- The paper presents AOD, a method that leverages adversarial training and orthogonal decomposition to disentangle hallucinatory from truthful features in LVLM hidden states.
- It demonstrates robust improvements on benchmarks, enhancing factual accuracy in tasks such as POPE and AMBER while maintaining multimodal utility.
- The approach is efficient and transferable, requiring minimal labeled data and enabling safe deployment across diverse LVLM architectures.
Adversarial Orthogonal Disentanglement for Hallucination Mitigation in LVLMs
Introduction
Large Vision-LLMs (LVLMs) have advanced multimodal understanding, yet persistent hallucination—generated content incongruent with visual facts—poses a major deployment barrier, especially in safety-critical domains. Existing mitigation techniques, both external (e.g., instruction tuning, RAG) and internal (e.g., attention-based sparsification or latent subspace classifiers), show limited efficacy and often incur substantial trade-offs between safety and utility. "Adversarial Orthogonal Disentanglement for LVLM Hallucination Mitigation" (2605.25377) introduces Adversarial Orthogonal Disentanglement (AOD), an internal intervention framework that leverages adversarial training and orthogonal decomposition to disentangle, and explicitly penalize, hallucination-inducing features in LVLM hidden representations, thereby reducing hallucination while preserving semantic integrity.
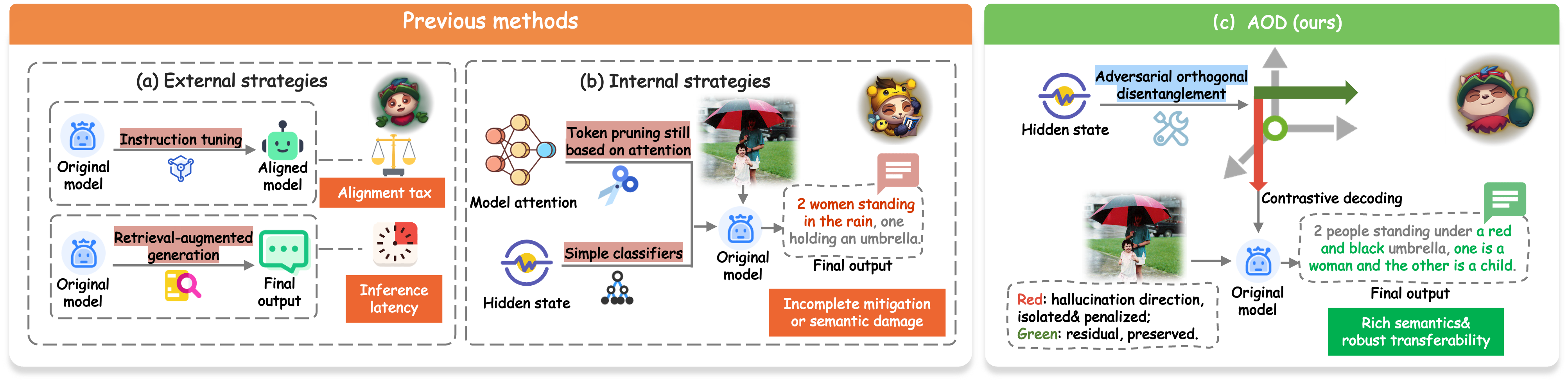
Figure 1: Comparison of mitigation strategies in LVLMs; AOD orthogonalizes hallucinatory and semantic subspaces, enabling robust mitigation and preserving semantic richness.
Hallucination in LVLMs is conventionally approached via external augmentation—leveraging instruction tuning or retrieval-augmented generation for additional alignment—or, more recently, through internal modifications targeting the model’s latent space. External methods impose considerable computational and latency cost, and often require costly model retraining. Internal strategies based on attention-based pruning are fundamentally paradoxical, as they operate on the defective attention distributions responsible for hallucinations, and energy-based or classifier-based latent interventions suffer from severe feature entanglement, often degrading task performance or yielding non-specific, overly cautious outputs.
Recent work in representation disentanglement suggests that semantically meaningful and hallucinatory signals, though coupled, can be linearly separated within high-dimensional latent spaces. Prior techniques typically focus on disentangling macroscopic features at the level of attention maps or demand substantial modifications to model architectures, limiting their practical scalability and universality.
Methodology
AOD reframes hallucination mitigation as a geometric latent disentanglement problem, seeking a single unit-norm direction in hidden state space (the hallucination direction) that captures hallucination-correlated variation, while an orthogonal residual captures truthful semantics. The framework is comprised of four essential steps:
- Hidden State Supervision: Extract hidden activations from a chosen LVLM layer and annotate them with binary hallucination labels by evaluating model outputs against ground truth.
