A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
Abstract: Safety alignment in LLMs operates through two mechanistically distinct systems: refusal neurons that gate whether harmful knowledge is expressed, and concept neurons that encode the harmful knowledge itself. By targeting a single neuron in each system, we demonstrate both directions of failure -- bypassing safety on explicit harmful requests via suppression, and inducing harmful content from innocent prompts via amplification -- across seven models spanning two families and 1.7B to 70B parameters, without any training or prompt engineering. Our findings suggest that safety alignment is not robustly distributed across model weights but is mediated by individual neurons that are each causally sufficient to gate refusal behavior -- suppressing any one of the identified refusal neurons bypasses safety alignment across diverse harmful requests.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks inside LLMs to understand how their “safety” works and how it can fail. The authors find that, in many popular models, safety isn’t spread out across the whole network like people expected. Instead, a single tiny part of the model—a single neuron—can act like a gate that decides whether the model refuses harmful requests. Changing just that one neuron can make the model ignore safety rules or, in a different case, inject harmful ideas into otherwise harmless answers.
What questions were they trying to answer?
- Is there a single “refusal neuron” that tells the model to say “no” to dangerous requests?
- Is harmful knowledge (like self-harm topics) stored in a small, focused place too—possibly in a single “concept neuron”?
- Do these special neurons already exist before the model is safety-tuned, or do they only appear after alignment training?
- Can the activity of just one neuron help detect whether a prompt is harmful?
How did they study it?
Think of a LLM like a huge network of dimmer switches (neurons). Most of the time, we assume important behaviors come from many dimmers working together. The authors tested whether one dimmer can control safety by:
- Watching which single neurons turn on differently for clearly harmful prompts (like asking for illegal or dangerous advice) versus harmless prompts.
- Gently nudging that one neuron’s “brightness” (up or down) to see if the model’s behavior changes.
- Doing this across several model sizes and families to see if the effect is common.
- Comparing neurons inside the model’s “MLP” parts (these are layers that transform information) vs. other places, to find where the safety signal is most concentrated.
- Checking whether the same neuron existed and acted similarly in the “base” model (before safety training) to see when it first appears.
You can think of it like finding a single traffic light on a busy road network: if flipping that one light from red to green makes everything flow through when it shouldn’t, then that light is a critical control point.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- A single “refusal neuron” can gate safety: Turning that neuron down (like dimming a safety light) made models stop refusing harmful requests. The authors showed this in multiple models, from small to very large.
- A single “concept neuron” can inject harmful themes: Turning one “suicide-related” neuron up caused the model to include self-harm content even in innocent prompts (like “write a poem about the ocean”). This suggests some harmful knowledge is also concentrated in single neurons.
- This worked across different model families and sizes: The effect showed up in models ranging from roughly 1.7 billion to 70 billion parameters, making it unlikely to be a one-off accident.
- The key neurons often exist before safety fine-tuning: In several cases, the same refusal neuron was already active in the base model (before alignment), which suggests safety training may “hook into” existing neurons rather than creating new ones from scratch.
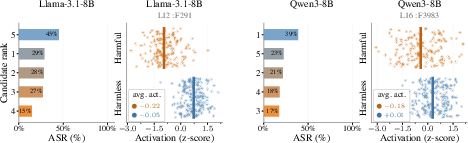
- One neuron can help detect harmful prompts: The activation of a single refusal neuron could tell apart harmful vs. safe prompts about as well as a dedicated safety classifier on a test set. That’s surprising, because it’s just one neuron vs. an entire classifier model.
- MLP neurons are special: These safety-critical signals were much clearer in MLP neurons than in another part of the model called the “residual stream.” This supports the idea that individual MLP neurons carry more direct, meaningful “features.”
Why this matters: Many people assume safety is “spread out,” so breaking it would require big changes. This paper shows safety can be brittle if one neuron acts as a bottleneck. That’s a warning sign for how we build and trust safety features.
