Learning to Route Languages for Multilingual Policy Optimization
Abstract: LLMs~(LLMs) are trained on heterogeneous multilingual corpora, yet existing policy optimization methods often implicitly restrict each training question to a single response language or rely on a fixed dominant language for supervision. We propose language-routed policy optimization (LRPO), an online policy optimization framework that treats language as a selectable variable. LRPO elicits multilingual rollouts for each training question and integrates their relative quality into preference-based policy updates, increasing the diversity and informativeness of training signals under the fixed rollout budget. To adaptively determine which languages to explore during reinforcement learning, we introduce a trainable language router formulated as a multi-armed bandit, balancing exploration of underutilized languages with exploitation of more informative ones. Extensive experiments show that LRPO consistently improves multilingual performance, demonstrating that adaptive language routing enables effective cross-lingual knowledge exploitation for training. We release all the resources at https://github.com/Guochry/LRPO.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching LLMs to choose the best language to answer a question during training. Instead of forcing the model to always reply in one language (often English), the authors let the model try answering in several languages and learn which language tends to give the most helpful, accurate answers for different kinds of questions. They call this approach LRPO, which stands for Language‑Routed Policy Optimization.
What were the goals?
The researchers wanted to:
- Help models better use knowledge that’s spread across many languages.
- Stop relying on one “dominant” language (like English) when other languages might contain better or more precise information for a specific topic or region.
- Dynamically decide which languages to use during training, so the model learns from the most informative language for each question.
How did they do it? (Simple explanation)
Think of the model like a student learning to answer questions. Each time it studies a question, it can “practice” answering in different languages. Then a teacher grades those answers and the student adjusts its strategy.
Here are the main parts:
- Multilingual practice rounds (“rollouts”): For each training question, the model generates several answers, each in a possibly different language. This increases the chance of surfacing the best information, because knowledge can be more complete or accurate in some languages than others.
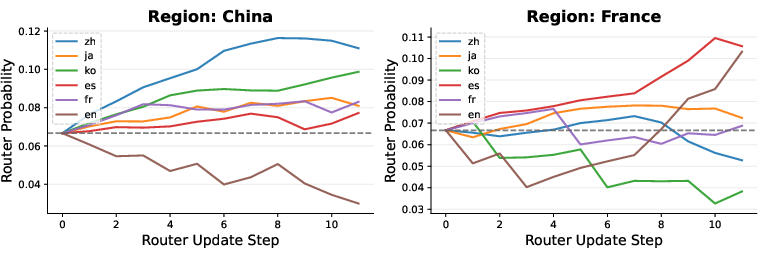
- A smart language chooser (“language router”): Imagine you have many slot machines (one per language). You want to play the machines that pay off most, but you also want to try others in case they’re good too. The language router works like a multi‑armed bandit: it balances trying underused languages (exploration) with using languages that have been giving better answers (exploitation). It also looks at the question’s topic (like math, safety, or local facts) and region (like China or France) to pick promising languages.
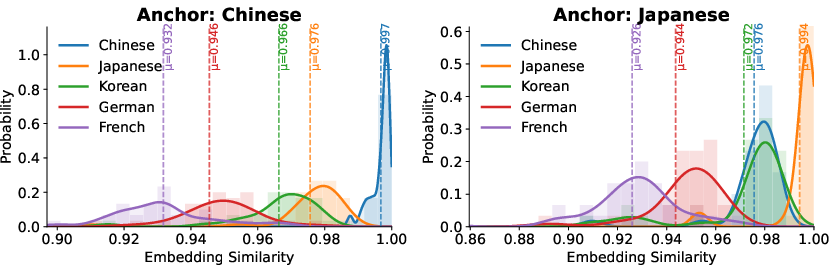
- Fair grading across languages (“reward calibration”): The model’s answers are compared to a high‑quality reference answer using a semantic similarity score (a way to measure whether two answers mean the same thing, even in different languages). But raw scores can be unfair—some language pairs get higher or lower similarity scores even when they mean the same thing. To fix this, the authors pre‑measure how scores behave across language pairs and “calibrate” them so the grading is fair, no matter the language.
- Learning from good answers: The model gets reward for high‑quality answers that follow the chosen target language. It updates itself to make those kinds of answers more likely next time. Over time, the router and the model improve together: the router becomes better at choosing languages, and the model becomes better at answering.
What did they find?
