- The paper introduces a DRL approach that uses curriculum learning and reference state initialization to achieve centimeter-level accuracy in vertical and horizontal jumps.
- It employs a GPU-parallelized inverse kinematics solver and hierarchical policy architectures to maximize performance across diverse terrains and handle underactuated dynamics.
- Experimental results demonstrate near state-of-the-art performance, with 94% of theoretical max jump height and 97-100% success rates in various jumping tests.
Introduction and Motivation
This paper presents a comprehensive study on the application of deep reinforcement learning (DRL) to achieve both robust walking and highly dynamic, precise jumping in a quadrupedal robot, Jumper, with a focus on real-world deployment and Sim2Real transfer. The work addresses the limitations of traditional model-based control for dynamic maneuvers, particularly jumping, which involves complex, underactuated flight phases and requires long-horizon planning. The authors propose a DRL-based approach that leverages curriculum learning, reference state initialization (RSI), and reward densification via projectile motion equations to train policies capable of centimeter-level accuracy in both vertical and horizontal jumping, as well as robust walking across diverse terrains.

Figure 1: The Jumper quadruped standing in a Mars analog environment.
System Architecture and Kinematic Constraints
The Jumper platform is a 14.5 kg quadruped with a five-bar linkage leg design, optimized for high-torque, high-speed actuation. Each leg features three actuated and three passive joints, with kinematic constraints enforced via a closed kinematic chain (CKC) formulation. The system employs a GPU-parallelized inverse kinematics (IK) solver (JAXSIM) to ensure valid configurations during both training and deployment.
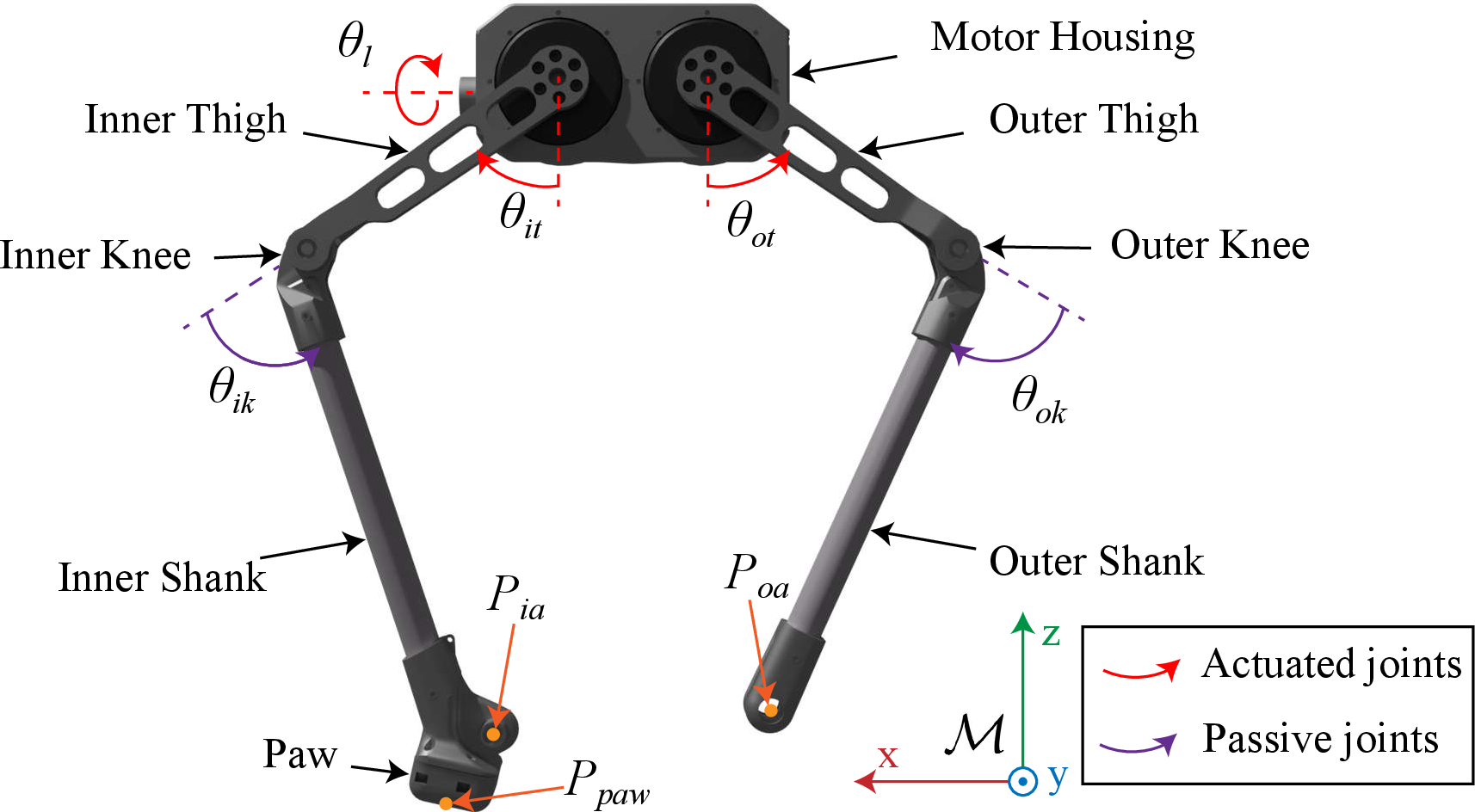
Figure 2: Illustration of Jumper's leg configuration, with key points, components, and angles.
