring a car’s doors).
- Animators can rig objects by parts more easily (e.g., arms, hinges, or joints).
- Designers and engineers can prepare models for 3D printing more reliably.
- Because it needs very little labeled data, it can be applied to new categories of objects without massive annotation efforts.
In short, SegviGen shows that a 3D model trained to imagine shapes can also be a strong helper for splitting those shapes into meaningful parts—doing it more accurately, with sharper edges, and with far less training data than before.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Dependence on a specific base model: Sensitivity of SegviGen to the choice of pretrained 3D generative backbone (e.g., Trellis.2 vs. other native 3D generators) is not evaluated; portability across architectures and training corpora remains unknown.
- Hidden pretraining cost: While fine-tuning uses few labels, the approach relies on a heavily pretrained 3D generative model; compute/data requirements and accessibility of such pretraining (and their impact on segmentation) are not quantified.
- Lack of semantic part labels: Outputs are unlabeled part regions (colors as proxies) without mapping to human-readable semantics; integrating language grounding (e.g., with VLMs/CLIP-like signals) is unaddressed.
- Colorization as a proxy for discrete parts: The color-based formulation may cause ambiguity (e.g., color collisions, nearby hues) and assumes permutation invariance via random palettes; there is no formal mechanism or analysis ensuring stable, discrete part assignment across shapes.
- Determining part granularity without guidance: In unguided full segmentation, it is unclear how the method decides (or can be instructed to decide) the number of parts; mechanisms for controlling or predicting granularity are missing.
- Post-processing and matching details: The process for converting predicted colors to final masks (e.g., clustering, thresholds, Hungarian matching) is under-specified; robustness of this step and its sensitivity to hyperparameters is not analyzed.
- Interaction modality limitations: Only positive click prompts (padded to 10 tokens) are supported; the effect of negative clicks, scribbles, boxes, or more extensive interactions—and robustness to mis-clicks—are not studied.
- Viewpoint dependence in 2D-guided mode: The 2D guidance uses a single view with no strategy for viewpoint selection or multi-view fusion; effects of occlusions, unseen surfaces, and misaligned guidance are not quantified.
- Sensitivity to 2D map quality: Robustness of 2D-guided segmentation to noisy, incorrect, or coarse 2D masks (e.g., from different 2D segmenters) is unexplored.
- Texture reliance and ambiguity: The approach leverages texture-aware priors; performance on texture-poor or textureless assets (e.g., raw scans), and resilience to high-frequency textures within a single part, are not evaluated.
- Domain and modality generalization: Generalization to real scans, point clouds, indoor scenes (e.g., ScanNet), or CAD-only/implicit surfaces is untested.
- Dataset scope and diversity: Evaluations are limited to two curated datasets with 200–300 objects; category-wise generalization, long-tail categories, and cross-dataset robustness are not systematically analyzed.
- No boundary-precision metrics: Only IoU is reported; boundary sharpness (e.g., Boundary F1), part connectivity, leakage, and adherence to thin structures are not quantitatively assessed.
- Small/thin-part performance: There is no stratified analysis of performance on tiny, thin, or highly concave parts; failure rates on fine structures remain unknown.
- Resolution and voxelization effects: Impact of O-voxel resolution and voxelization artifacts on mesh-surface alignment and boundary accuracy—especially when projecting voxel labels back to meshes—is not measured.
- Runtime and memory profiling: Inference time is briefly reported for a single setting; scaling with shape resolution/complexity, memory footprint, and comparative efficiency versus baselines are not comprehensively benchmarked.
- Ablations on model components: Only point-embedding and step-count ablations are provided; effects of freezing vs. fine-tuning the SC-VAE, different conditioning schemes, or removing generative priors (training from scratch) are not studied.
- Alternative label parameterizations: No comparison between colorization and more direct segmentation parameterizations (e.g., per-voxel logits, discrete tokens, or mask decoders) to validate colorization as the superior choice.
- Negative transfer and hallucination: Whether generative priors impose typical part layouts on atypical objects (leading to hallucinated parts or missed unusual parts) is not investigated.
- Interaction dynamics: Effects of click ordering, spatial distribution of clicks, and increasing number of prompts beyond 10, on convergence/accuracy, are not analyzed.
