- The paper introduces a modular zero-shot 3D visual grounding pipeline that leverages LVLMs and LLMs for geometric reasoning and object localization.
- It employs a two-stage process with offline segmentation and online agent planning, achieving higher accuracy on ScanRefer and Nr3D benchmarks.
- The approach enhances interpretability and efficiency via deterministic spatial scoring and adaptive on-demand rendering to resolve ambiguous views.
AgentGrounder: Zero-Shot 3D Visual Pointcloud Grounding with Multimodal Language Agents
Problem Setting and Challenges
3D Visual Grounding (3DVG) is a core task for embodied AI, where agents must localize objects in 3D scenes using natural language queries. Traditional 3DVG frameworks are predominantly supervised, relying on large annotated datasets with paired language and bounding box labels. This approach limits flexibility for scaling to unseen categories and open-vocabulary scenarios due to annotation cost. Zero-shot methods alleviate this constraint by leveraging pretrained vision-LLMs (VLMs) and LLMs, but existing pipelines suffer from brittle anchor-target matching, inefficient visual inspection, and underutilization of geometric scene relations.
AgentGrounder introduces a zero-shot 3DVG pipeline that operates directly on colored point clouds, forgoing task-specific 3D training and employing a tool-driven agent architecture. The pipeline's explicit planning, selective retrieval, deterministic geometric reasoning, and adaptive image rendering address key design limitations of prior work.
System Architecture and Pipeline
The framework consists of two principal stages: offline segmentation and online agent-driven reasoning. Initially, Mask3D is used for 3D instance segmentation on the input point cloud, producing semantic masks, bounding box geometry, and instance IDs. These are structured into an Object Lookup Table (OLT) enabling efficient metadata retrieval.
The agent uses a multimodal LVLM (Qwen3-VL-32B-Instruct) to decompose each language query, retrieve relevant candidate objects from the OLT by semantic label, compute spatial relations (nearest/farthest, left/right, below), and selectively invoke a rendering tool for view-dependent or visually ambiguous queries. The agent outputs a structured rationale capturing the chosen object, bounding box, and justification.
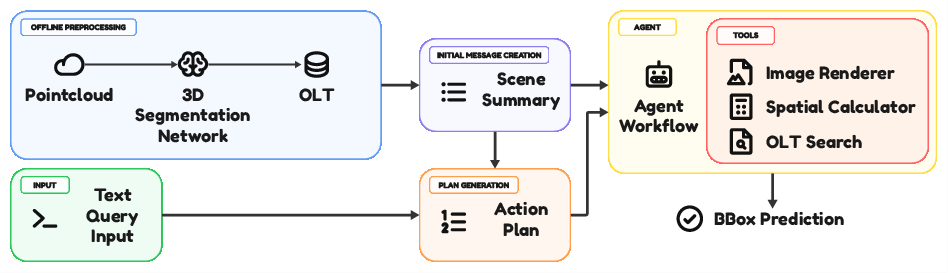
Figure 1: AgentGrounder pipeline: explicit agent planning, candidate retrieval from the Object Lookup Table, deterministic geometric reasoning, and adaptive view-dependent image rendering.
This design eliminates the early anchor-target matching failures seen in SeeGround, ensures efficient use of LVLM context windows, and promotes transparent, explainable grounding.
Experimental Results and Numerical Analysis
Evaluation on ScanRefer and Nr3D benchmarks highlights AgentGrounder's superior performance in zero-shot 3DVG:
- ScanRefer: Achieves [email protected] of 41.9 (+2.5% vs. SeeGround) overall, with 73.7 [email protected] (+4.8%) on Unique queries and 31.7 (+1.7%) on Multiple queries.
- Nr3D: Reaches overall accuracy of 52.4 (+6.3% vs. SeeGround), with consistent gains across Easy/Hard splits (59.6/45.4) and both viewpoint-dependent (47.9) and viewpoint-independent (54.5) scenarios.
The performance boost is particularly pronounced in view-independent queries, underscoring the impact of deterministic geometric scoring. Improvements on Hard and Multiple subsets indicate enhanced robustness to distractors and fine-grained spatial reasoning.

Figure 2: Comparative results showing AgentGrounder's consistent improvements over SeeGround across multiple splits and accuracy metrics.
Ablation studies further dissect the agent's toolset. Incremental enabling of retrieval, geometric reasoning, explicit planning, and on-demand rendering demonstrate complementary gains. Notably, rendering is essential for resolving viewpoint-sensitive ambiguities, while deterministic spatial scoring is the main driver for distractor resolution.
Theoretical and Practical Implications
From a theoretical perspective, AgentGrounder advances zero-shot 3D grounding by integrating explicit geometric reasoning and agentic planning, moving away from end-to-end neural pipelines in favor of modular, tool-oriented orchestration. The transparent, tool-driven logic facilitates interpretability, robustness, and reduces cascading errors intrinsic to fixed matching designs.
Practically, the system is well-suited for open-vocabulary reasoning in data-scarce environments and generalizes to previously unseen categories. Efficient context utilization and selective visual inspection substantially reduce LVLM token overhead, improving inference throughput and cost.
Limitations include processing latency due to runtime rendering and LVLM orchestration, and dependency on segmentation quality; failed segmentations propagate unrecoverable errors downstream.
Future Directions
Two promising directions strengthen AgentGrounder's foundation for real-world deployment:
- Human-in-the-loop Clarification: Incorporating user feedback to refine ambiguous candidate selection or resolve unclear labels can mitigate rigid agent failures and enhance adaptability.
- Adaptive Toolset and Failure Mitigation: Expanding the repertoire with fallback detectors, re-segmentation, or scene-aware heuristics will address initialization failures and improve robustness across varying objects and environments.
There is potential for cross-modal synergy, incorporating audio or richer scene priors and further optimizing runtime efficiency for mobile and robotic hardware.
Conclusion
AgentGrounder demonstrates a robust, practical, and transparent approach to zero-shot 3D visual grounding by combining multimodal LVLM agents, deterministic spatial logic, and adaptive visual inspection within a modular pipeline. Numerical superiority on ScanRefer and Nr3D benchmarks, particularly in spatially ambiguous and distractor-dense scenarios, underscores the value of agentic reasoning and structured tool orchestration. The framework sets the stage for scalable, open-vocabulary 3D scene understanding and provides a solid foundation for further integration of human feedback and adaptive tool deployment.