Optimistic Dual Averaging Unifies Modern Optimizers
Abstract: We introduce SODA, a generalization of Optimistic Dual Averaging, which provides a common perspective on state-of-the-art optimizers like Muon, Lion, AdEMAMix and NAdam, showing that they can all be viewed as optimistic instances of this framework. Based on this framing, we propose a practical SODA wrapper for any base optimizer that eliminates weight decay tuning through a theoretically-grounded $1/k$ decay schedule. Empirical results across various scales and training horizons show that SODA consistently improves performance without any additional hyperparameter tuning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SODA, a simple way to think about many popular deep-learning optimizers as part of one big family. It also gives a practical “wrapper” you can put around almost any optimizer (like Adam, Lion, Muon, or NAdam) to make it work better without extra tuning. The headline idea: use a built‑in, time‑based “weight decay” that automatically shrinks over time like 1/k, so you don’t have to guess this value yourself.
What questions does the paper ask?
- Can we explain a lot of modern optimizers (like Adam, Lion, Muon, NAdam) using one common framework?
- Can we remove the need to tune weight decay by replacing it with a simple, well‑founded schedule that works across models and training lengths?
- Can we prove why this works and show it helps in practice?
How does the method work?
Think of training like steering a bike down a hill:
- You use the slope to decide where to go (the gradient).
- You also smooth out bumps by remembering past slopes (averaging).
- You sometimes gently pull the bike back toward the start to keep it from drifting too far (weight decay).
SODA organizes these ideas cleanly, using three ingredients.
1) Two kinds of averaging: “dual” and “primal”
- Dual averaging: Keep a running average of gradients (how the loss is changing). SODA also adds “optimism,” which means slightly leaning toward where you think the next gradient is going. This is similar to “Nesterov momentum” you may have heard of.
- Primal averaging: Also average the model’s positions (the weights themselves) over time. This makes updates more stable.
Together, these two tracks let you both predict better steps and keep the model’s path smooth.
2) Geometry: different “rulers” for taking steps
Different optimizers use different ways of measuring and scaling steps:
- Adam scales each parameter separately (element‑by‑element).
- Lion uses only the sign of the gradient (direction over size).
- Muon uses “spectral” steps for matrices (moving entire layers in a coordinated way).
SODA can plug in any of these “geometries.” That’s why it can describe many optimizers inside the same framework.
3) The SODA wrapper: a simple add‑on you can use today
The wrapper is a tiny procedure you place around your favorite optimizer (the “base optimizer”). It:
- Keeps a copy of the initial weights (the starting point).
- At each step k, it mixes the current result with a small piece of the initial weights.
- The mixing amount is 1/(k+2), which creates an automatic, time‑decaying weight decay (strong at the start, weaker later).
You can think of it like a gentle rubber band tied to the starting point. The band loosens as training goes on, so early on you stay centered and stable, and later you can explore more freely. Crucially, you don’t add any new knobs to tune—the base optimizer’s learning‑rate schedule stays as is, and weight decay tuning disappears.
What did the researchers actually do?
- Theory: They show mathematically that many modern optimizers are special cases of SODA when you pick certain averaging choices and geometries. They also prove that the 1/k weight‑decay‑like mixing is a sound choice and leads to good convergence behavior.
- Unification: They demonstrate how Adam/NAdam, Lion, Muon, and others fit as “optimistic” dual‑averaging methods inside SODA.
- Practice: They test the SODA wrapper on several optimizers and tasks at different scales and training lengths, without adding any hyperparameters or manual weight‑decay tuning.
Main findings and why they matter
- One framework for many optimizers: Methods like NAdam, Lion, Muon (and more) are all just different settings of the same SODA template. This makes the field easier to understand and extend.
- A zero‑tuning weight decay schedule: The wrapper naturally creates a time‑based weight decay of size 1/k. It starts strong, then fades, and it’s tied to training time (k), not model size. That means fewer “magic numbers” to guess.
