- The paper introduces jNO, a unified JAX-native software stack that consolidates neural operator and foundation model training workflows.
- The system employs a tracing-first symbolic DSL to integrate mesh-aware domain workflows, adaptive sampling, and unified FEM assembly.
- jNO enhances experimental flexibility and reproducibility via parameter-level control, multi-device scaling, and systematic transfer learning.
jNO: A Unified JAX Library for Neural Operator and Foundation Model Training
Motivation and Ecosystem Consolidation
jNO (jax Neural Operators) introduces an integrated JAX-native software stack for neural operator and foundation model workflows, directly addressing persistent fragmentation in scientific ML toolchains. Its tracing-first design enables seamless composition of domains, models, residuals, supervised losses, and diagnostics within a single symbolic language that compiles into a unified optimization pipeline. This approach significantly reduces code restructuring demands and eliminates disparate interfaces for operator learning, mesh-aware residual evaluation, and PDE-constrained training.
The library consolidates state-of-the-art PDE foundation models—including Poseidon, Walrus, PDEformer2, MPP, Morph, BCAT, and DPOT—into a single JAX-native backend, facilitating systematic comparison, transfer learning, fine-tuning, and reproducibility. As a result, parameter-level control and cross-model hybrid objectives are enabled throughout a compositional execution graph, yielding increased experimental flexibility relative to mono-framework alternatives.
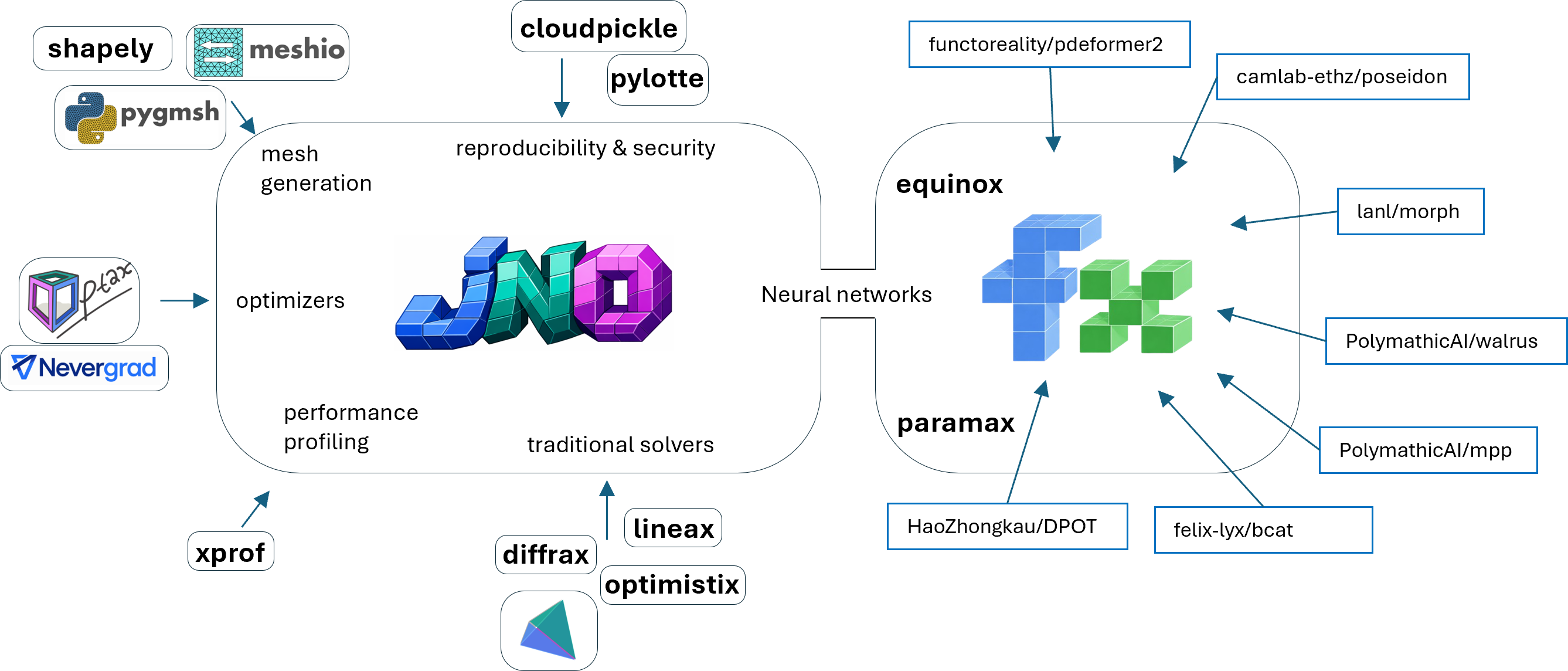
Figure 1: Overview of jNO's interdependencies and consolidated model ecosystem.
This consolidation is not limited to organizational aspects: it creates practical workflows for large-scale PDE surrogate modeling, ensemble approaches, and foundation model transfer across heterogeneous domains utilizing unified training controls and symbolic interface.
