- The paper introduces multi-teacher on-policy distillation to merge 50 effect LoRAs into one unified module.
- It employs dual-stream routing and asymmetric orthogonal prompting to maintain effect fidelity and prevent interference.
- Experiments demonstrate enhanced image quality, storage reduction, and robust zero-shot composition without retraining.
Multi-Teacher Distillation for Unified LoRA-Based Visual Effects
Introduction
CollectionLoRA addresses the fundamental deployment inefficiency in effect-driven image editing with diffusion models, where multiple separate Low-Rank Adaptation (LoRA) modules are required for each visual effect. This modular architecture incurs substantial storage and routing costs, and combinatorial interference between effect and acceleration LoRAs often results in concept bleeding and style degradation during inference. The paper introduces a multi-teacher on-policy distillation paradigm that consolidates up to 50 distinct effect LoRAs, including few-step acceleration, into a single unified LoRA. The framework resolves the feature interference bottleneck and significantly optimizes deployment performance by eliminating the need to dynamically load or compose LoRAs at runtime.

Figure 1: CollectionLoRA merges diverse effect LoRAs and few-step capabilities into a single module via multi-teacher distillation.
Motivation and Challenges
Conventional image editing pipelines, using pre-trained diffusion models and effect-specific LoRAs, suffer from three primary scalability bottlenecks: (i) linear growth in storage as the number of LoRAs increases, (ii) routing latency and matching errors during dynamic LoRA retrieval, and (iii) severe parameter interference from sequential LoRA composition—specifically between effect LoRAs and acceleration modules. Existing distillation approaches, adapted from LLMs, are insufficient in diffusion settings due to the large distribution gap between the base model and heterogeneous effect experts, leading to collapsed intermediate distributions and degraded generalization.
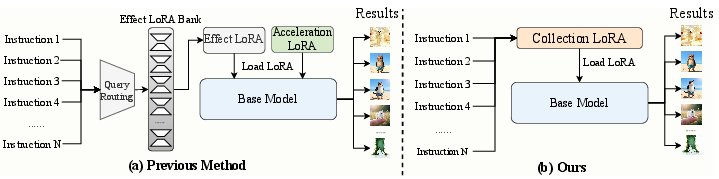
Figure 2: Comparison between conventional multi-LoRA serial pipelines and CollectionLoRA’s unified distillation paradigm.
Methodology
CollectionLoRA employs a multi-teacher on-policy distillation framework comprising three innovations:
- Probabilistic Dual-Stream Routing (PDSR): During training, batches are randomly routed between a general stream (using general-domain data for regularization) and an effect stream (injecting effect-specific samples), balancing generalization and effect fidelity as shown in the framework schematic.
- Asymmetric Orthogonal Prompting (AOP): The teacher and student models utilize distinct prompts for each effect. Teacher LoRAs use original task prompts, while student prompts are automatically generated captions with unique orthogonal trigger words via a Vision-LLM (VLM). This ensures concept isolation within the latent prompt space and mitigates manual prompt conflicts.
- Coarse-to-Fine Distillation Objective (C2F-DO): Optimization proceeds via trajectory anchoring (flow matching) for structural stabilization and Target Simulation (TS) for high-frequency restoration. TS, with strict step constraints, amplifies divergence between student and teacher distributions, overcoming vanishing gradients endemic to standard DMD in heterogeneous distillation.
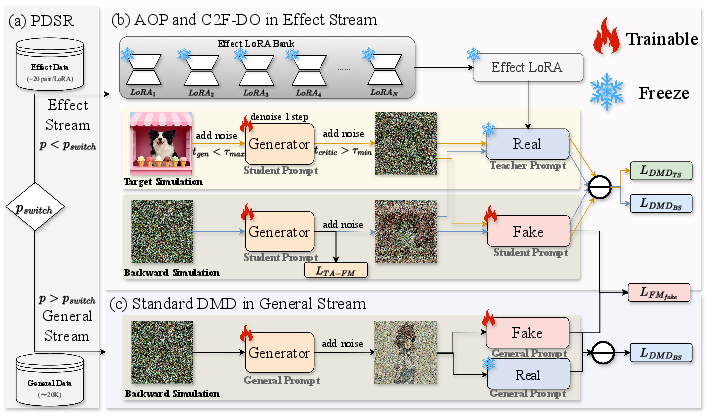
Figure 3: Schematic of CollectionLoRA training: PDSR dynamically routes between effect and general streams; AOP and C2F-DO operational in the effect stream.

Figure 4: (a) Vanilla DMD collapses the student distribution. (b) C2F-DO restores realistic detail in the presence of distribution gaps.
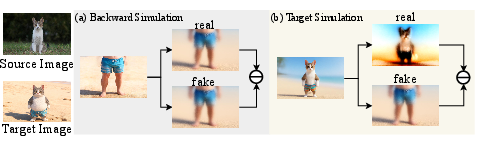
Figure 5: Target Simulation avoids domain drift and vanishing gradients compared to Backward Simulation in multi-teacher distillation.

Figure 6: Time-step constraints amplify divergence and stabilize gradient flow in target simulation for effective training.
Experimental Evaluation
Quantitative Results
On EffectBench (50 effects, ~20 paired samples/effect), CollectionLoRA demonstrates superior style alignment and overall image quality (CLIP: 0.727, DreamSim: 0.425, EditReward: 1.052), outperforming single-task teachers and joint FM baselines. The Bad Case Rate (BCR) drops to 0.087, and Valid Subject Alignment (VSA) reaches 4.380, indicating robust effect injection and identity preservation even under extreme concept compression.
Storage overhead and routing latency are reduced to 0 with up to 50 effects, and accuracy remains at 100% compared to baseline degradation (down to 76% at 150 LoRAs). At scales up to 180 effects, quality degrades moderately but remains competitive with single-task baselines, evidencing scalability and cost-efficiency.
Qualitative Results
Visual analyses confirm CollectionLoRA eradicates texture loss, style interference, and generalization collapse ubiquitous in baseline pipelines. Structural fidelity is retained even for OOD subjects due to dual-stream regularization.