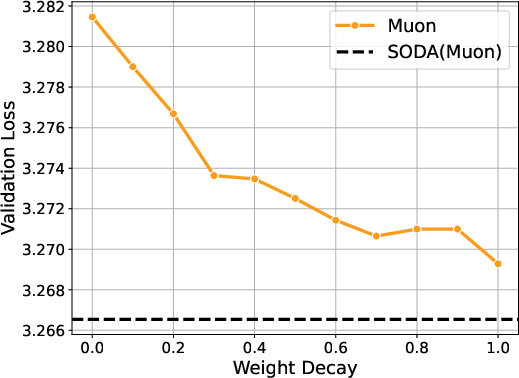
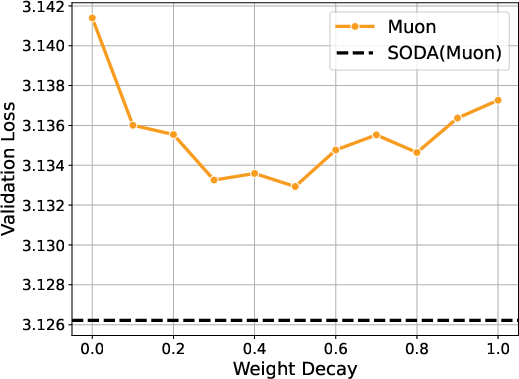
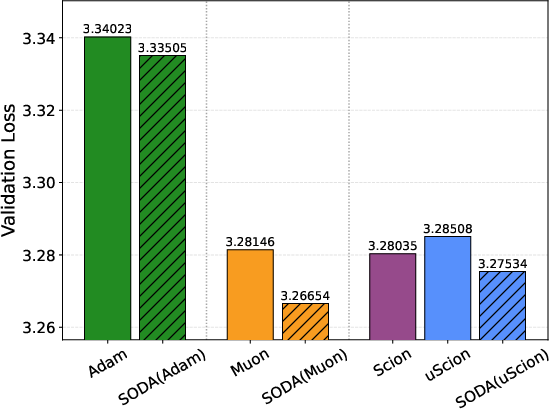
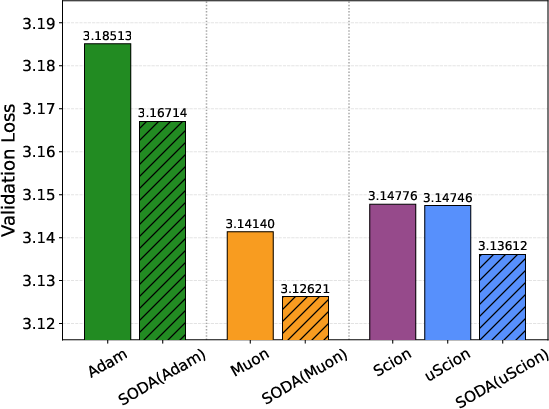
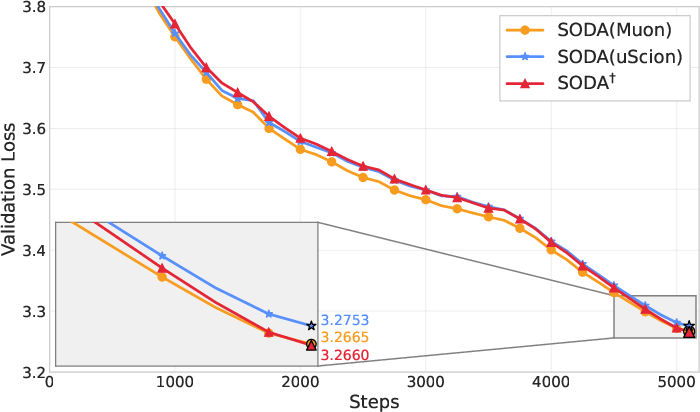
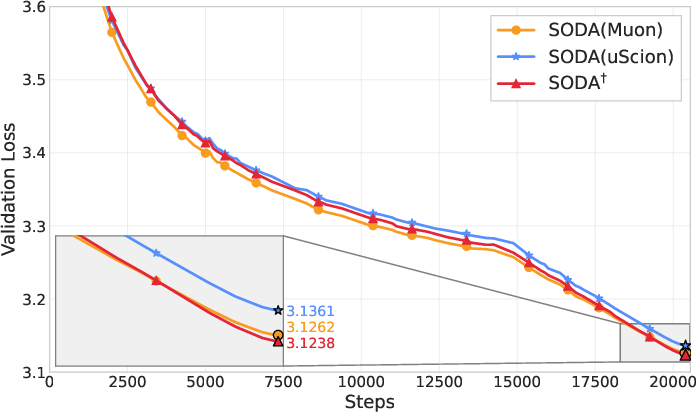
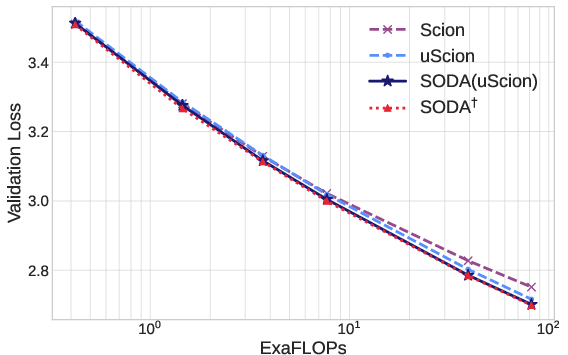
- Simple and effective: Wrapping Adam, Muon, or Scion with SODA reliably improves results across model sizes and training horizons—even beating baselines that had carefully tuned weight decay.
