- The paper introduces a unified taxonomy for neural decoders, revealing that data scaling combined with proper inductive bias is key to improved decoding accuracy.
- It employs FPGA-based INT4 quantization and aggressive pruning to achieve microsecond-scale (sub-1μs) latency for d=9 rotated surface codes.
- The study shows that hardware-aware neural decoder designs can outperform classical methods like MWPM, advancing scalable fault-tolerant quantum computing.
Revisiting Neural Decoders in Quantum Error Correction: Accuracy, Inductive Bias, and Hardware Co-Design
Motivation and Scope
Quantum error correction (QEC) underpins scalable fault-tolerant quantum computation, with the decoder—extracting and correcting logical errors from syndrome data—being a critical algorithmic component. This paper systematically reexamines neural decoders for QEC, focusing on the rotated surface code, and explicitly considers the hardware-imposed accuracy–latency tradeoff that arises in real-world quantum control, where microsecond-scale feedback is mandatory for logical qubit integrity. The study develops a unified taxonomy of neural decoder architectures and introduces an end-to-end neural compression pipeline targeting efficient deployment on FPGAs, addressing code distances up to d=9 (161 physical qubits), thus directly engaging with experimentally relevant scales.
The rotated surface code, as illustrated in (Figure 1), constitutes a 2D stabilizer code with local check operators encoding a logical qubit across a lattice of data and ancillary qubits. Error detection is achieved by repeated syndrome extraction, mapping the QEC task to a spatiotemporal classification setting. On each cycle, the decoder must infer the logical update given a syndrome tensor, optimizing for both logical error rate (LER) and real-time decision latency to enable live operation within the hardware's feedback clock.
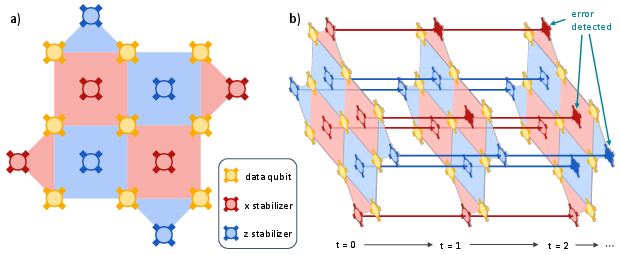
Figure 1: Schematic of a d=3 rotated surface code; surface-code data qubits and stabilizers are shown along with syndromic error propagation through time.
Neural Decoder Architectures: Inductive Bias and Unified Benchmarking
The study conducts an extensive evaluation of five canonical decoder families, each exemplifying different computational priors toward the code's structural and temporal complexity:
- MLPs: Structure-agnostic, fully-connected baselines, disregarding lattice locality.
- Dilated 3D-CNNs: Exploiting spatiotemporal locality but avoiding spatial pooling; parameter count scales rapidly with code distance.
- TCNs: Modular separation of spatial convolution and temporal aggregation, designed for parallelizable and quantization-friendly sequence processing.
- Transformers: Global self-attention with modified input tokenization to compensate for sparse binary syndrome signals.
- GNNs (Neural BP): Message-passing on Tanner graphs, with learnable update rules overcoming some standard BP instabilities.
This architectural unification enables a controlled comparison of data scaling, model complexity, and the impact of inductive bias on both accuracy and scalability.
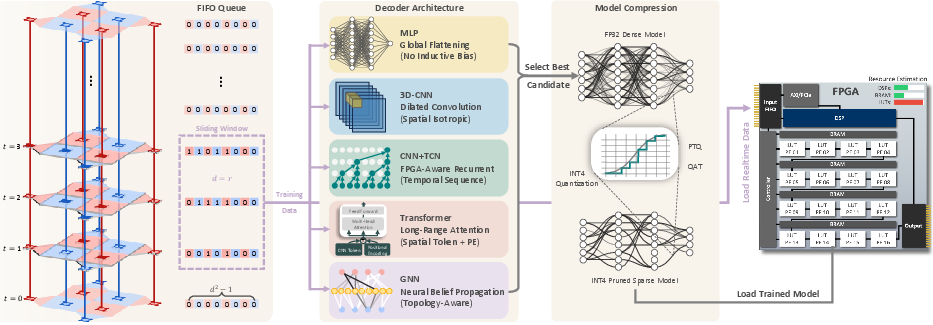
Figure 2: Complete QEC pipeline: causal syndrome windowing, neural architectural spectrum, and hardware-aware INT4 compression mapped to a LUT-based FPGA accelerator.
