Interactive Evaluation Requires a Design Science
Abstract: AI evaluation is undergoing a structural change. LLMs are increasingly deployed as systems that act over time through tools, environments, users, and other agents, while many evaluation practices still inherit assumptions from response-centered benchmarks (e.g., fixed inputs, isolated outputs, and outcome judgments that can be made from a single response). The field has begun to build interactive benchmarks, but the resulting landscape is fragmented: benchmarks differ in what interaction artifacts they admit, how trajectories are scored, and what claims their results support. This position paper argues that interactive evaluation should be treated as a principled evaluation paradigm, not merely a new family of agent benchmarks. Simply adopting previous evaluation paradigms does not suffice. We define evaluation as an autonomous mapping from evidence to judgments, and show that interactive evaluation changes both sides of this mapping: the evidence becomes interaction-generated trajectories, while the evaluation procedure must assess process, recoverability, coordination, robustness, and system-level performance. Building on this definition, we propose a two-axis taxonomy, derive design principles and reporting standards, examine representative scenarios, and analyze how longstanding evaluation challenges reappear at the trajectory level.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper argues that we need a better way to “grade” AI systems that act over time—like chatbots that browse the web, use tools, work with people, or coordinate with other AIs. In the past, we usually judged AI by checking a single final answer to a fixed question. But modern AI often solves problems through a series of steps and choices that change what happens next. The authors say evaluation should match that reality: we should judge the whole interaction (the path taken), not just the final output.
Key objectives and questions
The paper tackles three simple questions:
- What evidence should count when we evaluate interactive AIs? (Just the final answer, or the whole “story” of actions, tools used, mistakes and fixes?)
- How should we turn that evidence into a fair score or judgment?
- What principles should guide the design of these new evaluations so results are clear, comparable, and useful?
Approach: How the authors think about evaluation
The authors treat evaluation like a “grader” program that takes in evidence and returns a judgment. In math terms, that’s :
- is the evidence we allow (for interactive AIs, this is the full trajectory: observations, actions, tool calls, feedback, states, costs, and outcomes).
- is the result (scores, pass/fail, reports, rankings).
They propose a two-axis way to design and compare interactive evaluations:
- What evidence goes in (the interaction artifact):
- Tools and environments (e.g., web browsers, operating systems, apps, games)
- Users (real or simulated people who ask, clarify, and change their minds)
- Other agents (cooperation, negotiation, competition)
- Hybrid/dynamic systems (mixtures of the above with memory and changing conditions over time)
- How the evidence is judged (the evaluation program):
- Task success (did it finish the job?)
- Process quality and efficiency (did it choose good tools, avoid waste, and communicate clearly?)
- Recoverability and robustness (did it spot mistakes, adapt to change, and fix issues?)
- Safety, alignment, and social competence (did it behave responsibly and cooperate honestly?)
A helpful analogy: grading a science project. Old style = only grade the final poster. New style = also watch the experiments, see how problems were solved, whether the lab was safe, and whether the team worked well together.
Main findings and why they matter
This is a position paper (a structured argument), so the “findings” are observations about today’s evaluation landscape:
- Many “interactive” benchmarks record full trajectories but still score only the final result. That wastes valuable information about the process, recovery from errors, and risk.
- Evaluations often get stuck to a specific setup (like “web tasks = success rate only”), instead of using richer measures that match the claims they want to make (e.g., robustness, safety).
- Hybrid/dynamic settings (where tools, users, memory, and changing environments all mix) are under-tested, even though that’s close to how AIs will work in the real world.
- Practical issues slow progress: interactive evaluations are costly, often underuse human validation for human-sensitive claims, and can be hard to reproduce because small protocol changes (like tool access or retry limits) can change outcomes.
These points matter because judging only the final answer can be misleading. Two AIs can “succeed,” but one might be risky, brittle, or wasteful along the way. If we don’t measure the journey, we can’t tell the difference.
