- The paper introduces dual neural architectures that jointly predict action choice and duration, enabling dynamic frame-skip learning.
- Empirical results show RL agents converging to high frame-skip values, leading to exploitative and repetitive behavior.
- The study reveals that adaptive duration selection offers no clear advantage over fixed strategies, emphasizing the need for robust opponent evaluations.
Learning Action Duration in Fighting Games: An Expert Analysis
Introduction and Problem Definition
This work systematically examines reinforcement learning (RL) for action duration selection in the context of fighting games, evaluating agents' capacity not only to determine which action to execute but also how long to execute it. The study focuses on Street Fighter II - Special Champion Edition using the FightLadder environment, where rapid adaptation and temporal precision are critical. Standard RL frameworks typically employ fixed action intervals, e.g., every N frames, restricting temporal flexibility and realism. This research proposes, implements, and benchmarks a framework where the agent dynamically learns both the high-level action and the state-conditioned temporal extent (frame-skip) of each command.
Architectures for Joint Action and Duration Selection
The paper introduces two neural architectures enabling simultaneous prediction of action type and action duration: the separated policy head and the combined policy head. In the separated approach, the network emits distinct distributions for (a) motion/attack selection and (b) frame-skip (duration). Conversely, the combined architecture outputs a joint action space encoding both the primitive and its duration, scaling combinatorially with the number of allowed durations.
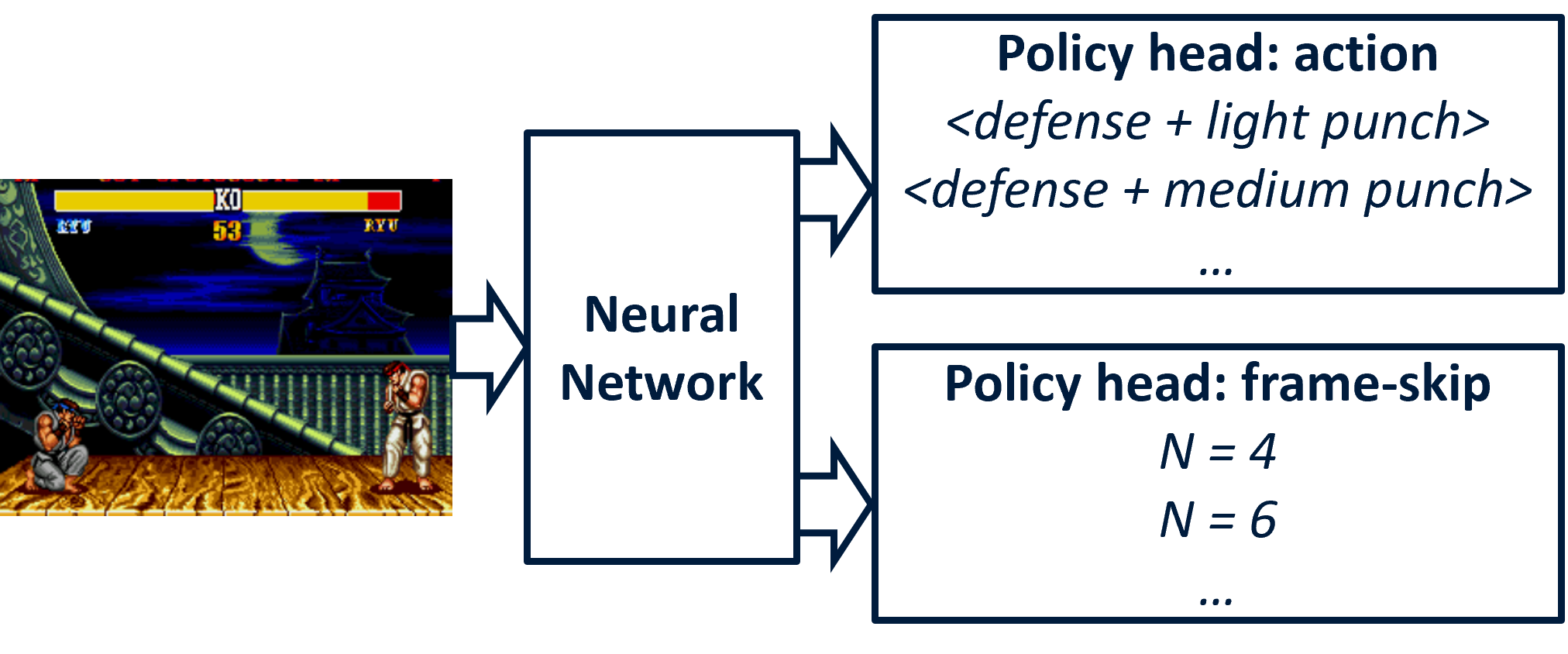
Figure 1: Policy architecture with separate heads: one policy for movement/attack combinations, another for frame-skip selection.