The Dominance of Data Scaling and the Necessity of Structural Priors
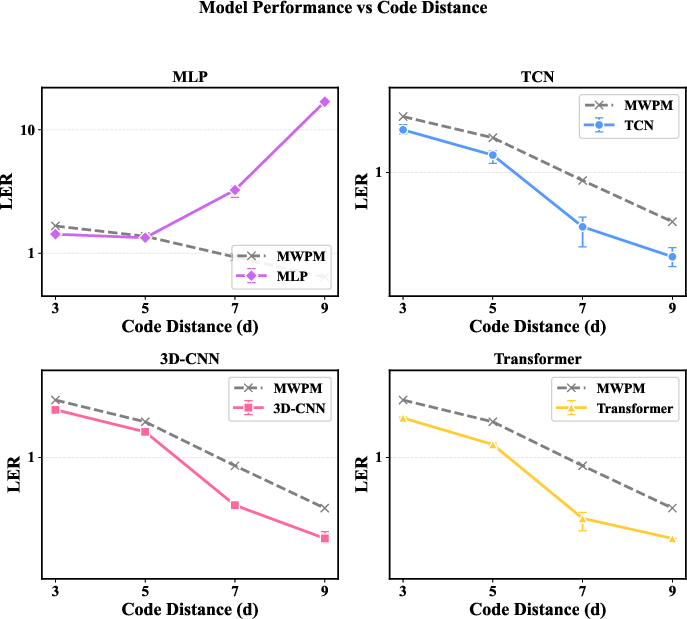
Experiments reveal that, provided correct inductive bias, decoding performance is predominantly driven by training set size rather than architectural depth or parameter count, particularly in the regime of up to 107 syndrome samples. Explicitly, compact TCNs and 3D-CNNs trained with larger data outperform more complex models trained on modest datasets. However, this data-dominant regime is bounded: absence of suitable architectural prior (as in MLPs) or misalignment (GNNs on lattices with short cycles) results in rapid performance degradation at higher code distances, resistant to remediation even with orders-of-magnitude more training data. Models explicitly encoding spatial and/or temporal structure—e.g., TCN and CNN—consistently outperform both the minimum-weight perfect matching (MWPM) baseline and other neural decoders at large code distances, whereas MLPs and GNNs fail to generalize or scale.
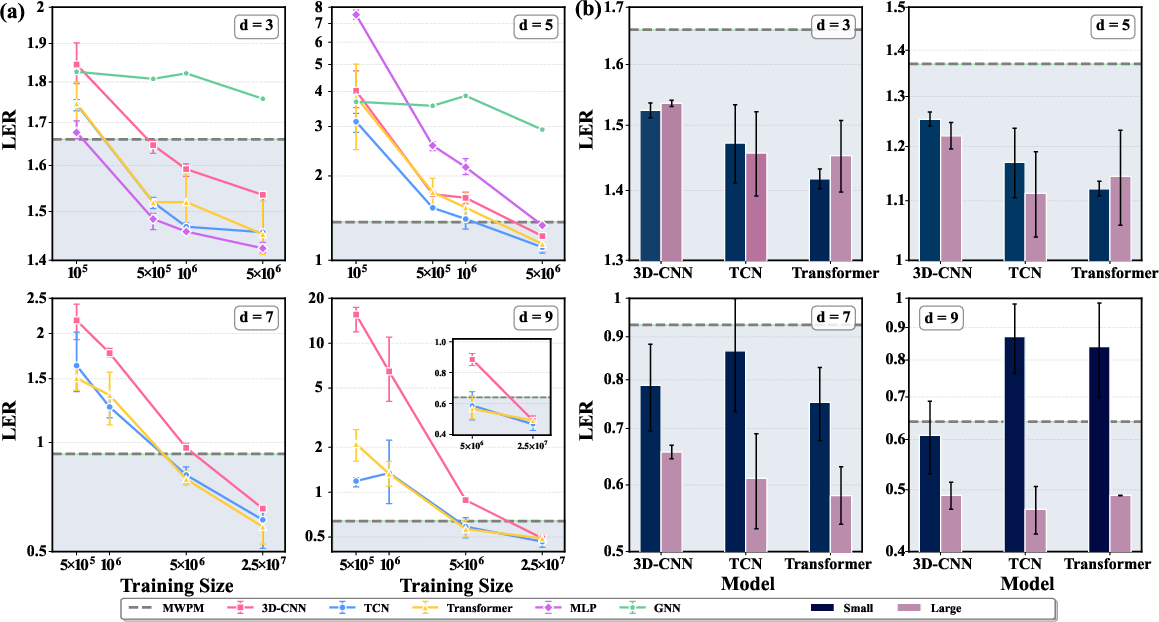
Figure 3: Decoding accuracy as a function of data size and model family on the surface code; LER improvement is data-limited for suitably structured models, while the benefit saturates quickly for unstructured MLPs.