- Multi-object and scene-level segmentation: Method is evaluated on single-object assets; extension to scenes with multiple interacting objects, clutter, or occlusions is unexplored.
- Articulated and hierarchical parts: Handling of articulated/functional components and hierarchical part structures (parent–child relationships) is not addressed.
- Reproducibility of 2D guidance pipeline: Critical components (e.g., exact image encoder for guidance tokens, guidance rendering protocol) are not specified in enough detail for faithful reproduction.
- Fairness of comparisons: Baselines differ in training data scale and supervision; controlled comparisons with matched training budgets/datasets are missing.
- Safety and bias: Potential biases inherited from the generative prior (e.g., object-category biases, style biases) and their effects on segmentation fairness are not analyzed.
Practical Applications
Immediate Applications
The following applications can be deployed now using SegviGen as described (pretrained on textured 3D assets, interactive point prompts, full segmentation, and optional single-view 2D map guidance). Each item names sectors, potential tools/products/workflows, and feasibility assumptions.
- 3D content creation and DCC pipelines (software, media/entertainment, gaming)
- What you can do:
- One-click to few-click part selection for precise mask creation with sharp boundaries for meshes; batch full segmentation of model libraries.
- Part-aware editing and material swaps; non-destructive edits scoped to parts; UV- and texture-preserving edits.
- Faster rigging and skinning workflows by exporting per-part masks or selection sets.
- Tools/products/workflows:
- Blender/Maya/3ds Max plugin: “SegviGen Part Colorizer” (interactive point prompts, export to vertex groups/face sets/material IDs).
- CLI/daemon for batch segmentation of asset repositories; export as per-part materials or mesh splits.
- Unreal/Unity editor extension to expose “toggle parts,” material variation packs, and LOD-specific part controls.
- Assumptions/dependencies:
- Input assets are textured meshes similar to Objaverse domain; omni-voxel/SC-VAE encoder available.
- GPU for inference (e.g., 12-step sampling ~2–3 s on A800-class GPU; slower on consumer GPUs).
- Post-processing (e.g., remeshing, watertight splitting) may be needed for 3D printing or physics-ready assets.
- Interactive 3D editing with downstream tools (software, media)
- What you can do:
- Use SegviGen to isolate target parts and pass masks to 3D editing models (e.g., VoxHammer) for localized stylization, inpainting, or texture synthesis.
- Tools/products/workflows:
- “Mask-and-edit” pipeline: clicks → SegviGen part mask → invoke texture/geometry editor → preview/render.
- Assumptions/dependencies:
- Downstream editor supports mask ingestion; consistent coordinate frames.
- UI integration for point-prompt input.
- 2D-to-3D guided segmentation for controllable granularity (software, media, education)
- What you can do:
- Specify a desired part granularity or label palette in a single 2D view (from SAM/Photoshop) and lift it to 3D-consistent part segmentation.
- Tools/products/workflows:
- “2D-guided 3D parsing” panel: import a 2D segmentation map; SegviGen enforces 3D-consistent parts and exports masks/material IDs.
- Assumptions/dependencies:
- A reasonable 2D guidance map; consistent camera/view for the guidance.
- Cross-attention encoder for image tokens as in the paper.
- Asset repository organization and monetization (e-commerce, digital marketplaces, DAM)
- What you can do:
- Auto-tag parts (e.g., “handle,” “wheel,” “screen”) via clustering/labeling on consistent per-part segments across a library.
- Enable end-user configurators: toggle components, recolor parts, offer variant packs derived from part masks.
- Tools/products/workflows:
- Cloud API: “Segment-on-upload” for model marketplaces; generate thumbnails with highlighted parts; per-part material variants.
- Assumptions/dependencies:
- Optional light human-in-the-loop mapping of colors to canonical names; taxonomy alignment varies across product categories.
- Reverse engineering for hobbyist 3D printing and maker projects (daily life, education)
- What you can do:
- Scan an object, reconstruct a textured mesh, segment parts, and export printable components or repair pieces.
- Tools/products/workflows:
- Pipeline: mobile/handheld scan → mesh reconstruction (e.g., Instant-NGP/photogrammetry) → SegviGen full segmentation → part extraction and meshing → slicer.
