EFGCL: Learning Dynamic Motion through Spotting-Inspired External Force Guided Curriculum Learning
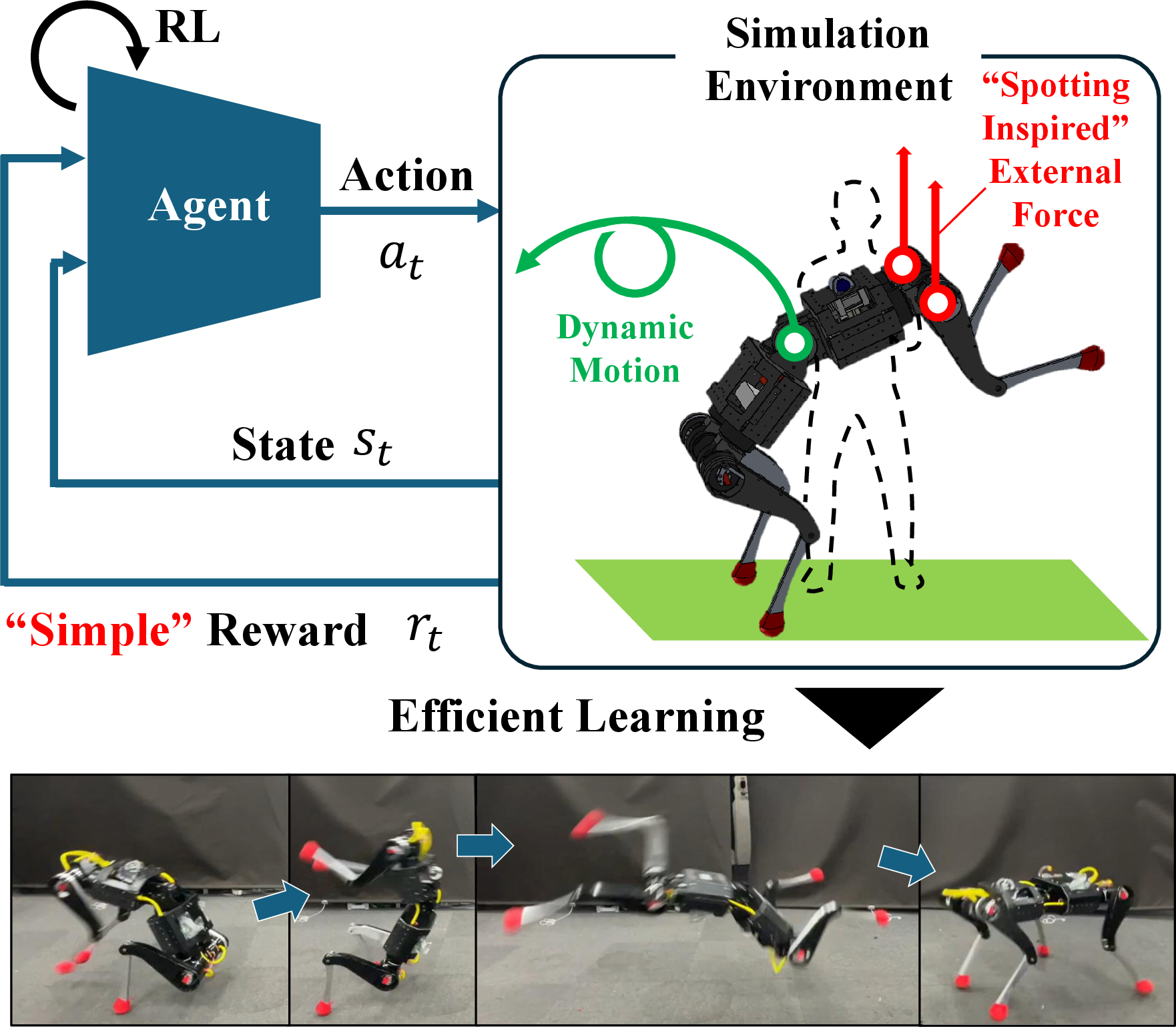
Abstract: Learning dynamic whole-body motions for legged robots through reinforcement learning (RL) remains challenging due to the high risk of failure, which makes efficient exploration difficult and often leads to unstable learning. In this paper, we propose External Force Guided Curriculum Learning (EFGCL), a guided RL approach based on the principle of physical guidance, in which external assistive forces are introduced during training. Inspired by spotting in artistic gymnastics, EFGCL enables agents to physically experience successful motion executions without relying on task-specific reward shaping or reference trajectories. Experiments on a quadrupedal robot performing Jump, Backflip, and Lateral-Flip tasks demonstrate that EFGCL accelerates learning of the Jump task by approximately a factor of two and enables the acquisition of complex whole body motions that conventional RL methods fail to learn. We further show that the learned policies can be deployed on real robot, reproducing motions consistent with those observed in simulation. These results indicate that physically guided exploration, which allows agents to experience success early in training, is an effective and general strategy for improving learning efficiency in dynamic whole-body motion tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to teach a four-legged robot to do fast, athletic moves like jumping high, doing a backflip, and doing a sideways flip. The key idea is to give the robot a gentle “helping hand” during training, like a coach spotting a gymnast, and then slowly take that help away as the robot learns to do the moves on its own.
What questions did the researchers ask?
They focused on three simple questions:
- Can we make learning risky, dynamic moves safer and faster by physically helping the robot during training?
- Can this approach work without special hand-crafted rewards or perfect example motions to copy?
- Will what the robot learns in simulation still work on a real robot?
How did they do it?
Here’s the approach in everyday terms:
- The big idea: a coach’s “spot.”