Overall, letting the model explore multiple languages and learn a smart routing strategy improved multilingual performance across different models and benchmarks.
Key takeaways:
- Consistent improvements across models: Tested on Qwen, Llama, and Gemma models, LRPO improved results on five multilingual benchmarks. For example, on Qwen2.5‑1.5B, a math test (mGSM‑v2) jumped from about 25% to 38% after LRPO—an especially big gain for open‑ended reasoning tasks.
- Multilingual > monolingual training: Training with a mix of languages beat training in only the question’s original language. Even simple mixtures helped; however, the learned, dynamic router worked best overall.
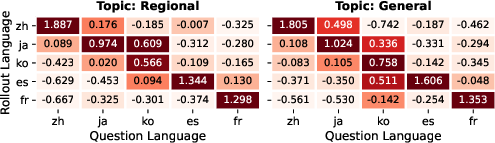
- The best language depends on the question: Sometimes English or the input language wasn’t the most accurate. In one example, a Japanese question got wrong answers in Japanese and English, but the French answer was correct. This shows why it helps to try multiple languages.
- Fair scoring matters: Without calibration, scores for identical meanings could differ across languages, which would mislead training. Calibrating fixed this, making cross‑language comparisons fairer.
- Easy start helps but isn’t required: A small amount of supervised fine‑tuning to help the model follow “answer in X language” instructions made training smoother, but LRPO still improved results without it.
Why does this matter?
- Better use of global knowledge: Useful information is scattered across languages. LRPO helps models tap into that, leading to more accurate and culturally grounded answers—especially for local or regional facts.
- Fairer multilingual AI: By not relying solely on English (or any single language), this approach can benefit speakers of many languages and improve performance where English is not the best source.
- Smarter, more efficient training: With a fixed budget of practice attempts, routing to the most informative languages makes each training step count more.
In short, LRPO shows that treating language as a smart choice during training—rather than a fixed setting—helps LLMs learn better from the world’s diverse knowledge. This could lead to assistants that answer more accurately across cultures and languages, making AI more useful and inclusive.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unaddressed in the paper. Each point highlights what is missing or uncertain and suggests directions future work could act on.
- Reward calibration robustness:
- The cross-lingual similarity calibration relies on only ~30 MT-generated “equivalent” pairs per language pair; assess statistical stability, translation noise effects, and how many samples are actually needed for reliable calibration.
- The chosen similarity model (mmBERT/BLEUberi) may encode language-specific biases; benchmark alternative cross-lingual similarity metrics and validate calibration against human judgments, especially for low-resource or typologically diverse languages.
- Scalability of calibration:
- The pairwise reward calibration scales as O(L²) in the number of languages; develop scalable approximations (e.g., metric learning, shared anchor spaces, pivot languages, or multilingual normalization layers) that maintain comparability without per-pair statistics.
- Dependence on reference answers:
- LRPO assumes access to “high-quality reference” responses for reward computation; clarify provenance and generality of these references and explore extensions to preference-only settings or reward models where references are unavailable.
- Sensitivity of reward design:
- No systematic analysis of the impact of calibration choices (mean vs. quantile), λ strength, or group normalization on learning dynamics; provide sensitivity studies and guidance for hyperparameter selection.
- Language-identification (LID) reliability:
- The LID component is unspecified; quantify LID error rates across scripts/dialects and analyze how misclassification affects training, especially when gating rewards to zero for “wrong” languages.
- Strict language gating:
- Zeroing rewards for off-target language outputs may penalize useful code-switching or partially multilingual answers; evaluate soft penalties, graded language adherence, or multi-language reward aggregation strategies.
- Router design limits:
- The router’s context is limited to coarse topic and optional region labels; investigate richer contextual bandits or small neural routers using learned text features (e.g., embeddings) for per-query routing.
- Topic and region annotations are derived from an LLM classifier with limited human validation; quantify labeling noise at scale and its impact on routing decisions.
- Exploration–exploitation strategy:
- The paper uses ε-greedy with annealing and EMA updates but does not compare to standard bandits (UCB, Thompson sampling) nor analyze regret/convergence under non-stationary rewards; conduct theoretical and empirical comparisons.
- Router stability and non-stationarity:
- The policy and reward distributions change during training, making the bandit non-stationary; evaluate adaptive algorithms (e.g., sliding-window estimates, change-point detection) and their effect on stability and sample efficiency.
