- The paper demonstrates that AI research agents predominantly generate ideas close to seed literature, indicating narrower exploration than human work.
- It applies quantitative measures such as cosine similarity and PCA clustering to compare AI-generated outputs with human-authored research.
- Findings reveal that AI agents favor method recombination over genuine question innovation, potentially limiting disruptive scientific advances.
AI Research Agents and the Concentration of Scientific Exploration
Introduction
The proliferation of AI research agents, equipped with LLM-driven scaffolds for ideation, experiment design, and paper drafting, raises critical questions regarding their impact on the diversity and directionality of scientific progress. Despite explicit prompting for high novelty and disruptive ideation, the extent to which these frameworks genuinely broaden the landscape of scientific inquiry remains empirically unresolved. "AI Research Agents Narrow Scientific Exploration" (2605.27905) systematically evaluates this issue by generating 37,802 research ideas across 19 citation-defined AI/ML research areas, spanning four major agentic frameworks and six LLM architectures. The paper rigorously quantifies exploration breadth, semantic distance from seed literature, associated impact via citation analysis, and the locus of novelty in generated ideas. The core assertion is that current AI research agents predominantly facilitate local elaboration—producing concentrated, literature-adjacent outputs—rather than stimulating wide-ranging or disruptive exploration.
Methods and Experimental Design
The study constructs a comprehensive experimental protocol leveraging papers from ICLR, NeurIPS, and ICML (2019–2025), forming 19 active research areas via bibliographic coupling. For each area, multiple five-paper seed sets are sampled as context, aligning with LLM context window capacities. Four representative agent scaffolds, including zero-shot prompting, AIScientist, ResearchAgent, and AgentLaboratory, are benchmarked against six LLMs (Qwen, Llama, and Gemma families). Each agent is explicitly prompted for novelty (“novel,” “high-impact,” “very innovative and unlike anything seen before”), isolating the effect of agentic protocol rather than prompt design.
Scientific ideas are decomposed into normalized research question/method tuples using LLM-based extraction, mapped into a shared semantic embedding space (Qwen3-Embedding-4B). Quantitative analyses encompass within-area pairwise similarity, centroid-based concentration, cosine distance to seed literature, alignment with follow-on human-authored work, citation impact of matched human analogs, and the novelty locus (research question vs. method recombination).
The protocol robustly covers temporal, agentic, and architectural axes, supporting systematic ablation across frameworks, years, and scaling regimes.
Concentration of AI-Generated Scientific Ideas
A principal result is the pronounced semantic concentration of AI-generated ideas relative to human-authored papers within identical research areas. Pairwise cosine similarity among AI outputs (~0.82–0.84) exceeds that for human-authored research (0.77), indicating reduced variance and narrower distribution in explored directions. This concentration persists across all agent frameworks and LLM backends, as confirmed via centroid distance analyses (mean distance: 0.091 for AI vs. 0.121 for human work).
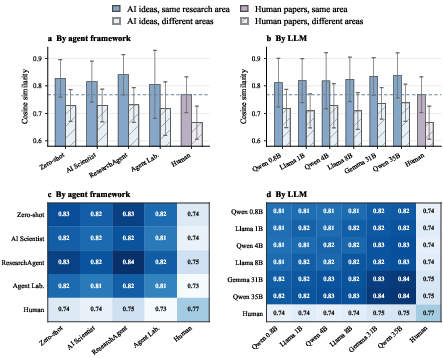
Figure 1: AI-generated ideas exhibit higher within-area pairwise similarity, indicating greater concentration compared to human-authored papers.
Notably, cross-agent and cross-model similarities are comparably high, suggesting that neither increased agentic sophistication nor model scaling fundamentally broadens the diversity of outputs. Human-generated research, by contrast, maintains a lower similarity baseline and occupies a measurably more dispersed semantic region.
Proximity to Seed Literature
AI agents consistently generate ideas that remain close—both lexically and semantically—to the seed corpus from which they are primed. The mean cosine similarity between AI idea embeddings and seed paper embeddings is 0.92, whereas later follow-on human-authored works, citing the same seeds, diverge more substantially (similarity 0.88). Semantic comparison with follow-on human research yields even lower alignment (0.82), demonstrating that humans more frequently traverse outwards from the seed region, even when conditioned on identical literature.