Implications: What the field should do next
The authors outline simple, actionable principles for building better interactive evaluations:
- Clearly describe the system and the evidence: what tools, memory, simulators, and logs are used—and which claims (success, process, recovery, safety) the evidence supports.
- Publish the interaction protocol: starting states, allowed actions, stopping rules, randomness, and reset conditions—so results are reproducible and fair.
- Test perturbation and repair: include ambiguity, misleading feedback, partial failures, and changing conditions to see if systems can detect problems and recover.
- Report outcome, process, and risk separately: don’t hide everything in a single score. Show success rate, cost/efficiency, robustness, and safety side by side.
- Build shared infrastructure without locking in one format: create common logging, viewers, and reporting standards, but keep room for diverse tasks and environments.
They also warn about risks unique to interaction: systems might “game” a simulator’s quirks, become overfit to one judge or user simulator, or look good in a high-control test but fail in realistic conditions. Evaluations should use varied environments and judges, refresh tasks, and check robustness across seeds and settings.
Big picture: If we design interactive evaluation well, we’ll get AI systems that are not just good at producing answers, but are also safe, efficient, reliable over time, and able to work with people and other AIs. That’s the kind of evidence developers, researchers, and the public actually need to trust AI in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues the paper surfaces or implies, framed as specific, actionable gaps for future research:
- Operational criteria for when interaction is “consequential”: clear tests to decide when a tool call or multi-turn exchange changes evidence/state enough to require interactive evaluation.
- Formal, substrate-agnostic definitions of process quality (e.g., action economy, exploration quality, code-edit locality, communication clarity) that can be measured consistently across domains.
- Standardized recoverability metrics: protocols and fault taxonomies for injecting errors, measuring detection/repair, and scoring recovery without conflating with final success.
- Robustness measurement frameworks that go beyond task success, including standardized perturbation libraries (e.g., misleading guidance, partial state drift, delayed feedback) with severity scales.
- Safety and social-competence rubrics tailored to trajectory settings, with validated criteria for manipulation, deception, undue influence, and uncertainty communication across cultures.
- Aggregation methodologies for multi-dimensional scoring (outcome, process, risk): principled weighting, sensitivity analyses, and reporting templates to avoid hiding trade-offs in a single scalar.
- Reliability and uncertainty reporting for interactive scores: power analyses, variance attribution (seeds, environment instances, user models), confidence intervals, and minimum episode counts.
- Cross-evaluator stability testing: protocols to check if conclusions hold across human judges, LLM-as-judge variants, and rubric versions; methods for judge calibration and bias auditing.
- Human-in-the-loop sampling strategies: when and how to sample trajectories for human review, required expertise levels, inter-annotator agreement targets, and cost-effective validation designs.
- Evidence-to-judgment traceability: schemas and tooling to link final scores back to trajectory segments and evaluator decisions for auditability and error analysis.
- Standardized logging schemas and replayable trajectory formats (events, timestamps, state diffs, tool I/O), enabling reproducible scoring and counterfactual re-evaluation under alternative programs.
- Protocol documentation standards (a “datasheet for interaction”): initial state distributions, action/observation spaces, reset/stop rules, randomness control, tool access, environment versions, and budgets.
- Versioning and governance for environments/tools: DOI-like identifiers, change logs, deprecation policies, and compatibility notes to prevent silent protocol drift.
- Cost-efficient evaluation designs: statistical subsampling, episode truncation, stratified sampling, and surrogate metrics that preserve discriminative power while lowering compute/human cost.
- Methods to detect and deter trajectory-level gaming and leakage: policy-gaming audits, held-out/private tasks, procedural generation, evaluator randomization, and anomaly detection in action traces.
- External validity studies linking interactive scores to real deployment KPIs (e.g., user satisfaction, incident rates, productivity), including prospective and retrospective validation.
- Construct validity frameworks for interactive capabilities: mapping trajectory measures to theoretical constructs, and using psychometric tools (e.g., IRT) to assess item/task quality.
- Normalization of process/efficiency metrics across substrates: unit costs (clicks, API calls, edits) and domain-specific cost-to-impact mappings to make cross-benchmark comparisons meaningful.