- Assumptions/dependencies:
- Good-quality reconstruction with texture; additional mesh cleanup for printability (watertightness, thickness).
- Rapid annotation and dataset bootstrapping (academia, software)
- What you can do:
- Reduce 3D part-annotation costs using interactive clicks or 2D-guided maps; generate strong pseudo labels with sharper boundaries.
- Tools/products/workflows:
- Active-learning annotation UI: annotator clicks → SegviGen mask → quick correction → export; batch pre-labeling of datasets.
- Assumptions/dependencies:
- Domain similarity between target data and pretraining data; simple correction tools for boundary edits.
- Virtual staging and AR/VR asset customization (media, retail)
- What you can do:
- Expose part-level customization in AR viewers (recolor, hide/show, swap materials) without manual authoring.
- Tools/products/workflows:
- Web viewer integration: precompute per-part masks; enable runtime toggles and dynamic materials.
- Assumptions/dependencies:
- Web-friendly mesh sizes; mask data embedded as metadata or separate glTF extras.
- Digital heritage and museum asset preparation (culture sector)
- What you can do:
- Segment scanned artifacts into functional/semantic parts to support restoration planning and 3D-printed replicas.
- Tools/products/workflows:
- Conservation pipeline: scan → SegviGen segmentation → per-part damage assessment and restoration notes.
- Assumptions/dependencies:
- Scans with sufficient texture; curator validation for semantic correctness.
- Policy and governance support for evaluation and procurement (policy, public sector)
- What you can do:
- Establish practical evaluation criteria for 3D segmentation tools used in public digitization projects (accuracy, boundary fidelity, data efficiency).
- Tools/products/workflows:
- Procurement checklists and test suites using public benchmarks (e.g., PartObjaverse-Tiny, PartNeXT) and IoU@k-click KPIs.
- Assumptions/dependencies:
- Access to representative sample assets from target domains; repeatable test hardware.
Long-Term Applications
These applications require additional research, domain adaptation, robustness improvements, scaling, or integration effort before broad deployment.
- Robotics manipulation, assembly, and disassembly (robotics, manufacturing, maintenance)
- What you could do:
- Use part segmentation to identify graspable subcomponents, isolate fasteners, and plan disassembly/assembly sequences with minimal supervision.
- Tools/products/workflows:
- ROS node integrating multi-view reconstruction → SegviGen segmentation → grasp/trajectory planner conditioned on parts.
- Assumptions/dependencies:
- Reliable on-the-fly textured mesh reconstruction in cluttered, occluded scenes; robustness to lighting and motion; near real-time inference on edge hardware; training on industrial/mechanical object distributions.
- CAD-native design and inspection (manufacturing, engineering)
- What you could do:
- Bridge from mesh segments to CAD/B-Rep features; automate feature recognition and tolerance checking; map segments to BOM components.
- Tools/products/workflows:
- “Mesh-to-CAD assistant”: SegviGen masks → surface fitting and feature recovery → CAD feature tree suggestions; QA pipeline comparing scanned parts to design intent per segment.
- Assumptions/dependencies:
- Accurate conversion from meshes to parametric surfaces; domain adaptation to mechanical parts with sharp edges, thin features; robust metrology-grade accuracy.
- Scene-level, multi-object, and dynamic/temporal part parsing (software, robotics, digital twins)
- What you could do:
- Segment parts within full scenes and track them through time for simulation, physics, and state estimation (e.g., opening drawers, moving joints).
- Tools/products/workflows:
- 4D generative segmentation (spatio-temporal latent); scene graph extraction with part hierarchies and articulation.
- Assumptions/dependencies:
- Training on large-scale scene datasets with part annotations and motion; handling occlusions and multi-object interactions.
- Language-grounded part understanding (software, education, robotics)
- What you could do:
- Query and segment parts via natural language (“select the heat sink fins”), or align parts to ontology labels for explainable robotics and training content.
- Tools/products/workflows:
- Multimodal interface: LLM + SegviGen features + retrieval across part libraries; teach-in workflows linking terms to parts.
- Assumptions/dependencies:
- Joint training with language-vision-3D corpora; consistent part taxonomies; grounding in specialized domains.
