- The paper introduces a dual-rate strategy that splits high-capacity global feature extraction from lightweight local denoising to reduce inference FLOPs.
- It employs a heavy transformer-based context encoder evaluated intermittently and a light denoising network applied at every timestep, achieving near-baseline sample quality.
- Experimental results on ImageNet demonstrate significant compute savings and compatibility with distillation frameworks, maintaining competitive FID scores.
Dual-Rate Diffusion: Accelerating Diffusion Models with an Interleaved Heavy-Light Network
Introduction
"Dual-Rate Diffusion: Accelerating diffusion models with an interleaved heavy-light network" (2605.18190) addresses a primary bottleneck in diffusion-based generative modeling—the high computational burden incurred by the repeated invocation of a large denoising neural network at every timestep during inference. The authors propose a principled architectural modification: splitting the generative model into two components—a heavy, high-capacity context encoder, evaluated at sparse intervals to capture global structure, and a light, efficient denoising network, evaluated at each step for local refinement. The context encoder’s high-dimensional outputs are cached and reused by the denoising model, decoupling global and local processing.
This architecture is motivated by both empirical and theoretical observations of the diffusion process: the global structure of samples changes slowly, while local details are refined in later steps. By amortizing the cost of high-level feature extraction and focusing lightweight computation on local detail, Dual-Rate Diffusion reduces inference FLOPs by factors of 2–4, without degrading sample quality. The method’s compatibility with distillation frameworks (notably Moment Matching Distillation, MMD) further enhances efficiency for few-step models.
Architectural Design and Generative Process
Dual-Rate Diffusion employs a dual-network structure. The context encoder—a heavy neural architecture, typically a transformer variant (UVit)—processes noisy input data at a sparse subset of timesteps, yielding high-level features. The lightweight denoising model leverages these features at each step to refine the data, focusing its capacity on incrementally updating local details.
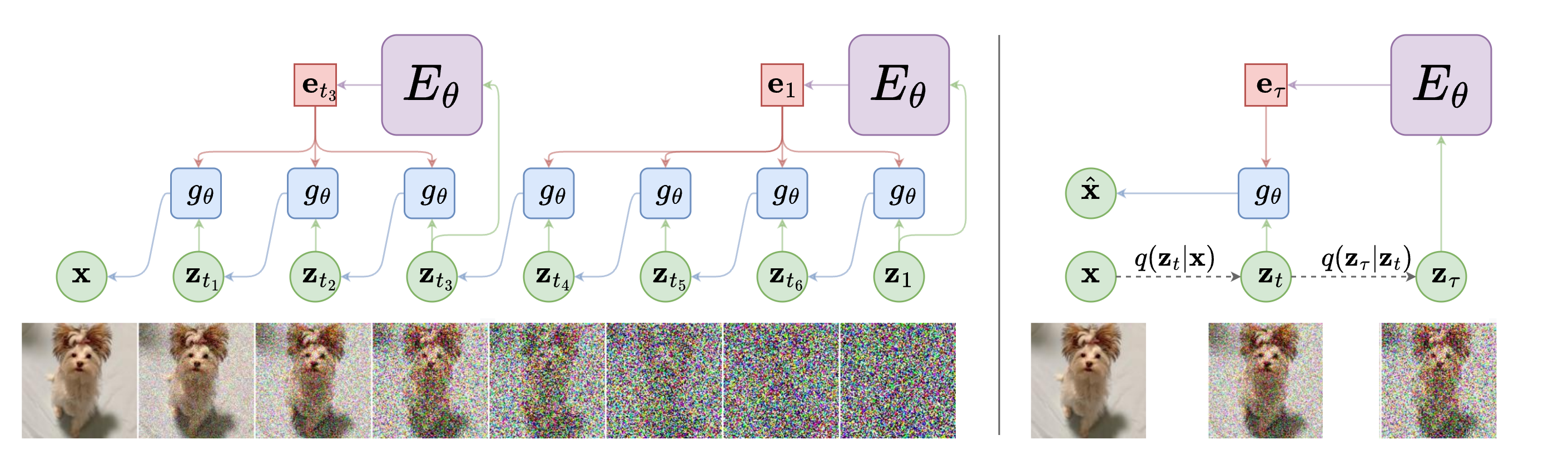
Figure 1: Overview of Dual-Rate Diffusion generative process and training, indicating sparse evaluation of the heavy context encoder and continuous refinement by the light denoising model.
Conditioning is implemented via hierarchical feature concatenation at corresponding spatial resolution levels across both networks, followed by linear projection to match channel dimensionality. This enables the light model to operate efficiently at each denoising iteration while remaining informed of the global context established previously.