- Long-horizon, persistent-state evaluations: benchmarks and metrics for cross-session memory, state accumulation, drift, and long-term risk management.
- Multi-agent evaluation protocols: standardized opponent/collaborator pools, Elo/TrueSkill-like rating systems, equilibrium/stability criteria, and causal credit assignment for coordination quality.
- User-simulator fidelity and diversity: empirical grounding, calibration to real user behavior, coverage of ambiguity/implicit intent, and guidelines for when real-user studies are required.
- Ethical, privacy, and safety safeguards for trajectory logs: PII redaction, safe sandboxes for executing agent actions/code, access controls, and data licensing for replayable traces.
- Stochasticity management: seeds, environment randomness, counterpart variability; stratified reporting and robustness checks that separate capability from protocol noise.
- Composite evaluation design patterns for hybrid systems (tools + users + agents + memory): reference architectures, minimal viable protocols, and failure-mode libraries.
- Judge model reliability in trajectory settings: prompt designs, debiasing (e.g., length control), calibration targets, and benchmarks for LLM-as-judge on process and safety dimensions.
- Re-scoring and counterfactual evaluation: mechanisms to replay trajectories under alternative evaluators, rubrics, or safety rules to test claim robustness without rerunning environments.
- Criteria to decide when interactive evaluation is necessary vs response-centered alternatives; cost–benefit thresholds and decision checklists.
- Standardized perturbation/repair curricula: staged difficulty, measurable progression, and curriculum transfer tests across domains.
- Fairness audits in interactive settings: methods to detect disparate performance or harmful strategies across demographic/user profiles and cross-cultural norms.
- Compute/carbon accounting and budget reporting for interactive evaluations to enable fair comparison and reproducibility across labs with different resources.
- Governance for community standards: processes for proposing/updating protocols, preventing premature convergence, and balancing realism with control.
- Extension to non-digital/embodied settings: bridging simulator–real gaps, safety constraints for physical interaction, and transferability of trajectory metrics across modalities.
Practical Applications
Immediate Applications
Below are concrete, near-term ways to apply the paper’s design-science framework for interactive evaluation. Each item notes sectors, potential tools/workflows, and key dependencies.
- Interactive CI/CD gates for coding agents
- Sectors: Software, DevOps
- What: Add trajectory-level checks (process quality, edit locality, test-first behavior, recoverability after a failing test) to continuous integration pipelines for code assistants and repo agents.
- Tools/products/workflows: Sandbox harnesses (e.g., OSWorld-like), trajectory logging/replay viewers, process metrics dashboards, PR gate that separates outcome vs. process vs. risk scores.
- Assumptions/dependencies: Deterministic sandboxes; reproducible environment versions; privacy controls for code; budget for repeated runs; protocol documentation.
- Web automation and customer support agent evaluation suites
- Sectors: Software, E-commerce, Customer Support
- What: Deploy web/app navigation evaluations that score not only task completion but also clarification quality, action economy, and recovery from misclicks or ambiguous instructions.
- Tools/products/workflows: WebArena- or AppWorld-style harness, user-intent perturbation modules, “clarify-then-act” scoring, LLM-judge + human spot-checks.
- Assumptions/dependencies: Stable site/app mirrors; user simulator validation; anti-leakage policies; seed/variance reporting.
- Red-teaming pipelines for interactive systems
- Sectors: Safety, Security, Trust & Safety
- What: Evaluate robustness to misleading guidance, state drift, unexpected tool outputs, and manipulative strategies in multi-turn settings.
- Tools/products/workflows: Perturbation-and-repair test suites, adversarial user/agent simulators, risk logging (unsafe actions, irreversible changes), incident replays.
- Assumptions/dependencies: Clear harm/constraint rubrics; human-in-the-loop escalation; audit trails.
- Procurement scorecards for enterprise agents
- Sectors: Industry, Government, Finance, Healthcare
- What: Require vendors to report protocol details, trajectory evidence, and disaggregated scores (task success, process, risk) when selling AI agents.
