- The paper introduces SOLANET, a novel framework that scales GPU-accelerated kNN graph construction to billion-point datasets using distributed and lock-free approaches.
- The methodology partitions data across GPUs, employs a lock-free NN-Descent algorithm, and uses binary-tree-structured refinement to optimize communication and computation.
- Experimental results show significant speedups (up to 11.7x) and high graph quality (recall@32 above 99%), highlighting SOLANET's potential for large-scale AI and data analytics.
SOLANET: Scalable Distributed GPU-Accelerated Neighbor Graph Construction
Introduction and Motivation
Approximate k-nearest neighbor graphs (kNNGs) are foundational in high-dimensional data analysis, vector databases, clustering, and modern AI workloads including LLM retrieval-augmentation and large-scale recommendation systems. As vector and embedding datasets grow to billions of items and high dimensions, the shortcomings of single-node and single-GPU solutions become significant. The construction of kNNG at this scale presents unique challenges: super-linear time complexity, irregular computation and communication, massive memory footprints, and the necessity for hardware and communication-aware distributed implementations.
SOLANET introduces a distributed, GPU-accelerated neighbor graph construction toolkit that specifically targets these issues, designed and evaluated on contemporary heterogeneous high-performance computing systems with AMD MI300A APUs. Core design elements include partitioned local graph induction, distributed cross-partition refinement via high-throughput approximate nearest neighbor (ANN) search, and lock-free local graph update algorithms. The framework leverages advanced communication primitives (MPI one-sided operations) and is decoupled from local ANN backend implementations.
Methodological Contributions
Distributed kNNG Construction Framework
SOLANET decomposes neighbor graph construction for large-scale data into two main phases:
- Local Graph Construction: The input dataset D is partitioned into P subsets, each processed on a separate GPU/MPI rank. Each partition forms an initial local kNNG using a GPU-optimized NN-Descent algorithm.
- Cross-Partition Refinement: To recover neighbor edges across partitions, each rank fetches remote graphs and datasets using high-bandwidth, low-latency MPI one-sided gets, executes batched graph-based ANN search, and updates its local kNNG with new candidates.
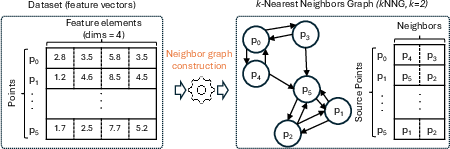
Figure 1: High-level depiction of local and distributed stages in nearest neighbor graph construction.
This design ensures strong arithmetic intensity, regular and coarse-grained communication, and natural support for asynchronous overlap of communication and computation. By abstracting the local graph construction and search algorithms, SOLANET can adapt to improvements in single-GPU ANN methods.
Lock-Free GPU NN-Descent
The local NN-Descent implementation for AMD GPUs eschews the traditional global memory locks for candidate list updates. Instead, it employs atomic append operations to per-point candidate buffers, followed by thread-serialized graph updates—maximizing parallel efficiency and mitigating serialization bottlenecks known to afflict prior lock-based GPU implementations.
Binary-Tree-Structured Distributed Refinement
To achieve scalability beyond all-to-all refinement—where communication and search costs saturate early—SOLANET introduces a hierarchical, binary-tree-structured merge pattern for subgraph refinement. At each level, datasets and graphs from groups of ranks are merged, and cross-group ANN search is executed, reducing both the number of refinement steps and data movement volume per refinement phase. This approach underpins the high scalability demonstrated, particularly for billion-scale graphs.
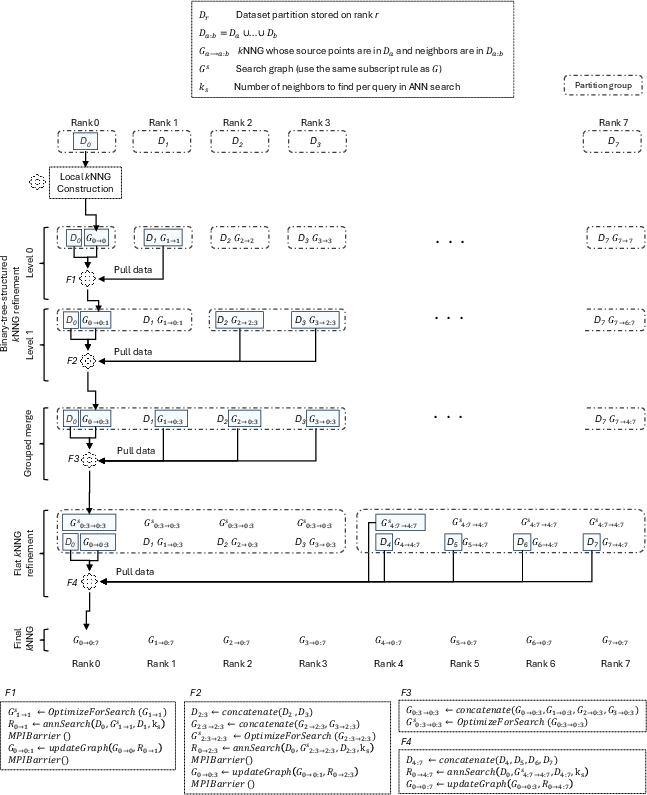
Figure 2: Execution pipeline of ANN search-based distributed kNNG refinement with hierarchical (tree-based) merging.