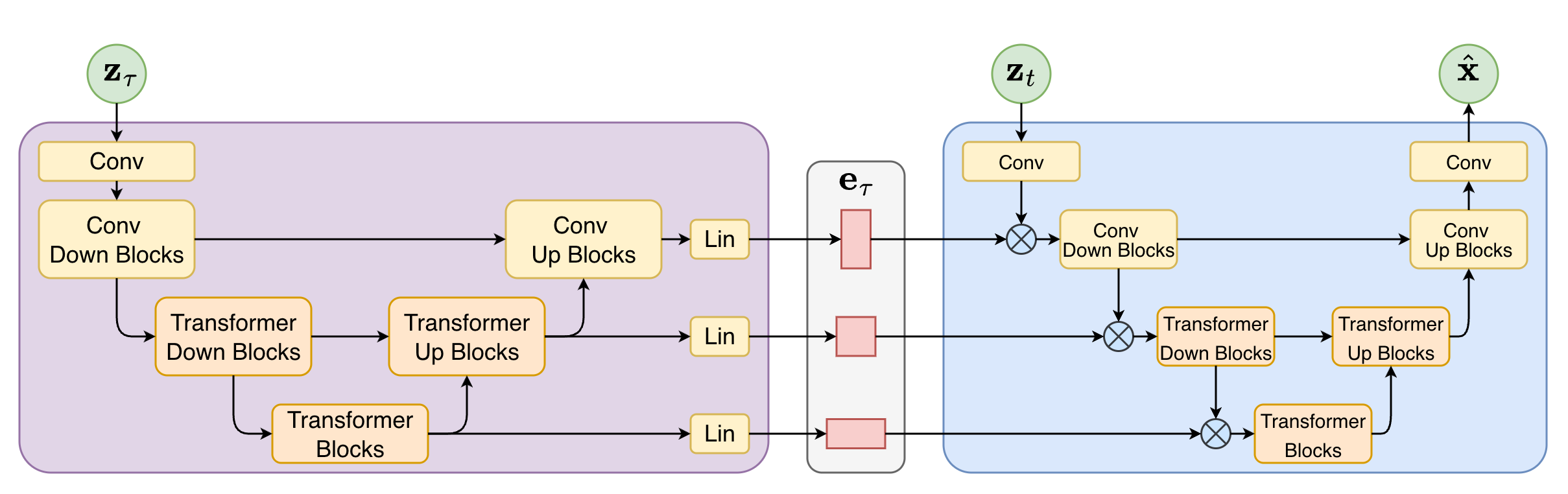
Figure 2: Dual-Rate Diffusion conditioning mechanism, showing hierarchical feature extraction and reuse across UVit levels.
Theoretical Fundamentals
Diffusion models rely on a Markovian forward process (data to noise) and a reverse denoising process (noise to data). Dual-Rate Diffusion introduces a dependency on two states: the current noisy sample and the most recent context-encoded state. Although this makes the process non-Markovian regarding sampled trajectories, the target distribution remains Markovian. High-fidelity sampling thus requires careful consideration in both training and inference to minimize distribution mismatch, especially when non-Markovian posteriors (e.g., DDIM) are involved.
The Dual-Rate loss retains the variational lower bound structure, extended to accommodate conditioning on both the current state and context features. Empirically, correct distribution matching necessitates use of Markovian processes for both training and sampling.
Experimental Results
The evaluation uses class-conditional ImageNet generation at 64×64 and 128×128 resolutions. The experiments cover both standard diffusion training and compatibility with MMD-based distillation. Efficiency is quantified in FLOPs and NFE; quality is assessed primarily by FID.
Dual-Rate Diffusion achieves near-baseline FID scores (1.12–1.52 at 64×64) while drastically reducing computational cost. Notably, with only $1/4$ the sampling budget of the baseline, Dual-Rate achieves superior FID, demonstrating effective amortization of global computation.
Ablation studies illustrate the trade-off between context encoder frequency and denoising feature dimensionality. Fewer context evaluations or narrower feature dimensions degrade quality; multi-level conditioning and feature dropout augment robustness.
