- The paper presents AutoREM, a memory-augmented LLM that automates robust optimization reformulation with minimal manual intervention.
- The paper demonstrates, via AutoRO-Bench, that the approach outperforms expert prompts and baselines, achieving up to 97.4% accuracy on in-distribution tasks.
- The paper validates the impact of modular memory components through ablation studies and transfer experiments, ensuring robust and scalable performance.
Introduction and Motivation
Robust Optimization (RO) addresses decision-making under uncertainty by requiring solutions to remain feasible for all admissible perturbations of problem data. While RO enables principled, reliable optimization, practical adoption has been throttled by the manual effort necessary to reformulate uncertain models into tractable deterministic counterparts—typically involving algebraic derivations grounded in convex analysis and duality. Recent advances in LLMs have automated aspects of optimization, particularly coding and initial formulation, but automating RO reformulation has remained intractable due to its requirement for mathematically consistent, multi-step reasoning.
The paper "Automated Reformulation of Robust Optimization via Memory-Augmented LLMs" (2605.11813) introduces two core contributions: (1) AutoRO-Bench, a systematic benchmark for assessing LLM-based RO reformulation; and (2) AutoREM, a tuning-free, memory-augmented framework that autonomously accumulates and refines reformulation knowledge to guide LLMs in robust counterpart derivation, without relying on domain experts or parameter updates.
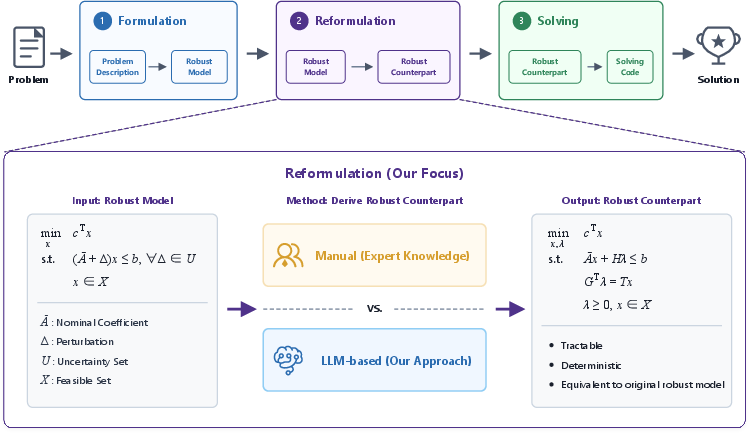
Figure 1: The robust optimization pipeline and focus on automating the reformulation stage.
Benchmark Design: AutoRO-Bench
AutoRO-Bench offers two evaluation tasks:
- RO Reformulation Task: Inputs formal mathematical models (in LaTeX) and requires LLMs to derive deterministic robust counterparts. The generated dataset spans diverse uncertainty sets (box, budget, polyhedral) and parametrizations, leveraging an automated pipeline that ensures notation-invariant learning and rigorous, solver-driven ground-truth.
- RO Application Task: Evaluates end-to-end LLM capability on realistic, language-described RO problem instances, with curated benchmarks from IndustryOR and OptiBench. Each instance appends uncertainty descriptions and robustness requirements to classical LP/MILP problems. Parameters may be provided symbolically, obligating LLMs to preserve mathematical expressions in reformulated outputs.
Both tasks employ solver-verification: a reformulator LLM produces an explicit robust counterpart, a coder LLM translates it to solver code, and numerical validation is conducted via RSOME or Gurobi, agnostic to output format.