- Hyperparameter sensitivity:
- Numerous training and router hyperparameters (K, K_on, ε, τ, α, M) are introduced; provide systematic ablations and tuning guidance to understand robustness across models and datasets.
- Compute and data efficiency:
- Multilingual rollout groups increase generation and scoring costs; quantify compute/memory overhead vs. gains, and study budget-aware policies (e.g., adaptive K per query, early stopping when signal saturates).
- Generalization to unseen/low-resource languages:
- Improvements on unseen languages are modest and uneven; evaluate mechanisms for routing to or benefiting languages with no training-time exposure, and study performance on truly low-resource scripts/dialects.
- Task/domain coverage:
- Gains are strongest on open-ended tasks; analyze failure modes on multiple-choice tasks and extend to other domains (code, safety, long-form reasoning, dialog) to characterize when LRPO is most useful.
- Per-language trade-offs:
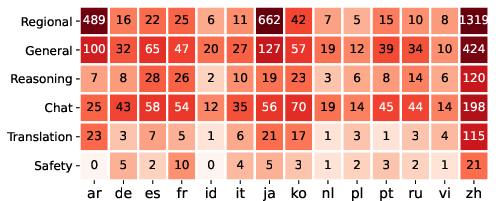
- Results are reported as aggregates; provide language-by-language analyses to detect regressions, especially on minority languages, and study fairness-aware routing constraints to prevent collapse onto a few high-reward languages.
- CARE-pro dataset transparency:
- The new CARE-pro set lacks detailed statistics (size, per-language/region balance) and public availability status; release detailed documentation and human-evaluation protocols to ensure reproducibility and external validation.
- Evaluation bias from LLM judges:
- CARE-pro uses an LLM judge with 93.5% agreement; assess judge biases across languages, scripts, and content types, and triangulate with human evaluations to quantify cross-lingual reliability.
- Warm-starting and language control:
- LRPO benefits from small SFT for language control tokens; characterize minimal data requirements, robustness across backbones, and alternatives for models without reliable language control.
- Router’s region-language assumptions:
- The region-conditioned matrix may entrench simplistic region↔language mappings and stereotypes; study more nuanced geographic and cultural associations, and evaluate robustness when region metadata is missing/ambiguous.
- Code-switching and multilingual outputs:
- The framework treats language as a single discrete choice per rollout; explore structured outputs that blend languages when beneficial (e.g., bilingual answers with citations) and adjust rewards accordingly.
- Inference-time routing:
- Routing is only used during training; investigate inference-time language routing and translation back to the user’s language, including user-preference modeling and latency/quality trade-offs.
- Scaling to many languages:
- The study trains on 14 languages but evaluates up to 44; examine the limits of scaling (e.g., 100+ languages), the combinatorial explosion in calibration, and strategies for adding new languages mid-training.
- Interaction with translation quality:
- Calibration and warm-start rely on MT; quantify how MT errors propagate into reward bias and study MT-free alternatives (parallel corpora, human-crafted equivalences, cross-lingual entailment).
- Group normalization effects:
- Normalizing rewards within multilingual rollout groups may introduce competition effects between languages; analyze whether normalization biases selection toward languages with higher-variance rewards.
- Safety and toxicity:
- The routing policy may preferentially sample languages with higher reward but potentially higher safety risks; integrate and evaluate safety-aware rewards and guardrails across languages.
- Theoretical understanding:
- Provide a formal treatment of LRPO’s convergence properties and the effect of calibration noise and non-stationarity on policy optimization, potentially via a joint bandit–RL framework.
Practical Applications
Immediate Applications
These applications can be deployed now with modest engineering effort, using the released LRPO code and standard RLHF/GRPO pipelines.
- Multilingual RLHF/RLAIF training that “routes” languages for better supervision
- Sectors: software/AI platforms, consumer assistants, enterprise chatbots
- How: Integrate the LRPO language router and calibrated cross-lingual reward into existing GRPO/RLHF training loops to elicit rollouts in multiple languages per prompt, then update the policy using relative quality signals across languages. Start with language tags/system prompts or a brief SFT warm-start for reliable language control.
- Tools/workflows:
- Router module (topic-/region-conditioned bandit with ε-greedy + temperature annealing)
- Cross-lingual reward calibration (offline similarity statistics + online calibration)
- Language ID check to gate rewards by language consistency
- Assumptions/dependencies: access to high-quality reference answers for reward computation; reliable cross-lingual similarity (e.g., multilingual encoders) and translation to build equivalence pairs; accurate topic/region tagging; compute budget for on-policy multilingual rollouts.