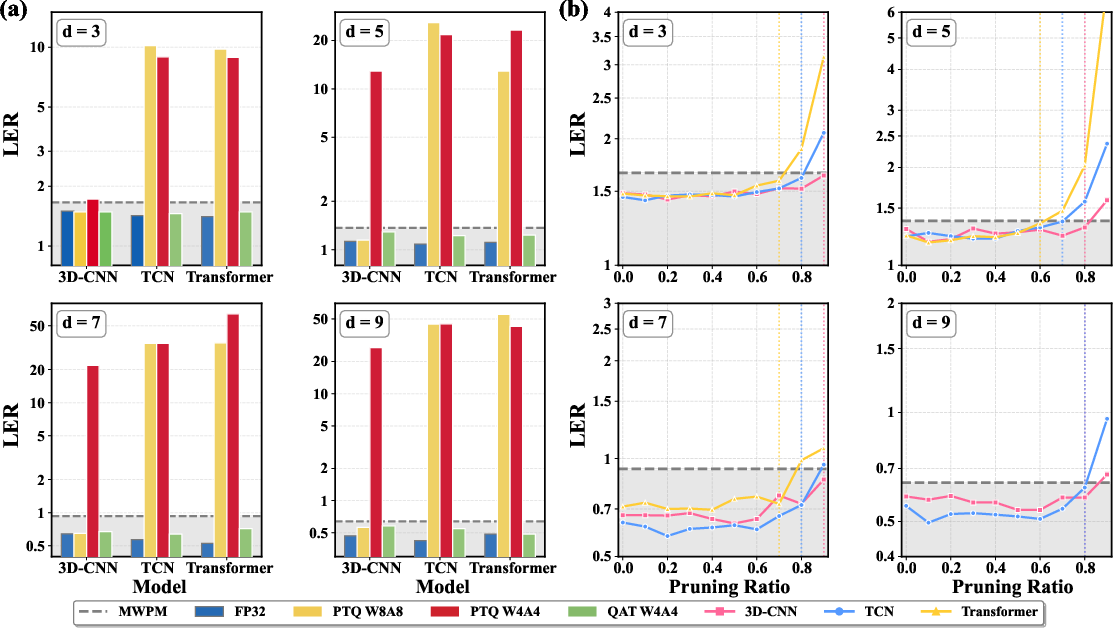
Hardware Co-Design: Quantization, Pruning, and Real-Time Deployment
Meeting microsecond-scale latency on real FPGAs necessitates an aggressive compression regime. The pipeline integrates INT4 quantization and magnitude pruning, leveraging quantization-aware training (QAT) to retain decoding fidelity, especially for sequence models vulnerable to quantization-induced accuracy loss. Results demonstrate that:
Model Selection, Training Efficiency, and Real-World Validation
Implications, Limitations, and Prospects
This work demonstrates that high-fidelity, real-time QEC decoding is realizable through careful data-model-hardware co-design: large-scale data, strong geometric/temporal inductive bias, and INT4 QAT-optimized, pruned models mapped to logic-heavy FPGAs. Findings highlight the non-negotiable requirement for inductive bias in neural codes—data scale is effective only when coupled to appropriate architectural structure. Furthermore, aggressive quantization and pruning must be an integral part of the decoder training regime whenever hardware deployment is anticipated. These principles generalize to other inference workloads under stringent latency/footprint constraints on custom hardware.
The results imply a promising path for practical large-scale QEC: neural decoders tailored with suitable priors and hardware co-design can surpass classical alternatives in both accuracy and latency, provided their training incorporates realistic device noise priors. At the same time, the observed limits of data-driven decoding without inductive bias suggest that future work should focus not only on data scaling and architecture search, but on rigorous prior incorporation and domain alignment. The framework here further encourages joint optimization of quantum control stack and machine learning pipeline for holistic, system-level quantum error mitigation.
Conclusion
A comprehensive empirical and implementation-driven analysis confirms that, for neural decoders of the rotated surface code, strong inductive bias and microsecond-scale hardware-aware compression strategies are necessary for scalable and real-time fault-tolerant quantum computing. Well-designed hardware–algorithm co-design, especially integrating QAT and pruning, is shown to be the only viable path at the intersection of accuracy, scalability, and latency constraints. These findings directly inform both near-term and future high-throughput quantum computation and suggest critical design axes for real-world deployment of learning-enabled quantum control systems.