- Theory supports practice: The math explains why the wrapper’s choices are stable and efficient, and clarifies that this “weight decay” is acting like smart averaging of the model’s positions, not just a generic penalty.
Here are some of the well‑known optimizers SODA brings under one roof:
- Adam / NAdam (element‑wise scaling; NAdam adds “optimism”)
- Lion (sign‑based steps with momentum)
- Muon (spectral steps for matrices)
- Scion and related spectral or multi‑norm methods
What’s the impact?
- Fewer dials to turn: The wrapper removes weight‑decay tuning from your training recipe. That’s a big deal at large scales, where tuning is expensive.
- Clearer design space: By separating “how you average” and “what geometry you use,” SODA makes it easier to design new optimizers and understand why existing ones work.
- Practical plug‑and‑play: You can take your current optimizer and add SODA’s wrapper to get more stable, often better training—no extra hyperparameters.
A note on limitations
The paper focuses on single‑epoch settings (you pass through the data once). For multi‑epoch training, you might still want a knob to control the strength of regularization to prevent overfitting.
In one sentence
SODA explains modern optimizers as one family and offers a tiny, theory‑backed wrapper that gives you automatic, time‑decaying weight decay (1/k), improving training quality without extra tuning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Extend the convergence analysis from convex objectives to nonconvex deep learning losses (e.g., ReLU networks), including conditions under which SODA retains stability and performance guarantees in practice.
- Generalize the theory to time-varying geometries and adaptive mirror maps (e.g., Adam/NAdam’s second-moment preconditioner, Shampoo), instead of the current analysis which assumes a fixed regularizer h.
- Analyze the impact of bias-corrections and the ε-stabilization term in Adam/NAdam on the SODA mapping (positive homogeneity and the z-update), and establish when the SODA wrapper is theoretically equivalent to these adaptive updates.
- Provide formal guidance on choosing and scheduling the optimism parameter (bar α_k) and gradient averaging (α_k) in practical deep learning settings where constant β-values are common; quantify trade-offs between constant vs. decaying schedules.
- Empirically and theoretically validate the proposed 1/k weight decay schedule beyond single-epoch settings: how to retain regularization benefits in multi-epoch training without losing the optimization advantages of iterate averaging.
- Disentangle model dimension (d) vs. training horizon (n) effects with controlled experiments that vary d and n independently (e.g., width scaling at fixed steps), to test whether 1/k time-decay alone suffices or if 1/d remains necessary in some regimes.
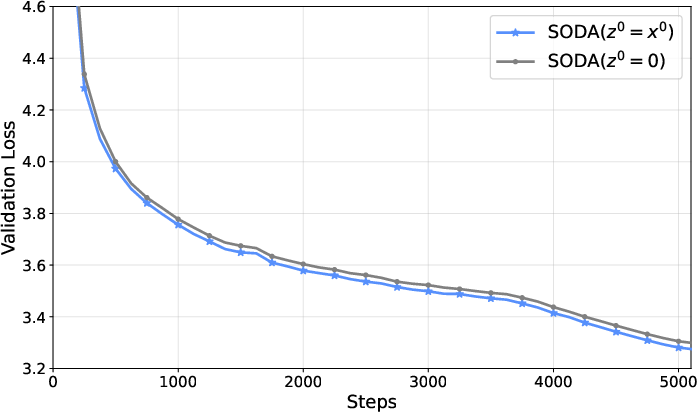
- Investigate how to adapt or reset the SODA anchor (z0) in multi-epoch training, curriculum schedules, or when restarting (e.g., per-epoch resets, periodic re-anchoring, or moving anchors).