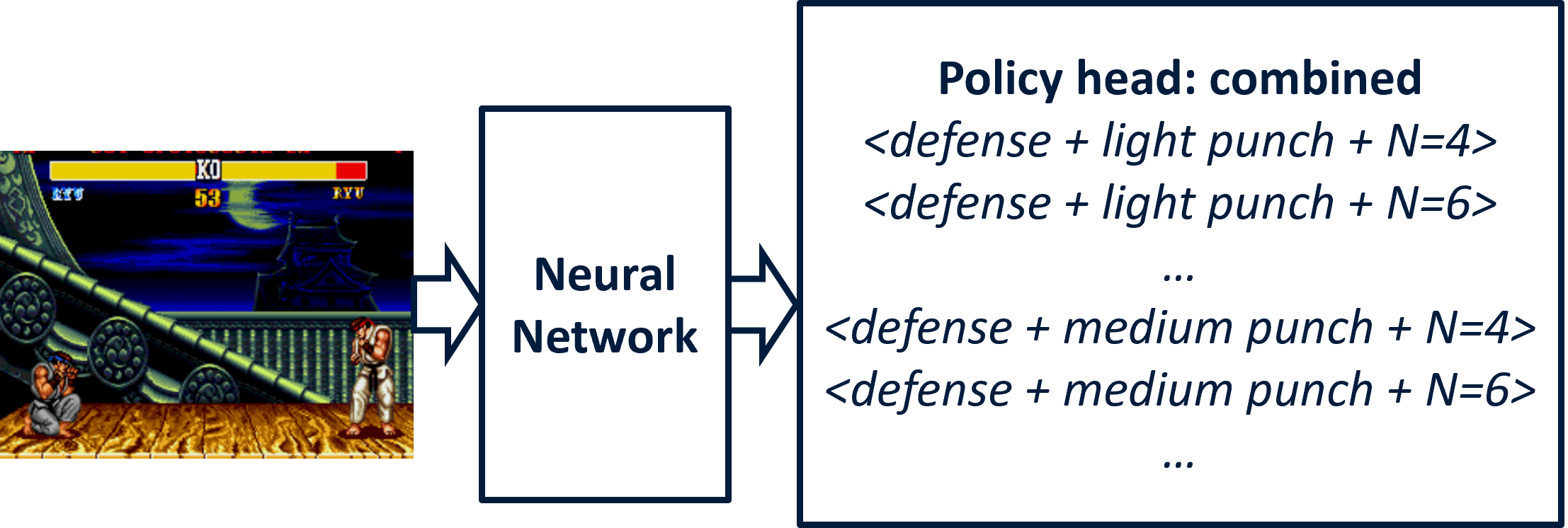
Figure 2: Policy architecture with a combined head: every action is a unique combination of movement, attack, and frame-skip.
The separated head approach offers tractable scaling with increasing duration sets and better performance in preliminary and main experiments.
Empirical Results and Behavioral Analysis
Across an extensive experimental campaign, the manuscript methodically evaluates agents trained using PPO over variable frame-skip strategies:
- Fixed frame-skip (4, 8, 16, 60, etc.)
- Uniformly random selection of skip at each decision point
- Policy-driven adaptive selection, under both separated and combined heads
Remarkably, RL agents, regardless of how they select durations, consistently converge to high frame-skip values—effectively lowering decision frequency (down to once per second for N=60). State-conditioned policies rarely exploit fine-grained responsiveness, even though the fighting game is fast-paced and could, in principle, reward precise timing. Training curves (Figure 3) validate stable learning with reward improvement, but learned behavior consistently exhibits low entropy over durations.