- Tools/products/workflows: Standardized protocol templates, trajectory schemas, evaluator diversity reports, pass/fail thresholds per dimension.
- Assumptions/dependencies: Organizational buy-in; evaluator independence; confidentiality-safe logging.
- Academic benchmark redesign using the 2D taxonomy
- Sectors: Academia
- What: Reframe benchmarks around “evaluation inputs” (tools/users/agents/hybrid) and “evaluation programs” (success/process/recoverability/safety), improving interpretability and comparability.
- Tools/products/workflows: Benchmark descriptors that specify admissible evidence X and evaluator E, open logging schemas, reproducible harnesses.
- Assumptions/dependencies: Community consensus on reporting standards; maintenance funding.
- Human-in-the-loop judging where claims require social competence
- Sectors: Healthcare, Education, Social Platforms
- What: Add targeted human review to trajectory segments that require norm-sensitive judgments (e.g., consent, uncertainty disclosure, pedagogy).
- Tools/products/workflows: Segment triaging (auto-flag likely sensitive turns), calibrated sampling plans, rater training, adjudication protocols.
- Assumptions/dependencies: Rater availability/expertise; cost controls; inter-rater reliability checks.
- MLOps for trajectory data
- Sectors: Software, Platforms
- What: Treat trajectories as first-class artifacts: collect, version, replay, and diff them; monitor seed variance and drift across deployments.
- Tools/products/workflows: Trajectory stores, viewers, comparators, batch replays under protocol changes, variance reports.
- Assumptions/dependencies: Storage/compliance frameworks; PII redaction; stable replay semantics.
- Evaluation of healthcare decision-support workflows
- Sectors: Healthcare
- What: Score how systems clarify ambiguous inputs, follow safety constraints, explain reasoning, and recover from initial misinterpretations—not just final recommendation accuracy.
- Tools/products/workflows: Clinician-in-the-loop adjudication, protocol disclosures (knowledge sources, tool access), safety and uncertainty metrics.
- Assumptions/dependencies: IRB/PHI safeguards; clinical expert time; domain-specific rubrics.
- Finance operations assistant testing
- Sectors: Finance, Operations
- What: Run perturbation-resilient tests for reconciliation, report generation, and tool-mediated workflows; track compliance and rollback capability.
- Tools/products/workflows: Synthetic-but-faithful ledgers, reversible sandboxes, compliance checklists embedded in E, recovery drills.
- Assumptions/dependencies: Regulatory alignment; data anonymization; clear stop/reset rules.
- Tutoring agent evaluation beyond final correctness
- Sectors: Education
- What: Evaluate tutors on misconception detection, scaffolding quality, and robustness to noisy student inputs.
- Tools/products/workflows: Student-behavior simulators, rubric-based process scoring, longitudinal memory checks.
- Assumptions/dependencies: Age-appropriate safety rubrics; educator validation; fair-use content constraints.
- Robotics validation with process and recoverability metrics
- Sectors: Robotics, Manufacturing, Logistics
- What: Use realistic simulators to score action efficiency, safe tool/device use, and recovery from minor failures, not only task completion.
- Tools/products/workflows: Simulator-in-the-loop evaluators, fault-injection scenarios, safety penalty logs.
- Assumptions/dependencies: Sim-to-real gap disclosure; repeatable seeds; safety envelopes.
- Personal assistant quality checks in daily life tasks
- Sectors: Consumer Apps
- What: Evaluate long-term memory coherence, preference alignment, and safe calendar/email edits with rollback.
- Tools/products/workflows: Memory perturbation tests, undo/redo audit logs, user-confirmation checkpoints.
- Assumptions/dependencies: User consent; privacy-preserving telemetry; cloud/app API stability.
Long-Term Applications
These opportunities require further research, scaling, standardization, or ecosystem maturation.
- Industry-wide protocol and trajectory standards (e.g., “OpenTrajectory”)
- Sectors: Software, Standards Bodies
- What: Define shared schemas for trajectory evidence, protocol descriptors, and evaluator outputs to enable cross-benchmark comparability and auditing.