- Study fine-tuning scenarios where the anchor is a pretrained checkpoint rather than random initialization: does centering at z0 help or hinder transfer, and should the anchor be updated during fine-tuning?
- Design selective-averaging policies that preserve standard “no weight decay” exceptions (e.g., biases, LayerNorm, batchnorm scales, some embeddings) while retaining the empirical gains of the SODA wrapper; characterize how exclusions affect theory and performance.
- Establish robustness under realistic noise models (heavy-tailed, non-iid, distribution shift) and common training tricks (gradient clipping, label smoothing, data augmentation), relaxing or replacing the current gradient-variation assumption.
- Quantify interactions between the wrapper’s 1/k iterate averaging and learning-rate schedules (warmup, cosine, linear, restarts), and give actionable recipes for joint scheduling that avoid early-phase underfitting or late-phase sluggishness.
- Compare SODA against schedule-free wrappers in unknown-horizon regimes, both theoretically and empirically, and determine conditions where 1/(k+2) averaging is preferable or inferior to horizon-agnostic alternatives.
- Provide explicit derivations and practical implementations of SODA for complex geometries (Shampoo, multi-norm/doubly-stochastic), including computational overheads, memory costs, and accuracy of approximations used in large-scale training.
- Validate and characterize the acceleration regime suggested by the theory (co-scheduling bar α_k and λ_k) on modern architectures; determine stable accelerated schedules and when acceleration improves optimization without hurting generalization.
- Analyze the computational trade-offs of reconstructing z0 on-the-fly (e.g., reproducibility with fixed seeds, overhead in distributed training, interactions with parameter sharding and optimizer state partitioning).
- Investigate the interaction of anchoring and iterate averaging with architectural components (residual connections, normalization layers, attention blocks), and whether geometry-specific anchors (per-layer or per-parameter-group) yield further gains.
- Provide formal equivalence mappings (and failure cases) for optimizers beyond those discussed (e.g., AdamW, AdEMAMix beyond the Simplified/NAdam case), clarifying when and how they fit into the SODA framework.
- Characterize generalization impacts of replacing constant decoupled weight decay with the proposed 1/k schedule across tasks (vision, NLP, RL), datasets, and scales, including explicit ablations against tuned baselines.
Practical Applications
Immediate Applications
The following use cases can be deployed now with minimal changes to existing training pipelines. Each item states sectors, concrete workflows or tools, and the key assumptions/dependencies that affect feasibility.
- Sector: Software/ML infrastructure; Large-scale AI (LLMs, vision, speech)
- Application: Plug-and-play optimizer wrapper that removes weight-decay tuning
- What to do: Wrap existing base optimizers (Adam, NAdam, Lion, Muon, Scion) with the SODA wrapper; disable decoupled weight decay in the base optimizer; keep your existing learning-rate schedule; anchor updates to the model initialization and use the 1/(k+2) iterate-averaging schedule
- Tools/products/workflows: Add a SODA wrapper module in PyTorch/TF/JAX optimizers; integrate as a Trainer/Lightning callback; default setting in Hugging Face training scripts
- Assumptions/dependencies: Most effective for single-epoch or compute-optimal regimes; base optimizer must expose a “no-weight-decay” update; learning-rate scheduling remains necessary; theoretical guarantees are convex but empirical results support deep learning use
- Sector: MLOps and AutoML platforms
- Application: Shrink hyperparameter search by fixing weight decay to the parameter-free 1/k schedule
- What to do: Remove “weight_decay” from search spaces; reallocate tuning budget to learning-rate and momentum; log the effective decay implied by the wrapper for traceability
- Tools/products/workflows: AutoML pipelines (Ray Tune, Optuna, Vizier), HPO dashboards that report energy savings by dropping an axis of search
- Assumptions/dependencies: Horizon-agnostic in practice (1/(k+2) is online); ensure base optimizers’ weight decay is disabled to avoid double regularization
- Sector: Sustainability and cost management (industry-wide)
- Application: Reduce training runs (and energy use) by eliminating weight-decay sweeps
- What to do: Adopt SODA as a default optimizer wrapper in training templates; quantify avoided HPO runs in carbon-accounting reports
- Tools/products/workflows: Job schedulers that tag “SODA-enabled” runs; carbon dashboards showing reductions from fewer tuning trials
- Assumptions/dependencies: Savings scale with prior reliance on weight-decay tuning; gains are larger for large models and long horizons