- In gymnastics, a coach may lightly support an athlete so they can safely feel what the right motion is like. The robot gets the same kind of help: small external forces (like an upward push) applied at the right time to make success more likely at the start.
- A step-by-step learning “curriculum.”
- At first, the robot gets strong help so it can experience success and collect good examples.
- As it gets better, the help is gradually reduced.
- The robot only moves to “less help” once it’s succeeding often enough, so progress is steady and not discouraging.
- Simple, fair rewards.
- All three tasks use the same reward setup so there’s no hidden “cheats” for any task.
- The only difference is the goal: jump height for Jump, and rotation angle for Backflip and Lateral-Flip.
- There are no special “hint” rewards or reference motions to copy.
- Teacher–Student training for real-world use.
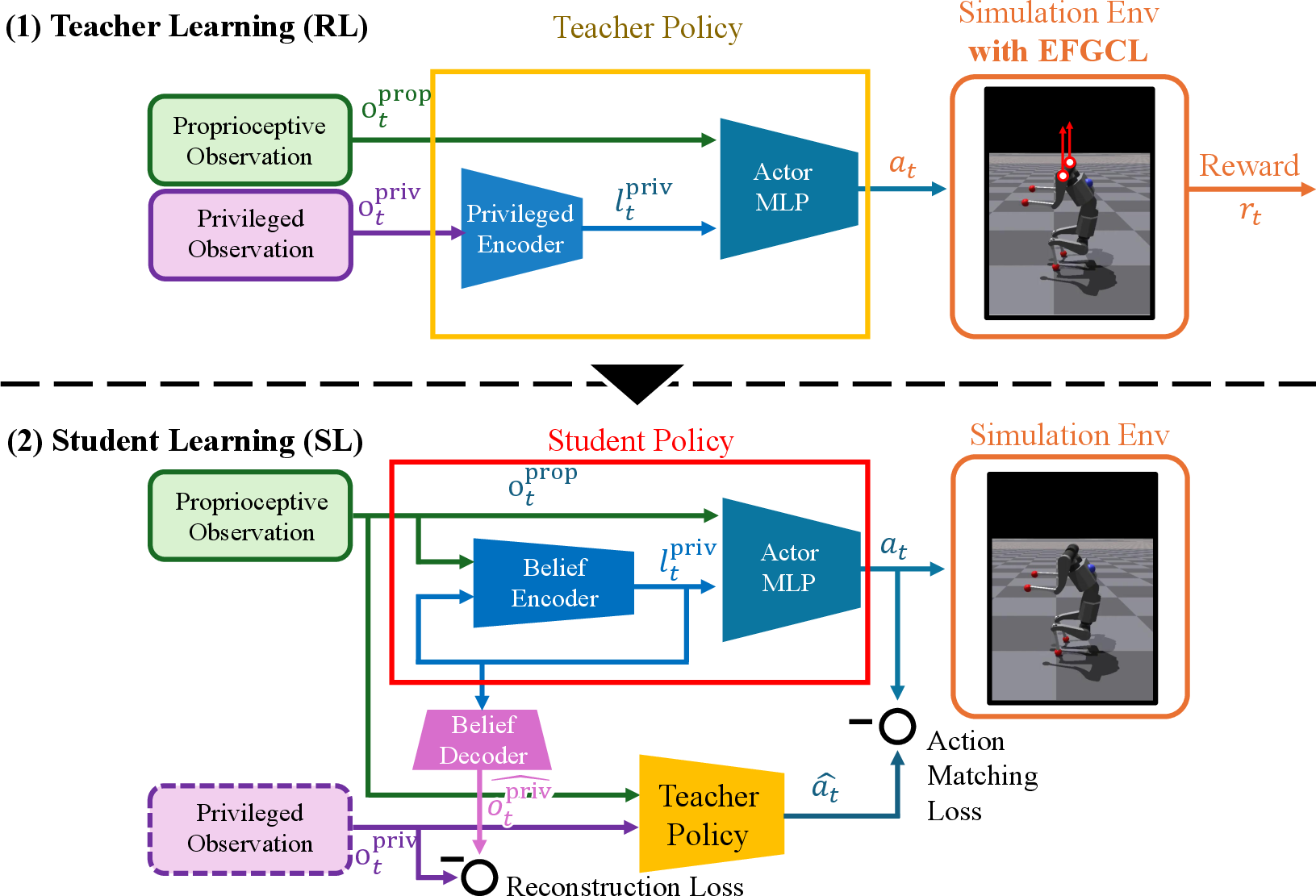
- First, a “Teacher” policy learns in simulation with full information (including some data a real robot wouldn’t see, like exact heights and angles).
- Then, a “Student” policy learns to imitate the Teacher using only the sensors a real robot has (like an IMU and joint encoders).
- This makes it easier to transfer the skill to the real robot.
- A tiny “timer” hint.
- Because the helping force turns on and off at certain times, the robot gets a simple time-like signal so it knows when assistance is happening. Think of it like a countdown meter that helps it synchronize its moves.
What did they find?