Figure 7: CollectionLoRA mitigates texture loss, style interference, and generalization collapse compared to baselines.
Zero-shot effect composition is emergent—chaining orthogonal effect descriptors in an inference prompt allows simultaneous effect blending not present during training, attributed to concept disentanglement in the prompt manifold.

Figure 8: Zero-shot composition: CollectionLoRA blends multiple effects at inference via prompt chaining without retraining.
Ablation Study
Component ablations validate the contributions: AOP reduces concept bleeding and failure cases, TS accelerates convergence and restores high-frequency details, TA-FM ensures structural consistency under optimization instability, and PDSR prevents catastrophic forgetting.
Incremental effect extension via lightweight fine-tuning enables stable addition of new effects without retraining, supporting continuous deployment updates.

Figure 9: Progressive integration of core modules resolves semantic collapse, restores texture, and ensures structural consistency.

Figure 10: TA-FM and TS integration accelerate convergence and enhance fidelity in training dynamics.
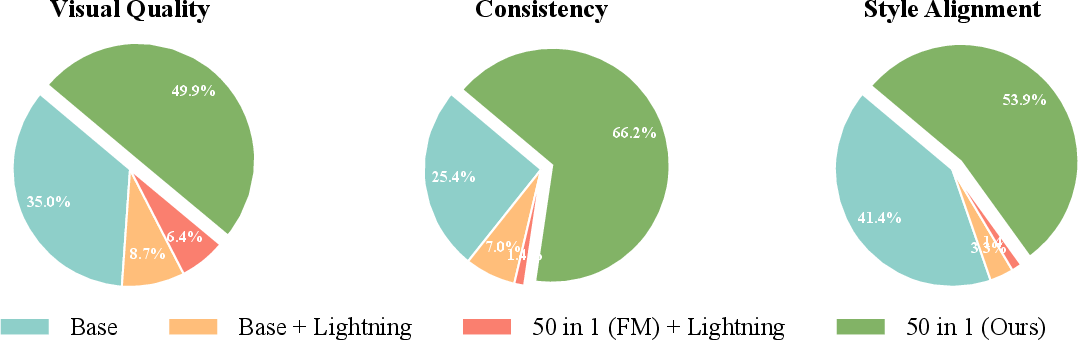
Figure 11: User study—CollectionLoRA achieves highest preference for quality, consistency, and style alignment.
Implications and Future Directions
CollectionLoRA fundamentally optimizes multi-effect deployment for diffusion models, minimizing both storage and runtime costs and enabling scalable effect personalization. The unified distillation strategy is compatible with incremental effect addition and supports emergent zero-shot composition, indicating significant advancement in modular generative editing. Practically, this lowers cost and complexity for large-scale, production-grade image editing or creative pipelines.
Theoretically, the approach demonstrates that on-policy multi-teacher distillation, combined with latent-space prompt isolation and hybrid objectives, is effective in absorbing highly heterogeneous creative effects into a single parameter regime. Future work should examine even larger-scale integration (hundreds–thousands of effects), cross-modal effect distillation (video, audio), and further disentanglement for controllable, compositional effect blending at inference.
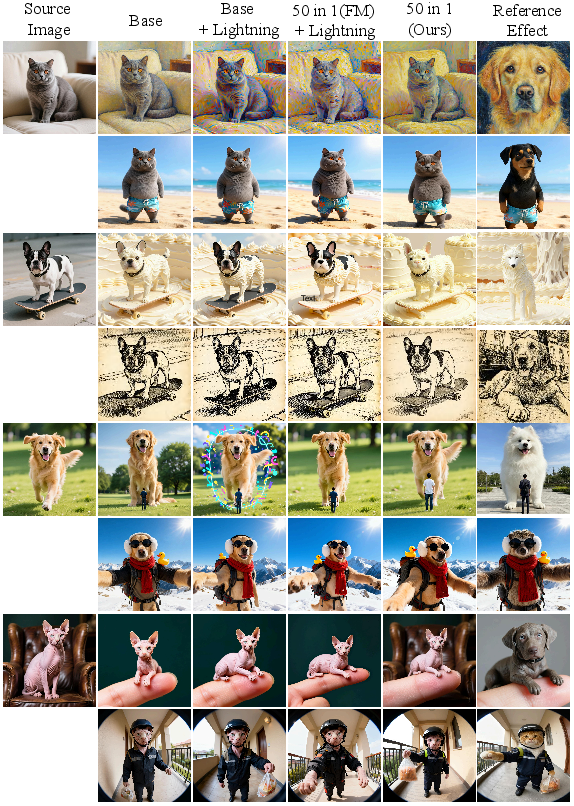
Figure 12: Qualitative evaluation, demonstrating the robustness of CollectionLoRA-generated images.

Figure 13: Additional qualitative evaluation illustrating structural and stylistic consistency across diverse effects.
Conclusion
CollectionLoRA establishes a new paradigm for effect-driven diffusion model editing, unifying disparate visual concepts and inference acceleration into a single LoRA via stable multi-teacher distillation. Experimental results confirm superior generation quality and concept isolation, with substantial reductions in deployment overhead. The emergent compositionality and extensibility further underscore its relevance for scalable, modular creative AI systems.
(2605.25378)