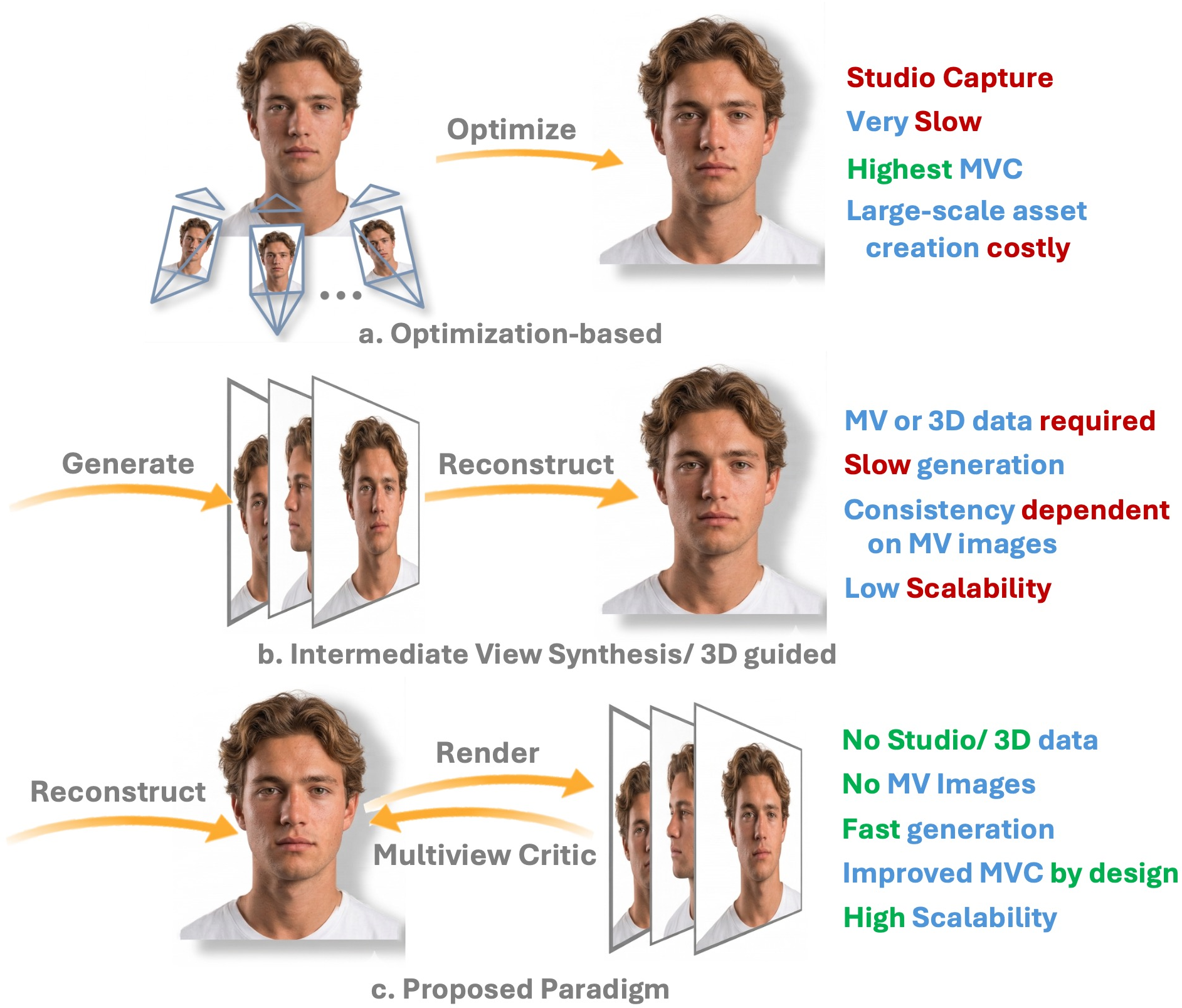
Multi-view Consistent 3D Gaussian Head Avatars 'without' Multi-view Generation
Abstract: High-fidelity 3D Gaussian head avatar generation is critical for applications such as AR/VR, telepresence, and digital humans. Existing methods depend on multi-view datasets, 3D captures, or intermediate 2D view synthesis. In contrast, we learn both conditional and unconditional 3D head models from randomly sampled 2D images alone, without using multi-view data, 3D supervision, or intermediate view generation. We introduce MVCHead, a single-shot state space model that enforces multi-view consistency (MVC) directly in the 3D representation while regressing 3D Gaussians under these constraints. At its core, we propose a Hierarchical State Space (HiSS) block that progressively refines Gaussians from coarse to fine, while capturing long-range dependencies. Within each HiSS block, we modify Mamba's standard unidirectional scan with the proposed Hierarchical Bi-directional State Scan (HiBiSS) that aligns recurrence with the axes along which multi-view inconsistencies are strongest. Finally, we design an SE(3) Multi-view Critic that judges whether a set of self-renders arises from a single underlying 3D configuration, rewarding cross-view pixel alignment without observing real multi-view pairs. MVCHead achieves state-of-the-art perceptual quality, surpasses prior methods in both texture and geometric consistency, and maintains comparable shape consistency. To demonstrate scalability, we