- The paper introduces a novel streaming architecture via a multi-stage causal distillation framework that enables low-bitrate (0.55–0.80 kbps) and low-latency (80 ms) speech coding.
- It employs a hybrid codec design with a causal encoder, compressor, quantizer, and a lightweight refiner module to maintain semantic and acoustic fidelity under streaming constraints.
- Experimental results demonstrate significant improvements in speech resynthesis, voice conversion, and downstream task performance, especially in multilingual and cross-domain scenarios.
FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation
Introduction and Motivation
FocalCodec-Stream addresses the challenge of real-time, low-bitrate speech coding for neural audio codecs (NACs), which are increasingly central to generative audio pipelines and speech LLMs (SLMs). While recent NACs achieve high-fidelity reconstruction and provide discrete representations suitable for downstream tasks, most are non-streamable due to reliance on long future context, making them unsuitable for interactive or low-latency applications. FocalCodec-Stream proposes a hybrid codec architecture that compresses speech into a single binary codebook at 0.55–0.80 kbps with a theoretical latency of 80 ms, targeting both high reconstruction quality and preservation of semantic and acoustic information under strict streaming constraints.
Architecture and Causal Distillation Framework
FocalCodec-Stream builds on the original FocalCodec architecture, introducing several modifications to enable streaming with low latency. The system comprises a streamable encoder, compressor, binary quantizer, decompressor, and decoder, all designed for causal operation. The encoder is derived from the first six layers of WavLM-large, modified to use causal convolutions and sliding window gated relative chunked attention, with chunking introducing a controlled lookahead within the latency budget. The compressor and decompressor employ focal modulation with causal convolutions and large-kernel causal pooling, while the quantizer uses binary spherical quantization, which is inherently streamable. The decoder is based on a causal variant of Vocos, replacing ConvNeXt blocks with causal convolutions and using a linear projection for waveform reconstruction.
A key innovation is the introduction of a lightweight refiner module after the decompressor, implemented as a residual chunk-wise feed-forward layer. This module leverages the available latency to better align the causal features with their non-causal counterparts, mitigating the distribution shift introduced by streaming constraints.
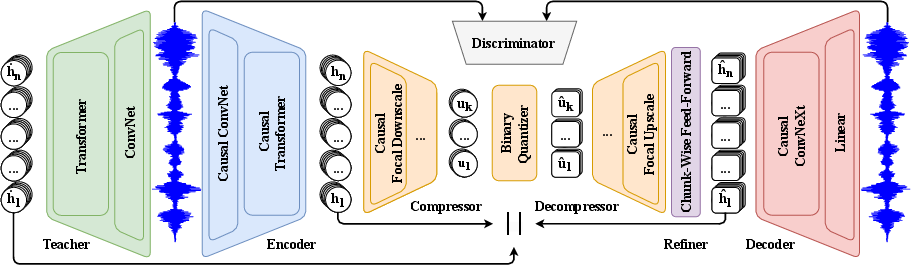
Figure 1: FocalCodec-Stream architecture, illustrating the causal encoder, compressor, quantizer, decompressor, and decoder, with a non-causal teacher for distillation.
The core of the training strategy is a multi-stage causal distillation framework:
- Stage 1: Causal distillation of the positional embedding, which in the original WavLM relies on a large receptive field incompatible with streaming. The causal variant is trained to approximate the full-context embedding via L2 loss.
- Stage 2: Distillation of the attention and convolutional feature extractor, converting them to causal form and aligning each layer with the full-context teacher using weighted L2 losses.
- Stage 3: Training the causal compressor–quantizer–decompressor stack on top of the causally distilled encoder, with the decoder trained on full-context features.
- Stage 4: Joint fine-tuning of the entire stack, including the refiner, to close the gap between the decoder and the decompressor outputs, further improving reconstruction quality.
Experimental Setup
The system is evaluated primarily in the 50 Hz token rate regime, with codebook sizes of 2k, 4k, and 65k, and supports both 16 kHz and 24 kHz audio. The training pipeline progressively scales data and chunk sizes across distillation stages, culminating in training on the full Libri-Light corpus (60k hours) for the final stage. The decoder is trained separately on clean LibriTTS data at 24 kHz. All models are trained on NVIDIA A100 GPUs, with careful tuning of learning rates and model capacity to compensate for the performance degradation introduced by causality.
Results and Analysis
Speech Resynthesis and Voice Conversion
FocalCodec-Stream demonstrates strong performance on speech resynthesis (SR) and one-shot voice conversion (VC) tasks. On LibriSpeech, the 65k variant achieves UTMOS and dWER scores close to the non-streaming FocalCodec baseline, outperforming all streamable baselines in intelligibility and speaker similarity. Code usage and entropy metrics indicate efficient quantizer utilization. In multilingual SR, FocalCodec-Stream variants remain competitive, with the 65k model achieving the best trade-off between intelligibility and speaker fidelity. Notably, supervised adaptation approaches such as PAST exhibit poor generalization to multilingual data, highlighting the robustness of the proposed distillation framework.
In VC experiments, FocalCodec-Stream achieves the highest naturalness and speaker similarity among streaming codecs, with the 65k variant maintaining low dWER and high speaker similarity, outperforming both acoustic and hybrid baselines.
FocalCodec-Stream is evaluated on a suite of discriminative (ASR, SI, SER, KS, IC) and generative (SE, SS) downstream tasks. Across discriminative tasks, all variants achieve competitive error rates, with the 65k model excelling in SI and the 4k model in SER. On generative tasks, FocalCodec-Stream achieves high DNSMOS and speaker similarity, with dWER values surpassing all baselines except PAST, which trades off speech quality for ASR performance. The 2k variant, with its compact codebook, is particularly well-suited for autoregressive modeling in SLMs.
Ablation Studies
Ablation experiments confirm the importance of the refiner module and the final fine-tuning stage. Removing the refiner degrades UTMOS, dWER, and similarity, while omitting the final stage has an even stronger negative impact. This underscores the necessity of the progressive multi-stage distillation and adaptation strategy for maintaining quality under low-latency constraints.
Implications and Future Directions
FocalCodec-Stream establishes a new state-of-the-art for streamable, low-bitrate speech coding, achieving a favorable balance between reconstruction quality, downstream task performance, latency, and efficiency. The single-codebook, hybrid design enables preservation of both semantic and acoustic information, making the codec suitable for integration into real-time SLMs, speech assistants, and interactive dialogue systems. The causal distillation framework provides a general recipe for adapting full-context self-supervised models to streaming settings, with potential applicability to other modalities and tasks.
The results highlight several important implications:
- Single-codebook, low-bitrate streaming is feasible without sacrificing downstream utility, provided that careful architectural and training adaptations are made.
- Causal distillation from large, full-context models is effective for preserving both reconstruction and representational quality, even under strict latency constraints.
- Hybrid codecs with semantic enrichment outperform purely acoustic codecs in both resynthesis and downstream tasks, especially in multilingual and cross-domain scenarios.
Future work should explore scaling to larger and more diverse datasets, further reducing latency and computational requirements for deployment on resource-constrained devices, and extending the approach to support autoregressive modeling and end-to-end speech generation.
Conclusion
FocalCodec-Stream presents a comprehensive solution for streaming, low-bitrate speech coding, combining a causally adapted architecture with a multi-stage distillation framework. The system achieves strong numerical results across a range of tasks and outperforms existing streamable codecs at comparable bitrates. The approach demonstrates that high-quality, semantically rich, and efficient speech coding is achievable in real-time settings, with broad implications for the design of future speech and audio generative models.