In tests on a simulated quadruped robot, and then on a real one, they found:
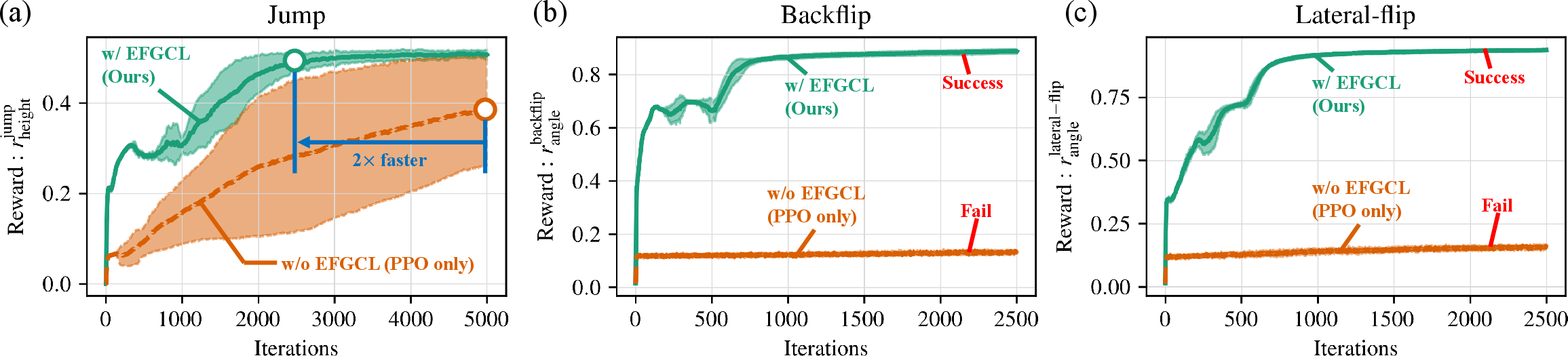
- Faster learning for Jump:
- With the helping forces (their method called EFGCL), the robot learned to jump about twice as fast as without help.
- Hard tricks became learnable:
- Backflip and Lateral-Flip did not learn reliably with standard methods.
- With EFGCL, the robot learned both of these complex, high-energy moves.
- Real-world transfer:
- The policies trained with EFGCL in simulation were used on a real robot.
- The real robot performed the moves in a way that matched the simulation.
Why that’s important:
- Early successes give the learning algorithm good “experience” to learn from, which stabilizes and speeds up training.
- This reduces crashes and flailing during exploration, which are common when trying risky moves.
Why does this matter?
- Safer, faster training: Physically guiding the robot early on makes it possible to tackle advanced, dynamic motions that are usually too hard or too dangerous to learn from scratch.
- Less expert tuning: It avoids expensive reward engineering and doesn’t need perfect example motions, making it more general and easier to apply to new tasks.
- Real-world readiness: Because the learned skills transfer to a real robot, this approach could help future robots learn athletic, emergency, or high-power tasks more quickly and reliably.
In short, giving robots a “spot” like a coach does for gymnasts helps them learn tough moves faster and more safely—and it works in the real world, not just in simulation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper opens several concrete avenues for further work. Below is a focused list of what remains uncertain, missing, or unexplored:
- Task-agnostic assistance design: External assistive forces are heuristically hand-crafted per task (points of application, magnitudes, timing). A general method to design or learn these forces (e.g., optimization, differentiable co-design, model-based synthesis) is not provided.
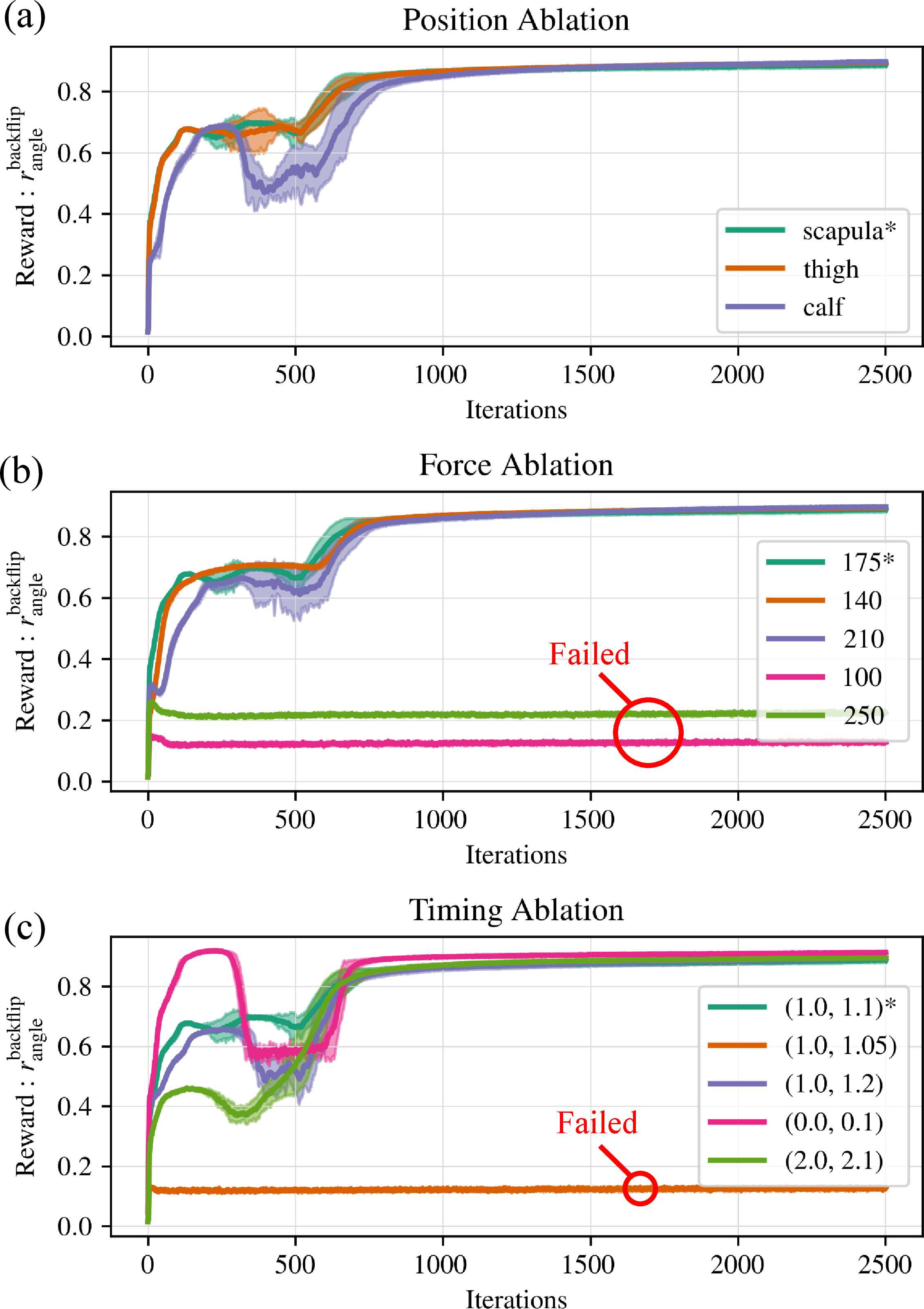
- Sensitivity to assistance parameters: The robustness of learning outcomes to variations in force magnitude, direction, timing windows, and contact points is not systematically quantified (e.g., tolerance bounds, safe ranges, and failure modes when assistance is too weak/strong or mis-timed).