release FaceGS-10K, the first large-scale dataset of ready-to-use 3D Gaussian head assets for training and evaluation of 3D head models. Project Page and code: https://humansensinglab.github.io/MVCHead/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making super-realistic 3D head “avatars” that look right from many different angles, using only regular 2D photos for training. The authors introduce a new method, called MVCHead, that can create a full 3D head in one go without needing fancy multi-camera setups, 3D scans, or first generating extra views. The big goal is “multi-view consistency,” which means the head should look like the same person—and have the same geometry and details—no matter which angle you view it from.
What questions did the researchers ask?
Here are the main questions the paper tries to answer:
- Can we train a 3D head generator using only normal 2D face photos, with no special multi-view or 3D data?
- How can we make the generated head look consistent from the front, side, and other angles without first creating extra images from those angles?
- Can a fast, single-pass model produce detailed, realistic heads that keep tiny features (like wrinkles, hair strands, and lip shape) consistent from different views?
How did they do it?
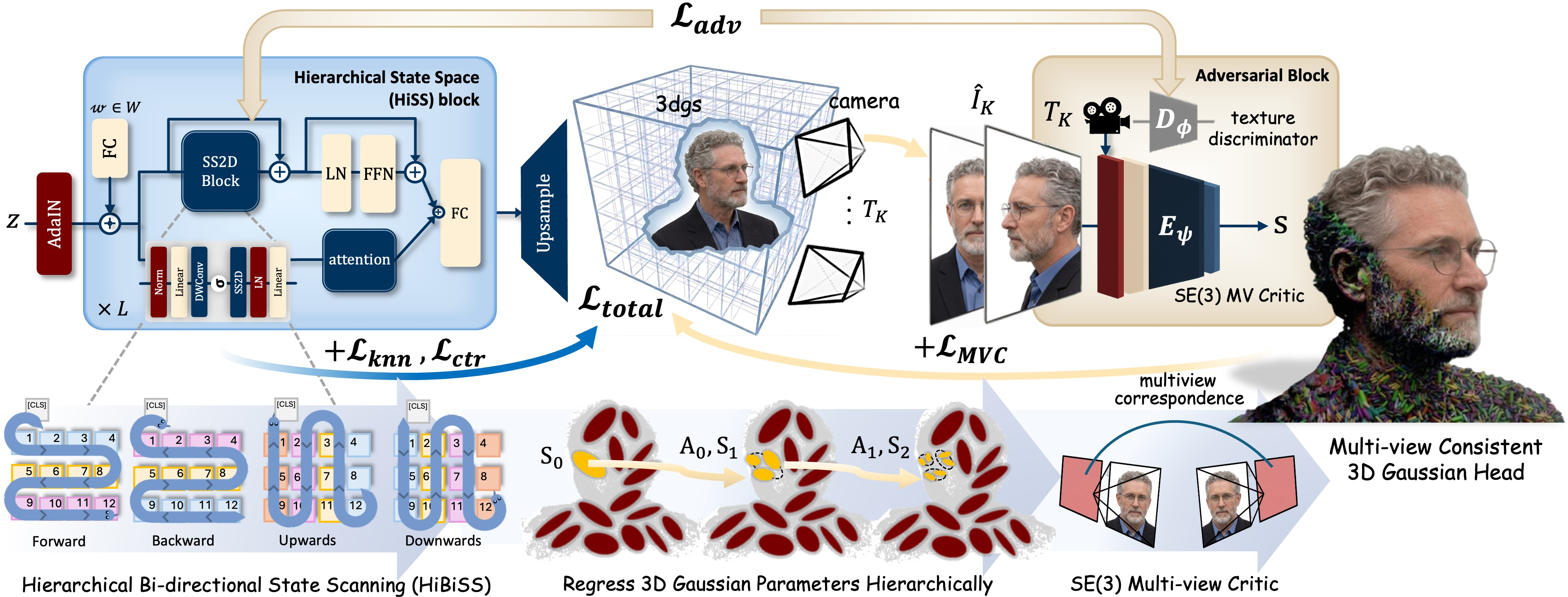
The authors combine three key ideas: a 3D building block called Gaussian splats, a special way of passing information across an image grid, and a “critic” that checks if different views belong to the same 3D head.
