- The paper introduces WorldKV, a training-free framework that employs retrieval and compression to overcome KV-cache limitations in autoregressive video models.
- It leverages CPU/GPU memory indexing by camera/action state to selectively retrieve redundant tokens and nearly doubles historical context under a fixed memory budget.
- Experimental results demonstrate that WorldKV maintains comparable revisit fidelity to full KV-cache methods while significantly improving real-time throughput and reducing computational overhead.
WorldKV: Efficient World Memory with World Retrieval and Compression
Introduction
"WorldKV: Efficient World Memory with World Retrieval and Compression" (2605.22718) addresses a critical bottleneck in autoregressive video diffusion models used for real-time interactive world generation. These models depend on causal attention and key-value (KV) caching for high-throughput frame generation, yet sustaining persistent world memory across long rollouts is constrained by the linear growth in memory footprint and computational cost. Sliding-window inference solutions sacrifice long-term revisit consistency, while full KV-cache attention is infeasible for real-time applications due to excessive resource consumption. The paper introduces WorldKV, a training-free framework that delivers efficient, scalable world memory by augmenting sliding-window inference with memory retrieval and compression.
Emergent KV-Based Memory and Its Bottlenecks
The KV cache in autoregressive video models is not merely a computational artifact but constitutes emergent spatial-temporal memory. When permitted to attend to the entire KV cache, models trained only on short sequences (e.g., Matrix-Game-2.0) exploit this cache to reproduce previously encountered viewpoints faithfully, thereby demonstrating a fundamental capability for long-term world memory even without explicit memory training. However, the linear increase in cache size with rollout length leads to both out-of-memory failures and severe inference throughput degradation. For example, LingBot-World-Fast's FPS drops from 8.87 to 3.61 as rollout length extends, and cache usage quickly exceeds GPU VRAM constraints.
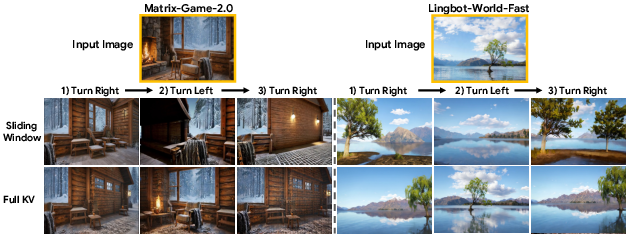
Figure 1: Emergent memory from attending Full KV cache, where long-term spatial-temporal consistency is maintained even in models trained on short sequences.
