- The paper establishes that probabilistic calibration can be directly trained using soft-target and hard-target fine-tuning to align output distributions.
- The methodology leverages dense prefix-level supervision and cross-entropy optimization, resulting in orders of magnitude improvements in Wasserstein and KL metrics.
- The research highlights tradeoffs between numeric fidelity and general stochasticity, offering practical insights for scientific, statistical, and decision-making applications.
Probabilistic Calibration Is a Trainable Capability in LLMs
LLMs (LMs) deployed for stochastic tasks—where users require outputs sampled from explicit distributional targets—often fail to allocate probability mass faithfully, even for simple numerical distributions. Standard pretraining and post-training protocols optimize for next-token prediction and preferred task completion but do not incentivize calibrated output probabilities. Prior studies expose pronounced gaps between intended and actual stochastic behaviors, especially when direct sampling is requested ("pick a random number from 1 to 10") (2605.11845).
This paper investigates whether probabilistic calibration can be directly learned via fine-tuning. The objective is to bridge the gap between user-specified distributional laws and the empirical outputs of LMs, framing calibration as the joint problem of learning valid output supports and the probability mass assignments over those outputs.
Calibration Fine-Tuning Methodology
Calibration Fine-Tuning (CFT) employs synthetic prompts requiring sampling from mathematical distributions. Two CFT variants are studied:
- Soft-target fine-tuning: Converts the target output distribution into trie-derived next-token supervision, enabling dense distributional guidance at every token prefix.
- Hard-target fine-tuning: Supervises via standard next-token cross-entropy on sampled completions from the target distribution, thus providing sparse-path supervision.
