- The paper presents black, a reinforcement learning approach that leverages action chunking and human interventions to finetune vision-language-action models with high sample efficiency.
- It decouples learning from acting, enabling effective adaptation across eight diverse robotic manipulation tasks with 100% task success in under 20 minutes of online data.
- The method outperforms prior techniques by integrating value-guided action selection and temporal abstraction, ensuring robust reliability and scalability for real-world deployment.
Sample-Efficient RL Finetuning for Vision-Language-Action Models: An Analysis of "EXPO-FT"
Overview and Motivation
The paper "EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models" (2605.25477) introduces "black," a new system for reliably and efficiently finetuning pretrained Vision-Language-Action (VLA) models via reinforcement learning (RL). VLAs—generalist policies trained with large-scale imitation learning and multimodal conditioning—have demonstrated considerable generalization across manipulation tasks. However, their deployment is hindered by suboptimal reliability in real-world settings without further adaptation. Prior RL and finetuning approaches either do not fully leverage pretrained VLAs, suffer from poor sample efficiency, or fail to achieve the high reliability necessary for practical robot deployment.
The paper addresses this gap by extending the EXPO algorithm [dong2026expostablereinforcementlearning] for RL finetuning to support action chunking and human-in-the-loop feedback, thereby enabling effective adaptation of VLAs for challenging manipulation tasks with minimal online data.
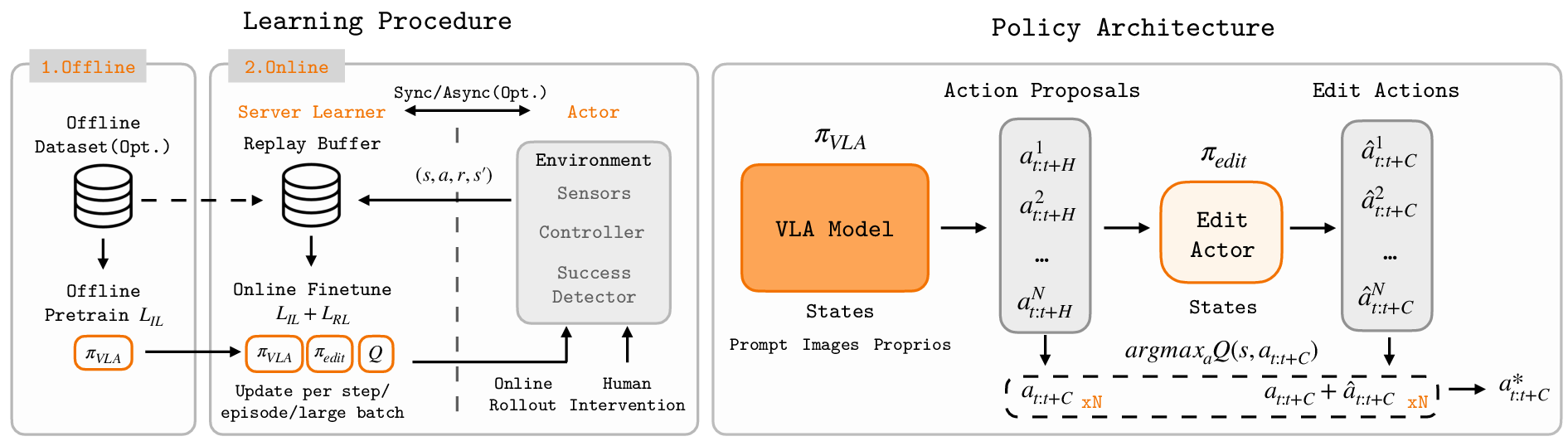
Figure 1: Architecture of black. The system decouples environment interaction from VLA training, enabling efficient RL finetuning with EXPO and action chunking.
Technical Approach
RL Finetuning with EXPO and Action Chunking
Black builds upon EXPO, an RL algorithm which operates on expressive policies such as diffusion or flow-matching models used in modern VLAs. EXPO separates policy optimization into a base flow policy (πVLA) and an edit policy (πedit) that predicts action corrections without backpropagating through the large base model. The edit policy maximizes the Q-function, and inference selects the value-maximizing action among candidates from both policies.
A key innovation in black is support for temporally extended actions (action chunks), reflecting the operational modes of VLAs, which output multi-step action sequences per timestep. The edit policy and Q-functions are extended to optimize over these chunks, substantially improving compatibility and sample efficiency.