Methodology: AutoREM Framework
AutoREM is a memory-augmented, tuning-free paradigm that enables an LLM to reformulate RO problems by drawing explicitly on past experience, encoded as a repository of structured textual memory. The pipeline comprises offline adaptation and online inference:
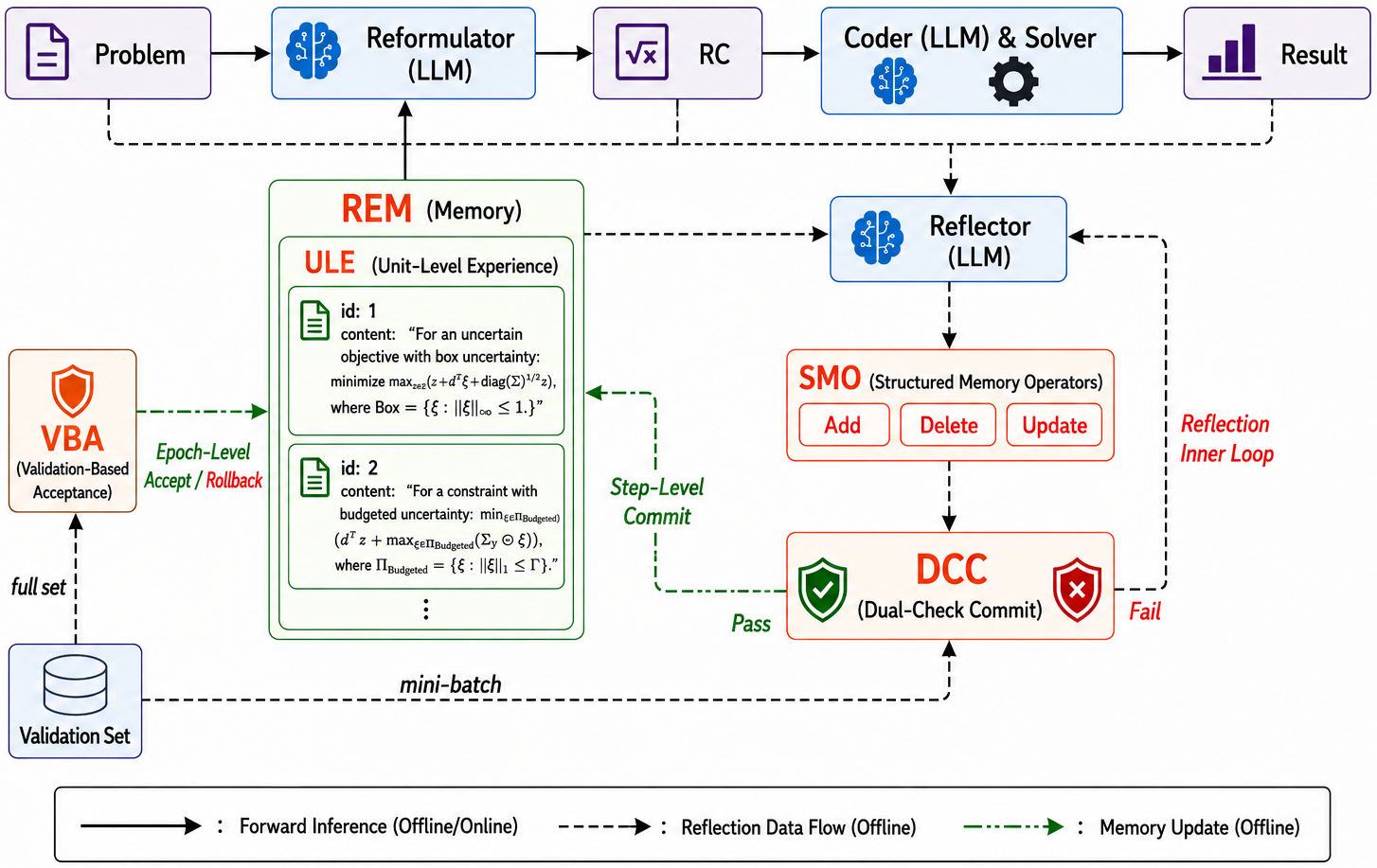
Figure 2: Overview of the AutoREM pipeline.