Both variants operate by updating only LoRA adapters on frozen-base models. The soft-target mechanism, as summarized in Figure 1, builds canonical output spaces and token tries for prompts, then minimizes KL divergence between the induced next-token distributions and the model predictions. Hard-target fine-tuning samples completions and optimizes cross-entropy over masked completions.
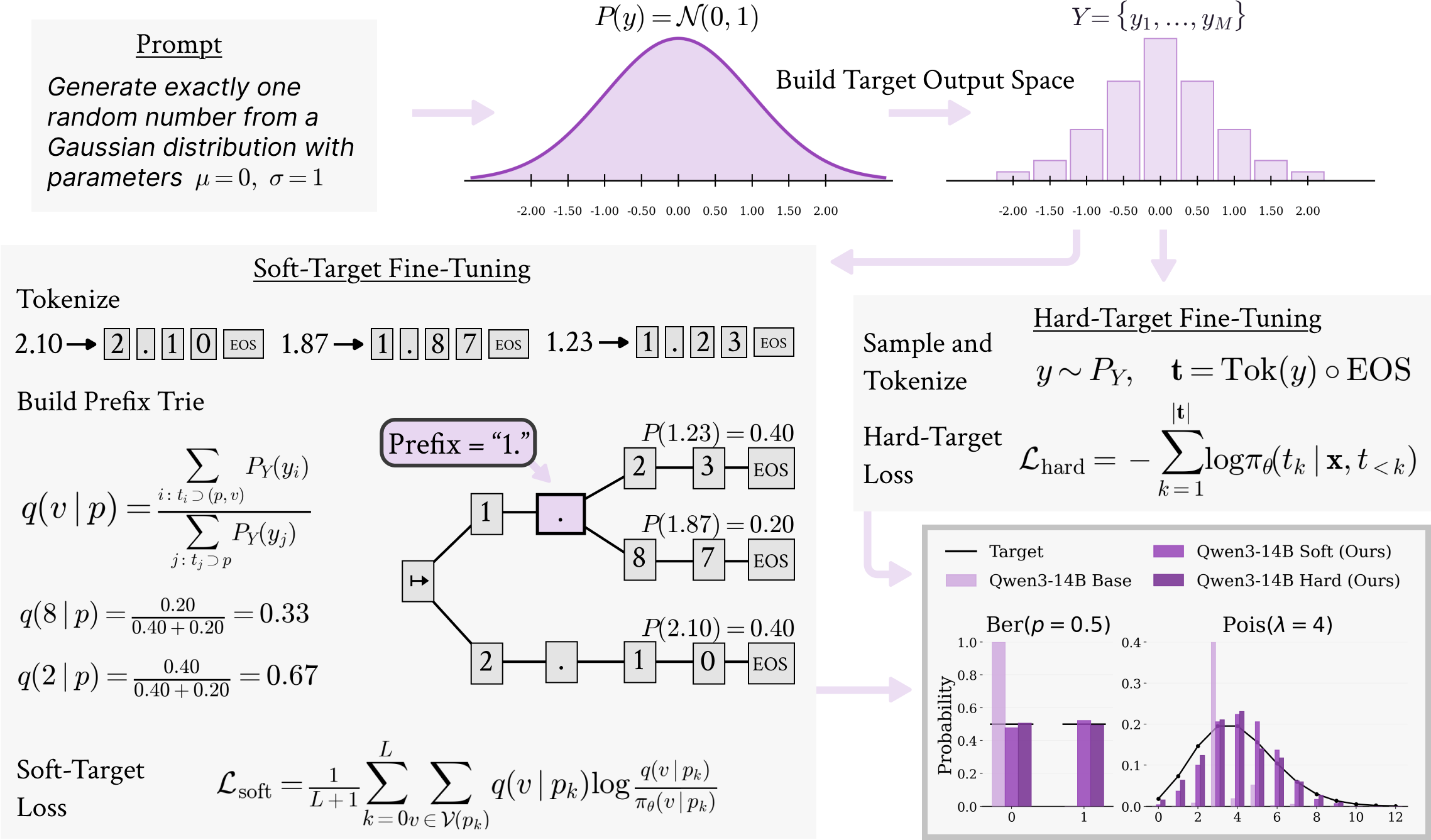
Figure 1: Calibration Fine-Tuning pipeline: soft-target (trie-derived next-token matching) versus hard-target (completion cross-entropy) supervision for probabilistic calibration.
Experimental Setup
The benchmark comprises 30 distribution families encompassing integer, discrete, and continuous laws. Training uses 24 families with grid-discretized parameters; 6 families serve as held-out OOD test cases. Canonical output spaces are quantized at five decimal precision, with bin caps (soft: 1001; hard: 16384) set via ablation studies. Models span Qwen3, Gemma-3-it, Llama-3.2-Instruct, and GPT-OSS, ranging from 0.6B to 27B parameters.
Evaluation axes include:
- Structured distribution sampling (sample-level Wasserstein distance, logit-level KL)
- Open-ended random generation (support breadth, unique output fraction)
- NoveltyBench (semantic partitioning and reward-based utility)
- MCQ answer-position balance (total variation from uniform distribution)
- Capability retention (TinyBenchmarks suite)
- PALOMA held-out language-model fit (perplexity, bits-per-byte)
Structured Distribution Sampling Results
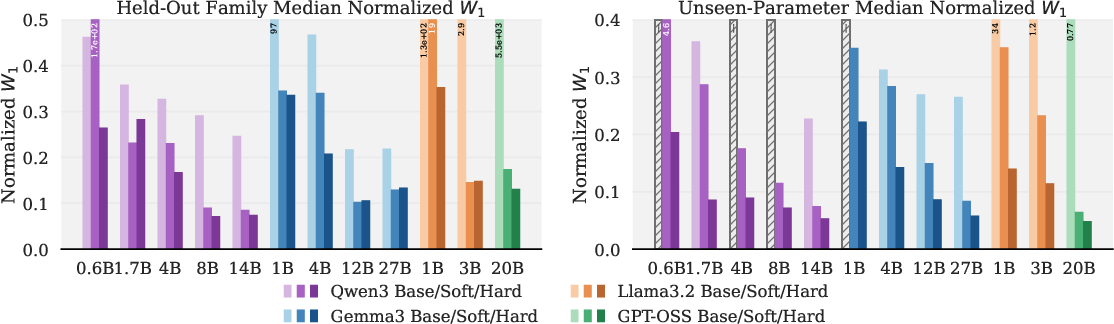
Empirical results show CFT substantially enhances distributional fidelity in structured sampling tasks (Figure 2). Both variants lower sample-level normalized Wasserstein-1 (W1) and logit-level KL by orders of magnitude, across all tested models, on both held-out OOD families and unseen parameter settings.
Qualitative sampling overlays further demonstrate improved match between empirical and target distributions (Figure 3). Models previously exhibiting narrow support or misallocation now sample validly and allocate mass in accordance with target laws.