- Automatic “coach” policy: The possibility of learning an assistance policy (a spotting controller) jointly with the robot’s policy (e.g., bi-level RL, population-based training, or meta-RL) is not explored.
- Curriculum schedule tuning: The success-rate threshold and decay step (ζ, ε) are fixed and task-agnostic; guidelines for selecting them, their effect on stability and sample efficiency, and adaptive/feedback-based schedules (e.g., PID-style, uncertainty-aware) are not analyzed.
- Stage transition safety and stability: There is no analysis of failure risks when reducing assistance (e.g., abrupt performance cliffs between adjacent MDPs) or mechanisms that detect and prevent premature decay that destabilizes training.
- Theoretical guarantees: The work lacks formal analysis of convergence, bias, or suboptimality induced by assistance-driven exploration (e.g., whether assisting can steer learning into local optima or exclude viable, more efficient strategies).
- Time-encoding reliance: The introduced time encoding is tied to assistance activation; its necessity, alternatives (e.g., phase variables, event-based encodings), and brittleness to timing perturbations are not ablated. It is unclear how well policies generalize to variable-duration motions or different command profiles without re-tuning.
- Command generalization: The policy accepts target height/angle commands, but interpolation/extrapolation performance across command ranges (and robustness to out-of-distribution commands) is not reported.
- Closed-loop responsiveness: It is unclear how reactive the learned policies are (versus time-locked); recovery from perturbations or timing slips during dynamic motions is not evaluated.
- Sim-to-real robustness: The extent of domain randomization, modeling error handling, and robustness to real-world variability (surface friction, compliance, IMU bias, latency) is not specified; quantitative sim-to-real transfer metrics are missing.
- Real-world assistance realization: Although assistance is applied in simulation, the feasibility, safety, and design of physical assistance mechanisms (harnesses, gantries, cable robots) for on-hardware training are not addressed.
- Safety under exploration: Strategies to prevent high-impact failures during either sim or real training (e.g., safety critics, constraint RL, shielded policies) are not integrated or evaluated.
- Energy and actuation limits: The impact of EFGCL on actuation effort, peak torques/velocities, thermal limits, and energy consumption is not assessed; no trade-off analysis between learning success and control effort is provided.
- Generalization across morphologies: Applicability beyond the specific quadruped (e.g., different masses/inertias, actuators, or to bipeds/humanoids) and how assistance scales with morphology is not studied.
- Task diversity: Validation is limited to three acrobatic tasks; extension to other dynamic skills (vaults, parkour, compliant landings) or contact-rich tasks (pushing, manipulation) remains untested.
- Assistance realism: Assistance is applied as pure forces at specific links; constraints that ensure physically realizable assistance (e.g., moment/force limits, no-penetration, actuator bandwidth of external device) are not modeled, raising questions about real-world implementability.
- Alternative assistance modalities: Torque injections, virtual fixtures, impedance shaping, or state resets are not compared against external force assistance; the relative benefits/risks across modalities are unknown.
- Baseline breadth: Comparisons are primarily against “no EFGCL.” Stronger baselines (reward shaping curricula, imitation from optimized trajectories, human demos, residual RL, guided exploration methods) are missing, limiting claims of superiority.
- Sample efficiency accounting: Absolute sample counts, wall-clock time, and compute budgets per task/stage are not detailed, making it hard to compare efficiency to prior work or across curricula.
- Policy distillation details: The Teacher–Student training specifies action-matching and privileged-state reconstruction, but key choices (loss weights, architectures, dataset sizes) and their effects on performance/robustness are not ablated.
- Partial observability handling: Recurrent policies, history stacks, or belief-state estimation (for dynamic, contact-rich flips) are not investigated as alternatives or complements to privileged-teacher distillation.
- Failure analysis: There is no taxonomy of observed failure modes (e.g., over-rotation, mis-timed takeoff, unsafe landing) or diagnostics linking them to assistance settings, aiding targeted improvements.
- Curriculum termination criteria: Beyond hitting a success-rate threshold, stopping conditions and safeguards against overfitting to assisted trajectories (e.g., validation success without assistance) are not formalized.
- Interaction with sparse rewards: While sparse rewards are kept, the paper does not quantify how EFGCL changes return distributions, value bootstrap quality, or advantage signal-to-noise, nor does it compare to alternative value-bootstrapping strategies (e.g., hindsight returns).
- Long-horizon composition: How EFGCL scales to multi-skill sequences (e.g., chained acrobatics) or libraries of reusable skills with shared curricula and assistance is open.