- Orthogonal Decomposition: Decompose each activation vector x as:
x=(x⊤v)v+[x−(x⊤v)v]
where v is the learned hallucination direction.
- Minimax Adversarial Objective: Train a classifier to maximize label predictiveness from the projected component, while an adversarial probe with a Gradient Reversal Layer (GRL) minimizes label predictiveness from the orthogonal residual, encouraging geometric and semantic disentanglement.
- Inference-Time Contrastive Decoding: Apply a dual-forward inference procedure: subtracting v to construct a factual-steered state, adding v for a hallucination-steered state, and combining outputs contrastively to suppress hallucinatory logits while preserving factual responses.
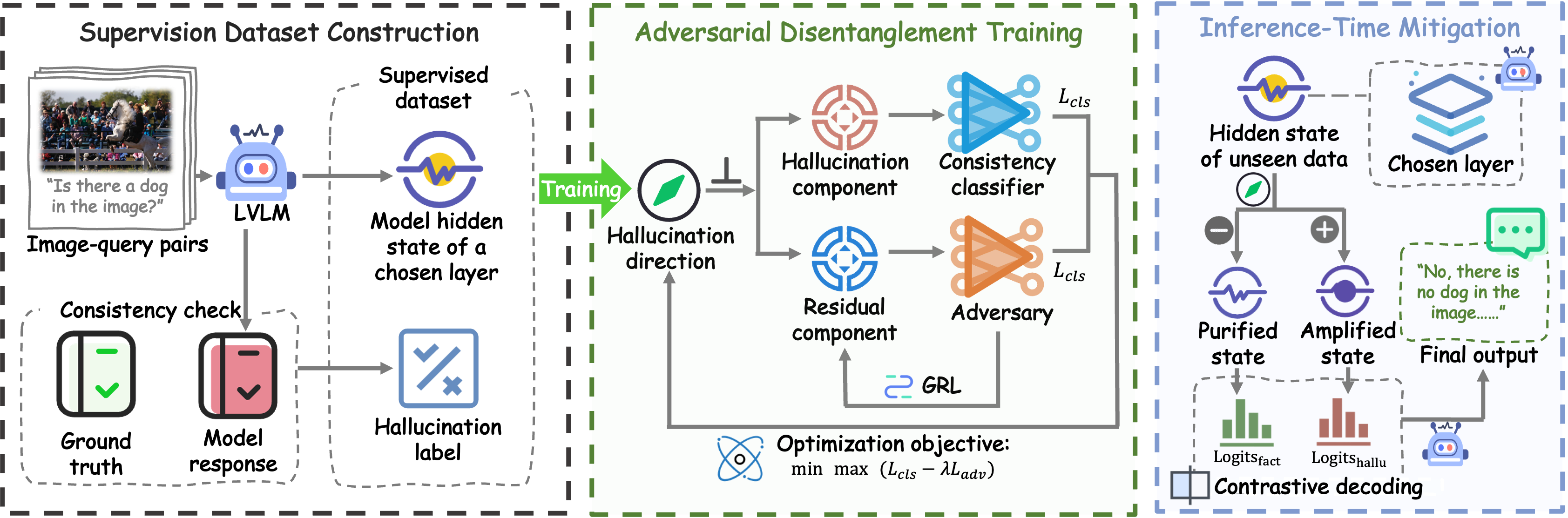
Figure 2: Schematic of the AOD framework, including extraction of hallucination direction and adversarial decomposition, enabling dual-pass contrastive inference.
Empirical Results
AOD is evaluated on representative LVLMs (LLaVA-1.5-7B, Qwen2.5-VL-7B, InternVL3-8B) over visual hallucination (POPE, AMBER, HallusionBench, CHAIR) and general utility (OCRBench-v2, RealWorldQA, MMStar, MMMU) benchmarks. Across all models and benchmarks, AOD demonstrates uniform, robust improvements:
- POPE: AOD achieves accuracy gains of +6.4% (LLaVA-1.5-7B), +5.6% (Qwen2.5-VL-7B), and +7.3% (InternVL3-8B) over base models.
- AMBER: Improvements exceeding 6% are observed, highlighting robust suppression of diverse hallucination typologies.