Human-in-the-Loop Interventions
To further accelerate learning, black incorporates human-in-the-loop interventions. During training, a human operator can override actions within chunks, providing targeted corrections that are then incorporated into the replay buffer. Early intervention rates are high but decrease as the policy improves, enabling the system to bootstrap exploration and refine behaviors efficiently.
System Architecture
Black features a decoupled learner-actor interface: the learner trains the VLA and manages the replay buffer, while the actor interacts with the environment, collecting rollouts and interventions. This design addresses the computational latency associated with large VLA models, allowing synchronous and asynchronous communication for scalability.
Experimental Evaluation
Task Suite and Methodological Details
Eight real-world robotic manipulation tasks were selected, each posing distinct challenges such as contact-rich dynamics, precise alignment, deformable object handling, and randomization of initial states. Tasks include Egg Flip, String Light Routing (multiple stages), Candy Scoop, Cube Pick, Flower Insert, and Pool Shot.

Figure 2: Diverse manipulation tasks used for evaluation, spanning dexterous, precise, deformable, and dynamic manipulation.
The system utilizes a sparse binary reward and rule-based task success classifiers, with human teleoperation used for demonstration collection and interventions. Visual and proprioceptive observations are processed by both actor and critic; the critic employs a lightweight ResNet-50 backbone for efficiency.
Main Results
Black achieves perfect task completion (30/30 successes) across all tasks within an average of 19.1 minutes of online robot data. This significantly outperforms prior RL-from-scratch and VLA finetuning methods, including HG-DAgger, HIL-SERL, DSRL, and supervised finetuning baselines. Across manipulation types—dynamic, precise, deformable, large initial state randomization—black consistently yields high reliability and sample efficiency, validated through quantitative comparisons.
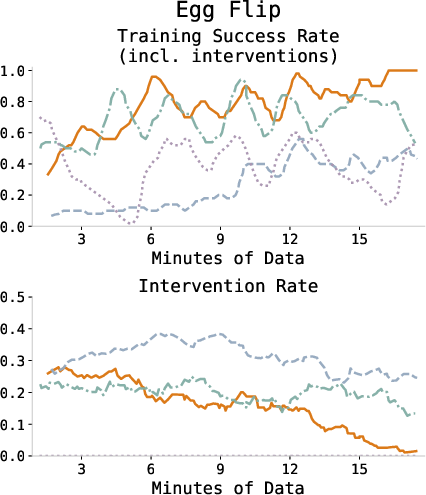
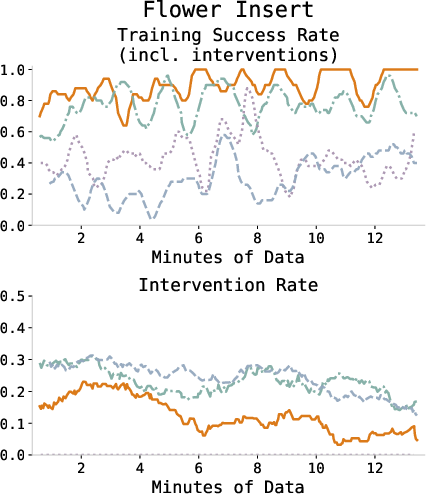
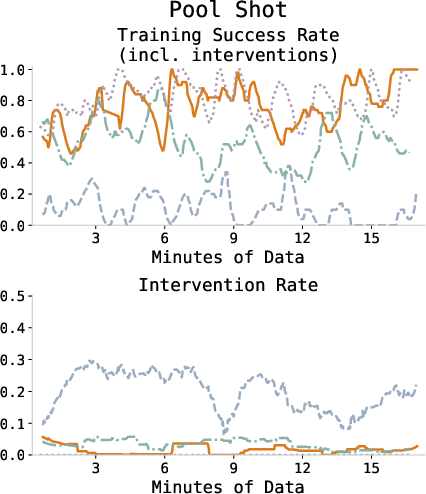
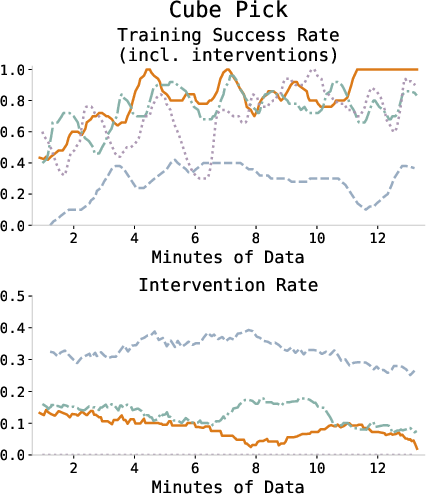
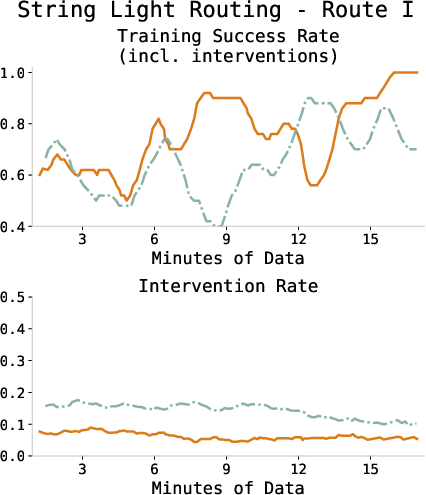
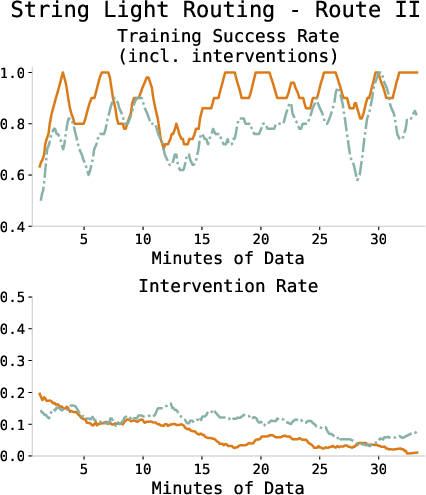
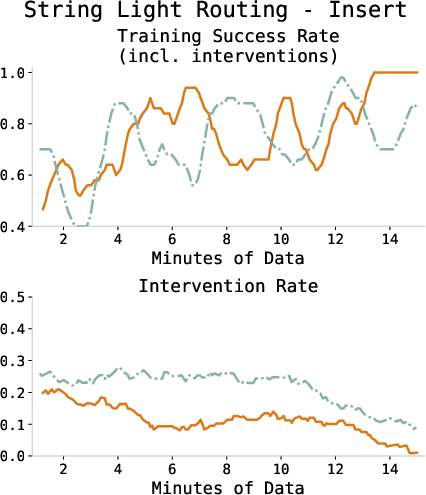
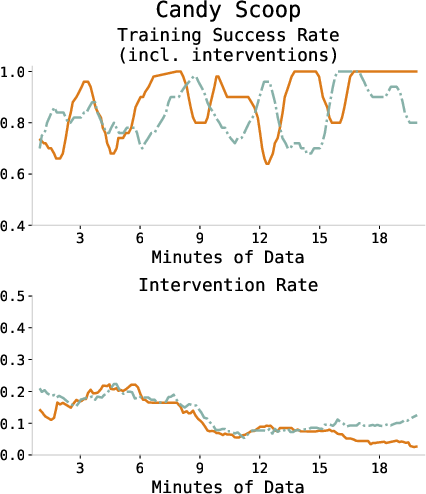

Figure 3: Training success and intervention rates across all tasks, showing consistent improvement and diminishing human intervention as the policy converges.
Robustness and Efficiency Analysis
The episode completion time consistently decreases during training, indicating more efficient policy execution and task proficiency as the agent adapts.