Building heads from tiny colored blobs
Instead of using a traditional 3D mesh, the method represents a head as a huge cloud of tiny, soft, colored blobs in 3D space, called “3D Gaussians.” Think of spraying very fine, colored mist to form a head. Each blob has a position, size, color, and transparency. When you “splat” all blobs onto a camera view, you get a photo-like image. With enough blobs placed carefully, you can create realistic faces with fine details.
Teaching the model with only photos
The model starts from a random code (like a seed) and predicts all the blobs for a single head in one pass. It learns by rendering images from random camera angles and comparing them to real photos so textures and lighting look natural. Importantly, it never sees real multi-view pairs of the same person. Instead, it learns consistency through clever design and a special training signal.
The model improves details in stages (coarse to fine). New blobs are added near existing ones so details refine the shape rather than drift around. This “hierarchical” process keeps the head stable as it gets more detailed.
Keeping views consistent: two ideas
- Hierarchical Bi-directional State Scan (HiBiSS): Imagine reading a page left-to-right, right-to-left, top-to-bottom, and bottom-to-top to make sure everything stays aligned. Faces often change horizontally when you turn your head left or right (yaw), and vertically when you nod up or down (pitch). HiBiSS passes information across the grid of features in both directions along rows and columns, helping the model keep shapes and textures lined up between views. It’s like smoothing out tiny misalignments exactly along the directions where faces tend to shift.
- SE(3) Multi-view Critic: This is a learned “referee” that looks at several rendered images of the same generated head from different camera positions and scores how likely they are to come from a single, consistent 3D object. If the views don’t match well (for example, the ear shape subtly changes or hairlines don’t line up), the score drops. The model is trained to maximize this score, so it naturally learns to produce heads that stay consistent across angles—without ever seeing real multi-view pairs of a person. “SE(3)” just means it uses camera positions and rotations correctly, without being confused by where the whole scene is placed.
What did they find, and why is it important?
The authors show that MVCHead:
- Produces very realistic 3D head renders, capturing tiny details like wrinkles, hair wisps, skin pores, and accessories.
- Keeps textures and geometry more consistent across different viewing angles than previous methods that either need multi-view data, 3D supervision, or generate intermediate views.
- Works in a “minimal-resource” setting: it does not need expensive multi-camera rigs, 3D scans, or extra view-synthesis steps.
In short, it reaches state-of-the-art quality and consistency while being simpler and more scalable to train.
They also release FaceGS-10K, a large set of ready-to-use synthetic 3D Gaussian head assets. This can help others train and test 3D head methods without dealing with privacy issues or costly 3D capture.
What could this lead to?
- Faster, cheaper creation of high-quality digital humans for AR/VR, games, film, and telepresence, since studios wouldn’t need multi-camera rooms or 3D scans.
- Safer, privacy-friendly avatars, because the model generates new, non-identifiable faces rather than copying real people.
- Better tools for creators and researchers, thanks to the FaceGS-10K dataset of synthetic 3D heads.
Simple limitations and future ideas: the method mainly covers front and side views (not full 360°), and it learns shape only from 2D supervision. Adding back-of-head training data, symmetry priors, or tougher training examples for the critic could push consistency even further.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed so future researchers can act on it.
- Limited view coverage: the model is trained on front/side views and cannot synthesize full 360° heads (especially back-of-head and top-of-head); data, priors, or augmentation strategies for unseen regions remain unspecified.
- No accuracy evaluation against real multi-view/3D ground truth: all MVC/shape metrics are self-referential (from the model’s own renders) rather than against captured scans or calibrated multi-view images; real-world geometric fidelity is unknown.
- SE(3) Multi-view Critic negatives are weak: negatives are different identities rather than “same-identity but inconsistent geometry” sets; the critic may mostly learn to detect identity differences instead of true cross-view inconsistencies; constructing and evaluating hard negatives is left open.