- General Utility: Strong boosts on complex utility tasks (e.g., +10.4% on OCRBench-v2) indicate that AOD’s targeted mitigation does not compromise, and can even enhance, underlying multimodal reasoning abilities.
AOD maintains and sometimes improves performance on challenging utility-oriented datasets, in direct contrast to methods that reduce hallucinations at the expense of core capability. The ablation studies reveal that efficacy peaks when intervening at middle-to-late transformer layers, and AOD hyperparameters (steering strength, contrastive weight, adversarial factor) are robust across a wide operational range, enabling reliable deployment.
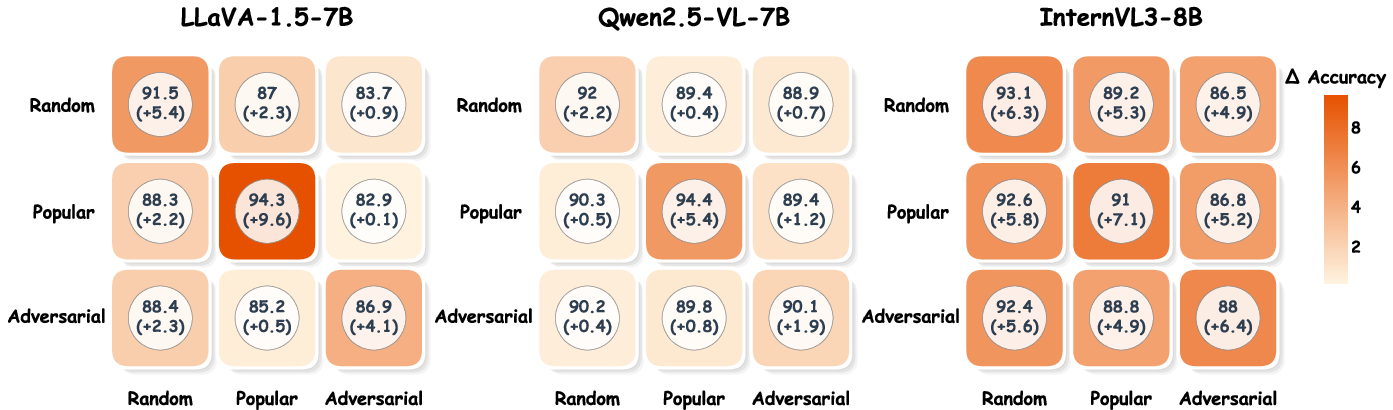
Figure 3: Heatmap showing the zero-shot transferability of learned hallucination directions across POPE splits, underscoring generalization to unseen difficulty levels.
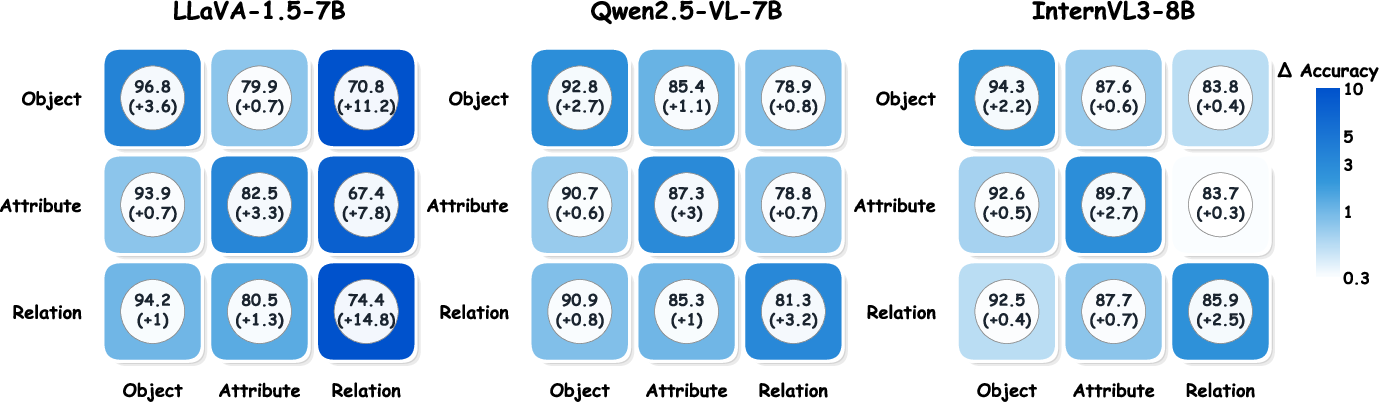
Figure 4: Heatmap illustrating cross-typology transferability on AMBER; AOD produces typology-specific improvement, revealing geometric subspace modularity.