- Region-aware model alignment for localized, culturally accurate answers
- Sectors: public sector citizen services, travel/tourism, e-commerce marketplaces, media/libraries
- How: Use the LRPO router’s region-conditioned logits to favor languages strongly associated with a question’s region (e.g., routing regional questions to local-language rollouts), improving factual grounding and cultural nuance in the trained assistant.
- Tools/products: “Region-aware Fine-Tuner” that ingests region metadata and optimizes router matrices A (topic-by-language) and B (region-by-language) during RL.
- Assumptions/dependencies: availability of region labels for training queries; guardrails to avoid reinforcing stereotypes; up-to-date regional knowledge in pretraining data.
- Multilingual data augmentation and selection for fine-tuning
- Sectors: data engineering/MLOps, localization vendors, academic labs
- How: Use the LRPO rollout-and-score loop to produce multiple answers across languages for each training prompt and keep the highest-calibrated responses to create higher-quality, language-diverse preference datasets for SFT/DPO or mixed pipelines.
- Tools/workflows: batch rollout generation, cross-lingual similarity scoring, calibrated filtering, pair construction for DPO or preference datasets.
- Assumptions/dependencies: availability of base model capable of responding in many languages; reliable language ID and reference-quality scoring.
- Cross-lingual evaluation and QA scoring with calibration
- Sectors: model evaluation providers, compliance/governance teams, academia
- How: Reuse the paper’s calibrated cross-lingual semantic similarity to fairly compare answers across languages when building multilingual leaderboards or quality audits.
- Tools/products: “Cross-lingual Reward Calibrator” library that estimates per-language-pair distributions and maps raw similarity scores to calibrated rewards/quantiles.
- Assumptions/dependencies: representative equivalence and mismatch pairs for each language pair; regular recalibration as models or similarity encoders change.
- Contact-center and support bot training for global audiences
- Sectors: CX/CRM, telecom, fintech, consumer electronics
- How: Train support bots with LRPO so that rollouts can surface the best guidance from languages where product/community knowledge is richest (e.g., forums in Spanish), while producing answers in the user’s language at inference.
- Tools/workflows: router conditioned on “support topic,” region, and product locale; language-tagged prompts; policy updates with multilingual rewards.
- Assumptions/dependencies: guardrails to avoid leaking language of internal sources into user-facing outputs; data policies for cross-lingual source use.
- Better cross-cultural Q&A and study aids
- Sectors: education/edtech, media, tourism
- How: Train assistants that can surface complementary knowledge across languages during training, improving correctness on cross-cultural facts (e.g., regional etiquette, local institutions).
- Tools/products: multilingual tutoring assistants; travel Q&A assistants with region-aware training.
- Assumptions/dependencies: benchmark-aligned references; access to multilingual corpora that cover local knowledge.
- Rapid uplift of small multilingual models (1–4B) for edge or cost-sensitive deployments
- Sectors: on-device assistants, IoT, embedded systems
- How: Apply LRPO to compact instruction-tuned models to close multilingual gaps without full retraining, taking advantage of the router’s targeted exploration of informative languages.
- Tools/workflows: light SFT warm-start for language-control tokens; short LRPO runs under fixed rollout budgets.
- Assumptions/dependencies: sufficient multilingual knowledge in the base model; careful budget/latency tuning for on-device constraints.
Long-Term Applications
These applications will benefit from further research, scaling to more languages/domains, expanded datasets, and productization.
- Inference-time language routing and code-switching for better reasoning
- Sectors: software/AI, education, research tools
- Vision: Extend the router to inference to select a “thinking” or intermediate language for reasoning steps (or switch across steps), then translate back to the user’s language for final output.
- Dependencies: stable and interpretable routing during inference; robust CoT privacy and style controls; safe code-switching.
- Router-guided retrieval augmentation across languages
- Sectors: enterprise search, legal, healthcare, finance
- Vision: Use the router to select document language(s) for retrieval per query and topic/region, prioritizing corpora where evidence is richer or more reliable; integrate calibrated cross-lingual similarity for re-ranking.
- Dependencies: high-quality multilingual corpora and metadata; governance for cross-border data access; consistent cross-lingual embeddings.