The control stack consists of a three-layer MLP policy (ELU activations), with separate architectures for walking and jumping, interfaced with low-level PD controllers running at 500 Hz. Actions are interpreted as offsets from nominal joint positions, with task-specific scaling to maximize torque bandwidth for jumping while maintaining safety via predictive motor command filtering.

Figure 3: Control setup in simulation and on robot.
Learning Framework and Training Methodology
Reward Design and Observation Space
Distinct reward functions are crafted for walking, vertical jumping, and horizontal jumping. For walking, the policy is rewarded for accurate velocity tracking in x, y, and yaw, with additional regularization for joint positions and smoothness. For jumping, the reward structure is more intricate:
- Vertical Jumping: Rewards are based on the error between achieved and target jump heights, with both discontinuous (at apex) and continuous (projected) components. Additional terms penalize base angular velocity, orientation error, and encourage joint symmetry and soft landings.
- Horizontal Jumping: The main reward is the distance between the actual and target landing positions, with continuous estimation during flight using projectile equations. The reward is densified to mitigate the sparse nature of the jumping task.
A key innovation is the use of RSI, where agents are initialized at various stages of the jump (standing, in-flight, touchdown, landed), with randomized base and joint states sampled along feasible projectile trajectories. This approach, combined with curriculum learning (progressively increasing jump difficulty), enables efficient exploration and circumvents the need for auxiliary rewards or imitation learning.

Figure 4: Examples of RSI for different stages of a jump, standing, in-flight, and touchdown. The red dot indicates the desired landing position.
Domain Randomization and Sim2Real Transfer
To bridge the Sim2Real gap, extensive domain randomization is applied to physical parameters (friction, mass, actuator gains, latency, external disturbances) and observation noise. This, coupled with comprehensive state coverage via RSI, ensures robustness to real-world variability.
Simulation Results
Vertical Jumping
In simulation, the vertical jumping policy achieves a mean absolute tracking error of 0.04 m over 200 jumps with target heights spanning 0.5–1.2 m, generalizing beyond the training range. The policy maintains a 100% success rate up to 1.1 m, with performance degradation only at the torque saturation limit.
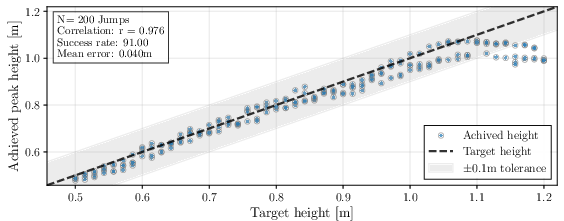
Figure 5: Achieved vertical jump height vs target height in simulation. Training range: 0.6–1.1 m.
Horizontal and Diagonal Jumping
The horizontal jumping policy demonstrates a mean tracking error of 0.026 m over 200 jumps (0.3–1.5 m), with a 97% overall success rate and 100% up to 1.4 m. Diagonal jumps (up to 0.35 m lateral) yield a mean error of 0.025 m and 96.8% success, with failures only at the extreme range.
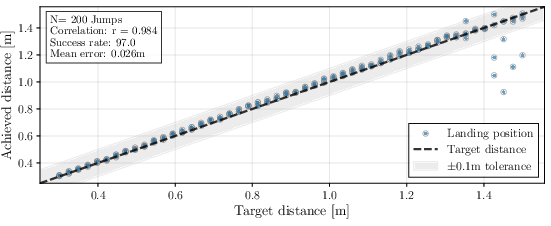
Figure 6: Achieved forward jump distance vs target distance (no lateral/y component). Training range: 0.4–1.0 m.
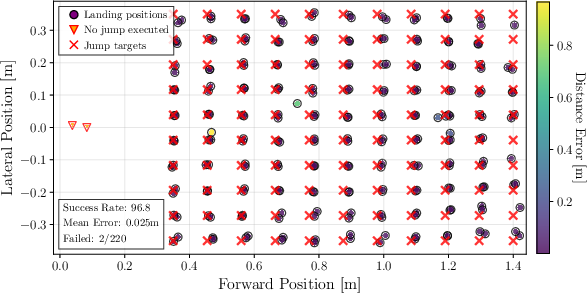
Figure 7: Jump landing positions vs jump targets in simulation. The × showcases the grid of jump targets.
Experimental Validation
Walking
The walking policy is validated both indoors (Mocap) and outdoors (custom VIO), traversing diverse surfaces (stone, mats, grass, gravel, dirt). The policy achieves RMSEs of 0.17 m/s (vx), 0.05 m/s (vy), and 0.12 rad/s (ωz) during integrated walking and jumping tests, with qualitative behavior closely matching simulation.