Figure 5: Qualitative corrections from AOD on LLaVA-1.5-7B; hallucinated or missed evidence is suppressed, with enhanced grounding and factual precision.
Analysis
Transferability
AOD’s hallucination directions exhibit strong zero-shot transfer. When trained on one split or typology (e.g., adversarial POPE, AMBER-Attribute), the intervention generalizes to unseen data and orthogonal hallucination types, though maximal improvements are achieved in-matching conditions, validating both universality and specificity.
Latent Space Geometry
Layer-wise activation analysis demonstrates that differences between hallucinatory and truthful states become most prominent beyond the early perception layers, peaking in the mid-to-late stages of the transformer. Intervention at these strata yields optimal suppression, consistent with the hypothesis that semantic integration and over-reliance on language priors are the locus of multimodal hallucination.
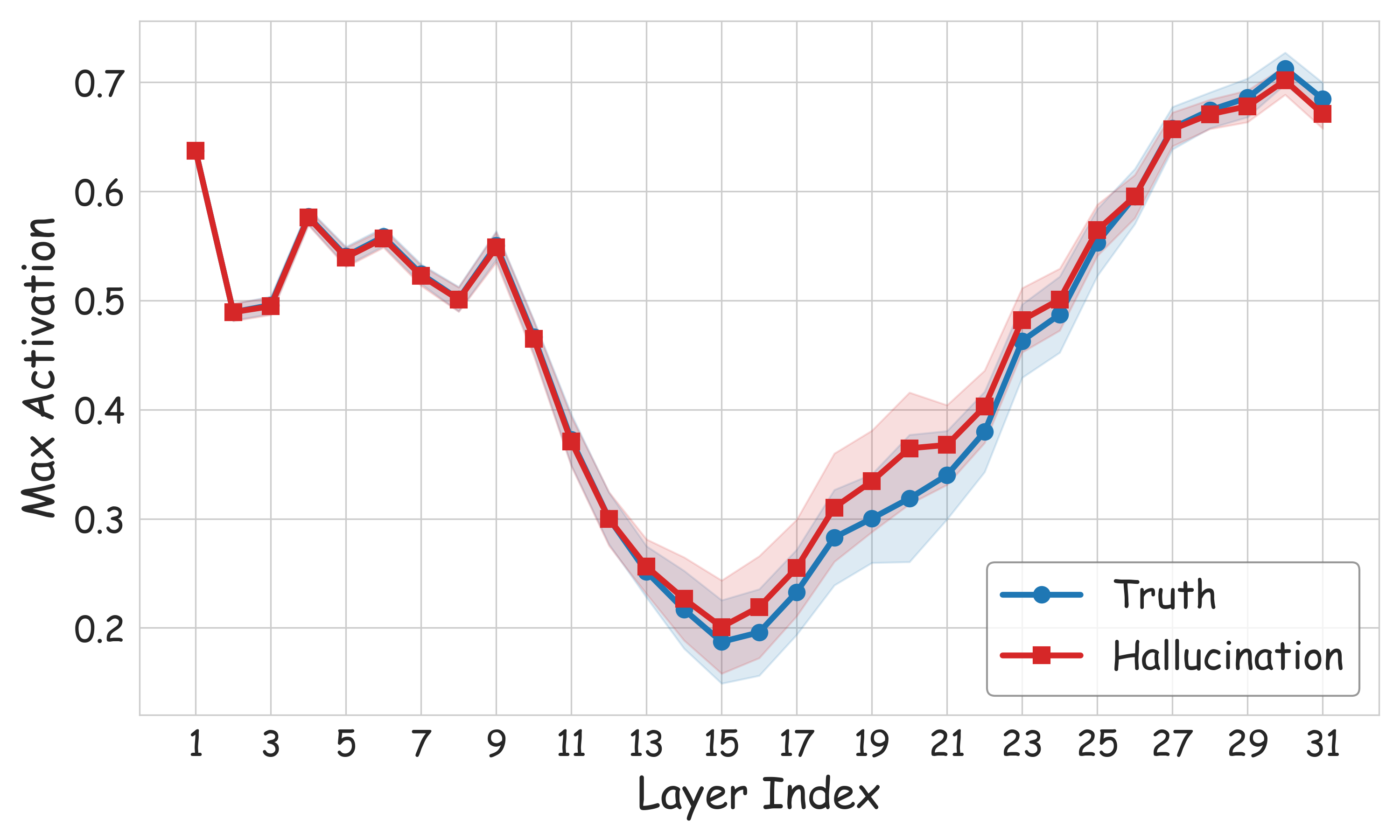
Figure 6: Layer-wise max activation statistics highlighting divergence between truth and hallucination beyond initial layers, supporting targeted intervention.