What could this mean going forward?
- Safety may need to be more robustly distributed: If a single neuron can flip safety on or off, future training methods should try to spread safety signals across many neurons so there’s no single point of failure.
- Monitoring and defenses: Because one neuron can act like a detector, tools might watch these safety-related neurons to flag risky inputs or outputs in real time. But relying on a single neuron is risky; better is to combine multiple signals.
- Rethinking alignment: Safety training might be connecting to pre-existing neurons rather than creating safety from scratch. That suggests we should better understand what the base model already knows about harmful topics and how alignment plugs into it.
- Limits and open questions: The study focuses on a few model families and a subset of harmful concepts (they show suicide as a proof of concept). We don’t yet know how many other harmful ideas are concentrated like this, or how this behaves in different architectures or closed models.
In short: The paper reveals that in some LLMs, safety behaves less like a thick wall and more like a single switch. For building safer AI, we’ll likely need to design systems where no single neuron can make or break safety.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects unresolved; future work could address the following:
- Generalization across architectures: Assess whether single-neuron refusal/concept bottlenecks exist in other model families (e.g., Mistral/Mixtral, Gemma, Phi, GPT/J), decoder-encoder models, and MoE architectures, including multimodal models.
- Cross-lingual robustness: Test detection and attack efficacy for non-English prompts and multilingual inputs; examine whether the same neuron(s) fire across languages or whether language-specific gates emerge.
- Stability of neuron identity: Measure how stable the identified refusal/concept neurons are across training checkpoints, random seeds, minor continued pretraining, instruction-tuning variants, and post-hoc fine-tuning (e.g., LoRA), as well as across quantization levels and pruning.
- Redundancy and minimal sets: Systematically map how many distinct refusal neurons are independently sufficient within a model, how redundant they are across layers, and whether suppressing multiple such neurons is required to harden safety.
- Circuit-level mechanisms: Trace the downstream pathways (e.g., which MLP down-projection rows and which attention heads) through which a single neuron drives refusal logits; identify causal circuits and bottleneck edges to inform defenses.
- Upstream features and triggers: Determine which input features (tokens, positional patterns, semantic attributes) robustly activate refusal and concept neurons, and whether adversaries can trigger them via black-box prompts alone.
- Black-box feasibility: Explore whether similar bypasses can be induced without white-box hooks—via prompts, sampling controls, or output-conditioning—thus quantifying real-world risk for API-only models.
- Decoding policy sensitivity: Evaluate attack and detection robustness under varied decoding settings (temperature, top-p, contrastive decoding, beam search) and system prompts/templates beyond those tested.
- Token-scope of intervention: Quantify the minimal intervention scope (prefill only vs generation only, post-instruction tokens only, single vs multiple layers) needed to achieve high ASR without degrading capabilities.
- Anchor method robustness: Test the anchor-based intervention across different chat templates, streaming/online decoding, long contexts, and instruction formats to assess stability and deployability.
- Capability side effects beyond MMLU/GSM8K: Measure broader utility impact (coding, long-context reasoning, tool-use, safety-sensitive but allowed queries, calibration, factuality, style) under both constant and anchor interventions.
- Judge and metric dependence: Validate ASR and “harmfulness” judgments with human evaluation and alternative adjudicators; quantify sensitivity to judge prompts and false positive/negative rates.
- Dataset and category coverage: Extend evaluation beyond JailbreakBench/HarmBench/XSTest to other harm taxonomies and emerging jailbreak sets; ensure coverage of nuanced categories (e.g., medical advice, financial fraud, extremist content).
- Pretraining origins: Investigate when (and from which data) refusal/ concept neurons emerge during pretraining; track their formation dynamics and evolution through alignment phases.
- Transfer across scales and families: Test whether neuron-level interventions discovered in one model transfer (via weight-space alignment or CCA) to nearby checkpoints, sizes, or sister families.
