- The paper demonstrates that a dual-memory architecture jointly optimized with diagnostic reasoning via reinforcement learning leads to remarkable accuracy gains.
- It introduces Group Relative Policy Optimization to balance diagnostic rewards and memory efficiency, ensuring effective adaptation to evolving clinical cases.
- Empirical evaluations on MedCaseReasoning and ER-Reason datasets confirm the agent's superior performance and its ability to generalize in real-world clinical environments.
Joint Optimization of Reasoning and Dual-Memory for Self-Learning Diagnostic Agent
Motivation and Problem Setting
LLM-based clinical diagnostic agents have demonstrated substantial progress in automated reasoning and decision support. However, prevailing approaches consistently exhibit limitations in experience-driven adaptation; cases are processed independently, precluding mechanisms for experience accumulation and reuse. These shortcomings are pronounced in real clinical practice, where expert clinicians leverage both (i) formal medical knowledge and (ii) experiential diagnostic heuristics distilled from prior cases, especially for rare diseases and presentations with subtle cues. To address this gap, the paper introduces a self-learning agent trained via reinforcement learning to jointly optimize diagnostic reasoning and the management of a cognitively inspired dual-memory module.
Dual-Memory Architecture and Policy Framework
The proposed agent architecture is centered on two memory clusters: a bounded-capacity short-term cluster retaining recent cases annotated with outcomes, and a long-term cluster storing abstracted diagnostic rules synthesized from evicted cases. The dual-memory design reflects clinical reasoning patterns, enforcing explicit decisions about what information to retain, consolidate, or abstract.
At each decision round t, the policy model πθ observes a new patient case xt, possibly invokes memory operations (list, append, pop, consolidate), and emits the final output ot (diagnosis and structured reasoning). Policy updates are performed via Group Relative Policy Optimization (GRPO), leveraging round-wise rewards that combine diagnostic correctness and memory efficiency.
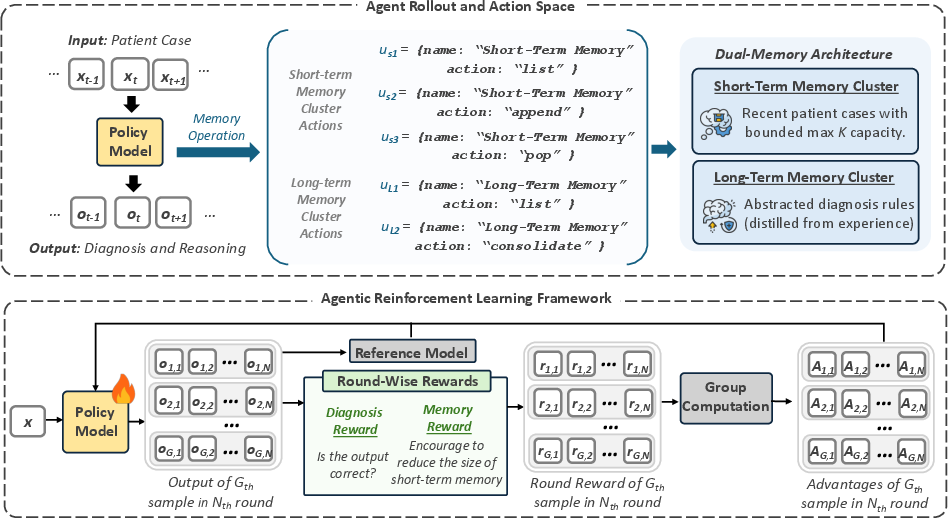
Figure 1: Agent structure: at each round, the model processes a patient case, operates on dual-memory, and updates policy via sampled rollouts and rewards.
Reward Modeling and Optimization
The reward function is decomposed into diagnostic and memory components:
- Diagnostic Reward: rtdiag provides strong supervision for prediction correctness (+5 for correct, -5 otherwise).
- Memory Reward: rtmem penalizes large occupancy of short-term memory, enforcing timely consolidation; −α⋅∣MtS∣/K with explicit schedule interpolation across rounds.
A linear interpolation is employed to modulate the weighting of rewards across the temporal stream, accentuating memory formation in early rounds and diagnostic accuracy in later stages. This round-wise reward shaping mitigates cold-start variance and incentivizes staged learning.
Experimental Evaluation
Standard Evaluation: MedCaseReasoning Dataset
Evaluation on MedCaseReasoning (closed-set, rare and complex cases) demonstrates pronounced gains:
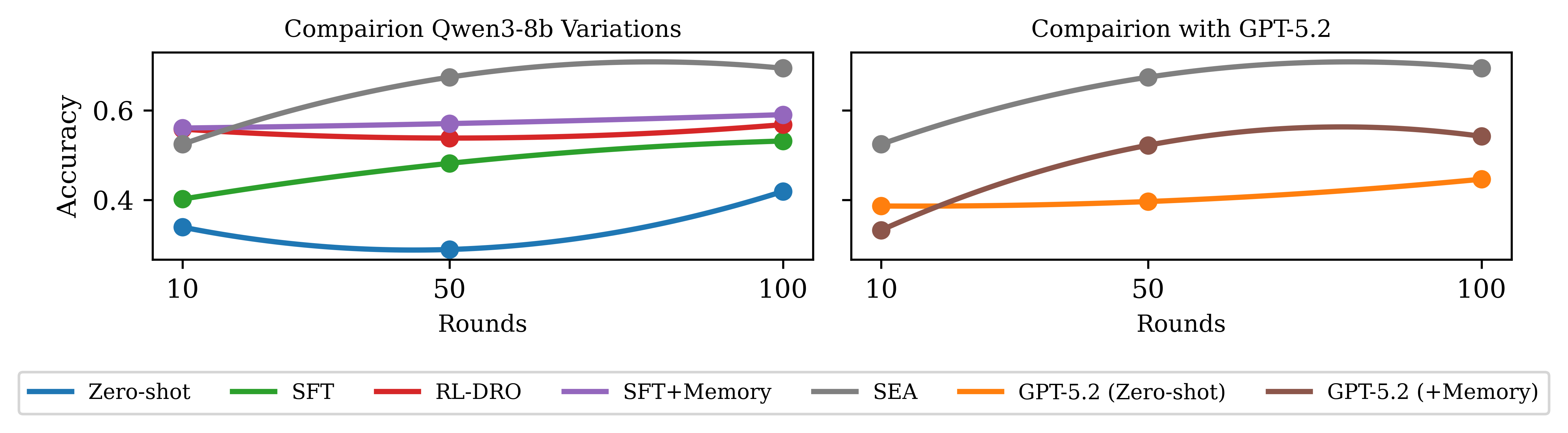
- SEA (Qwen-8B) achieves 92.46% accuracy (+19.6% improvement over strongest baseline) and 86.81 macro-F1.