- Adaptivity to task geometry: Assistance timing is fixed (e.g., 1.0–1.1 s) across tasks; aligning assistance with learned state events (e.g., peak compression, toe-off detection) may improve robustness but is not explored.
- Uncertainty-aware assistance: The approach does not use epistemic/aleatoric uncertainty to modulate assistance; whether uncertainty-driven assistance leads to safer and faster learning is unknown.
- Hardware wear and longevity: The effect of repeated dynamic motions learned via EFGCL on hardware fatigue and maintenance is not discussed; strategies to minimize wear while maintaining task success are lacking.
- Reproducibility of reward terms: The reward structure references common components, but exact functional forms/constants (e.g., r_common, λ_ω) are not fully specified in the main text; complete, unambiguous definitions and code are needed for replication.
- Ethical and operational constraints: Practical guidelines for safely deploying dynamic acrobatics on real robots (operator procedures, fail-safes, environment preparation) are not included, limiting real-world adoption.
These points can guide targeted experiments (e.g., parameter sweeps, ablations, new baselines), method development (e.g., learned assistance controllers, adaptive curricula), and theory (e.g., bias/convergence analyses) to strengthen and generalize the proposed EFGCL framework.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations around External Force Guided Curriculum Learning (EFGCL)—a “physical guidance” approach that applies external assistive forces during training and gradually removes them (spotting-inspired curriculum) to learn dynamic, high-risk motions with sparse rewards.
Immediate Applications
These applications can be piloted or deployed now with existing simulators, RL frameworks, and standard lab hardware.
- Train dynamic locomotion skills for legged robots (e.g., robust jumping over gaps/curbs) — Sector: Robotics (field robotics, logistics) — Tools/workflows: Integrate EFGCL into Isaac Gym/Mujoco training; design assist-force patterns (points, vectors, timing); PPO + success-rate-based scheduler; teacher–student pipeline for sim-to-real; use overhead tether/gantry for real-world spotting during early trials — Assumptions/dependencies: Access to accurate simulation, force-application rig or harness, safe workspace; assist-force pattern heuristics tuned per task/robot
- Safe, rapid R&D of “acrobatics-like” motions (backflips/lateral flips) for demo/entertainment robots — Sector: Entertainment/Media, Events — Tools/workflows: EFGCL training pipelines to produce show-ready motion libraries; show control integration; rigging for rehearsals; safety interlocks — Assumptions/dependencies: Liability/safety procedures; durable actuators; performance repeatability
- Faster policy training for agile mobility in warehouses and factories (e.g., quick step-ups, obstacle traversal) — Sector: Manufacturing/Logistics — Tools/workflows: EFGCL-assisted training for high-clearance maneuvers; domain randomization; deployment on quadrupeds used for inspection and inventory — Assumptions/dependencies: ROI depends on facility layout and safety approvals; robot torque/thermal limits
- Academic benchmarking for dynamic RL with sparse rewards (reduce reward-shaping bias) — Sector: Academia/Research — Tools/workflows: Open-source EFGCL “assistive curriculum” modules (success-rate scheduler, time-encoding, P–F–T assist patterns); reproducible tasks (jump/backflip/lateral-flip); ablations on assist magnitude/decay — Assumptions/dependencies: Community adoption and standardization; consistent simulators/sensors
- Laboratory safety workflows for learning high-risk skills — Sector: Research Infrastructure, Safety Engineering — Tools/workflows: “Spotting” rigs (gantry/tether/boom) with force control; staged curricula with thresholds (ζ) and decay step (ε); automated halt on failure spikes; data logging for near-miss analysis — Assumptions/dependencies: Force-feedback hardware; compliance with lab safety standards
- Productization of an EFGCL training add-on for RL toolchains — Sector: Software/AI Tools — Tools/workflows: Plugins for PPO-based libraries (e.g., Stable Baselines3/RSL-RL) with success-rate-driven assistance decay; time-encoding module; privileged-observation teacher scaffolding — Assumptions/dependencies: Maintenance across simulator backends; licensing for commercial use
- Sim-to-real pipelines with privileged teacher/student policies — Sector: Robotics (Startups, OEMs) — Tools/workflows: Teacher trains with privileged sensors + EFGCL; student distills to onboard sensing; deployment on mid-scale quadrupeds (e.g., 15–25 kg); routine calibration + domain randomization — Assumptions/dependencies: Sensor quality, actuator bandwidth; fidelity gap management; structured curricula
- Rapid skill library generation for legged robot SDKs — Sector: Platform Robotics — Tools/workflows: Batch-train parameterized jump/flip primitives under EFGCL; expose as API commands with target height/angle inputs; validation suite to ensure safe envelopes — Assumptions/dependencies: Envelope definition to prevent damage; versioned training datasets
- Development of assist-force pattern catalogs and design guidelines — Sector: Engineering Services — Tools/workflows: Templates for P (application points), F (vectors/magnitudes), T (timing) across robot morphologies; calculators based on projectile/rigid-body approximations; empirical ranges for safe assistance — Assumptions/dependencies: Task- and hardware-specific tuning; need for generalization to new platforms
- Institutional guidance and lab policy for dynamic robot training — Sector: Policy/Compliance (Institutional) — Tools/workflows: SOPs for staged assistance removal; maximum allowable external forces; criteria for transition to unassisted trials; incident-reporting frameworks — Assumptions/dependencies: Institutional safety committee buy-in; training for operators
Long-Term Applications
These require further research, scaling, hardware advances, and/or regulatory development before broad deployment.