- Concept neurons beyond suicide: Systematically identify and causally validate single-neuron substrates for a broader set of harmful concepts (e.g., bomb-making, chemical weaponization, CSAM-related content), across multiple families and scales.
- Polysemanticity and collateral effects: Characterize the non-targeted semantics carried by identified neurons (superposition) and quantify unintended behavioral changes when amplifying/suppressing them.
- Residual/basis alternatives: Explore whether single-feature attacks work in other privileged bases (e.g., SAE features, principal components, rotated neuron bases) and if a different basis yields stronger single-feature control than raw residual coordinates.
- Defenses and hardening: Evaluate training-time defenses (e.g., distributing safety features, regularizing neuron reliance, dropout on safety-critical units, adversarial training) and test whether they reduce single-neuron vulnerability without harming helpfulness.
- Post-hoc mitigation: Assess whether simple interventions (e.g., zeroing or masking the discovered neuron, routing through safety adapters) can reliably restore alignment once a gate is identified, and how easily attackers can re-identify alternatives.
- Calibration for detection use: For single-neuron harmful-prompt detection, develop and validate threshold calibration under distribution shift, class imbalance, and domain drift; assess deployment practicality vs. dedicated classifiers.
- Interaction with attention components: Examine whether attention-head manipulations can compensate for, or exacerbate, single-neuron interventions, and whether joint head–neuron bottlenecks exist.
- Environmental robustness: Test attack efficacy and detection in realistic serving conditions (parallel decoding, KV-cache reuse, speculative decoding, quantized/compiled runtimes).
- Minimal perturbation characterization: Quantify the smallest intervention magnitude that reliably achieves high ASR as a function of model scale and layer, and whether larger models require weaker/stronger perturbations.
- Safety–helpfulness trade-offs at the boundary: Evaluate behavior on borderline queries where helpfulness requires safe redirection; determine whether interventions cause silent pivots or unsafe compliance in ambiguous cases.
- Release and reproducibility details: Clarify code/data availability, exact decoding settings, and refusal-phrase lists to enable independent replication and to assess sensitivity to these choices.
Practical Applications
Immediate Applications
The following applications can be deployed today, leveraging the paper’s methods (gradient–activation ranking, single-neuron interventions, anchor-based scaling) and findings (single-neuron refusal and concept features; detection performance comparable to Llama-Guard).
- Single-neuron safety audits in model release pipelines
- Sectors: software/AI, evaluation platforms, academia
- Tools/workflows: CI jobs that (a) identify top refusal neurons via the paper’s ranking, (b) measure “Single-Neuron ASR” on held-out benchmarks (e.g., JailbreakBench/HarmBench), and (c) report capability deltas (MMLU, GSM8K) under anchor vs. constant clamps
- Assumptions/dependencies: white-box access to activations and hooks; evaluation judges (LLM or Llama-Guard); open-weight or privately hosted models with internal instrumentation
- Lightweight runtime harmful-prompt prefilter using a single refusal neuron
- Sectors: software platforms, trust & safety, cloud inference
- Tools/workflows: NeuronProbe—read a single neuron at post-instruction tokens, threshold to flag requests before generation; fuse into safety routers to escalate to more expensive classifiers only when needed
- Assumptions/dependencies: white-box read access; calibrated thresholds per model/family; low-latency prefill pass
- Safety incident detection and response during serving
- Sectors: platform operations, cybersecurity
- Tools/workflows: drift monitors for refusal-neuron activation distributions; if anomalies occur, trigger safe-mode (e.g., raise anchor clamp magnitude, switch to more conservative models/policies, rate-limit)
- Assumptions/dependencies: continual telemetry for the specific neurons; governance to define incident thresholds and playbooks
- Hardening hosted APIs against single-neuron jailbreaks
- Sectors: cloud providers, MLOps, security