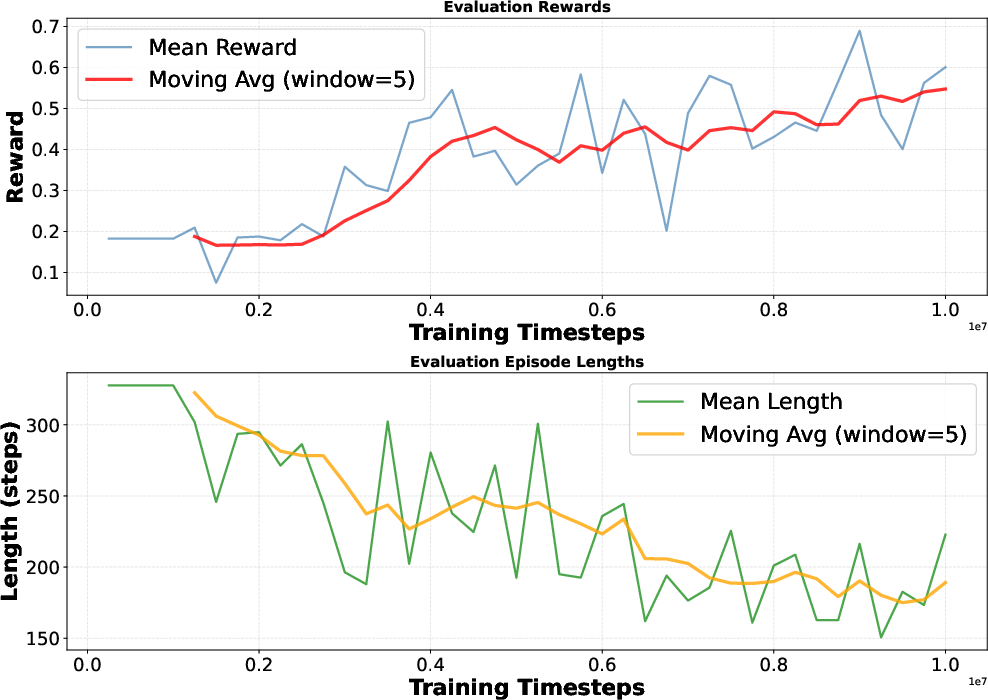
Figure 3: Average episodic reward and episode length for the separated policy agent, illustrating robust and monotonic learning progress.
Detailed temporal analyses (Figures 4-6) further reveal:
- Persistent preference for high frame-skip (Figure 4), irrespective of agent or game state.
- Minimal diversity in button selections and combos, with repetitive, exploitative behavior (Figures 5, 6).
- Lack of responsiveness to theoretically relevant state factors (e.g., hit points, distance to opponent).
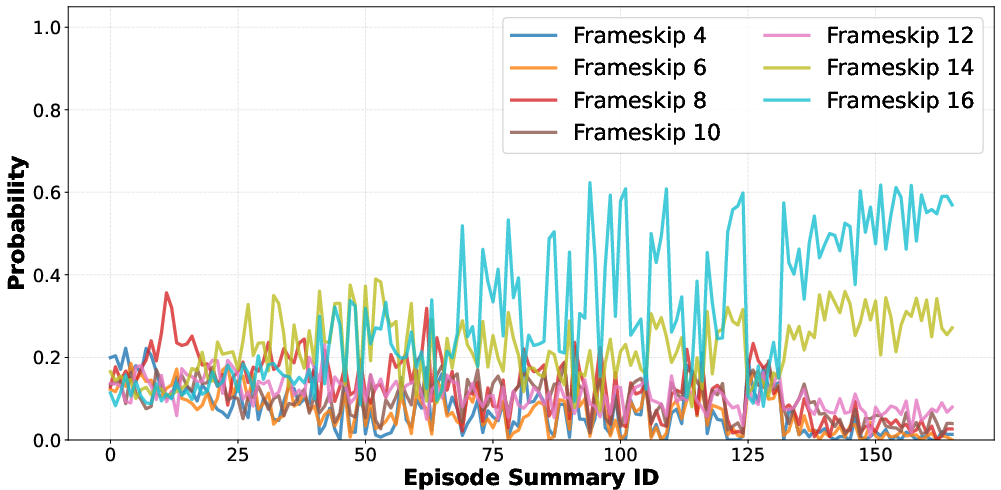
Figure 4: Frame-skip choices become highly biased toward longer durations as training progresses.