- Healthcare and biomedical modeling (healthcare)
- What you could do:
- Segment anatomical 3D meshes (e.g., patient-specific organ models) or device components to aid preoperative planning and implant customization.
- Tools/products/workflows:
- Surgical planning UI: quick part isolation and measurement; device-part segmentation for multi-component implants.
- Assumptions/dependencies:
- Domain-specific training on medical 3D data; adaptation from textured meshes to volumetric/CT/MRI data or surface meshes without texture; regulatory validation.
- Standardization and interoperability of part taxonomies (policy, industry consortia)
- What you could do:
- Establish open standards for part-level labels, hierarchies, and metadata to enable cross-tool workflows and consistent evaluation.
- Tools/products/workflows:
- “Colorization-as-label” interchange spec for glTF/USD; benchmark suites and governance processes across domains (consumer goods, automotive, aerospace).
- Assumptions/dependencies:
- Multi-stakeholder alignment; mapping between existing taxonomies; testbeds with public assets.
- On-device and real-time segmentation for AR wearables and mobile (consumer tech)
- What you could do:
- Allow users to interactively segment and edit parts of objects in mobile AR apps for customization, education, or repair guidance.
- Tools/products/workflows:
- Distilled/lightweight SegviGen variants; hardware-accelerated inference; streaming to edge/cloud when needed.
- Assumptions/dependencies:
- Efficient encoders for mobile SoCs; fast online reconstruction; low-latency networking for hybrid edge-cloud execution.
- Automated assembly and digital twin maintenance (manufacturing, energy)
- What you could do:
- Maintain live part-level digital twins of equipment; detect missing/damaged components; support predictive maintenance with part-level telemetry.
- Tools/products/workflows:
- Plant-scale pipeline: periodic scans → segmentation → part-state tracking → alerts and work orders tied to a CMMS.
- Assumptions/dependencies:
- Robust scanning schedules; integration with enterprise systems; high reliability in challenging environments (dust, reflections).
Cross-cutting assumptions and risk considerations
- Domain shift: The reported performance is on textured consumer-style meshes (Objaverse-like). Industrial CAD, mechanical parts, medical, and outdoor scans will require fine-tuning and possibly different encoders.
- Geometry quality: Segmentation is performed on a geometry-aligned reconstruction; poor reconstructions (holes, noise, low texture) degrade results and may require cleanup.
- Labeling and taxonomy: Color-as-label requires post-hoc mapping from colors to names; taxonomy consistency is nontrivial across datasets and sectors.
- Compute and latency: Reported timings use A800 GPUs and ~12 denoising steps; real-time or mobile deployment needs model compression/distillation.
- Post-processing: For downstream manufacturing/printing, additional steps (watertight partitioning, remeshing, manifold checks) are often necessary.
- IP and licensing: Training/usage of 3D assets must comply with licenses; outputs may inherit attribution requirements in some repositories.
Glossary
- 2D segmentation map–guided full segmentation: A segmentation mode where the 3D model is conditioned on a provided 2D segmentation map to control part granularity and labels. "2D segmentation mapâguided full segmentation is uniquely enabled by SegviGen"
- 2D-to-3D distillation: Supervising a 3D model using signals distilled from 2D models to transfer knowledge into 3D. "optimize 3D segmentation via 2D-to-3D distillation"
- 2D-to-3D lifting: Transferring segmentation priors from 2D images to 3D (e.g., via projection/fusion) to produce 3D masks. "transfer the comprehensive 2D segmentation priors to 3D via 2D-to-3D lifting."
- AdamW optimizer: An optimization algorithm with decoupled weight decay that improves training stability and generalization. "We adopt the AdamW optimizer~\cite{adamw}"
- Back-projection: Projecting 2D masks back onto 3D geometry to reconstruct 3D masks from multi-view predictions. "which are then back-projected and fused into 3D masks."