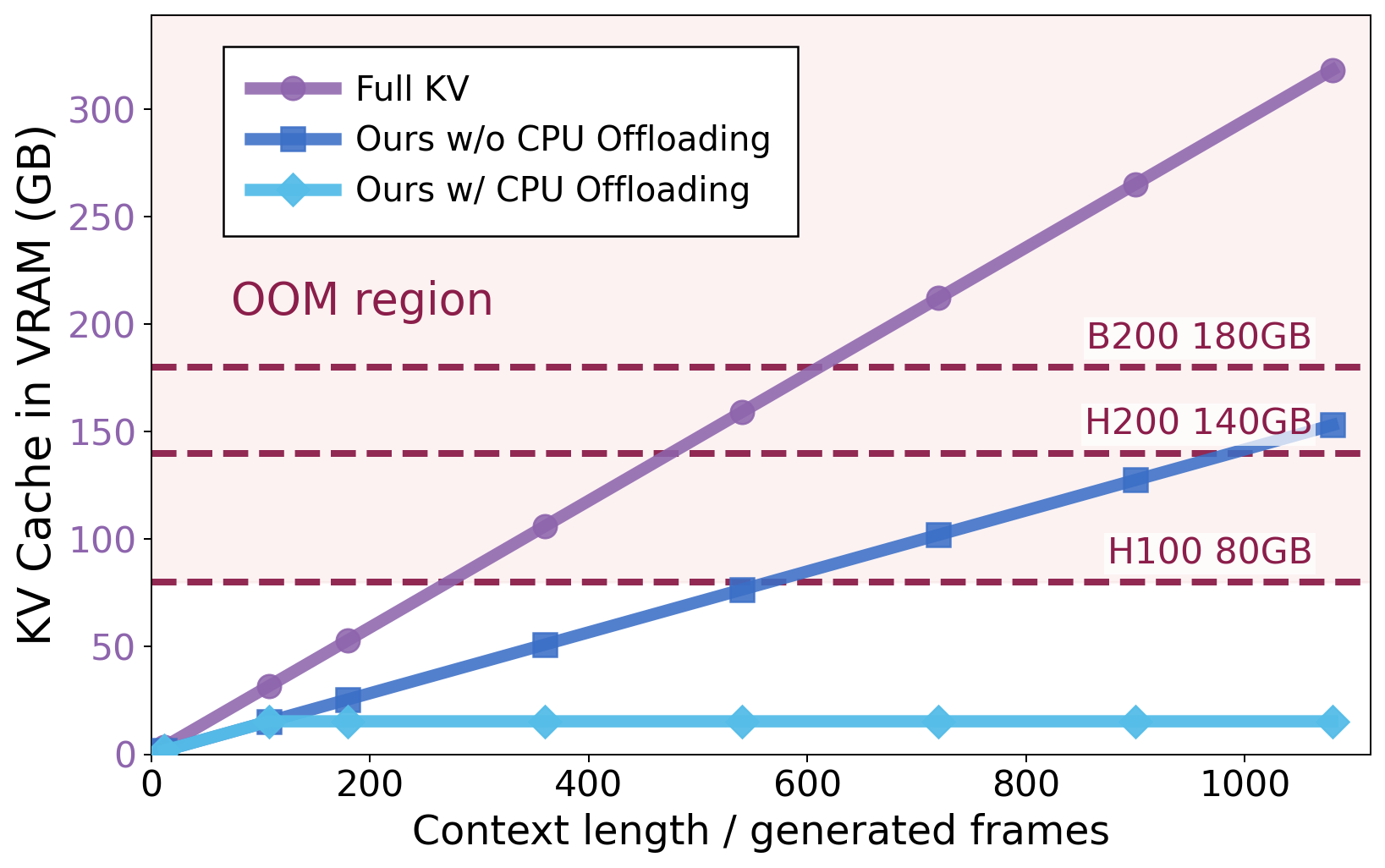
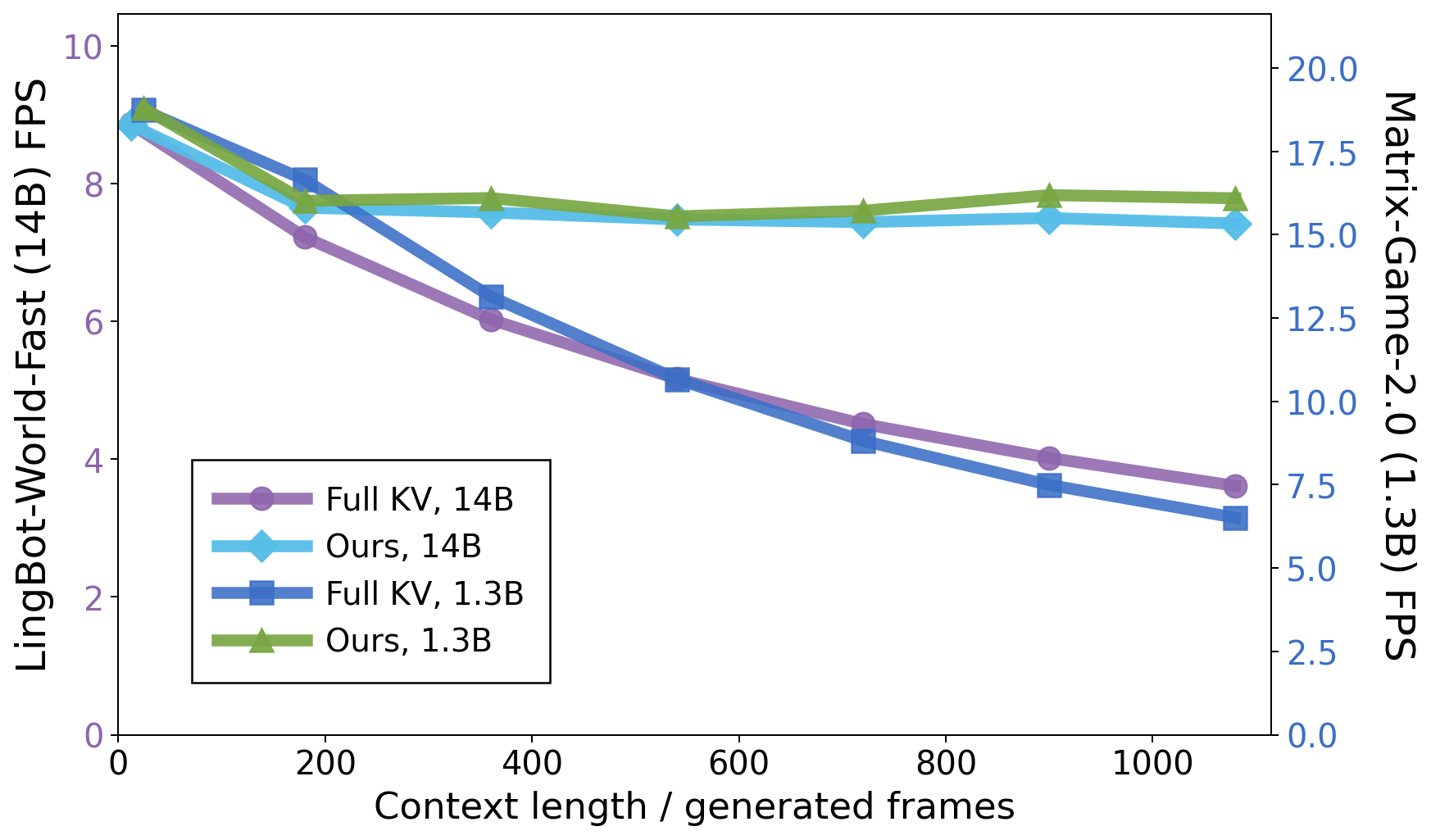
Figure 2: KV cache size (LingBot-World-Fast 14B), illustrating rapid VRAM exhaustion under full KV cache attention.
WorldKV Framework: Retrieval and Compression
WorldKV circumvents the limitations of both full KV-cache attention and sliding-window inference via two synergistic components:
- World Retrieval: Stores evicted KV-cache chunks in CPU/GPU memory, indexed by camera/action state, and selectively retrieves viewpoint-relevant caches during revisits. Retrieval is modular and algorithm-agnostic, supporting both camera/action-based heuristics and query-based (attention score) selection.
- World Compression: Exploits redundancy among temporally adjacent frames within each chunk via key-key cosine similarity. By pruning tokens highly similar to a designated anchor frame, compression achieves approximately 2× more history under a fixed memory budget, retaining only distinctive tokens for future retrieval.
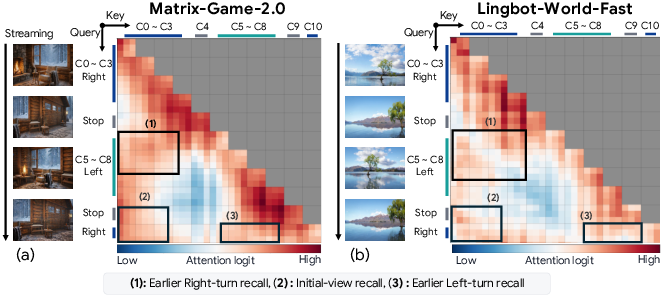
Figure 3: Attention maps reveal that models assign high attention to KV caches with overlapping viewpoints, motivating retrieval by camera/action relevance.