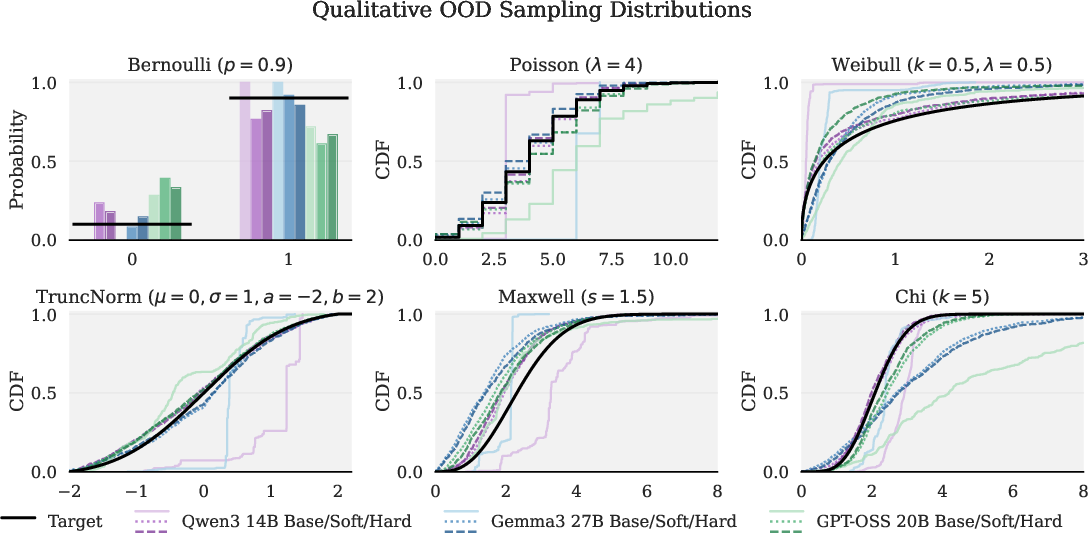
Figure 3: Qualitative OOD sampling: overlays of target distribution, base model, and CFT samples, demonstrating improved stochastic fidelity.
Transfer to Natural Language Stochastic Tasks
CFT-enhanced models generalize stochasticity beyond explicit mathematical prompts. On open-ended random generation, soft-target fine-tuning drastically broadens next-token support and increases unique output rates (Figure 4, Figure 5). Semantic diversity is augmented, especially for larger Qwen and Gemma models; however, this does not always uniformly translate to useful diversity in weaker models.
NoveltyBench evaluations show increased semantic partition counts and improved reward-based utility for most models, particularly favoring the soft-target configuration. However, some models (e.g., GPT-OSS-20B) experience reduced utility even as distinctness rises, indicating a tradeoff between breadth and quality.
MCQ answer-position balance benefits from CFT, with Qwen models exhibiting improved uniform answer placement. Transfer performance is model-family dependent and less consistent outside Qwen.
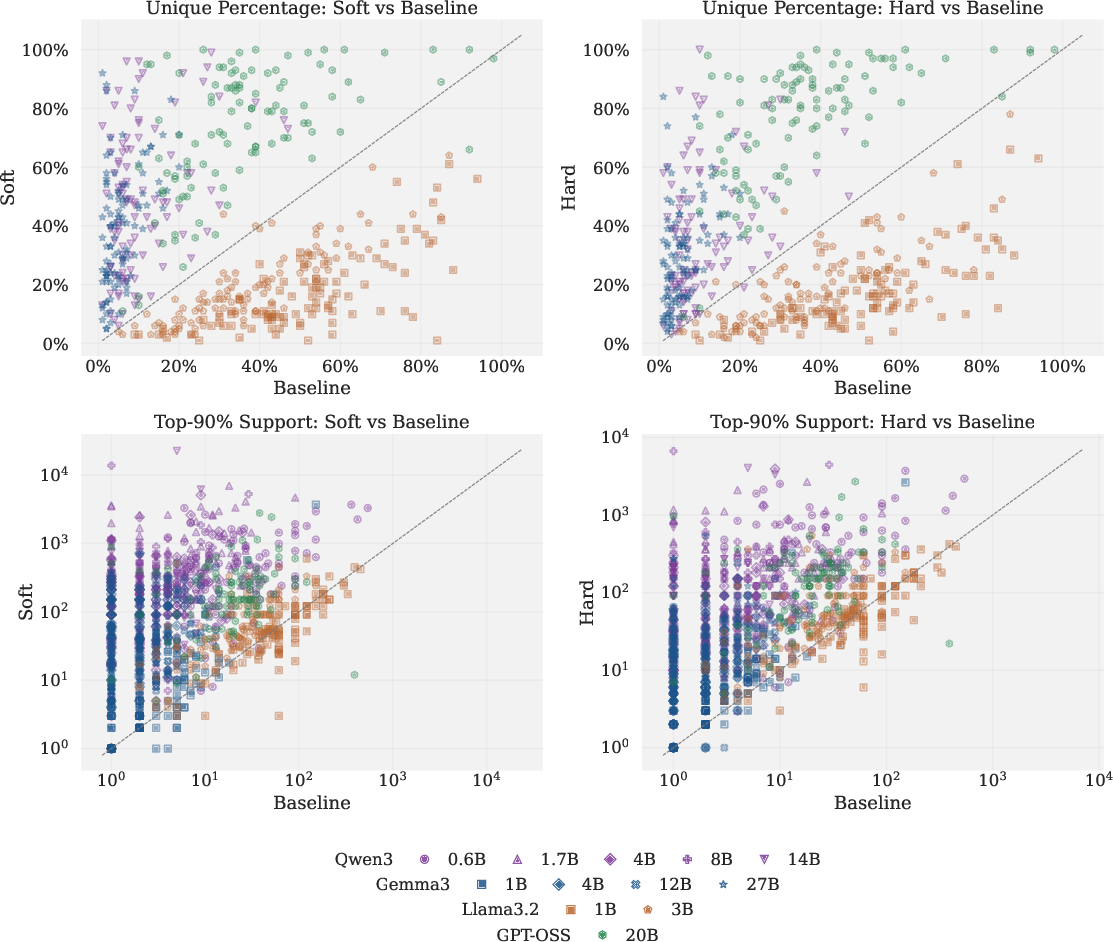
Figure 4: Per-prompt open-generation comparisons: soft-target and hard-target fine-tuned models achieve broader stochastic support and increased unique output rates.
Figure 5: Qualitative open-generation sampling: CFT broadens empirical output frequency distributions across diverse prompts.
Capability Retention and LLM Fit
CFT presents mixed retention results. TinyBenchmarks gp-IRT scores reflect modest degradation in arithmetic reasoning, with aggregate capability often favoring the base checkpoint, especially for smaller models. However, language-model perplexity on PALOMA is often preserved or improved after CFT, especially for Qwen and Gemma families, refuting the hypothesis that calibration simply flattens token probabilities and damages general fit.
Figure 6: Per-task retention gp-IRT breakdown: CFT’s impact varies by task, with arithmetic reasoning most affected.
Figure 7: PALOMA perplexity per slice: CFT sometimes improves or preserves held-out text likelihood.
Figure 8: PALOMA bits-per-byte evaluation: tokenizer-robust measures confirm frequent retention or improvement of language modeling.
Ablation Studies
Ablations on discretization precision, bin caps, and supervision budget inform selection of training hyperparameters. The final recommended configuration balances fidelity improvements against computational tractability and retention.