- CLIP-like embedding space: A joint vision-language embedding space modeled after CLIP, used for similarity-based part queries. "aligned to a CLIP-like embedding space"
- Conditional flow matching: A generative training objective that learns a vector field to transport noise to data under conditioning signals. "Training follows the conditional flow-matching objective"
- Cross-attention: An attention mechanism that conditions one sequence of tokens on another (e.g., image guidance tokens). "injected via cross-attention:"
- Cross-view inconsistencies: Discrepancies among predictions from different camera views that degrade 3D fusion quality. "cross-view inconsistencies"
- Diffusion Transformer (DiT): A transformer architecture used to parameterize denoising in diffusion-like generative models. "a diffusion transformer (DiT)~\cite{peebles2023dit} to perform denoising over compact latents"
- Domain gap (2D–3D): Systematic differences between 2D and 3D data distributions that hinder transfer of learned features. "2D--3D domain gap"
- Geometry-aligned reconstruction: A reconstruction where feature representations are aligned with the underlying 3D geometry to preserve structure. "active voxels of a geometry-aligned reconstruction."
- Intersection over Union (IoU): A metric measuring the overlap between predicted and ground-truth masks, used to assess segmentation accuracy. "using IoU to measure the accuracy of overall mask predictions."
- Linear interpolants: Linear paths between Gaussian noise and data latents used to define training trajectories in flow matching. "matching the constant velocity along linear interpolants:"
- Multi-task flow transformer: A flow-based transformer backbone conditioned to handle multiple tasks within a single model. "the multi-task flow transformer predicts the noise residual for flow-matching training."
- Multi-view mask aggregation: Combining masks from multiple rendered views and fusing them into a consistent 3D segmentation. "multi-view mask aggregation"
- Non-canonical part decompositions: Part segmentations that do not follow a fixed taxonomy or standard labeling scheme. "arbitrary, non-canonical part decompositions."
- Non-maximum suppression (NMS): A post-processing technique that removes redundant, overlapping masks or detections. "merging redundant masks with NMS."
- nvdiffrast: A GPU-based differentiable rasterizer used to render 2D guidance maps from 3D assets. "rendered via nvdiffrast or derived from a 2D segmenter"
- Omni-voxel (O-Voxel): A structured sparse voxel representation that jointly encodes geometry and appearance per active voxel. "an omni-voxel sparse voxel representation (O-Voxel)"
- Open-world part segmentation: Segmenting parts without a closed label set, enabling generalization to unseen categories or part definitions. "open-world part segmentation"
- Physically-based material attributes: Material parameters (e.g., roughness, reflectance) used in PBR, modeled jointly with geometry. "encoding physically-based material attributes jointly with geometry"
- Promptable 2D models: 2D segmentation models that accept prompts (e.g., points/boxes) to generate masks. "promptable 2D models"
- Pseudo-labels: Automatically generated labels used as supervision when ground truth is unavailable. "transferred 2D representations or pseudo-labels"
- Render-and-lift pipeline: Rendering multi-view images, segmenting them in 2D, and lifting the results back into 3D. "A common strategy adopts a render-and-lift pipeline:"
- RoPE (Rotary Positional Embedding): A positional encoding that rotates query/key vectors to encode relative positions in attention. "encoded by RoPE within the attention layers"
- SC-VAE (Sparse Compression VAE): A variational autoencoder that compresses sparse 3D voxel features into compact structured latents. "a Sparse Compression VAE (SC-VAE) maps each voxelized asset feature tensor"
- Sinusoidal encoding: A positional encoding using sine and cosine functions to represent discrete indices or positions. "A sinusoidal encoding is first computed from "
- SparseTensor: A sparse tensor data structure that stores feature values together with their explicit coordinate indices. "the coordinate indices of the SparseTensor"
- Task embedding: A learned vector that encodes task identity and is injected into the model to enable multi-task behavior. "task identity is encoded as a continuous embedding"
- Tex-SLAT flow model: The texture-structured latent flow module in Trellis.2 that performs flow-based denoising for textures. "the Tex-SLAT flow model is trainable"
- Trellis.2: A native 3D generative framework providing structured latents for geometry and texture. "We adopt Trellis.2~\cite{trellis2} as our base model"
- Variational Autoencoder (VAE): A generative model that encodes data into a latent distribution and decodes it to reconstruct inputs. "a variational autoencoder~\cite{kingma2013vae}"
- Voxel (active voxels): Volumetric grid cells representing space; active voxels are those occupied by or relevant to the 3D asset. "a sparse set of active voxels on a regular grid"
Collections
Sign up for free to add this paper to one or more collections.