- Sector: Distributed training (cloud and on-prem clusters)
- Application: Standardize optimizer behavior across nodes with fewer per-node hyperparameters
- What to do: Apply SODA on each worker; reconstruct initialization on the fly from a shared seed; keep DDP/ZeRO settings unchanged
- Tools/products/workflows: PyTorch DDP/FSdp, DeepSpeed, parameter-efficient fine-tuning frameworks, DiLoCo/GPA-inspired training recipes with modernized SODA
- Assumptions/dependencies: Mixed-precision and gradient-accumulation must be consistent with base updates; ensure no duplicated weight decay
- Sector: Healthcare AI (medical imaging, EHR models)
- Application: Stable, tuning-light training for resource-constrained labs and hospitals
- What to do: Use SODA to avoid costly grid searches for weight decay; keep LR schedules and data-privacy compliance unchanged
- Tools/products/workflows: Hospital training pipelines (MONAI, TorchIO) with SODA as the optimizer wrapper
- Assumptions/dependencies: Many clinical tasks are multi-epoch; SODA’s parameter-free decay is primarily validated for single-epoch; consider reintroducing a regularization knob for long multi-epoch regimes
- Sector: Robotics and embedded/edge ML
- Application: On-device or time-constrained fine-tuning without delicate regularization tuning
- What to do: Use SODA with Lion/Muon for sign-based or spectral geometries; leverage the 1/k schedule to stabilize small-batch or online updates
- Tools/products/workflows: TFLite/ONNX-runtime training extensions, ROS-based training scripts with a SODA optimizer wrapper
- Assumptions/dependencies: Memory constraints require reconstructing initialization from a seed rather than storing a full copy; horizon may be unknown (1/(k+2) is still valid)
- Sector: Finance and regulated industries
- Application: More reproducible, auditable training by removing a sensitive hyperparameter
- What to do: Standardize SODA as default; document the parameter-free weight-decay schedule in model cards and changelogs
- Tools/products/workflows: MLOps compliance modules that record the deterministic 1/(k+2) averaging rule
- Assumptions/dependencies: In-house validation must confirm no degradation on multi-epoch or nonstationary datasets; maintain LR/momentum governance
- Sector: Academia and open-source
- Application: Reproducible baselines and cleaner ablations without weight-decay tuning
- What to do: Publish results with SODA-wrapped optimizers (Adam, Lion, Muon, Scion) and report base hyperparameters only; use SODA to teach dual averaging/optimism and geometry-aware updates in courses
- Tools/products/workflows: Reference implementations, course notebooks, benchmark leaderboards that compare base optimizers with and without SODA
- Assumptions/dependencies: Theoretical results are convex; still empirically strong for deep nets; spectral or ℓ∞ geometries should match parameter types (e.g., spectral maps for matrices)
Long-Term Applications
These opportunities require further research, scaling studies, or engineering effort before wide deployment.
- Sector: Software/ML infrastructure; Large-scale AI
- Application: Accelerated SODA schedules that co-schedule optimism and iterate averaging for faster convergence
- What could emerge: “SODA-ACC” plugins implementing the accelerated parameterization (increasing weights) suggested by the theory
- Assumptions/dependencies: Stability in nonconvex deep nets must be established; careful coupling of λk and αk required; extensive empirical validation on LLMs and vision transformers
- Sector: Multi-epoch training across domains (healthcare, vision, NLP)
- Application: SODA variants with an explicit regularization knob for multi-epoch overfitting control
- What could emerge: “SODA+Reg” with a tunable regularization strength layered over the 1/k averaging; adaptive schemes blending optimization benefits with generalization
- Assumptions/dependencies: Requires exploring generalization–optimization trade-offs; may reintroduce a small number of hyperparameters
- Sector: Optimizer design and research tooling (academia and industry R&D)
- Application: Auto-geometry selection inside SODA (ℓ∞, spectral, multi-norm) per layer or parameter type
- What could emerge: “GeoSODA” that detects matrices vs. vectors and applies spectral vs. elementwise geometry; meta-learned geometry choices
- Assumptions/dependencies: Extra compute for SVDs or approximations; stability of mixed geometries; need for tooling to define mirror maps with tractable Fenchel conjugates
- Sector: Federated and distributed learning (cross-industry)
- Application: Tuning-light clients with predictable optimizer behavior in heterogeneous settings
- What could emerge: Federated training kits that use SODA wrappers client-side to reduce client-level HPO and variability