- Agile SAR (search-and-rescue) robots traversing rubble with leaps and dynamic body maneuvers — Sector: Public Safety/Defense — Tools/workflows: EFGCL-trained policies for gap-jumping, dynamic roll/pitch maneuvers; high-power actuators; robust perception for foothold selection — Assumptions/dependencies: Ruggedized hardware; robust perception–control integration; regulatory approval for field trials
- Dynamic locomotion for humanoids (parkour-like behaviors) — Sector: Robotics (Humanoids), Entertainment, Logistics — Tools/workflows: Extend EFGCL to multi-contact, whole-body torque control; learning assistive fields for arms/torso; dedicated safety cages and counterweight rigs — Assumptions/dependencies: Greater actuator torque/precision; more complex assist pattern design; fall protection systems
- High-energy dynamic manipulation (throwing, batting, hammering) with robot arms — Sector: Manufacturing, Sports Robotics, Construction — Tools/workflows: EFGCL-like assistance via external torques/cable-driven end-effectors; sparse task rewards (e.g., release speed/impact metrics); curriculum over assistance decay — Assumptions/dependencies: Safe tool handling; end-effector rigs; precise release timing sensing
- Aerial robotics acrobatics trained with controlled flow fields — Sector: Drones/UAVs — Tools/workflows: Wind-tunnel or fan-array “assistance fields” to shape exploration for flips/rolls; aero-sim integration; decay to free-flight policies — Assumptions/dependencies: Wind tunnel access; accurate aerodynamics modeling; flight safety protocols
- Learning exoskeleton/prosthesis controllers with therapist-like physical guidance — Sector: Healthcare/Rehabilitation — Tools/workflows: Patient-in-the-loop RL where external robotic support applies assist forces; curriculum-based reduction as capability improves; safety-verified sparse rewards — Assumptions/dependencies: Clinical trials, ethics approvals; patient safety frameworks; explainable controllers
- “Spotter robots” that help train other robots (multi-robot training ecosystems) — Sector: Robotics Platforms/Services — Tools/workflows: Secondary robot applies controlled forces to a trainee robot during early curriculum stages; closed-loop assistance scheduling; co-training protocols — Assumptions/dependencies: Inter-robot coordination; safety guarantees; standardized APIs for force application
- Automated synthesis of assistive-force curricula (learn the P–F–T pattern) — Sector: AI/Autonomy Software — Tools/workflows: Meta-learning or bilevel optimization to discover optimal assistance fields; co-optimization of rewards and MDP modifications under safety constraints — Assumptions/dependencies: Significant compute; reliable estimators for “success density”; generalization across tasks/robots
- Standards for dynamic robot training and public deployment — Sector: Policy/Standards — Tools/workflows: National/international guidelines on maximum training forces, deceleration profiles, allowed curricula; certification paths for dynamic behaviors in public spaces — Assumptions/dependencies: Industry consensus; regulatory bodies’ engagement; incident data for risk models
- Education kits for “physical guidance in RL” — Sector: Education/EdTech — Tools/workflows: Low-cost robots with magnetic/tethered assistance rigs; curriculum modules illustrating sparse rewards vs. MDP modification; sandboxed simulators — Assumptions/dependencies: Safety with student operators; robust, affordable hardware
- Cost-optimized training pipelines and analytics for robotics companies — Sector: Finance/Operations in Robotics — Tools/workflows: EFGCL-driven KPIs (time-to-first-success, success-density curves) for budgeting and throughput planning; automated risk-cost trade-off dashboards — Assumptions/dependencies: Data infrastructure; alignment of engineering and finance metrics
- Cross-domain “physical guidance” for general RL (beyond robotics) — Sector: Software/AI Research — Tools/workflows: Formalizing MDP modifications as learnable curricula in other domains (e.g., game AI with environment-side assistance); frameworks for success-rate thresholds and assistance decay — Assumptions/dependencies: Task-specific analogs to “assist forces”; measurable success criteria; transferability studies
Notes on feasibility across applications:
- Success hinges on the ability to apply, measure, and control external forces in both simulation and hardware.
- Assist-force design is currently heuristic; automated design and validation will improve scalability.
- Teacher–student architectures help sim-to-real transfer but depend on sensor fidelity and robust domain randomization.
- Safety, liability, and regulatory frameworks are critical for high-energy behaviors in public or human-adjacent settings.
Glossary
- Action space: The set of all actions available to an agent or policy at a given state. "This update control is particularly effective for legged robots with high-dimensional action spaces and unstable dynamics, as it prevents training collapse caused by abrupt policy changes."
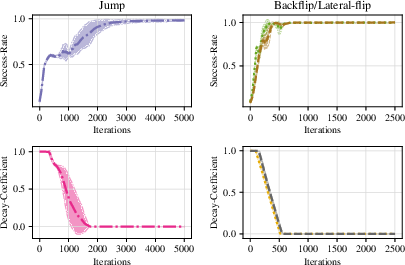
- Adaptive curriculum: A training schedule that adjusts task difficulty based on performance metrics to ensure stable progression. "EFGCL adopts a success-rate-based adaptive curriculum to prevent excessive difficulty changes caused by curriculum updates."
- Clipped surrogate objective function: A modified optimization objective in PPO that clips policy updates to stabilize training. "PPO constrains the magnitude of policy updates by optimizing a clipped surrogate objective function based on the likelihood ratio between the current and previous policies,"
- Curriculum learning: A training strategy that starts with easier conditions and gradually increases difficulty to improve learning stability. "Curriculum learning has been widely adopted as a representative approach to address the aforementioned issue."
- Discount factor: A scalar that determines how future rewards are weighted relative to immediate rewards in RL. "where is the discount factor."