- Active learning and data acquisition for underrepresented languages
- Sectors: public sector, NGOs, foundation model labs
- Vision: Use router reward signals to identify topics/regions where the model underperforms and drive targeted human data collection or translation/annotation efforts to uplift low-resource languages.
- Dependencies: annotation pipelines with community participation; funding and incentives for low-resource languages; fairness metrics.
- Domain-specialized multilingual policy optimization (medical/legal)
- Sectors: healthcare, legal, compliance, safety
- Vision: Train domain-specific routers that favor languages with stronger domain literature (e.g., German for certain medical specialties) and calibrate rewards using domain validators (e.g., medical NLI, guideline match).
- Dependencies: domain references and evaluators; rigorous safety and regulatory validation; PII and compliance safeguards.
- Multilingual safety and cultural alignment
- Sectors: trust & safety, platform policy, content moderation
- Vision: Align safety policies across languages by routing to languages that best capture nuanced cultural norms, calibrating cross-lingual safety rewards, and reducing English-centric bias in moderation models.
- Dependencies: cross-cultural safety taxonomies; robust multilingual toxicity/safety metrics; human-in-the-loop checks.
- Multi-agent systems with language-specialist agents
- Sectors: research, complex enterprise workflows
- Vision: Orchestrate multiple agents specialized by language/domain, with a bandit-style router assigning queries or subtasks to the most promising agent-language pairs and aggregating responses.
- Dependencies: agent coordination protocols; evaluation and arbitration across languages; latency and cost controls.
- Knowledge base construction and verification across languages
- Sectors: publishers, encyclopedias, open knowledge communities
- Vision: Build or refine knowledge bases by selecting languages with the most reliable/corroborated facts per topic-region and performing cross-lingual triangulation with calibrated similarity and hard negative mining.
- Dependencies: source provenance tracking; editorial policies for cross-lingual synthesis; versioning and audit trails.
- Regulatory technology for multilingual compliance
- Sectors: finance, healthcare, public administration
- Vision: Router-guided parsing of laws/guidelines across languages and jurisdictions to improve compliance Q&A and update tracking; calibrated scoring to detect divergences in interpretations across translations.
- Dependencies: curated corpora of statutes and regulations; validation with legal experts; explainability requirements.
- Personalized, inclusive assistants for diasporas and multilingual households
- Sectors: consumer tech, accessibility
- Vision: Assistants that learn which language(s) best surface accurate local knowledge for users’ contexts (e.g., heritage language for community topics), then respond in the preferred display language.
- Dependencies: privacy-preserving personalization; robust language preference detection; cultural sensitivity review.
- Standards and benchmarks for fair multilingual evaluation
- Sectors: standards bodies, public policy, academia
- Vision: Adopt calibrated cross-lingual scoring practices to reduce language-induced bias in model assessment, and develop router-aware benchmarks that reflect regional and cross-cultural tasks (e.g., CARE-pro-like tests).
- Dependencies: consensus on scoring protocols; open benchmark contributions from global communities; periodic recalibration as models evolve.
Glossary
- Calibration statistics: Summary measures computed from empirical similarity distributions to adjust and compare scores across language pairs. Example: "which is then used to estimate calibration statistics."
- Contextual multi-armed bandit: A bandit formulation where the expected reward of each action (arm) depends on observed context (e.g., topic, region). Example: "Router learning can be viewed as a contextual multi-armed bandit problem,"
- Cross-lingual reward calibration: A procedure that calibrates similarity-based rewards so they are comparable across different languages. Example: "LRPO adopts a two-stage cross-lingual reward calibration strategy,"
- Cross-lingual semantic similarity: A metric that measures how similar the meanings of texts are across different languages. Example: "using cross-lingual semantic similarity~\cite{chang2025bleuberi}."
- Direct Preference Optimization (DPO): An offline RL method that trains a policy by maximizing the log-odds of preferred responses over dispreferred ones. Example: "DPO~\cite{rafailov2023direct}: an offline RL method that updates the policy by maximizing the log-odds difference between preference pairs."
- Distributional quantile-based calibration: Calibrating a raw score by mapping it to its empirical quantile under a language-pair-specific distribution. Example: "The second is a distributional quantile-based calibration,"
- Epsilon-greedy strategy: An exploration mechanism that selects a random action with probability ε to ensure exploration. Example: "First, an -greedy strategy assigns every language a non-zero probability of being sampled."