- RL with outcome-only rewards yields modest improvements (77.32%), confirming that guided memory optimization is essential.
- Naive memory-augmented baselines degrade performance (e.g., ReAct+ShortTerm-Memory drops to 42.51%), underscoring the necessity of structured memory management.
Long-Horizon Evaluation: ER-Reason Dataset
In stream-based deployment settings (ER-Reason), the self-learning agent outperforms all variants:
Ablation and Expert Evaluation
Ablation experiments on MedCaseReasoning validate the criticality of each module:
- Removing dual-memory or memory-management reward results in sharp declines (e.g., accuracy drops to 0.4741 below zero-shot baseline).
- Short-term memory enhances alignment with instance context; long-term memory provides generalization, but both require regulated management.
Clinical expert evaluation (Likert scale, 5-point) yields high scores for rule practical utility (3.946), clinical correctness (3.865), and trust (4.216), confirming that induced rules are reliable and applicable. Lower case-relevance (2.595) aligns with the intentional abstraction for generalization.
Theoretical and Practical Implications
This work establishes that structured dual-memory enables continual adaptation in diagnostic agents without parameter updates, challenging the dependency on static context and retraining. Experience-driven memory consolidation is fundamental for sustained learning in deployment environments with distributional drift and sparse supervision. The dual-memory module is externally implementable, facilitating rapid integration with diverse LLM architectures. The reinforcement framework jointly optimizes reasoning and memory, ensuring traceable, auditable decision-making.
Future Directions
Key extensions include broadening the action space (e.g., evidence gathering), integrating multi-modal inputs (lab findings, imaging), establishing safety and privacy protocols for clinical deployment, and formalizing memory consolidation algorithms for richer abstraction. Exploration of hierarchical memory structures and adaptive compression schemes will improve scalability in larger, more heterogeneous environments. Long-horizon RL remains pivotal for robust adaptation under non-stationary clinical streams.
Conclusion
The joint optimization of reasoning and dual-memory mechanisms demonstrably improves both static and deployment-phase diagnostic accuracy, enabling agents to transform experience into reusable diagnostic knowledge. The agent substantially outperforms baselines across multiple metrics and settings, with dual-memory providing modular, generalizable adaptation capabilities and memory-regulated reinforcement driving sustained improvement (2604.07269).
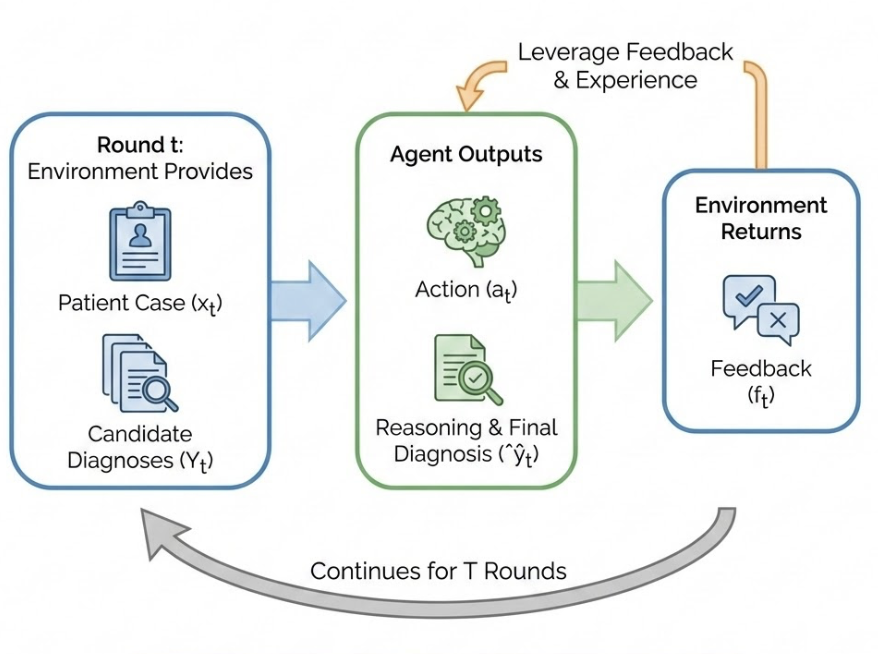
Figure 3: Task setup for sequential diagnosis; agent outputs reasoning and diagnosis, receives feedback, and leverages memory for ongoing adaptation.