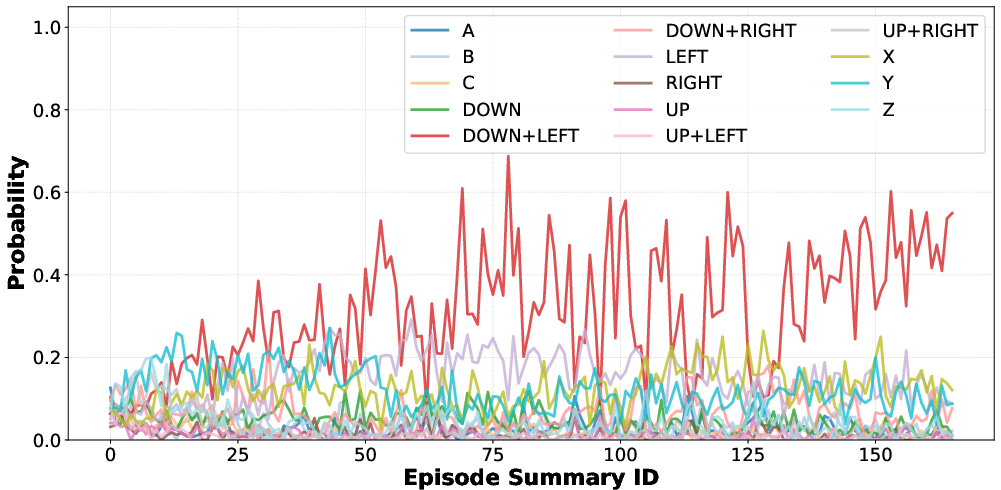
Figure 5: Distribution over button choices—repetition of a small subset dominates over time.
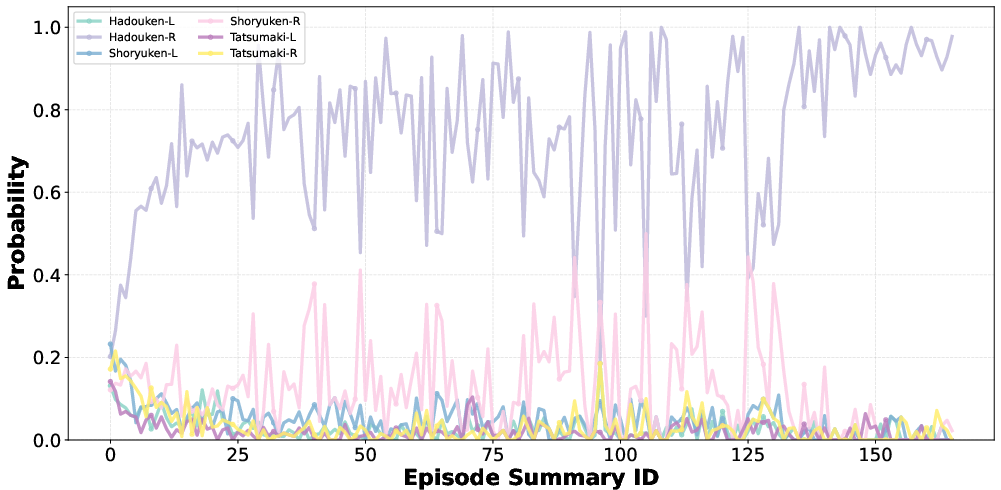
Figure 6: Combo selection entropy rapidly collapses, with agents exploiting a single combo for extended periods.
These findings are stable across multiple frame-skip configuration sets and architectural choices.
Generalization and Transfer
When tested on unseen opponent characters or after finetuning, performance deteriorates or becomes highly opponent-specific. Policies optimized against a single built-in AI (e.g., Ryu) exploit idiosyncratic weaknesses rather than learning robust tactical depth. Sequential finetuning (Figure 7) and additional transfer experiments confirm that agents simply transition to repetitive exploitation of different single combos per new opponent, as dictated by the opponent’s vulnerabilities.