Experimental Evaluation
Evaluation is conducted on LLNL's Tuolumne cluster, incorporating up to 512 AMD MI300A APUs. SOLANET is tested across diverse datasets, from Fashion-MNIST and GIST to DEEP-1B, SIFT-1B, and synthetic DEEP-2B, up to 2 billion points.
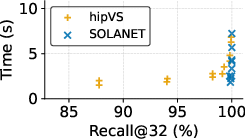
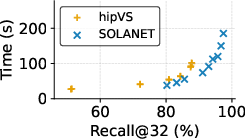
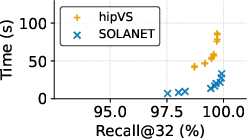
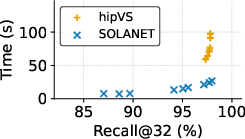
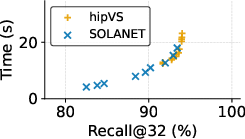
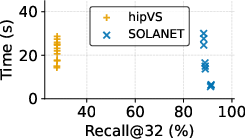
Figure 3: Visualization and characteristics of the Fashion-MNIST dataset as used in evaluation.
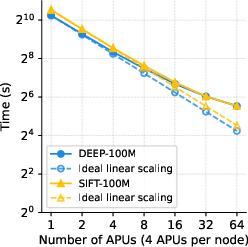
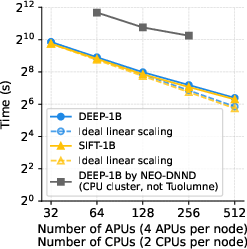
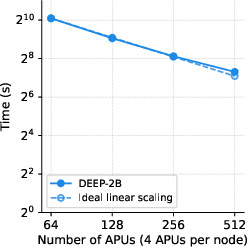
Figure 4: Schematic of DEEP-100M and SIFT-100M billion-scale datasets.
Key findings include:
- The lock-free single-GPU implementation consistently outperforms hipVS (itself state-of-the-art for AMD) in both construction time and recall across nearly all datasets, except NYTimes.
- The distributed engine exhibits near-linear strong scaling up to the point where per-partition size falls below computational saturation or communication overheads dominate. For DEEP-1B and SIFT-1B, SOLANET achieves 11x–11.7x speedup scaling from 32 to 512 APUs, and for DEEP-2B, 6.9x from 64 to 512 APUs.
- Compared to NEO-DNND, a distributed CPU-based NN-Descent, SOLANET provides an 8.3x runtime reduction at competitive recall for billion-scale inputs.
- Graph quality remains high, with recall@32 above 99% for L2 benchmarks. NEO-DNND graphs used as a reference yield 70–75% recall when compared against SOLANET’s output, whereas SOLANET reaches 99% compared to NEO-DNND, demonstrating both accelerated runtime and improved neighbor accuracy.
Runtime and Scalability Analysis
The authors provide formal runtime complexity estimates, factoring in both computation (ANN search and local kNNG construction) and communication (latency and bandwidth), exploiting empirical findings that ANN search time at fixed k0 is largely insensitive to the number of source points due to the search radius's boundedness in graph traversal and optimization. The hierarchical merge pattern and group-wise flat refinement minimize redundant data pulls and maximize communication efficiency, critical for practical scaling on modern supercomputers.
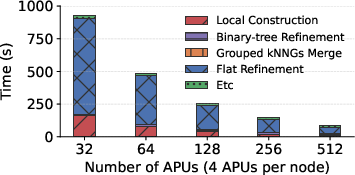
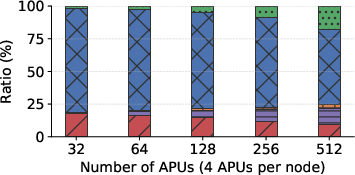
Figure 5: Absolute execution time breakdown across distributed phases for the DEEP-1B dataset.
Implications and Future Directions
SOLANET advances neighbor graph construction methodology by introducing GPU-accelerated, distributed design tailored to the demands and properties of billion-point, high-dimensional workloads. From a practical standpoint, this enables real-time or near-real-time construction of high-quality neighbor graphs for retrieval, clustering, and embedding similarity computation at a scale previously not accessible without custom or disk-based solutions.
Theoretically, the architecture decouples distributed strategies from the specifics of ANN backends, allowing transparent exploitation of future improvements in GPU graph search and construction. The lock-free approach and communication-optimized refinement outline a general paradigm for future large-scale distributed similarity indexing beyond ANN, including non-Euclidean or nonmetric similarities.
Future research opportunities include integration with additional ANN algorithms, adaptation to NVIDIA accelerators, and intelligent partitioning schemes exploiting domain semantics to further reduce cross-partition refinement.
Conclusion
SOLANET establishes new standards for scalable, distributed k1NNG construction on GPU-accelerated platforms. Through architectural innovations in communication, lock-free concurrency, and graph refinement, it demonstrates both superior empirical scaling and graph quality on billion-scale vector workloads. This toolkit provides a high-performance foundation for a host of contemporary AI and data-intensive applications, directly supporting the growth and increasing complexity of scientific and industrial vector analytics.