Operation Efficiency
AOD requires only a small, labeled dataset (≈300–600 examples are sufficient) to extract stable hallucination directions and is model-agnostic, facilitating efficient, training-free deployment. The dual-pass contrastive decoding incurs a moderate inference-time overhead compared to the computational and memory cost of full retraining or RAG architectures.
Ablations
Comprehensive ablations confirm that:
- Middle–late layer interventions are essential for maximal efficacy (Figure 7).
- Steering strength and contrastive weights can be safely tuned within practical ranges.
- The adversarial disentanglement loss is required for effective isolation of hallucination from semantic features.
- Single-pass variants (AOD w/o CD) offer plausible lightweight alternatives when latency is critical, at modest performance cost.
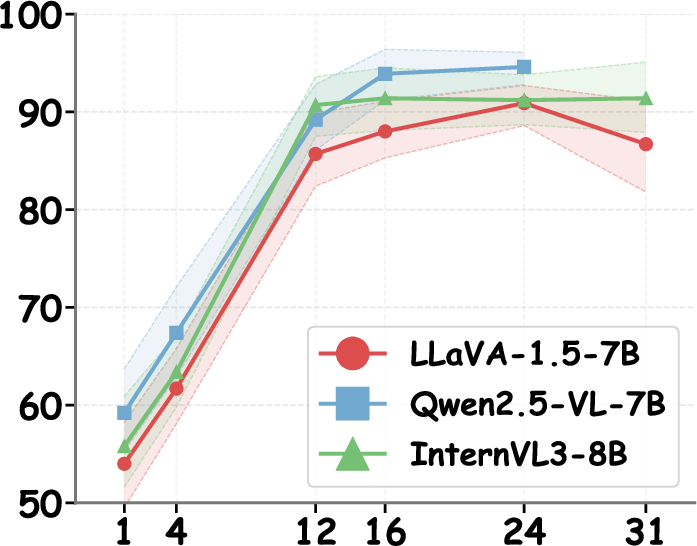
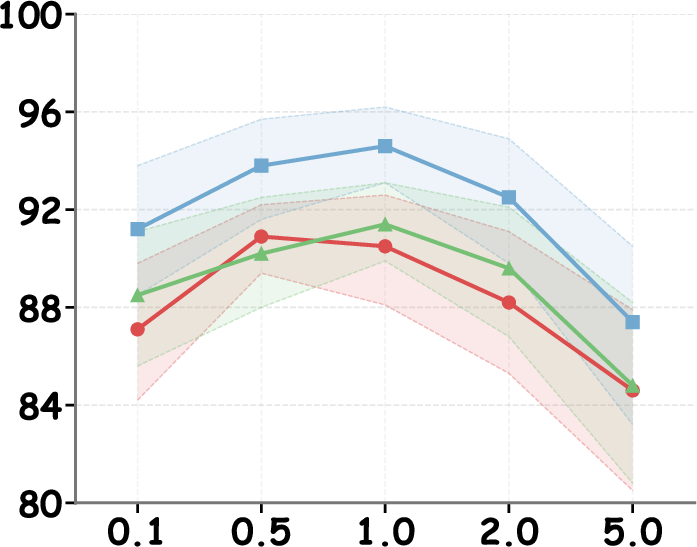
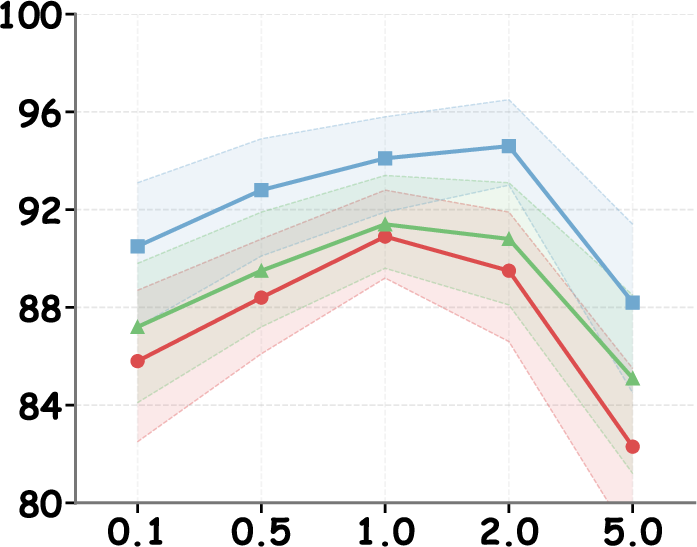
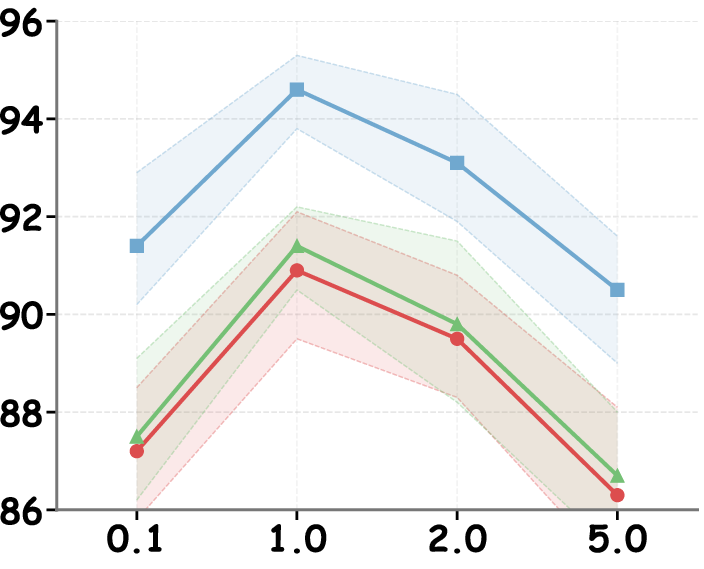
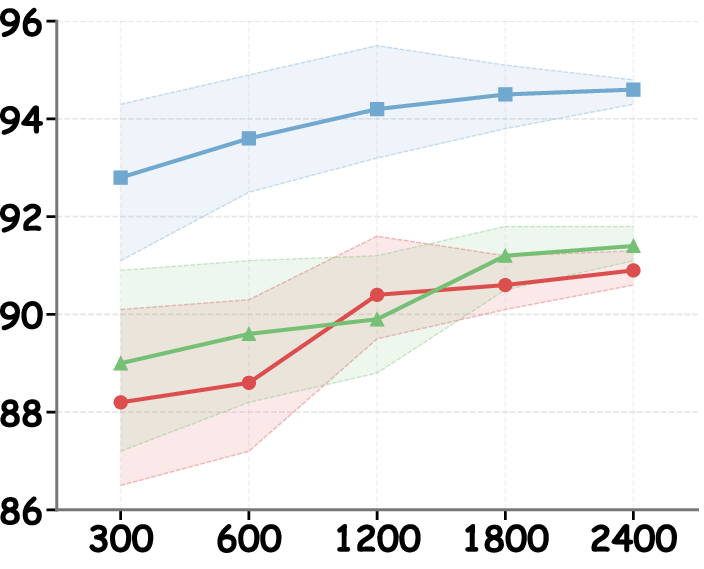
Figure 7: Intervention efficacy as a function of transformer layer choice, peaking in middle-to-late layers for all model backbones.
Implications and Future Directions
AOD’s success in isolating and neutralizing hallucination-prone subspaces with transferability across tasks and typologies sets a precedent for geometric editing of deep model representations. Practically, it enables safety-centric deployment of LVLMs in sensitive environments (e.g., autonomous vehicles, medicine), without retraining or performance regression. Theoretically, it motivates further investigation into universal latent subspace biases and the modularity of failure modes within large neurosymbolic systems.
Future research may focus on:
- Extending AOD to hierarchical disentanglement, enabling simultaneous control of multiple failure modes.
- Automated discovery of intervention strata via information-theoretic latent analysis.
- Integration with model-agnostic interpretability frameworks for real-time monitoring and dynamic correction.
Conclusion
AOD demonstrates that hallucination mitigation can be achieved via adversarial orthogonal disentanglement in LVLM hidden spaces, producing substantial suppression of hallucinations while preserving—and in some cases enhancing—general utility and reasoning capacity. The approach is robust, transferable, data-efficient, and does not require model retraining or architectural changes. These findings substantiate geometric manipulation of activations as a practical and theoretically grounded tool for responsible multimodal model deployment.