- Potential critic gaming/degenerate solutions: no analysis of whether the generator can increase the critic score via over-smoothing, opacity tricks, or texture blurring while losing detail; mechanisms to detect and prevent such failure modes are not provided.
- Critic bootstrapping and stability: the critic is trained purely on self-renders without real multi-view supervision; how it avoids reinforcing early-model biases, and how stable the joint training dynamics are (oscillations, collapse) is not analyzed.
- Sensitivity to the number of views K and pose sampling: the effect of K, pose distribution (yaw/pitch range), and sampling curriculum on MVC signal quality and gradients is not ablated.
- Assumption of upright heads and axis-aligned scans: HiBiSS aligns recurrences to image rows/columns and assumes roll ≈ 0; handling of non-upright heads, large roll angles, or arbitrary camera rotations is not addressed (e.g., rotation-equivariant scans).
- Invariance to intrinsics and lens effects is unvalidated: GTA claims intrinsics invariance, but generalization to varying focal lengths, distortions (e.g., fisheye), and crop/zoom changes in real cameras is not empirically tested.
- View-dependent appearance and lighting: the model uses per-Gaussian color without an explicit reflectance/shading model; consistency of specular highlights, shadows, and view-dependent effects across views is neither modeled nor evaluated.
- Backgrounds and silhouette handling: training uses unconstrained 2D images, but how backgrounds are modeled/segmented and how silhouette leakage or haloing is mitigated is not documented or evaluated.
- Lack of animation/rigging: the approach generates static heads and does not address expressions or jaw/eye articulation; integration with FLAME-like rigs or 4D controllability remains open.
- Disentanglement is unmeasured: appearance conditioning via AdaIN is claimed to decouple appearance from geometry, but there are no quantitative disentanglement metrics (e.g., identity/shape consistency under style changes) or controllability tests.
- Diversity and mode coverage: beyond FID, there is no quantification of identity diversity, demographic balance, hairstyle/accessory coverage, or mode collapse (e.g., distributional coverage metrics, PPL, feature-space diversity).
- Domain generalization and OOD robustness: performance on faces with extreme hairstyles, occlusions (hats, masks), unusual makeup, facial hair, ethnic/age diversity, or extreme poses/lighting is not systematically assessed.
- Metric standardization for MVC: MVC is measured via adapted MVGBench/MEt3R with many pipeline choices; sensitivity/robustness of these metrics to texture vs geometry, occlusions, or pose spacing is not studied, and a standardized benchmark protocol is not established.
- Dataset bias in FaceGS-10K: the assets are generated by the same model and filtered by its own consistency/realism criteria, risking “echo-chamber” bias; diversity, realism, and MVC statistics, and validation against real-world variation are not reported.
- Identity privacy and memorization: claims of non-identifiability are not substantiated with nearest-neighbor analyses or memorization tests against the 2D training set (e.g., FFHQ).
- Compute/memory and speed trade-offs: predicting 240K Gaussians is heavy, yet inference/render-time throughput, memory footprint, and scaling with the number of Gaussians/blocks are not reported; real-time deployment constraints are unclear.
- Architectural ablations are incomplete: there is no study of alternative SSM designs (e.g., rotation-aware scanning, local-convolutional SSMs), different upsampling ratios r, number of HiSS blocks L, or Gaussian budget N on MVC vs quality/speed trade-offs.
- Fairness and breadth of baselines: comparisons omit strong two-stage multi-view diffusion + 3D reconstruction pipelines under matched resource constraints and omit methods with 3D supervision on shared MVC metrics; cross-paradigm evaluation is missing.
- Robustness to camera distribution shift: the critic uses canonicalized poses; how MVC degrades under out-of-distribution camera rigs or pose distributions is not quantified.
- Occlusion-aware consistency: how the critic or losses handle self-occlusions (e.g., hair strands, ears behind hair) and visibility changes across views is not detailed; occlusion reasoning in consistency scoring remains open.
- Failure mode taxonomy: the paper lacks a qualitative analysis of typical errors (e.g., ear asymmetry, hair flicker, silhouette jitter, texture bleeding) and their correlation with pose, lighting, or hair complexity.
- Parameterization and optimization details: the effects of quaternion parameterization, opacity/scale constraints, and regularizers on stability and MVC are not systematically studied; alternative constraints (e.g., symmetry, anatomical priors) are proposed but not explored.