- Tools/products/workflows: Open specs, conformance suites, reference validators.
- Assumptions/dependencies: Multi-stakeholder governance; backward compatibility; IP/privacy constraints.
- Certification for interactive AI systems
- Sectors: Policy/Regulation, Healthcare, Finance, Critical Infrastructure
- What: Regulatory programs that require trajectory-based evidence of recoverability, safety, and social competence before deployment in high-risk domains.
- Tools/products/workflows: Accredited third-party evaluators, standardized perturbation batteries, cross-judge stability checks.
- Assumptions/dependencies: Legal frameworks; liability definitions; funding for oversight.
- Insurance underwriting based on robustness/recoverability scores
- Sectors: Insurance, Enterprise Risk
- What: Use evaluated risk and repair capability to price policies for agentic AI in operations (e.g., back-office automation, IT runbooks).
- Tools/products/workflows: Risk scoring models fed by E outputs, mandated periodic re-evaluations, incident-linked premium adjustments.
- Assumptions/dependencies: Loss data availability; anti-gaming measures; actuarial acceptance.
- Dynamic, procedurally generated evaluation marketplaces
- Sectors: Software, Research Platforms
- What: Benchmarks that refresh tasks, environments, and user/agent counterparts to reduce overfitting and policy-gaming.
- Tools/products/workflows: Task generators with coverage guarantees, anti-leakage governance, authenticated evaluator pools.
- Assumptions/dependencies: Content safety; reproducible seeding; compute budgets.
- Evaluation-first RL and agent tuning
- Sectors: AI/ML Platforms
- What: Use process/recovery metrics as training signals to produce agents optimized for safe, efficient, and repairable behavior.
- Tools/products/workflows: Reward models aligned with E’s dimensions, off-policy learning from logged trajectories, counterfactual replay.
- Assumptions/dependencies: Stable evaluators; credit assignment reliability; avoidance of reward hacking.
- Hybrid, persistent-state enterprise copilot testing
- Sectors: Enterprise Software, Productivity
- What: End-to-end evaluations across tools, users, and memory over weeks/months, measuring accumulation of errors, drift, and long-horizon reliability.
- Tools/products/workflows: Cross-session state trackers, memory integrity checks, longitudinal perturbations.
- Assumptions/dependencies: Data retention/privacy; versioned app ecosystems; long-run cost.
- Cross-evaluator and counterpart robustness audits
- Sectors: Academia, Standards Bodies
- What: Require that claims generalize across multiple judges/simulators and counterpart policies to reduce evaluator dependence.
- Tools/products/workflows: Evaluator ensembles, counterfactual substitution tests, sensitivity analyses.
- Assumptions/dependencies: Availability of diverse evaluators; meta-analysis methods.
- Safety-critical approval pathways for interactive autonomy
- Sectors: Transportation, Robotics, Medical Devices
- What: Build formal approval regimes where trajectory evidence demonstrates adherence to safety envelopes and failure recovery under disturbances.
- Tools/products/workflows: High-fidelity digital twins, fault catalogs, standardized safety/risk scoring.
- Assumptions/dependencies: Accepted hazard models; traceability; real-world validation.
- Education accreditation for AI tutors
- Sectors: Education Policy
- What: Certify tutoring systems on fairness, capability to correct misconceptions, and appropriate escalation to human instructors.
- Tools/products/workflows: Student-population simulators with demographic coverage, process rubrics, long-term learning outcome linkage.
- Assumptions/dependencies: Ethical oversight; bias auditing; longitudinal studies.
- Continuous post-deployment monitoring with trajectory-level canaries
- Sectors: All deploying sectors
- What: Runtime probes and drift detectors that evaluate recoverability and safety behaviors in the wild, with replayable evidence for audits.
- Tools/products/workflows: Canary tasks, streaming trajectory sampling, alerting and rollback workflows.
- Assumptions/dependencies: Observability; privacy-preserving logging; organizational incident response.