Offline Adaptation: AutoREM constructs high-quality experience memory via four core components:
- Unit-Level Experience (ULE): Reformulation knowledge is decomposed at the granularity of individual uncertain rows (objective or constraints), enhancing precision and modularity of reuse.
- Structured Memory Operators (SMO): Atomic add, update, and delete operations permit fine-grained, interpretable modification of memory entries.
- Dual-Check Commit (DCC): Proposed memory edits are batch-validated against correlated instances; only universally beneficial updates are committed, preventing silent regressions.
- Validation-Based Acceptance (VBA): Epoch-level evaluation ensures global memory quality; harmful updates are rolled back, and only the best-performing snapshot is retained.
Online Inference: All memory entries are supplied in-context to the reformulator, allowing dynamic attention and retrieval without external indexing modules. This approach circumvents the pitfalls of additive-only or unverified memory accumulation, which in prior work (e.g., ACE, ReasoningBank) caused performance degradation due to propagation of erroneous traces.
Experimental Evaluation
Datasets: AutoREM is evaluated on three reformulation datasets (Random/in-distribution, Hard/out-of-distribution, Large/higher-dimensional) and a 32-instance application set.
Baselines: Comparisons include Max Thinking (test-time computation scaling), domain Expert Prompts, prior memory methods (ACE, ReasoningBank), and leading formulation frameworks (AlphaOPT, LEAN-LLM-OPT, OptiTree).
Key Results:
- Accuracy: AutoREM achieves 97.4% on Random, outperforming Expert Prompt by +4.7%, Max Thinking by +6.8%, and ACE/ReasoningBank by more than +10%. On the Hard split, the accuracy drop is minimal (−2.6%), whereas all baselines degrade substantially. AutoREM maintains a 24% absolute advantage over the Base LLM in this setting.
- Efficiency: AutoREM uses 54% fewer output tokens than Max Thinking and achieves consistent efficiency gains over all baselines even as problem dimensions increase.
- Generalization: Memory constructed using DeepSeek-V4-Flash transfers effectively to other flagship LLMs (GPT-5.4, Qwen3.6-Plus), with accuracy improvements of +6.3% and +7.3%, respectively.
- Ablation: Removing any of ULE, SMO, DCC, VBA induces non-trivial accuracy loss, substantiating their necessity.
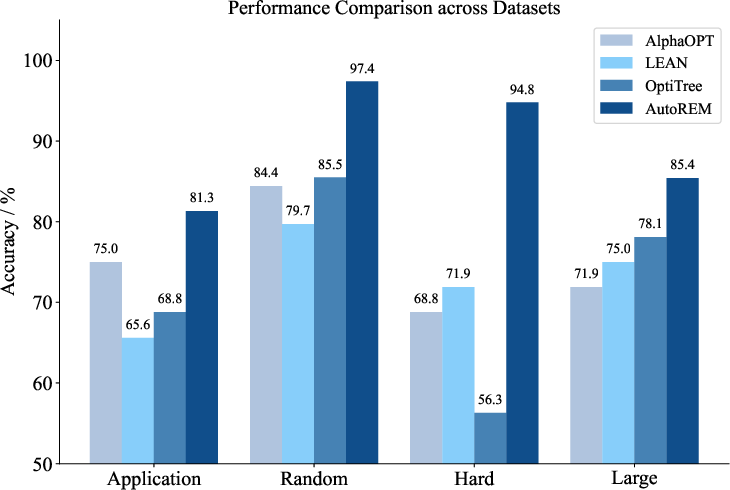
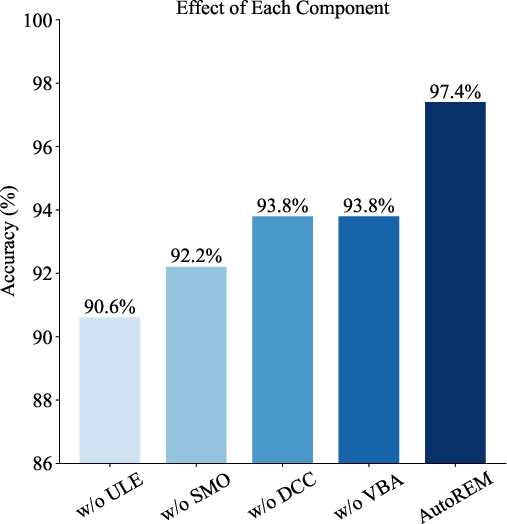
Figure 3: Comparison with LLM-based benchmarks on end-to-end application instances.