- Generalization to conditional tasks: the inversion-based personalization demo lacks quantitative identity preservation and MVC assessments; how inversion affects geometry/texture consistency is unexplored.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s tooling, leveraging MVCHead’s single-shot 3D Gaussian head generation, the SE(3) Multi-view Critic, and the released FaceGS-10K dataset.
- Sector: Games/Film/AR-VR content creation — Synthetic head asset libraries
- Use case: Rapidly populate scenes with high-fidelity, non-identifiable 3D head avatars for crowds, extras, and background actors without multi-view capture or per-asset optimization.
- Tools/products/workflows: “Gaussian Head Asset Factory” that samples latents → auto-renders K views → gates with the SE(3) Multi-view Critic → exports 3DGS assets or converts to meshes for Unreal/Unity.
- Assumptions/dependencies: Production pipeline support for 3D Gaussian Splatting (or robust splat-to-mesh conversion); currently best suited to front/side views; GPU inference for high-res assets.
- Sector: Social VR and telepresence — Privacy-preserving avatar catalogs
- Use case: Provide non-identifiable, view-consistent head avatars that users can pick and lightly personalize (e.g., hair color, skin tone) for meetings or virtual events.
- Tools/products/workflows: In-app “avatar picker” fed by MVCHead/FaceGS-10K; batch generation with identity filters; optional single-image inversion for mild personalization.
- Assumptions/dependencies: Real-time performance and expression animation are outside current scope (static head or limited motion); back-of-head coverage is limited.
- Sector: E-commerce (eyewear, audio wearables, hats) — 3D try-on mannequins
- Use case: Display products on diverse, realistic head forms that remain consistent across viewing angles for product pages and AR previews.
- Tools/products/workflows: Attribute-conditioned sampling (IPD approximation, skin tone, gender presentation) → align to standard rigs → render or convert to meshes for web viewers.
- Assumptions/dependencies: Limited back-of-head fidelity may affect hat/helmet demos; no guaranteed anthropometric ground truth.
- Sector: VFX/game QA — Multi-view consistency gate using the SE(3) Multi-view Critic
- Use case: Automated QC for multi-view diffusion outputs, reconstructions, or 3D assets by scoring cross-view consistency before asset acceptance.
- Tools/products/workflows: “SE3Critic” plugin for DCCs (Blender/Unreal) that ingests image sets + poses and outputs a consistency score with thresholds for pass/fail.
- Assumptions/dependencies: Critic must be exposed as a library/endpoint; thresholds require calibration per content type; trained invariances assume pose-only conditioning.
- Sector: Academia/ML — Benchmarking and training with FaceGS-10K
- Use case: Train 3D reconstruction models or multi-view generators without using personal data and benchmark MVC using adapted MVGBench/MEt3R scores.
- Tools/products/workflows: Public dataset consumption; baseline MVCHead for ablations on HiSS/HiBiSS and critic designs; integration with open-source 3DGS rasterizers.
- Assumptions/dependencies: Licensing/ethics for synthetic humans; dataset demography and attribute balance should be audited.
- Sector: Privacy tech / Media anonymization — Face replacement with synthetic heads
- Use case: Replace identifiable faces in videos with consistent, non-identifiable 3D heads while keeping scene geometry coherent across views.
- Tools/products/workflows: Track face pose → pick/generate a matching Gaussian head → render and composite per frame; SE(3) Critic monitors temporal-view consistency.
- Assumptions/dependencies: Current method is static (no expression or speech sync); relighting, expression transfer, and temporal stability require additional modules.
- Sector: XR device testing and calibration — Standardized head targets
- Use case: Use consistent 3D head assets to test rendering pipelines, stereo alignment, and face-occlusion handling across head poses.
- Tools/products/workflows: A curated subset of FaceGS-10K with canonical rigs and ground-truth camera poses; automated validation using the SE(3) Critic.
- Assumptions/dependencies: Requires standardized rigs and pose protocols; limited 360° coverage.
- Sector: HCI prototyping and education — Ready-to-use 3D head proxies
- Use case: Quickly add 3D head proxies to prototypes of face-centric UIs, interaction demos, and classroom labs on 3DGS/SSMs.
- Tools/products/workflows: Lightweight viewer and export scripts; teaching modules illustrating HiBiSS scanning and 3DGS rendering.
- Assumptions/dependencies: Students/developers need access to modern GPUs for rendering/experiments.
- Sector: Small/indie studios — Low-cost avatar creation without capture rigs
- Use case: Generate high-fidelity heads from 2D-only training data for indie games and indie films lacking scanning budgets.