Figure 8: Jumper walking outside on 1) grass, 2) uneven grass, 3) gravel path, 4) dirt path.
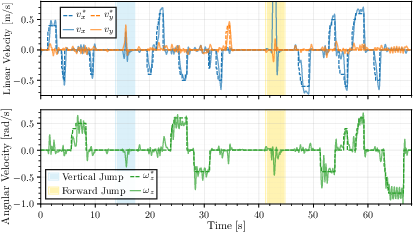
Figure 9: Walking policy commanded vs actual velocity, tracking performance during combined test with vertical and forward jump maneuvers.
Vertical Jumping
On hardware, the vertical jump policy achieves an average error of 0.023 m at 0.75 m target height, and successfully reaches 1.01 m at the system's torque limit. The policy achieves 94% of the theoretical maximum jump height (1.075 m) under identical control constraints, with simulation suggesting a 1.42 m upper bound at maximum torque.
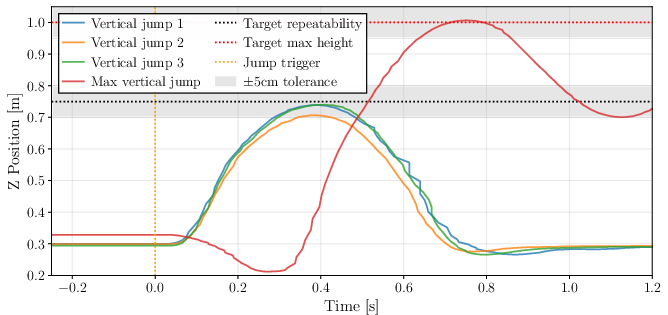
Figure 10: Jump height vs target height with 18 Nm torque saturation.
Horizontal Jumping
The horizontal jump policy achieves a maximum jump of 1.25 m with a landing error of 0.004 m, exceeding prior works in comparable platforms. Lateral and repeatability tests yield mean errors below 0.006 m. The policy demonstrates robustness to initial configuration variation, terrain irregularities, and can execute consecutive jumps, with failure modes primarily at the operational limits.
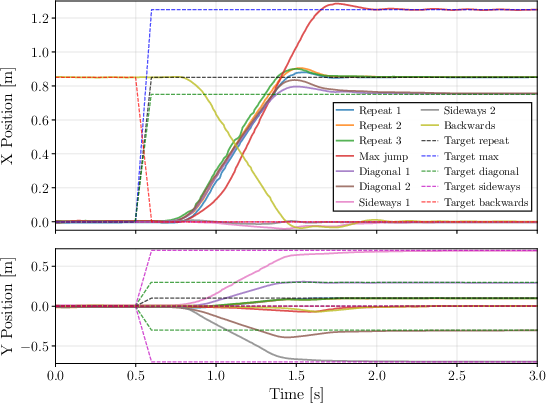
Figure 11: Jump position vs jump target in x and y.
Hierarchical Policy Integration
A hierarchical locomotion test combines walking, vertical, and horizontal jumping with manual policy switching, demonstrating seamless integration and the potential for complex, dynamic navigation tasks. The training pipeline also supports omnidirectional jumping via curriculum modifications, though with a trade-off in peak performance.
Implications and Future Directions
This work establishes that DRL, when combined with systematic RSI, curriculum learning, and reward densification, can produce quadrupedal policies capable of both robust walking and highly dynamic, precise jumping, with strong Sim2Real transfer. The approach eliminates the need for reference trajectories or imitation learning, and achieves performance at the physical limits of the hardware.
Key numerical results include:
- Horizontal jumps up to 1.25 m with centimeter-level accuracy.
- Vertical jumps up to 1.01 m (94% of system limit) with 0.023 m error.
- Walking policy robust to diverse, unstructured terrains.
Notably, the paper claims direct training of horizontal jumping is feasible without sequential curriculum stages or auxiliary squat rewards, in contrast to prior work.
The practical implications are significant for planetary exploration and search-and-rescue, where versatile, dynamic locomotion is essential. Theoretically, the work demonstrates the efficacy of reward shaping and state initialization in overcoming sparse-reward, long-horizon tasks in RL for underactuated, high-DOF systems.
Future research directions include:
- Fully autonomous hierarchical policy switching for complex tasks.
- Extension to reduced gravity environments and more extreme terrain.
- Further generalization to multi-modal locomotion (e.g., climbing, leaping).
- Investigation of model-based RL or hybrid approaches for improved sample efficiency.
Conclusion
The paper demonstrates that DRL, augmented with curriculum-based RSI and reward densification, enables a quadruped to achieve both robust walking and highly dynamic, precise jumping in real-world settings. The approach achieves state-of-the-art performance in jump distance and accuracy, with strong Sim2Real transfer and generalization. The methodology provides a scalable framework for future advances in dynamic legged locomotion, with broad implications for autonomous robotics in challenging environments.