- Assumptions/dependencies: Many federated tasks are multi-epoch and nonstationary; communication–computation trade-offs and generalization require study
- Sector: Hardware and compilers (GPU/TPU vendors, MLIR/XLA/TorchInductor)
- Application: Kernel-level implementation of SODA’s centering and 1/k averaging for efficiency
- What could emerge: Fused kernels or graph passes that implement base updates plus SODA’s averaging; low-overhead reconstruction of z0 from a seed
- Assumptions/dependencies: Vendor support and careful integration with mixed precision, gradient scaling, and sharded optimizers
- Sector: Policy, governance, and sustainability
- Application: Standardize parameter-free weight-decay schedules to reduce compute waste and increase reproducibility
- What could emerge: Best-practice guidelines recommending “use a SODA-style 1/k schedule unless multi-epoch generalization requires otherwise”; carbon accounting standards acknowledging reduced HPO
- Assumptions/dependencies: Community consensus and further evidence on broad task coverage; clear caveats for multi-epoch regimes
- Sector: Education and workforce development
- Application: Unified teaching modules on modern optimizers via optimistic dual averaging and geometry
- What could emerge: Curriculum materials and interactive labs showing how Adam, Lion, NAdam, Muon, Scion arise as SODA instances; diagnostic tools to visualize primal vs. dual processing
- Assumptions/dependencies: Requires accessible implementations (PyTorch/TF/JAX) and datasets illustrating geometry choices
- Sector: Safety and reproducibility in high-stakes AI (healthcare, finance, public sector)
- Application: Reduced configuration surface for safer, more reproducible training
- What could emerge: Standard operating procedures adopting SODA to minimize undocumented knobs; model cards that list only base optimizer hyperparameters and the fixed SODA schedule
- Assumptions/dependencies: Audits will still require verifying remaining hyperparameters (LR/momentum); nonconvex theory development would strengthen adoption
- Sector: Edge/on-device learning ecosystems
- Application: SODA-enabled on-device training/fine-tuning with stable defaults
- What could emerge: Extensions in CoreML/NNAPI/TFLite training APIs that expose SODA as the default wrapper
- Assumptions/dependencies: Broader maturity of on-device training workflows; careful handling of initialization anchoring and limited memory
- Sector: Benchmarking and evaluation science
- Application: Cleaner cross-optimizer comparisons by removing weight-decay tuning as a confounder
- What could emerge: Benchmarks that report “SODA-wrapped” and “base” results side-by-side; leaderboards scoring efficiency improvements from parameter-free regularization
- Assumptions/dependencies: Agreement on reference geometries per domain; standardized logging of effective iterate-averaging schedules
Notes on cross-cutting assumptions:
- The theory is convex; while empirical results are strong in deep learning, guarantees in nonconvex settings remain future work.
- The proposed 1/k schedule is primarily motivated for single-epoch or compute-optimal regimes; multi-epoch settings may need an additional hyperparameter for regularization strength.
- Base optimizers must support decoupled weight decay being disabled; the SODA wrapper assumes stepsize schedules remain in the base optimizer.
- Geometry choice matters: ℓ∞ for elementwise parameters (sign-based), spectral for matrices; multi-norm and other geometries are possible if their conjugates are tractable.
Glossary
- Acceleration (accelerated methods): Techniques that speed up convergence (often via momentum or extrapolation), achieving faster rates than basic gradient methods. Example: "Primal extrapolation, corresponding to in \ref{eq:SODA}, originates in accelerated gradient and proximal-gradient methods \citep{tseng2008accelerated,lan2012optimal}."
- Bregman divergence: A geometry-aware discrepancy induced by a convex function, defined as . Example: "For differentiable , we write the objective Bregman divergence as D_f(u,v) := f(u)-f(v)-\braket{\nabla f(v), u-v}."
- Clipping: A proximal-like operation that constrains an update into a norm ball, effectively projecting a step to maintain feasibility. Example: "By combining the above, we can handle a non-smooth via ``clipping.''"
- Co-coercivity: A property of -smooth convex functions linking gradient differences to Bregman divergence or squared gradient norms. Example: "For convex -smooth , co-coercivity gives"
- Conditional gradient (Frank–Wolfe) methods: Projection-free optimization methods that use a linear minimization oracle over the feasible set. Example: "This is the core operation in Frank-Wolfe (conditional gradient) methods \citep{frank1956algorithm,ken-fw,jaggi2013revisiting}, which are projection-free but typically require to be smooth."