- Tools/products/workflows: “One-click Avatar Batch” SaaS; QC via SE(3) Critic; optional inversion from a single reference image.
- Assumptions/dependencies: Personalization via inversion is feasible but not the primary focus; domain shift can occur for non-FFHQ-like imagery.
- Sector: Data curation — Filtering and ranking synthetic multi-view sets
- Use case: Rank multi-view outputs from external pipelines by cross-view consistency to assemble higher-quality datasets.
- Tools/products/workflows: Batch scoring API wrapping the SE(3) Critic; tie-breaking via texture realism discriminator.
- Assumptions/dependencies: Critic generalization to different styles/domains should be validated; careful thresholding needed.
Long-Term Applications
These opportunities require further research or engineering (e.g., 4D dynamics, full 360° coverage, optimization for real-time deployment), but are natural extensions of MVCHead’s findings and methods.
- Sector: Real-time telepresence — Fully animatable 4D head avatars
- Use case: Expressive, full-rotation (360°) avatars driven by facial capture/audio for meetings, livestreaming, and games.
- Tools/products/workflows: Extend MVCHead with expression- and audio-driven dynamics; rigging over 3DGS (or hybrid mesh-splat) with pose- and lighting-aware rendering.
- Assumptions/dependencies: Training on expression/phoneme data; back-of-head modeling; low-latency inference; robust relighting.
- Sector: Full-body digital humans — Head–body integration
- Use case: Seamlessly combine consistent heads with articulated bodies for virtual production and simulation.
- Tools/products/workflows: Joint head–body Gaussian generators; skeleton/skin rigs; cross-part MVC critics for global consistency.
- Assumptions/dependencies: Large-scale 2D-only supervision for bodies or mixed supervision; efficient rendering at scene scale.
- Sector: Healthcare/telemedicine — Privacy-preserving patient avatars
- Use case: Share patient cases using de-identified but anatomically plausible avatars for consults, training, or triage simulations.
- Tools/products/workflows: Inversion with identity obfuscation constraints; controlled attribute sliders (age, ethnicity presentation) for fair depiction.
- Assumptions/dependencies: Clinical validation and ethics approval; accuracy requirements vary by use; regulated environments.
- Sector: Robotics/AV simulation — Synthetic humans for perception training
- Use case: Populate simulated environments with diverse, consistent head models to improve detection, tracking, and HRI robustness.
- Tools/products/workflows: Domain-randomized head libraries with controlled pose/lighting; integration into sim engines (CARLA, Isaac).
- Assumptions/dependencies: Bridging sim-to-real gap; potential bias in synthetic distributions; licensing for redistribution.
- Sector: Biometrics R&D — Safe testbeds for recognition/anti-spoofing
- Use case: Evaluate algorithms on non-identifiable but realistic avatars with controlled variations (pose, illumination, occlusion).
- Tools/products/workflows: Protocols using FaceGS-10K-like datasets; extended MVC metrics; perturbation-based negative sets for harder test cases.
- Assumptions/dependencies: Synthetic-to-real generalization; policy acceptance for benchmark use; careful governance to avoid misuse.
- Sector: Mobile apps — On-device avatar generation
- Use case: Generate avatars from selfies on smartphones/AR glasses.
- Tools/products/workflows: Compressed MVCHead variants; approximate 3DGS renderers or neural rasterizers optimized for mobile NPU/GPU.
- Assumptions/dependencies: Model compression and quantization; power/thermal limits; privacy-preserving on-device inference.
- Sector: Standards and policy — MVC quality and disclosure norms
- Use case: Incorporate cross-view consistency scores and SE(3)-aware critics into industry standards for synthetic human quality and content disclosure.
- Tools/products/workflows: Open benchmarks (MEt3R- and MVGBench-style) and certified QC toolkits; dataset cards for synthetic human asset libraries.
- Assumptions/dependencies: Multi-stakeholder adoption; transparent metrics; ongoing bias and representativeness audits.
- Sector: Advanced retail/virtual fitting — Accurate anthropometric control
- Use case: High-fidelity, size-accurate virtual try-on for wearable products requiring ear/temporal geometry precision (eyewear, AR glasses).
- Tools/products/workflows: Latent-space controls or conditional generative modeling tied to anthropometric priors; 360° coverage and ear geometry emphasis.
- Assumptions/dependencies: Ground-truth anthropometry for calibration; improved back-of-head quality and controllability.