Memory Analysis and Adaptation Dynamics
AutoREM's memory converges to a minimal set of verified, non-redundant reformulation templates (eight canonical entries), contrasting sharply with prior approaches that collect dozens of overlapping or contradictory strategies. The adaptation dynamics are visualized by monitoring validation accuracy during offline learning. Notably, the VBA mechanism actively prevents permanent regressions by rolling back injurious updates, stabilizing accuracy at the highest plateau.
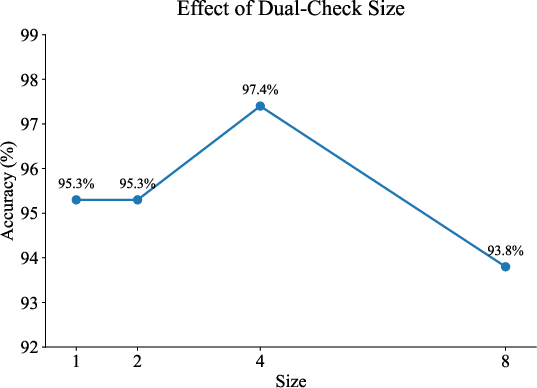
Figure 4: Effect of dual-check batch size B on adaptation accuracy.
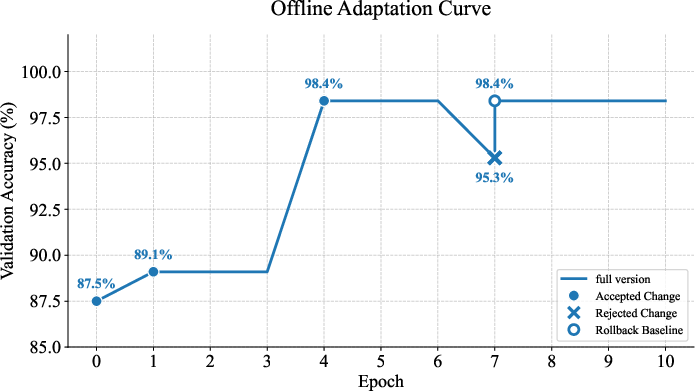
Figure 5: Validation accuracy curve across offline adaptation epochs.
Implications and Future Directions
Practically, AutoREM demonstrates that algorithmic, solver-grounded experience memory enables robust automation of mathematical derivations, traditionally requiring domain experts. The approach scales efficiently, generalizes to unseen problem structures and larger dimensions, and offers strong transferability across heterogeneous LLMs. Theoretically, it provides evidence that structured, fine-grained, and verifiable memory augmentation is essential for tasks requiring mathematical exactness, as indiscriminate accumulation is harmful. Future research may extend AutoREM to more general problem classes (MIRO, non-linear RO, constraints with high-level symmetries), leverage weaker supervision signals (e.g., feasibility checks), and explore integration with meta-reasoning or agentic LLM workflows.
Conclusion
AutoREM, evaluated on the systematic AutoRO-Bench, establishes a highly accurate, efficient, and transferable paradigm for automated RO reformulation via memory-augmented LLMs, outperforming prior expert prompts and memory frameworks. Its selective, verifiable memory construction and modular attribution are critical for algebraically precise reasoning. The results substantiate the necessity of quality-focused adaptation for mathematically rigorous tasks and suggest promising directions for scalable AI-driven optimization modeling.

