- The paper introduces BD-RFSQ to structurally separate emotion and acoustic features, ensuring emotion preservation during speech compression.
- It employs a dual-path architecture with multi-rate training and affine normalization to maintain robust affect fidelty at low bitrates.
- Empirical evaluations on multiple benchmarks show significant reductions in emotion degradation while retaining competitive perceptual quality.
Emotion-Preserving Neural Speech Coding via Block-Diagonal Residual FSQ
Motivation and Problem Statement
Neural speech codecs increasingly serve as the discrete intermediaries between raw audio and speech LLMs (SLMs), transforming continuous speech signals into tokenized representations for downstream generative tasks. Traditional codecs are optimized primarily for perceptual reconstruction fidelity, often neglecting preservation of affective information. As SLMs target emotionally rich applications—empathetic dialogue, mental health analysis, expressive speech synthesis—the capacity to retain emotion-relevant cues during compression becomes critical. However, existing codecs systematically degrade emotion features, as evidenced by substantial drops in speech emotion recognition (SER) performance post-compression, even at moderate bitrates. The paper identifies two primary mechanisms responsible for this degradation: reconstruction-driven bit allocation, which sacrifices affective cues under bitrate constraints, and cross-stream leakage, where emotion-designated latent dimensions are contaminated by acoustic gradients due to fully connected quantizer architectures. Addressing these mechanisms necessitates structural, not merely loss-driven, protection of affective information within the quantizer.
AffectCodec: Architecture and Quantization Principle
AffectCodec introduces Block-Diagonal Residual Finite Scalar Quantization (BD-RFSQ) to enforce explicit structural guarantees for emotion preservation. The codec employs a dual-path architecture: an acoustic encoder supplies high-dimensional spectral representations, while a frozen emotion2vec encoder delivers frame-level affective features, aligned to codec frame rate via convolutional adapters. Emotion information is integrated at two granularities: global affect vectors modulate the acoustic pathway through FiLM layers, and local emotion features are discretized via BD-RFSQ.
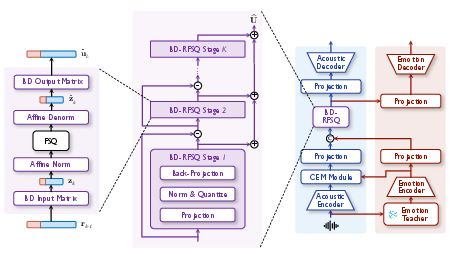
Figure 1: Internal structure of a single BD-RFSQ stage, illustrating block-diagonal partitioning of emotion and acoustic subspaces for quantization.
BD-RFSQ operates by constraining learnable input/output projections to be block-diagonal, strictly partitioning emotion and acoustic subspaces throughout residual quantization stages. Each stage quantizes both partitions independently, preventing cross-stream overwriting by acoustic reconstruction gradients—a property formally proven in the appendices. This maintains per-stage composite tokens, ensuring compatibility with flat-token SLM interfaces. The token format affords uniform handling and integration within downstream modeling pipelines.
Algorithmic Enhancements and Training Procedures
To maximize robustness at low bitrates—where affective degradation is most severe—AffectCodec incorporates multi-rate training with explicit supervision at intermediate quantization depths. Multi-rate reconstruction losses are imposed at several stage counts, combining mel-spectrogram reconstruction and emotion cycle-consistency losses. A biased stage dropout strategy further concentrates optimization on low-bitrate regimes.
Affine normalization addresses residual magnitude decay across quantization stages, replacing data-dependent LayerNorm with fully learnable per-dimension affine transformations. This approach enables end-to-end training and supports index-only decoding, eliminating reliance on runtime statistics.
Comparative Evaluation and Ablation Analysis
Experiments span multiple emotional speech benchmarks (IEMOCAP, CREMA-D, ESD), evaluating AffectCodec against strong baselines (EnCodec, DAC, X-Codec, SpeechTokenizer) at bitrates from 1.5 to 6.0 kbps. Primary emotion preservation metrics include Emotion Degradation Rate (EDR) and Valence/Arousal/Dominance (V/A/D) MSE, measured using independently trained SER classifiers to avoid evaluation bias. AffectCodec achieves substantial reductions in EDR across all datasets and bitrates, with the most pronounced gains at 1.5 and 3.0 kbps—conditions under which prior codecs degrade sharply (see tabulated results in the original paper). Notably, AffectCodec retains competitive perceptual quality and intelligibility (ViSQOL, STOI, WER) relative to acoustic-focused codecs, demonstrating a favorable trade-off between emotion fidelity and signal reconstruction.
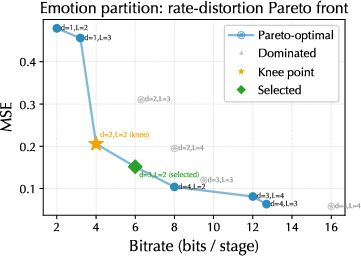
Figure 2: Rate-distortion Pareto front for the emotion FSQ partition, showing optimal configurations for emotion quantization and the selected operating point.
Ablation studies quantify the contribution of each component. Removing BD-RFSQ, multi-rate training, or the coarse-granularity emotion module significantly worsens emotion preservation. The block-diagonal constraint in BD-RFSQ yields the largest impact, confirming the theoretical analysis of cross-stream leakage. Empirical probes reveal that unconstrained quantizers exhibit much higher linear decodability of acoustic features from emotion-designated dimensions, reflecting catastrophic gradient leakage. BD-RFSQ reduces this by a factor of five.
Practical and Theoretical Implications
AffectCodec provides a general mechanism for structurally protecting designated speech attributes against quantization-induced degradation, enabling attribute-aware compression conducive to high-fidelity downstream generative modeling. The architecture preserves the flat-token format required by SLMs, facilitating seamless integration with scalable LLM pipelines. Structurally enforced bit allocation supersedes traditional loss balancing, delivering reliable attribute retention under strict bitrate constraints.
From a theoretical perspective, the block-diagonal quantization framework opens pathways for codec design targeting preservation of other non-acoustic attributes (prosody, speaker identity, linguistic content), given appropriate partitioning and supervision modules. The multi-rate training paradigm can be extended to cover additional operational secondary objectives, such as phonetic intelligibility or semantic preservation.
Speculation on Future Developments in AI
The demonstrated ability to structurally retain affective cues at low bitrates will likely accelerate research in emotion-aware generative speech models, conversational AI, and telecommunication platforms optimized for affect transmission. Attribute-aware neural compression, as instantiated via BD-RFSQ, is anticipated to serve as a foundation for SLMs that flexibly compose and edit speech with both acoustic and expressive fidelity. Future work may investigate automatic discovery and allocation of latent partitions for arbitrary attribute sets, potentially using adversarial separation or optimization-driven partition search.
Expanding evaluation to include downstream generative tasks (e.g., emotional speech synthesis, empathetic dialogue generation) will clarify the real-world utility of attribute-preserving codecs. Long-term, integration with watermarking or transparency mechanisms can mitigate abuse, ensuring responsible deployment of emotion-capable speech technologies.
Conclusion
AffectCodec advances neural speech coding by introducing BD-RFSQ, architecturally enforcing structural separation and explicit bit allocation for emotion and acoustic information. This yields strong gains in emotion preservation at low bitrates without sacrificing signal fidelity. The method offers a principled path toward attribute-aware speech compression, compatible with flat-token SLM architectures. Empirical and theoretical analyses confirm that structural protection is essential for reliable attribute retention under bandwidth constraints, informing future codec design for emotionally rich AI speech systems.