- Exponential moving average: A smoothing update that blends new observations with past values using an exponential decay factor. Example: "using an exponential moving average with adaptation rate ,"
- Gated rewards: Rewards that are multiplied by an indicator (gate) so they contribute only when certain conditions (e.g., language consistency) are satisfied. Example: "We then apply GRPO~\cite{shao2024deepseekmath} using the gated rewards ,"
- Group Relative Policy Optimization (GRPO): An online RL algorithm that updates a policy using relative quality within groups of sampled responses. Example: "group relative policy optimization (GRPO)~\cite{shao2024deepseekmath}"
- Hard contrastive pairs: Negative (mismatched) examples selected to be the most similar to a reference, making them challenging contrasts. Example: "hard contrastive pairs, defined as the most similar mismatched pairs."
- Instruction-tuned backbones: Pretrained LLMs further fine-tuned to follow instructions. Example: "We evaluate LRPO on three instruction-tuned backbones,"
- Language consistency indicator: A binary signal indicating whether a generated response is in the intended target language. Example: "we introduce a language consistency indicator that checks whether each response is generated in the target language:"
- Language identification function: A function that detects the language of a given text. Example: "where denotes a language identification function."
- Language router: A trainable module that selects which languages to use for generating rollouts during training. Example: "we introduce a trainable language router formulated as a multi-armed bandit,"
- Language tags: Special markers or tokens specifying the desired output language for generation. Example: "via language tags or target-language system prompts,"
- Log-odds difference: The difference between the log-odds of preference pairs, used as an optimization signal. Example: "maximizing the log-odds difference between preference pairs."
- Logits: Pre-softmax scores output by a model that are converted into probabilities by a softmax. Example: "the router first retrieves the corresponding topic-level logits ."
- LRPO (Language-routed Policy Optimization): The proposed online RL framework that routes generation across languages to improve training signals. Example: "We propose language-routed policy optimization (LRPO), an online policy optimization framework that treats language as a selectable variable."
- Mean-based calibration: Adjusting scores by subtracting language-pair mean differences to improve cross-language comparability. Example: "The first is a mean-based calibration,"
- Multi-armed bandit: A sequential decision problem where a learner chooses among actions (arms) to maximize cumulative reward under uncertainty. Example: "formulated as a multi-armed bandit,"
- On-policy learning: Learning from data generated by the current policy rather than an external behavior policy. Example: "To preserve on-policy learning for the input language, we reserve a fixed quota of $K_{\text{on}$ rollouts"
- Preference-based policy updates: Policy improvements driven by relative preferences among multiple candidate responses. Example: "integrates their relative quality into preference-based policy updates,"
- Quantile function: A function that returns the quantile (rank) of a value within an empirical distribution. Example: "we estimate the empirical quantile function "
- Region-by-language matrix: A parameter matrix mapping regions to language-specific routing logits. Example: "a region-by-language matrix ."
- Reinforcement learning from human feedback (RLHF): Training a policy with rewards derived from human preference signals. Example: "reinforcement learning from human feedback (RLHF)~\cite{ouyang2022training}"
- Reward buffer: A data structure that accumulates reward signals for estimating expected utilities used in router updates. Example: "we maintain a reward buffer that records rollout rewards indexed by topic, region, and language."
- Rollout group: A set of multiple responses generated for the same prompt to compare and optimize. Example: "Language-routed multilingual rollout group"
- Simulated annealing: A schedule that gradually reduces exploration parameters to shift from exploration to exploitation. Example: "we apply simulated annealing to both the exploration rate and the softmax temperature ,"
- Softmax temperature: A parameter controlling how peaked or flat the softmax probability distribution is. Example: "the softmax temperature ,"
- Supervised fine-tuning (SFT): Using labeled data to further train a model before or during RL-based optimization. Example: "Warm-starting with supervised fine-tuning (SFT)."
- Temperature-scaled softmax: A softmax function with a temperature parameter that adjusts distribution smoothness. Example: "using a temperature-scaled softmax:"
- Topic-by-language matrix: A parameter matrix mapping topics to language-specific routing logits. Example: "a topic-by-language matrix "
- Warm-starting: Initializing training from a model that has been pre-adapted (e.g., via SFT) to stabilize subsequent learning. Example: "LRPO outperforms GRPO even without warm-starting,"
Collections
Sign up for free to add this paper to one or more collections.