- Decoupled weight decay: A regularization technique applying weight decay separately from the gradient step so that decay is not scaled by the learning rate. Example: "and is not multiplied by the stepsize schedule as otherwise standard in e.g., decoupled weight decay \citep{loshchilov2017decoupled},"
- Dual averaging: An optimization framework that accumulates (averages) gradients in the dual space and maps them back to the primal via a conjugate. Example: "The Dual Averaging framework \citep{nesterov2009primal} and its variants typically rely on the Fenchel conjugate to map gradient information back to the primal space."
- Dual norm: The norm on the dual space defined by the supremum of inner products over the unit primal norm ball. Example: "Let be a norm with dual norm , and let ."
- Fenchel conjugate: The convex conjugate of a function, defined by a supremum over linear functionals minus the original function. Example: "The Fenchel conjugate of a function is defined as:"
- Fenchel–Young inequality: A fundamental inequality relating a function and its conjugate, characterizing optimality and dual mappings. Example: "This identity is a direct consequence of the Fenchel-Young inequality \citep{bauschke2012fenchel}."
- Filtration: The increasing sequence of sigma-algebras capturing the information available up to each time step in a stochastic process. Example: "Let be the natural filtration."
- Follow-the-regularized-leader (FTRL): An online learning approach selecting decisions by minimizing accumulated linearized loss plus a regularizer. Example: "also known as optimistic follow-the-regularized-leader (FTRL) in online learning \citep{rakhlin2013online}."
- Indicator function (of a set): A function that is 0 on the set and outside, used to encode constraints in optimization. Example: "Let be the indicator function of a set (i.e., $0$ if and otherwise)."
- Linear minimization oracle (LMO): An oracle that returns the minimizer of a linear form over a feasible set; central to Frank–Wolfe. Example: "The is then the :"
- Mirror map: A geometry-defining regularizer whose conjugate gradient determines how dual information is mapped to the primal. Example: "and is a sequence of geometry defining regularizers (or mirror maps)."
- msign: The matrix sign operator from the SVD of a matrix, used to define spectral-direction updates. Example: "with , where is the singular value decomposition of "
- Nesterov momentum: An “optimistic” momentum scheme that evaluates gradients at an extrapolated point to improve convergence. Example: "The so-called Nesterov momentum corresponds to choosing the optimistic parameter as ."
- Online-to-batch conversion: A technique turning online regret bounds into expected optimization error bounds in the stochastic setting. Example: "Under bounded gradient we rely on the following online-to-batch conversion which holds for any primal extrapolation parameter ."
- Optimism (optimistic updates): The use of a predictive correction (e.g., current gradient) to form an “optimistic” dual variable for the next step. Example: "This is an optimistic version of the celebrated Dual Averaging scheme \citep{nesterov2005smooth}"
- Primal averaging: Averaging iterates to stabilize optimization and improve robustness/smoothness of the trajectory. Example: "how we average iterates (primal averaging / schedule-free)"
- Primal extrapolation: Forming an auxiliary point by extrapolating (convexly combining) current and candidate updates before gradient evaluation. Example: "by introducing a primal extrapolation sequence () from \citet{tseng2008accelerated,lan2012optimal,defazio2024road}:"
- Schedule-free: An approach or wrapper that avoids hand-tuned learning-rate schedules by leveraging iterate averaging. Example: "recipes such as the schedule-free wrapper \citep{defazio2024road} highlight that the assembly of these ingredients can be as important as the ingredients themselves."
- Sharp operator: The mapping that returns the maximizer of a linear function regularized by a squared norm; equivalent to a normalized gradient step. Example: "The is the sharp operator \citep{nesterov2012efficiency}:"
- Spectral norm ball: The set of matrices with spectral norm at most one; its LMO yields spectral-direction steps. Example: "For the spectral norm ball, "
- Subdifferential: The set of subgradients (or, for conjugates, maximizers) defining generalized gradients for nonsmooth functions. Example: "The subdifferential is equivalent to the set of maximizers of this conjugate operation:"
- Universal methods: Algorithms that automatically achieve optimal rates in both smooth and nonsmooth regimes without prior knowledge. Example: "to obtain universal methods, i.e., a single algorithm simultaneously attaining both the optimal smooth stochastic convex rate and the nonsmooth rate ."
Collections
Sign up for free to add this paper to one or more collections.