Tracing System and Symbolic Programming Model
At the core of jNO is a symbolic tracing system implemented as a domain-specific language (DSL), leveraging placeholder nodes to build arithmetic/differential expression trees rather than executing operations eagerly. Traced expressions are deferred until compilation, ensuring that model calls, differential operators, and loss terms uniformly participate in XLA-level optimization. Graph nodes encapsulate Variables, Literal/constants, ModelCall, Jacobian, and Hessian, enabling reuse and operation registry without accidental collisions and guaranteeing robustness.
jNO performs common sub-expression elimination and canonicalization before evaluation, reducing redundant computation and compilation overhead. The TraceEvaluator dispatches batch contexts, differentiating operator pathways via both autodiff and finite-difference mechanisms. The system also supports shape diagnostics and monitored expressions at runtime for explicit dependency tracing and debugging.
Mesh-Aware Domain Workflow and Adaptive Sampling
The domain class in jNO integrates mesh generation, geometry tagging, context sampling, and batch orchestration through a unified API, supporting mesh generation (PyGmsh/Gmsh), external mesh loading (meshio), and tagging for interior/boundary/subdomains. Mesh connectivity data, neighborhood, topology, nodal measures, and boundary indices are precomputed for efficient finite-difference and FEM workflows. Batched domains facilitate neural operator training across variable PDE parameterizations, enabling per-sample conditioning tensors for operator learning.
Adaptive point management hooks allow point sets to be updated dynamically during training, supporting advanced sampling strategies and adaptive residual error mitigation. The domain class thus forms the bridge: aligning meshing, parameterization, geometry tags, and boundary structures within the traced optimization pipeline.
Unified Finite Element Method Integration
jNO's finite element (FEM) interface builds on the same symbolic tracing model as residual/operator workflows. Mesh-based weak forms, variational PINNs, steady-state FEM systems, nonlinear residuals, and transient time-discrete systems can be composed within a unified DSL: mesh data, quadrature regions, boundary metadata, trial/test symbols, and PDE constraints are all managed on the symbolic graph level. Weak forms are grouped at assembly via FEAX and dispatched as JAX-compatible linear systems or residual operators, maintaining differentiability and compatibility with JAX-native solvers (Diffrax, Optimistix).
By keeping FEM assembly in the JAX ecosystem, the framework supports full pipeline differentiation, backpropagation through assembled operators, and solver-in-the-loop computations—enabling the integration of scientific modeling and physics-informed ML objectives without requiring a PETSc-style external backend.
Model Interface, Foundation Model Translation, and Training Controls
jNO exposes neural operator architectures—including FNO, GeoFNO, PCNO, UNet, CNO, Transformer, DeepONet, and PointNet—via external repositories (foundax) and treats all models as first-class traced graph operations when wrapped in jNO.nn.wrap. Translated foundation models from PyTorch can be leveraged as compositional modules, supporting transfer learning and hybrid adaptation layers.
Model-level controls (initialization, optimizer assignment, parameter masking, LoRA adaptation, dtype selection) are handled natively and attached to model objects, permitting mixed-precision training, low-rank adaptation, and parameter-specific optimization strategies—all within the traced symbolic execution graph.
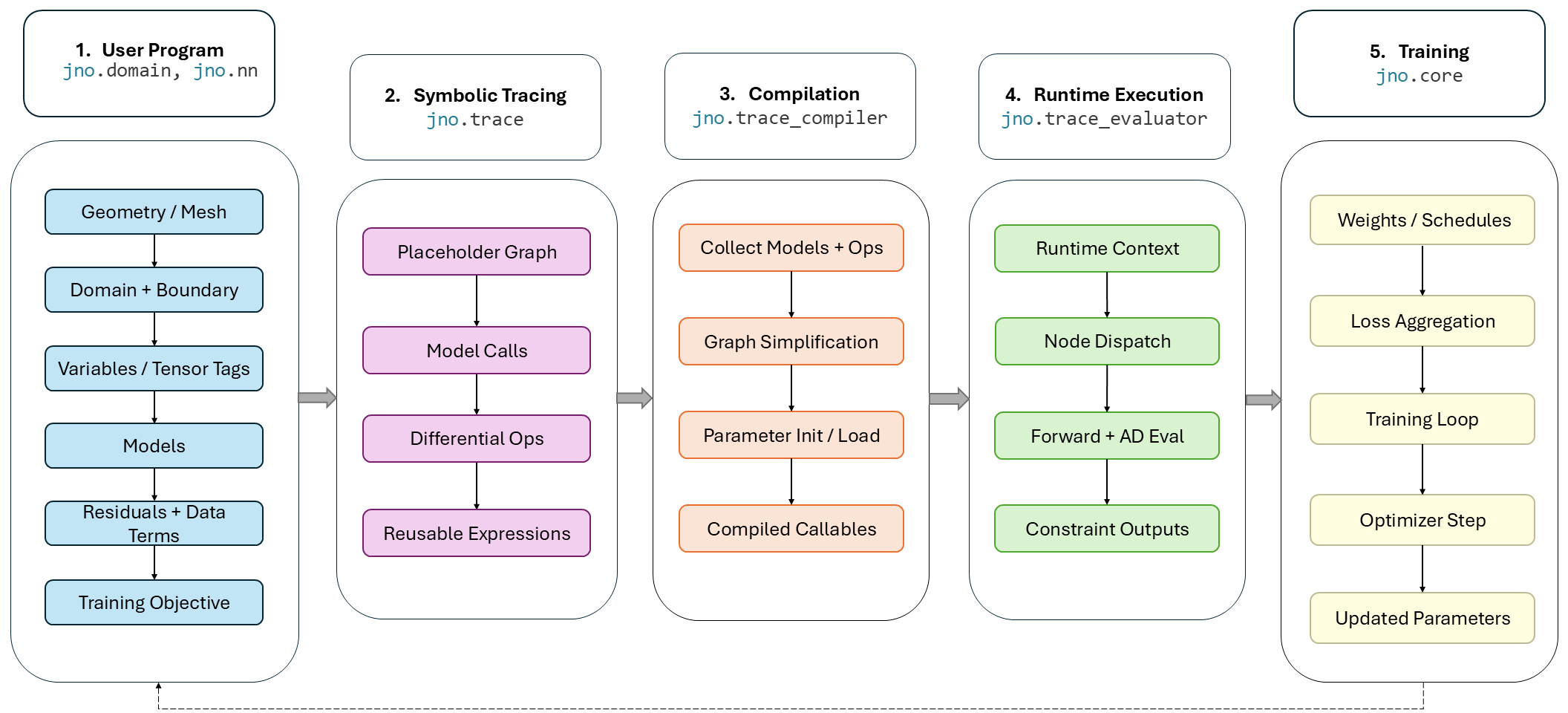