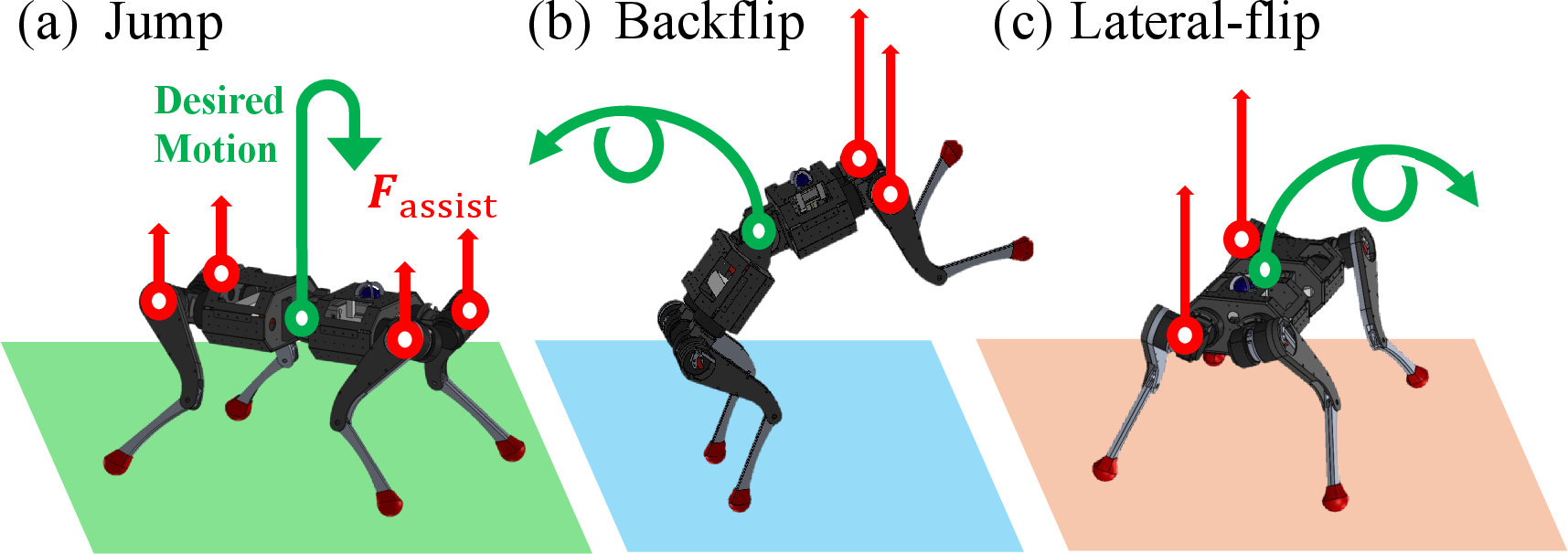
- External assistive forces: Physically applied forces that help the agent execute tasks successfully during training. "By applying external assistive forces in the early stages of learning, the agent experiences motion sequences with a higher probability of success."
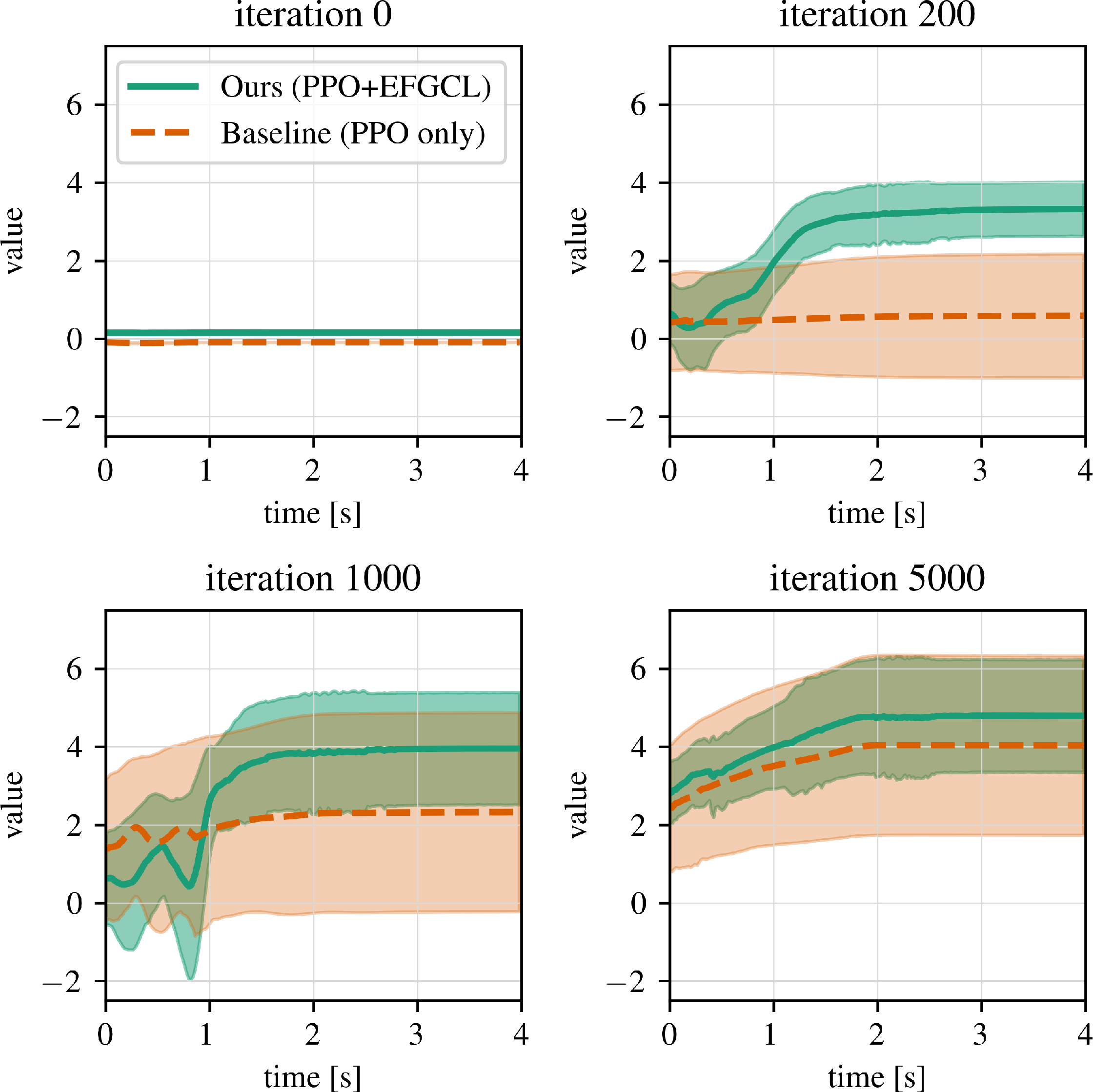
- External Force Guided Curriculum Learning (EFGCL): A reinforcement learning framework that uses physical guidance via external forces, decaying them over a curriculum to learn dynamic motions. "we propose External Force Guided Curriculum Learning (EFGCL), which gradually decays external assistive forces and demonstrate that physical guidance significantly improves exploration efficiency."