- Sector: Security/forensics — Multi-view deepfake detection
- Use case: Detect cross-view inconsistencies in malicious content by adapting SE(3) Critics to spot non-physical view sets.
- Tools/products/workflows: Forensic toolkits that score multi-view assets/videos for consistency under varying poses.
- Assumptions/dependencies: Domain adaptation of the critic; adversarial robustness; access to multi-view or multi-frame evidence.
- Sector: Engine interoperability — Robust Gaussian-to-mesh pipelines
- Use case: Port high-fidelity heads into engines that lack native 3DGS support while preserving cross-view fidelity.
- Tools/products/workflows: Differentiable splat-to-mesh conversion with MVC-aware losses; hybrid representations (splat textures on coarse meshes).
- Assumptions/dependencies: High-quality conversion algorithms; performance trade-offs at runtime.
- Sector: Research tooling — Generalized SE(3) critics for 3D QA
- Use case: Extend pose-aware critics to other 3D domains (objects, scenes) to enforce global consistency without multi-view ground truth.
- Tools/products/workflows: Task-agnostic SE(3) critic libraries; integration with training loops as differentiable rewards.
- Assumptions/dependencies: Domain-specific adaptations; meaningful negative-set construction for stable training.
Notes on feasibility and dependencies (cross-cutting)
- Current limitations from the paper: limited 360° coverage (back-of-head), no expression/temporal dynamics (static heads), 2D-only supervision (no explicit geometric ground truth), and model biases from FFHQ-like training distributions.
- Infrastructure: 3D Gaussian Splatting renderer support is needed for best visual fidelity; for engines without 3DGS, conversion to meshes may reduce detail.
- Performance: While MVCHead is single-shot, high-fidelity outputs (≈240K Gaussians/head) still require modern GPUs; real-time use cases need optimization.
- Governance: Synthetic human assets reduce privacy risks but require clear disclosure, bias audits, and license clarity for commercial deployment.
Glossary
- 3DGS rasterizer: A renderer that converts 3D Gaussian splats into images by rasterization. "The resulting set of 3D Gaussians is processed by a 3DGS rasterizer~\cite{kerbl20233d}."
- AdaIN: Adaptive Instance Normalization; a conditioning layer that modulates features with learned scale and bias to control style/appearance. "we apply disentangled appearance conditioning via AdaIN layers~\cite{huang2017arbitrary}."
- adversarial texture discriminator: A GAN discriminator focused on ensuring realistic textures in rendered images. "an adversarial texture discriminator that ensures high-frequency realism and stylistic alignment with the training distribution;"
- anisotropic Gaussians: 3D Gaussian primitives with direction-dependent scales (covariances) used to represent surfaces. "We aim to learn a generative mapping from a latent code to a 3D head, represented as a set of anisotropic Gaussians~\cite{kerbl20233d}."
- ArcFace: A margin-based face recognition loss used to preserve identity when optimizing a personalized avatar. "minimize an ArcFace-based identity preservation loss~\cite{deng2019arcface}."
- Chamfer Distance (CD): A bidirectional distance between point sets, commonly used to compare 3D shapes. "We assess shape consistency using Chamfer Distance and depth error."
- cLPIPS: Cross-view LPIPS; a perceptual similarity metric adapted to evaluate consistency between renders from different views. "where "
- cPSNR: Cross-view PSNR; measures pixel-wise fidelity between cross-view renders to assess texture consistency. "where "
- cSSIM: Cross-view SSIM; structural similarity across views to quantify texture stability under pose changes. "where "
- DINO: A self-supervised Vision Transformer used to extract semantic features for geometric consistency evaluation. "and FeatUp-DINO~\cite{fu2024featup, caron2021emerging} for measuring feature agreement with a view-invariant encoder"
- differentiable splatting renderer: A rendering operator that maps 3D Gaussians to images with gradients for end-to-end learning. "A differentiable splatting renderer maps and a camera pose to an image:"
- epipolar-consistent correspondence: Pixel matches between two views that satisfy epipolar geometry constraints. "Using MASt3R~\cite{leroy2024grounding} for estimating epipolar-consistent correspondence"
- extrinsics: Camera pose parameters (rotation and translation) that locate the camera in space. "We inject extrinsics by anchoring all poses relative to the first view "
- FeatUp: A method to upsample feature maps, improving resolution for dense correspondence. "and upsample them with FeatUp~\cite{fu2024featup} to obtain high-resolution feature maps"
- FID: Fréchet Inception Distance; measures distributional similarity of generated images to real ones. "We use FID to assess the perceptual realism of rendered views from generated 3D Gaussian head avatars."