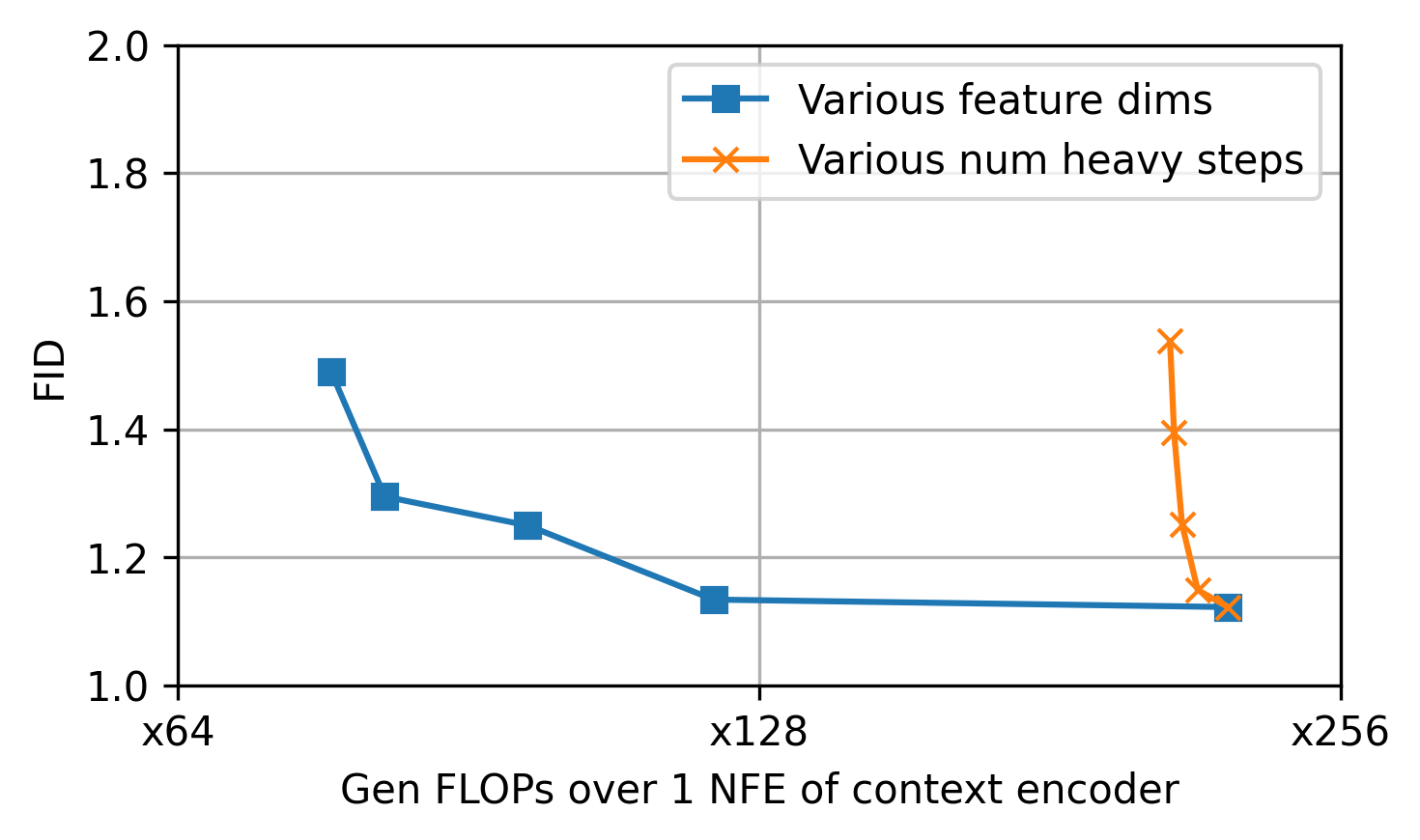
Figure 3: Ablation study of context encoder evaluations and feature dimensionality, showing performance-compute trade-offs.
Sample quality remains high across both architectures and distillation variants, as exhibited by the randomly generated ImageNet samples.


Figure 4: Random samples from Dual-Rate Diffusion on ImageNet 64×64 with K=16 and k=512.


Figure 5: Random samples from Dual-Rate MMD on ImageNet 64×64 with K=4 and k=8.
At higher resolution (128×1280), the method maintains competitive quality with substantial compute savings.


Figure 6: Random samples from Dual-Rate Diffusion on ImageNet 128×1281 with 128×1282 and 128×1283.


Figure 7: Random samples from Dual-Rate MMD on ImageNet 128×1284 with 128×1285 and 128×1286.
Distillation Compatibility
The dual-rate architecture is directly extendable to distillation frameworks, most notably MMD. The student model incorporates both a context encoder and denoising network, with training dynamics coordinated to avoid distribution mismatch. Rollouts of the student’s denoising process are necessary to maintain in-distribution inputs during training.
Empirical results show that Dual-Rate MMD outperforms standard MMD distillation in compute-quality trade-offs, achieving FIDs of 1.17–1.90 with only 8 denoising steps at 128×1287 and 128×1288, respectively. The full rollout strategy, in which context states are generated by the student, further improves stability and alignment.
Recent diffusion acceleration research predominantly tackles step count reduction (advanced ODE solvers, distillation, direct mapping), but still relies on heavy computation per step. In contrast, Dual-Rate Diffusion reduces cost per function evaluation by decomposing global and local processing. The method is structurally distinct from caching strategies (layer- or token-wise reuse), enabling independent scaling of context and denoising models. Its architectural simplicity facilitates integration with complementary acceleration techniques, e.g., token caching or adaptive execution.
Limitations and Future Directions
The principal limitation is increased training cost per iteration, since both networks must be updated jointly. Alternative or staggered training regimes may mitigate this burden. The dual-observation dependency also constrains training to stochastic Markovian processes for unbiased optimization. Future research could explore adaptive schedules for context encoder invocation, hybrid architectures, and deployment to other modalities (e.g., video, audio) where global structure evolves slowly.
Conclusion
Dual-Rate Diffusion provides an efficient and flexible framework for accelerating diffusion models by interleaving sparse high-capacity global feature extraction with frequent lightweight denoising. The approach obtains competitive or superior sample quality with a fraction of the inference compute of standard models and maintains compatibility with prevalent few-step distillation methods. The architectural decoupling of global and local processing represents a robust path toward scalable generative modeling in high-dimensional domains.