- Open repositories of interaction risks and countermeasures
- Sectors: Research, Safety, Policy
- What: Shared catalogs of trajectory-level failure modes (gaming, simulator artifacts) and standardized mitigation tests.
- Tools/products/workflows: Public registries, reference perturbation suites, benchmark “health” dashboards.
- Assumptions/dependencies: Community contribution incentives; curation governance.
- Consumer-grade “agent safety labels”
- Sectors: Consumer Apps, Policy
- What: Simple, interpretable labels summarizing task success, process, and risk profiles for personal assistants and automation tools.
- Tools/products/workflows: Aggregation from standardized E outputs, third-party verification, periodic re-scoring.
- Assumptions/dependencies: Standardization; anti-fraud mechanisms; consumer education.
These applications operationalize the paper’s core ideas: treat evaluation as a mapping from trajectory evidence to judgments; explicitly specify protocols; design for perturbation and repair; and report outcome, process, and risk separately. Feasibility depends on shared infrastructure (logging/replay schemas, protocol templates), validated evaluators (including human-in-the-loop), reproducible environments, privacy/security controls, and stakeholder alignment across industry, academia, and regulators.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- action-dependent conditions: Evaluation conditions where subsequent evidence or state depends on earlier actions, affecting what and how to judge. "trajectory-based, system-level evaluation under action-dependent conditions"
- action-dependent state: State that changes based on the agent’s actions, altering future observations and opportunities. "These inputs expose action-dependent state: clicks, API calls, file edits, or app operations change what the agent can observe later."
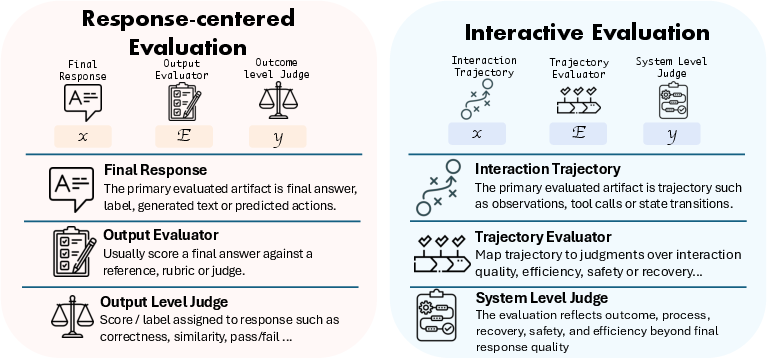
- admissible evidence: The set of artifacts that an evaluation accepts as valid input for judgment. "Interactive evaluation is evaluation in which the admissible evidence includes trajectories generated by consequential interaction, and the evaluation program maps those trajectories to judgments about system-level performance."
- adversarial perturbations: Deliberate changes to evaluation conditions to test system robustness or detect gaming. "Mitigations should therefore operate at the trajectory level: held-out environments, procedurally generated tasks, private or refreshed evaluation suites, adversarial perturbations, and audits of suspiciously efficient or unnatural trajectories."
- agent benchmarks: Benchmarks focused on autonomous agents, often emphasizing task completion or behaviors in interactive settings. "Interactive evaluation should be treated as a principled evaluation paradigm, not merely a new family of agent benchmarks."
- chain-of-thought: An explicit reasoning trace produced by a model during problem solving. "Third, chain-of-thought or self-reflection is not enough by itself: internal reasoning may be valuable evidence when exposed under a protocol, but interaction requires an external loop whose continuation is partly action-dependent."
- closed loop: An interaction setting where outputs feed back into inputs, making future states depend on previous actions. "We first explain why response-centered evaluation was historically useful and why its assumptions become insufficient when systems act in closed loop."
- construct-validity risk: The risk that an evaluation measures adaptation to particular evaluators or simulators rather than the intended capability. "This creates a construct-validity risk: systems may perform well under one judge, simulator, or expert group but fail under plausible alternatives."