- Generalized Advantage Estimation (GAE): A technique to compute the advantage function as a weighted sum of TD errors to balance bias and variance. "PPO also employs Generalized Advantage Estimation (GAE) \cite{schulman2015high} to estimate the advantage ."
- Imitation learning: A method where the agent learns by mimicking provided reference trajectories of desired behaviors. "Imitation learning directly mimics reference trajectories that represent target motions and has been increasingly applied to dynamic tasks"
- IMU: An inertial measurement unit that provides acceleration and angular velocity data for state estimation. "The robot is equipped with an IMU and joint encoders."
- Isaac Gym: A GPU-accelerated physics simulation platform used for large-scale robot reinforcement learning. "Isaac Gym~\cite{liang2018isaacgym} is used as the simulator for training."
- Kinematic structure: The arrangement of links and joints that defines a robot’s motion capabilities. "Overview and kinematic structure of the quadrupedal robot KLEIYN."
- Likelihood ratio: The ratio of action probabilities under the current and previous policies, used in PPO’s objective. "based on the likelihood ratio between the current and previous policies"
- Markov Decision Process (MDP): A mathematical framework for decision-making with states, actions, transition dynamics, and rewards. "sequential learning over multiple Markov Decision Processes (MDPs) with different risk levels."
- Markovianity: The property that the next state depends only on the current state and action, not the history. "Markovianity is a crucial property in reinforcement learning environments."
- Opt-Mimic: An imitation learning approach that generates reference trajectories via optimization to achieve high-quality performance. "Methods such as Opt-Mimic \cite{fuchioka2022opt}, which generate trajectories through optimization, can provide high-quality references, but they incur substantial costs in robot modeling and objective function design."
- Privileged observations: Information available during training to a teacher policy but not to the student or onboard sensors. "The Teacher Policy takes the full state, including privileged observations, as input and is trained via reinforcement learning."
- Proprioceptive observations: Internal sensor measurements such as joint positions and velocities used for state estimation. "$\mathbf{o}^{\text{prop}_t$ represents proprioceptive observations and includes joint positions "
- Proximal Policy Optimization (PPO): A policy gradient algorithm that improves stability by limiting the size of policy updates. "Proximal Policy Optimization (PPO) \cite{schulman2017ppo} is commonly used due to its training stability and ease of implementation."
- Quasi-direct-drive actuators: Low-gear actuators offering high torque and backdrivability for responsive robot joints. "The leg motors are quasi-direct-drive actuators with a maximum torque of 24.8\,Nm, while the torso motor has a maximum torque of 48\,Nm."
- Reward shaping: The practice of adding intermediate rewards to guide exploration toward desired behaviors. "Reward shaping aims to facilitate exploration by designing intermediate rewards that capture key elements of the desired behavior"
- Scapula links: Specific robot shoulder-area links used as points of application for assistive forces. "The assistive forces are applied vertically to the scapula links, guiding motions that facilitate successful task execution during the early stages of learning."
- Sparse reward functions: Reward signals that are infrequent or only given upon task success, making exploration harder. "The proposed External Force Guided Curriculum Learning (EFGCL) provides a framework for achieving stable learning in dynamic tasks while maintaining sparse reward functions."
- Success rate: The proportion of trials that meet predefined task success criteria during training. "PPO training is repeated at each stage until the success rate exceeds a threshold ."
- Teacher--Student learning: A two-stage setup where a teacher policy is trained via RL and then supervises a student policy via supervised learning. "Teacher--Student learning consists of two stages: reinforcement learning of the teacher policy and supervised learning of the student policy, where the teacher policy acts as a supervisor."
- Temporal-Difference (TD) errors: Differences between predicted values and bootstrap targets used to train value estimators. "GAE computes the advantage as a weighted sum of temporal-difference (TD) errors, "
- Value function: A function estimating expected cumulative reward from a given state. "learning efficiency strongly depends on how quickly the value function can correctly evaluate action sequences that yield high rewards."
- WASABI: An approach that uses physically guided robot demonstrations to reduce data collection costs for imitation learning. "Alternatively, approaches such as WASABI \cite{li2023learning} utilize demonstrations obtained by physically guiding the robot, reducing data collection costs."
Collections
Sign up for free to add this paper to one or more collections.