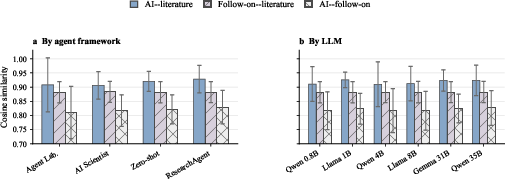
Figure 2: Cosine similarity demonstrates that AI ideas remain more proximate to their seed literature than follow-on human-authored papers.
PCA projections further visualize this phenomenon, with AI ideas forming dense clusters adjacent to the five-paper anchor, while human follow-ons scatter more broadly and in orthogonal directions.
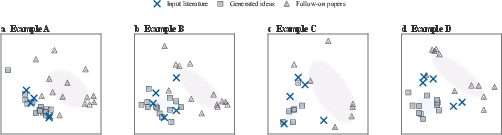
Figure 3: PCA plots show tighter clustering of AI ideas near starting literature, in contrast to dispersed, exploratory follow-on human work.
Scientific Impact Evaluation
To probe whether the output region favored by AI agents corresponds to higher-impact scientific content, the authors match AI-generated ideas to published human-authored papers in the same area with cosine similarity >0.9. Citation analysis reveals that these matched human works accrue, on average, 4–8 fewer citations than their respective area/year baselines, a statistically significant disadvantage for most agentic scaffolds. This result underscores that the regions in semantic space favored by AI agents are, empirically, less likely to be scientifically influential, challenging the implicit assumption that concentrating on literature-adjacent outputs offers optimal ground for high-impact propositions.
Nature of Novelty: Question versus Method Recombination
A crucial analytical dimension is the source of novelty in AI-generated ideas. The study separates the introduction of new research questions from recombinations of technical methods. In 85.1% of cases, AI-generated research questions are already present in the seed context, indicating minimal framing innovation. Conversely, only 62.6% of technical methods are present in the seed, demonstrating a higher rate of method recombination than question reframing.
This asymmetry is consistent across agent frameworks and robust to reasonable shifts in the semantic matching threshold. The implication is that novelty, when present, is almost exclusively method-level (algorithmic or architectural recombination), rather than the generation of genuinely new research problem formulations.
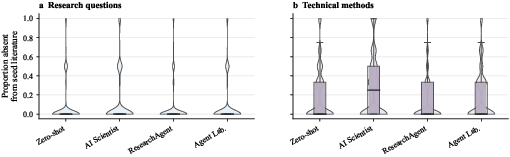
Figure 4: Violins quantify that AI-generated novelty arises predominantly from technical method recombination, not from research question innovation.
Implications and Future Directions
The aggregated findings indicate that, despite explicit prompts and architectural advances in agentic scaffolding, current AI research agents favor localized exploration and exhibit limited capacity to broaden the scientific landscape. The stability of this behavior across scale and agent protocol suggests an inductive bias imposed by present LLM pretraining distributions and agent orchestration schemas, which structurally prefer literature-adjacent, method-recombinative outputs over the introduction of uncharted research questions or deep cross-domain exploration.
From a systems perspective, these results call into question the sufficiency of current prompting and agentic decomposition strategies for stimulating disruptive scientific ideation. There are practical implications for scientific workflows: pervasive integration of AI agents in research ideation pipelines risks an entrenchment of established paradigms, potentially crowding out high-risk, high-reward directions often associated with transformative discoveries.
Theoretically, the work highlights an urgent need to investigate new scaffolding, reward signal shaping, or meta-cognitive mechanisms for agentic systems—approaches that might better emulate the cognitive foraging and reframing behaviors characteristic of human scientific innovation. Future research may explore agent collectives with explicit epistemic diversity incentives, curriculum designs promoting exploration of semantically distant knowledge clusters, or adaptive memory architectures that counteract the anchoring effects intrinsic to large-scale pretrained models.
Conclusion
"AI Research Agents Narrow Scientific Exploration" provides comprehensive empirical evidence that agentic LLM-driven frameworks produce semantically concentrated, literature-adjacent research ideas, favoring method-level recombination over research question innovation. These findings are robust to agentic protocol, model scaling, and explicit novelty prompting. This suggests that current AI research agents, while effective at local elaboration and synthesis, lack mechanisms required to simulate the broader exploratory thrust of human scientific creativity. Bridging this gap remains a critical open problem as AI becomes increasingly integrated into the knowledge production pipeline.