- counterpart adaptation: Changes in behavior by another agent or user in response to the evaluated system’s actions. "including ambiguity, misleading feedback, partial failure, state drift, and counterpart adaptation."
- design science: A research paradigm focused on building and evaluating artifacts and principles for disciplined design. "Interactive evaluation should be built as a design science for evaluating systems acting through trajectories."
- evaluation harnesses: Reusable software frameworks that standardize running, logging, and scoring evaluations. "The field needs reusable environments, logging schemas, trajectory viewers, evaluation harnesses, and reporting templates."
- evaluation program: The procedure that maps accepted evidence to judgments or scores. "the evaluation program maps those trajectories to judgments about system-level performance."
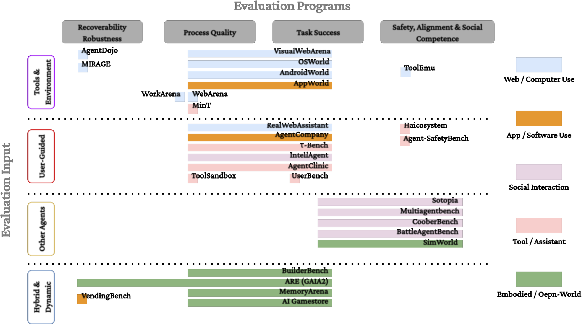
- evaluation substrates: The environments or mediums (e.g., tools, web, multi-agent) in which interaction occurs during evaluation. "Many interactive evaluations remain organized around evaluation substrates rather than evaluation programs."
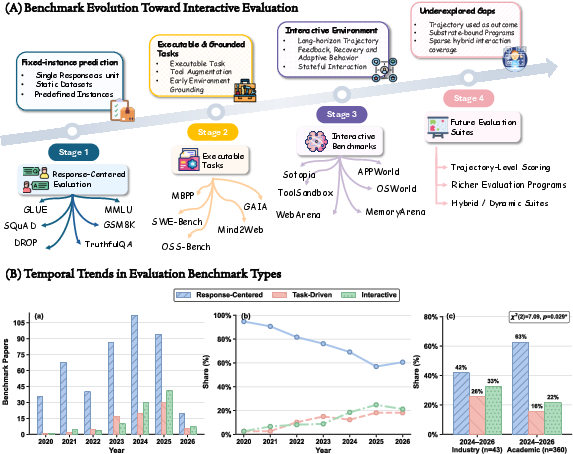
- grounded environments: Environments that connect actions to meaningful, realistic state changes and consequences. "Benchmarks have evolved from fixed-instance response evaluation to executable, grounded, and interactive settings,"
- held-out environments: Unseen evaluation environments used to reduce leakage and gaming. "held-out environments, procedurally generated tasks, private or refreshed evaluation suites, adversarial perturbations, and audits of suspiciously efficient or unnatural trajectories."
- Hybrid and Dynamic Systems: Settings that combine tools, users, agents, memory, and changing environments with persistent state. "Hybrid and Dynamic Systems Lack Robust Coverage."
- initial state distribution: The distribution over starting states for task episodes in interactive evaluation. "including the initial state distribution, allowed actions, observation space, counterpart behavior, stopping rules, randomness, persistence, and reset conditions."
- interaction protocol: The detailed rules and setup that govern how trajectories are generated and evaluated. "Specify the Interaction Protocol."
- interactive evaluation: An evaluation paradigm that judges trajectories generated through consequential interaction, not just final answers. "Interactive evaluation should be treated as a principled evaluation paradigm, not merely a new family of agent benchmarks."
- LLM-as-a-judge: Using a LLM as an automated evaluator of outputs or trajectories. "Many interactive evaluations rely on final success scores, automated checks, or LLM-as-a-judge pipelines,"
- logging schemas: Standardized data formats for recording trajectory artifacts and metadata. "The field needs reusable environments, logging schemas, trajectory viewers, evaluation harnesses, and reporting templates."
- observation space: The set of observations available to the system at each step in an environment. "including the initial state distribution, allowed actions, observation space, counterpart behavior, stopping rules, randomness, persistence, and reset conditions."