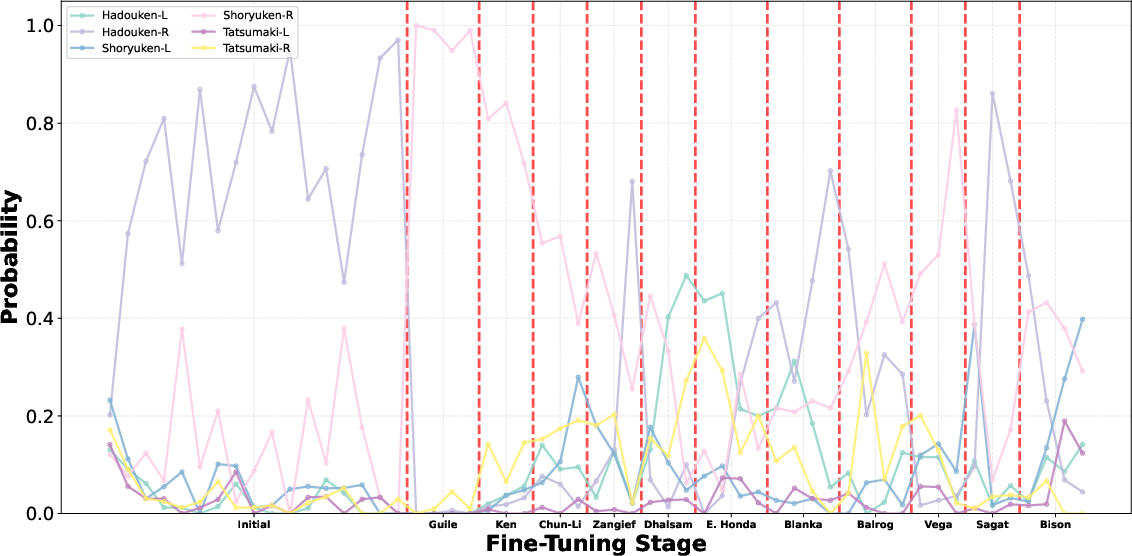
Figure 7: Evolution of combo move selection during sequential finetuning; dominance shifts as the training opponent changes.
No evidence emerges that adaptive duration selection (learning frame-skips as a function of state) meaningfully expands behavioral diversity or robustness relative to well-tuned fixed durations. Notably, fixed, high frame-skip strategies are competitive or superior across the vast majority of metrics, contradicting the intuition that high responsiveness (low frame skip) is essential in rapid, real-time environments.
Theoretical and Practical Implications
- Temporal abstraction via high frame-skip is both easy to learn and highly effective against exploitable, stationary scripted bots. Temporal abstraction simplifies credit assignment and exploration (as per macro-action and options theory), decreasing learning complexity but at the cost of behavioral sophistication.
- The tested game environment’s built-in AIs are highly susceptible to degenerate but high-reward repetitive strategies. Thus, evaluation against only such opponents risks overestimating agent depth and adaptability.
- The anticipated value of adaptive (state-dependent) action durations is not realized in this context. The policy learns near-constant durations, and only in the presence of a more complex, adaptive opponent (e.g., human or strong learned RL policy) might state-responsive durations prove essential.
- The results highlight an evaluation artifact: agents can achieve high episodic rewards with near-minimal computational cost (ultra-high frame-skip), undermining assumptions about the necessity of real-time reaction in RL-based fighting game policies.
- For robust RL benchmarks in complex environments, opponent diversity and explicit anti-exploit constraints are necessary.
Future Directions
Several lines of research are implied:
- Training and evaluating against adaptive, adversarial RL agents or human players to avoid convergence on brittle, high frame-skip exploitation.
- Incorporation of computational cost constraints (e.g., maximum number of decisions per unit time) or biologically plausible reaction-time architectures to enforce more realistic and diverse behaviors.
- State-conditional duration selection could become relevant in multi-agent settings, or where action timing has a critical, non-exploitable impact on outcome, provided the evaluation partner's robustness is ensured.
- Extending the framework to multi-agent RL with decentralized duration-selection policies could probe interactions and emergent timing strategies in non-exploitable settings.
Conclusion
This study demonstrates that, in the tested fighting game and evaluation setup, learned action duration selection confers no clear advantage over fixed, well-chosen frame-skip values. High frame-skip values readily enable exploitative, repetitive behaviors against scripted bots, and learning state-conditioned timing is not encouraged by the environment. These results problematize conclusions drawn from evaluations limited to fixed-AI opponents and suggest that methodological rigor in opponent selection and evaluation design is crucial for progress in RL for temporally extended, real-time games. The potential of adaptive timing for richer policies remains an open direction, deferred pending more robust evaluation setups and environments where temporal adaptation cannot be bypassed through environment-specific exploitation (2605.20911).