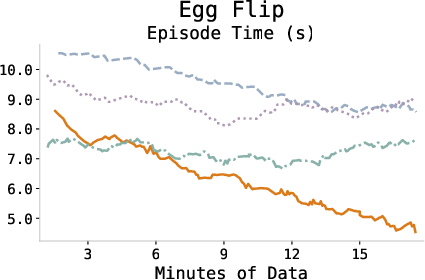
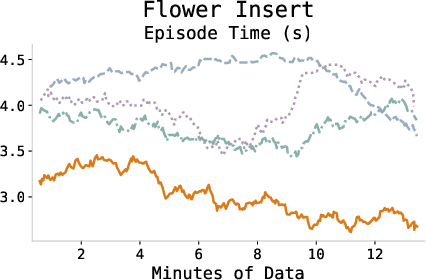
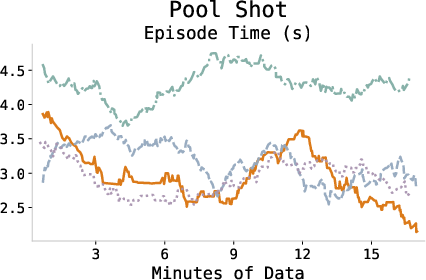
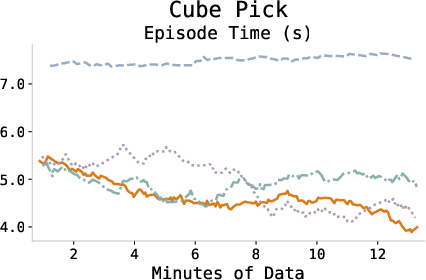
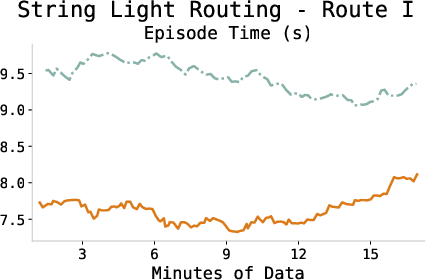
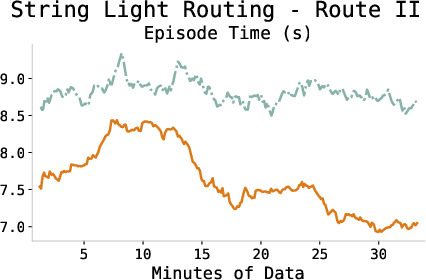
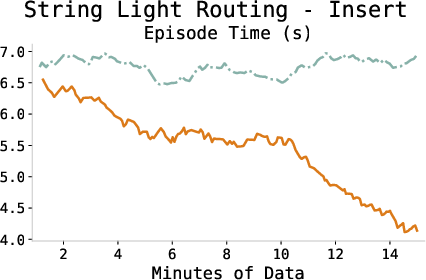
Figure 4: Episode completion times across tasks demonstrating increased efficiency through learning.
State space randomization visualization confirms the agent's generalization across diverse initial conditions.

Figure 5: Visualization of randomized initial state spaces, illustrating the scope of generalization required by robust policies.
Critical Findings and Claims
- Black consistently achieves 100% task success across all evaluated manipulation domains.
- Sample efficiency is substantially improved relative to all prior methods, with reliable performance achieved in under 20 minutes of online data.
- Human-in-the-loop interventions are critical for bootstrapping exploration but are quickly reduced as RL finetuning proceeds.
- Action chunking and value-guided action selection enhance compatibility with pretrained VLA representations and enable high closed-loop responsiveness and precision.
- Prior RL-from-scratch methods (e.g., HIL-SERL) fail to generalize or converge reliably under large initial-state randomization, whereas black is robust across all such regimes.
- Finetuning methods constrained to latent space or prior modes (e.g., DSRL) have limited capacity for acquiring new behaviors; black directly finetunes the VLA in the RL loop.
Implications for AI and Robotics
The results demonstrate that RL finetuning of pretrained VLA models is not only feasible but broadly beneficial, overcoming both sample efficiency and reliability bottlenecks. The system's open-source implementation and generality across manipulation types suggest broad applicability for future robotic deployment. The architectural separation between actor and learner provides a scalable template for integrating large, expressive models with real-world interaction.
Future Directions
Several practical limitations remain, including manual environment resets and computational overhead from large-scale VLAs during high-frequency interaction. Automating environment resets and developing more computationally efficient inference and update strategies for VLAs are natural future directions. Extending the approach to multi-agent settings, continuously evolving task suites, and lifelong learning would further leverage the strengths of RL-adapted VLAs.
Conclusion
The paper establishes a new paradigm for sample-efficient, reliable RL finetuning of VLAs in robotics, offering formal algorithmic innovations and strong empirical validation across real-world manipulation challenges. The methodological contributions—temporal action chunking, edit-policy RL, human-in-the-loop corrections, and efficient system architecture—collectively position black as an effective framework for deploying generalist robotic policies with practical reliability and efficiency.