- policy-gamed: A failure mode where agents exploit benchmark regularities without demonstrating intended competence. "In response-centered evaluation, leakage often concerns exposure to test inputs or reference answers. In interactive evaluation, leakage can occur through environment state, public task templates, tool APIs, simulator regularities, predictable user models, or evaluator heuristics. The resulting failure mode is not only that a model knows the answer, but that a system learns how to behave strategically inside the benchmark. Agents may exploit simulator quirks, avoid meaningful exploration, optimize for superficial trajectory signals, or discover shortcuts that satisfy the scorer without demonstrating the intended competence."
- procedurally generated tasks: Tasks created algorithmically to diversify conditions and reduce overfitting. "held-out environments, procedurally generated tasks, private or refreshed evaluation suites, adversarial perturbations, and audits of suspiciously efficient or unnatural trajectories."
- protocol artifacts: Score differences caused by protocol choices rather than true capability differences. "Reporting should include variance across seeds, environments, users, perturbations, and state initializations, and should identify whether failures reflect missing capability, brittle policies, or genuine sensitivity to deployment-relevant variation."
- recoverability: The capability to detect mistakes and repair or adapt mid-trajectory. "A benchmark that records a trajectory but scores only final success supports a different claim from one that measures recoverability, risk, coordination, or adaptation."
- replay infrastructure: Tools that support trajectory storage, visualization, and deterministic re-execution for auditability. "The field needs reusable environments, logging schemas, trajectory viewers, evaluation harnesses, and reporting templates."
- reset conditions: Rules determining when and how an environment or task is reset during evaluation. "including tool access, observation space, retry budget, reset condition, or environment version."
- response-centered evaluation: Evaluation focused on fixed inputs and standalone final outputs rather than interaction processes. "Response-centered evaluation judges final responses; interactive evaluation judges trajectories as evidence of system-level performance and process."
- retry budget: A limit on the number of retries allowed during interaction or execution. "including tool access, observation space, retry budget, reset condition, or environment version."
- Safety, Alignment, and Social Competence: Evaluation dimensions testing norm adherence, cooperation, and appropriate communication. "Safety, Alignment, and Social Competence."
- simulator artifacts: Peculiarities of simulated environments that agents might exploit to achieve scores without real competence. "Fidelity, Control, and Simulator Artifacts."
- Standardization--Diversity Tradeoff: The tension between comparable infrastructure and preserving diverse evaluation formats. "Standardization--Diversity Tradeoff."
- state drift: Gradual changes in persistent state across interactions that can accumulate and affect performance. "including ambiguity, misleading feedback, partial failure, state drift, and counterpart adaptation."
- stochastic runs: Multiple randomized executions used to estimate performance variability and robustness. "It may combine executable tests, state checks, human or model judges, process annotations, penalties for unsafe actions, and aggregation across stochastic runs."
- substrate-independent programs: Evaluation programs designed to apply across different environments or tools. "revealing gaps in trajectory-level scoring, substrate-independent programs, and evaluations combining tools, users or agents, memory, and changing environments."
- Task Success: An evaluation program checking whether the final state meets the specified goal. "Task Success."
- trajectory evidence: The recorded sequence of actions, observations, and state changes used as the basis for evaluation. "Trajectory evidence is only interpretable relative to the protocol that generates it."
- trajectory-level judgment: Scoring that assesses properties of the process itself, not just the final outcome. "without fully developing trajectory-level judgment."
- trajectory viewers: Tools for inspecting and analyzing recorded trajectories for evaluation and audit. "The field needs reusable environments, logging schemas, trajectory viewers, evaluation harnesses, and reporting templates."
- user simulators: Models or scripted systems that emulate user behavior to generate interaction trajectories. "user simulators"
- web environment: An executable setting where agents interact with the web through actions and observations. "The trajectory may come from a web environment~\citep{zhou2023webarena,he2024webvoyager},"
Collections
Sign up for free to add this paper to one or more collections.