- FID_3D: A variant of FID computed over wider camera pose distributions to test realism across viewpoints. "we also report FID$_{\text{3D}$~\cite{barthel2025cgs},"
- FLAME: A parametric 3D head/face model used for rigging or supervising facial geometry. "GaussianAvatars~\cite{qian2024gaussianavatars} rigs Gaussians to FLAME~\cite{li2017learning};"
- Geometric Transform Attention (GTA): An attention mechanism that embeds SE(3) structure for pose-aware token alignment, yielding equivariance/invariance properties. "Geometric Transform Attention (GTA)~\cite{miyato2023gta} addresses it by embedding SE(3) structure directly into the attention"
- Hierarchical Bi-directional State Scan (HiBiSS): A bidirectional, axis-aligned state space scanning scheme across rows and columns to propagate consistency. "we modify Mamba's standard unidirectional scan with the proposed Hierarchical Bi-directional State Scan (HiBiSS)"
- Hierarchical State Space (HiSS) block: A hierarchical module that refines Gaussians from coarse to fine using state space and attention mixers. "we propose a Hierarchical State Space (HiSS) block that progressively refines Gaussians from coarse to fine"
- intrinsics: Camera internal parameters (e.g., focal lengths) describing projection characteristics. "ensuring equivariance to global rigid transforms and invariance to intrinsics."
- Jacobian: The matrix of partial derivatives describing how image coordinates change with small parameter variations (e.g., rotations). "are the pitch and yaw Jacobians at ."
- Kalman filtering: A recursive estimator for linear dynamical systems, foundational to classical state space models. "State Space Models (SSMs) originate from classical linear dynamical systems and Kalman filtering~\cite{kalman1960new}."
- MASt3R: A method for pose-free stereo reconstruction used to compute view-consistent correspondences. "Using MASt3R~\cite{leroy2024grounding} for estimating epipolar-consistent correspondence"
- Mamba: A selective state space model architecture enabling long-range dependencies with input-dependent projections. "Mamba~\cite{gu2024mamba} extends S4 by replacing its fixed hidden-space projection matrices with an input-dependent selective projection mechanism."
- MEt3R: A metric for measuring multi-view consistency directly from image pairs without pose or 3D ground truth. "we adapt scores from two SOTA frameworks: MVGBench~\cite{xie2025mvgbench} and MEt3R~\cite{asim2025met3r}"
- MVGBench: A benchmark framework for assessing multi-view generation and consistency. "we adapt scores from two SOTA frameworks: MVGBench~\cite{xie2025mvgbench} and MEt3R~\cite{asim2025met3r}"
- quaternion: A 4D rotation representation used to parameterize 3D rotations of Gaussian splats. "is a unit quaternion defining a rotation matrix ,"
- R1 gradient penalty: A regularization term in GAN training that stabilizes the discriminator by penalizing gradient norm on real data. "A standard camera-conditioned adversarial loss with an R1 gradient penalty."
- SE(3): The group of 3D rigid motions (rotations and translations). "a camera pose to an image"
- SE(3) Multi-view Critic: A pose-aware critic that scores whether a set of renders is consistent with a single 3D configuration. "we design an SE(3) Multi-view Critic that judges whether a set of self-renders arises from a single underlying 3D configuration"
- SO(3): The group of 3D rotations; used for rotation matrices derived from quaternions. ","
- SS2D: A 2D selective state space scanning module adapted for grid-structured inputs. "by adapting SS2D~\cite{liu2024vmamba} to the hierarchical Gaussian prediction setting:"
- State Space Model (SSM): A sequence model that updates hidden states via linear or structured dynamics to capture long-range dependencies. "State Space Models (SSMs) originate from classical linear dynamical systems and Kalman filtering~\cite{kalman1960new}."
- Structured State Space Sequence (S4): A structured SSM family enabling efficient, long-range sequence modeling. "Gu~et al. introduced the modern Structured State Space Sequence (S4) family, which demonstrated strong long-range dependency modeling"
- ViT-style design: An architecture patterned after Vision Transformers, using patch tokens and attention blocks. "Architecturally, follows a ViT-style design augmented with GTA~\cite{miyato2023gta}."
Collections
Sign up for free to add this paper to one or more collections.