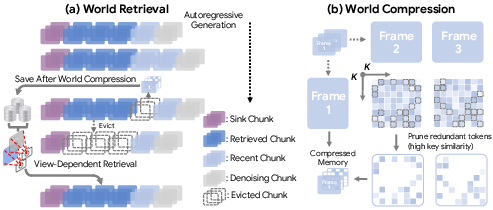
Figure 4: Overview of WorldKV. (a) KV chunks are stored compressed and retrieved at revisit time; (b) compression prunes tokens redundant with the anchor frame.
Experimental Evaluation
Benchmarks and Methodology
The paper assesses WorldKV across two architectures: Matrix-Game-2.0 (not memory-trained; native 6-frame sliding window, 1.3B parameters) and LingBot-World-Fast (memory-trained; full KV cache, 14B parameters). Evaluation spans 60 scene-trajectory pairs with diverse visual content, measuring scene revisit consistency via PSNR, SSIM, LPIPS, and FID.
Quantitative Findings
WorldKV achieves strong numerical results, matching or surpassing full KV-cache attention and memory-trained baselines (WorldPlay, Yume-1.5) in revisit fidelity while maintaining real-time throughput. Specifically, on LingBot-World-Fast, WorldKV closes the performance gap with full KV-cache attention (LPIPS: 0.455 vs. 0.441; PSNR: 15.660 vs. 15.901) at roughly double the throughput. On Matrix-Game-2.0, WorldKV outperforms full KV-cache, demonstrating superior revisit fidelity metrics despite lack of explicit memory training in the backbone.
Ablations
Compression ratio ablations indicate that moderate retention rates (3→1.5 frames per chunk) yield optimal memory fidelity, showing that retained anchor tokens are not sufficient—distinctive tokens must also be preserved. Retrieval algorithm comparisons show that both camera/action-based and query-based strategies significantly outperform sliding-window inference, with camera/action-based retrieval slightly superior.
Qualitative Analysis
WorldKV delivers faithful frame regeneration during revisits in multi-loop trajectories, maintaining scene structure and appearance over extended rollouts without hallucinations or drift. Selective retrieval and compression can outperform full KV-cache attention by mitigating attention dilution, echoing findings in long-context LLMs.

Figure 5: Frame-by-frame comparison across methods on two trajectories, demonstrating WorldKV's superiority in consistent visual memory.
Broader Applicability
WorldKV generalizes beyond the tested models, as demonstrated by application to Inspatio-World, a real-time 4D world simulator not memory-trained on long sequences. With WorldKV, Inspatio-World maintains long-term scene persistence across novel-view revisits, underscoring the method's universality for KV-cache-based autoregressive video architectures.

Figure 6: Applying WorldKV enables Inspatio-World to preserve memory consistency across repeated viewpoint revisits.

Figure 7: Additional frame-by-frame comparisons show robust memory fidelity across varied trajectories and methods.
Practical and Theoretical Implications
WorldKV provides a training-free mechanism for deploying persistent world memory in autoregressive video diffusion models, enabling scalable, efficient interactive simulation for embodied AI, gaming, and robotic training. The results challenge the necessity of memory-trained modules for consistency, demonstrating that architectural and inference-time memory management can suffice, provided effective retrieval and compression schemes are employed. Broader implications include the reduction of VRAM and computational overhead, making persistent simulation more tractable on commodity hardware.
On the theoretical front, WorldKV's selective retrieval and compression principles may inspire KV-cache management strategies in other domains, including language modeling and reinforcement learning, particularly in settings demanding long-horizon context and sparse relevance.
Limitations and Future Directions
WorldKV's fidelity is bounded by the quality of the underlying world model; artifacts accumulate in trajectories longer than those seen during training. Host-device transfer latency in CPU offloading remains an obstacle for multi-minute rollouts. Addressing these with hybrid memory schemes and further integrating WorldKV with memory-aware training protocols represents a salient avenue for future research.
Conclusion
WorldKV demonstrates that efficient world memory for autoregressive video models can be achieved without architectural modifications or further training. The combined retrieval and compression framework maintains real-time throughput and preserves long-term consistency, establishing a robust baseline for persistent interactive generation in AI-driven environments. The method's versatility and strong empirical results indicate considerable potential for widespread adoption and further theoretical exploration.