Figure 2: Main execution pipeline of jNO for model training, demonstrating unified symbolic tracing and optimization.
Boundary conditions are encoded on the forward pass with symbolic transformations; hard constraints (e.g., Dirichlet) are enforced directly via output envelopes prior to residual calculation. This approach ensures boundary-compliant solutions without manual post-processing and is fully differentiable within the traced graph.
Runtime Execution, Training, and Hyperparameter Tuning
The runtime in jNO/core manages multi-device execution, memory management, and low-overhead training loops, with all constraints compiled into a JIT-optimized XLA function. Device sharding, buffer donation, persistent XLA caching, throughput fusion, and resampling strategies are provided to maximize scalability and minimize memory footprint.
Hyperparameter tuning is natively integrated via ArchSpace, offering categorical, float, and integer search ranges for architecture and training parameters. Nevergrad is supported for gradient-free optimization over mixed-type spaces. The tuning interface is deeply integrated, enabling fully reproducible, systematic parameter sweeps across compositional models and hybrid objectives.
Experiment Persistence, Quality Control, and Availability
jNO features robust persistence for core solver states, domain objects, and compiled IREE models, with optional RSA-signed artifacts for verifiable exchange. Reproducibility is further enabled by automated tests, integration examples, and validation scripts. The test suite ensures reliability across tracing DSL, domain/geometry operations, derivatives, adaptive resampling, and multi-device training workflows.
The software is available on Linux, macOS, and Windows (via WSL2), requires Python >=3.11,<3.14, and is distributed via GitHub and PyPI under EPL-2.0 license.
Implications and Future Directions
jNO represents a methodological advance in ecosystem consolidation for scientific ML, enabling unified workflows for neural operator learning, mesh-aware residuals, and physics-informed foundation model training in a JAX-centric environment. The practical implications include accelerated research iteration, extended model comparison and transfer capacities, and reduction in reproducibility barriers. The framework provides measurable speedups and improved numerical stability through explicit XLA optimizations, supporting high-throughput operator learning and PDE surrogate modeling.
From a theoretical perspective, the traced symbolic paradigm facilitates hybrid objective construction, ensemble modeling, and progressive transfer learning across diverse PDE domains. By integrating mesh-based FEM assembly and differentiable weak forms, jNO supports a broader class of scientific modeling tasks with compositional regularization and adaptivity.
Potential future directions include extension to stochastic PDEs, generalized multimodal foundation models, advanced resampling/point management schemes, and tighter integration with distributed accelerator backends for extreme-scale deployments.
Conclusion
jNO addresses persistent fragmentation in neural operator and foundation model workflows by providing a tracing-first, JAX-native framework that supports unified composition of geometry, mesh, model, residual, and objective functions. Its symbolic language and traced execution pipeline enable compositional workflows, parameter-level training control, and seamless integration of translated foundation models, while delivering robust performance and reproducibility. jNO provides a practical and extensible platform for both operator-learning and physics-informed ML in scientific domains, with broad applicability and clear potential for advancing future AI-driven PDE modeling and simulation (2605.10159).