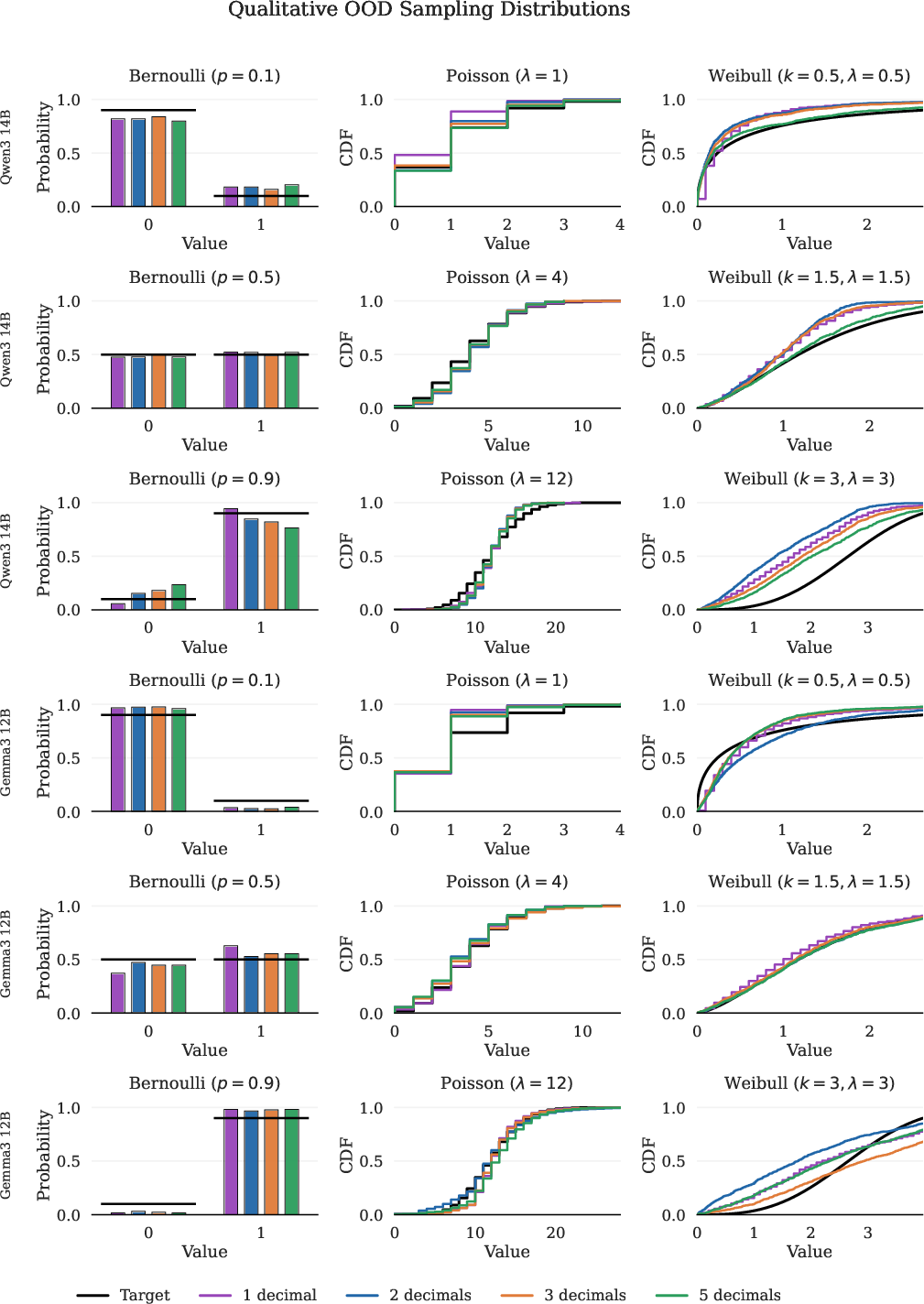
Figure 9: Qualitative impact of output discretization precision in soft-target CFT: finer discretization alters behavior, but calibration dominates over granularity.
Theoretical and Practical Implications
Findings confirm that probabilistic calibration is not merely a product of prompting or indirect supervision but is a trainable capability in LMs with appropriate fine-tuning protocols. Dense prefix-level supervision (soft-target) promotes broadly transferable stochastic generation, while sampled-path supervision (hard-target) enforces strict numeric fidelity.
Practically, CFT enables LMs to serve as calibrated probabilistic samplers, suitable for downstream scientific, statistical, and stochastic decision-making applications. The mechanisms learned by each variant may differ: soft-target training instills general distributional awareness, whereas hard-target training reinforces sample-wise fidelity.
Theoretically, CFT suggests that LMs can be trained to approximate arbitrary output laws given a tractable canonical output space, but hybrid approaches may be required to recouple calibration with downstream reasoning performance. Future developments could extend CFT to retention-aware calibration objectives and hybrid supervision protocols, exploiting adaptation of both stochastic and epistemic uncertainties across tasks.
Conclusion
Calibration Fine-Tuning enables substantial improvements in stochastic sampling tasks for LLMs. Both soft-target and hard-target variants achieve robust gains in structured numeric fidelity and broader language-space stochasticity. However, calibration-induced gains involve tradeoffs: the hard-target variant maximizes fidelity, the soft-target variant enhances stochastic transfer, and the retention of general capabilities is not uniformly guaranteed. Overall, probabilistic calibration is a controllable, trainable property of modern LMs; ongoing research will focus on integration of calibration with general task capabilities and adaptive distributional alignment for stochastic AI interfaces.