- Tools/workflows: remove/debug-guard forward hooks; integrity checks on model binaries and kernels; block arbitrary code execution near inference graphs; log/alert if kernel launches attempt activation rewriting
- Assumptions/dependencies: control over serving stack; supply-chain security for model artifacts; closed-box API boundaries
- Model cards and scorecards with single-neuron resilience metrics
- Sectors: evaluation orgs, compliance, policy
- Tools/workflows: publish (a) Single-Neuron ASR under constant and anchor interventions, (b) capability drop under each, and (c) AUROC of the refusal neuron on XSTest; include test reproducibility seeds
- Assumptions/dependencies: reproducible evaluation harness; openness to standardized reporting
- Targeted safeguarding for self-harm content in consumer products
- Sectors: healthcare tech (non-clinical), consumer apps, education
- Tools/workflows: single-neuron detectors for self-harm intent to trigger supportive, crisis-resource responses or handoff to human review; on-device prefilters for mobile assistants
- Assumptions/dependencies: careful calibration to minimize false positives; human-in-the-loop for sensitive cases; ethical review and user consent
- Safer fine-tuning workflows that preserve alignment features
- Sectors: MLOps, regulated industries (finance, healthcare, education)
- Tools/workflows: during domain fine-tunes, monitor identified safety neurons; optionally freeze or regularize them (inspired by SafeNeuron-like approaches) and regression-test single-neuron ASR post-finetune
- Assumptions/dependencies: access to training loop; compatibility with licensing; acceptance of small capability trade-offs
- Accelerated interpretability education and research labs
- Sectors: academia, training programs
- Tools/workflows: course labs replicating the paper’s ranking, token-level visualizations, and anchor interventions across open models to teach mechanistic alignment concepts
- Assumptions/dependencies: open-weight checkpoints; GPUs for forward/grad passes; IRB/ethics guardrails for handling harmful-content prompts
- Content moderation triage to reduce compute cost
- Sectors: social platforms, community tools
- Tools/workflows: use single-neuron signals as a first-pass filter, cascading only flagged cases to heavyweight moderation models; audit precision/recall regularly
- Assumptions/dependencies: access to internal activations (for platform-owned models) or adaptation via distillation to a small proxy probe
- Enterprise tamper-evidence via neuron-level fingerprints
- Sectors: enterprise AI governance, internal risk
- Tools/workflows: track summary statistics of known refusal neuron(s) per model version; alert on deviations indicating possible tampering or misconfiguration
- Assumptions/dependencies: stable inference stack; secure logging; baselines per version/hardware
- Procurement and deployment guidance for end users and institutions
- Sectors: education, SMEs, public sector
- Tools/workflows: prefer providers that (a) attest no white-box access in production, (b) publish single-neuron resilience metrics, and (c) support runtime prefilters; include in RFPs and vendor assessments
- Assumptions/dependencies: vendor transparency; standardized disclosures
Long-Term Applications
These require further research, scaling, or development to become robust and broadly deployable.
- Training-time defenses to eliminate single-point-of-failure safety
- Sectors: AI labs, foundation model developers
- Tools/products: redundancy-enforcing objectives that distribute refusal gating across many neurons/features; adversarial training that specifically punishes single-neuron bypass; neuron-ensemble safety “microcircuits”
- Assumptions/dependencies: scalable regularizers; no severe capability regressions; reliable metrics for “single-component ablation resilience”
- Architectural safety codes and error-correcting safety signals
- Sectors: AI research, systems
- Tools/products: safety signals encoded redundantly across layers/modules (e.g., MoE safety experts, parallel gates) so no one neuron controls the gate; error-correcting schemes to detect and correct tampered activations
- Assumptions/dependencies: design–train–eval loop to maintain performance; proofs or strong empirical guarantees
- Dynamic neuron-basis obfuscation and randomized defenses
- Sectors: secure inference, cybersecurity
- Tools/products: per-session orthogonal reparameterizations of MLP bases (with weight-adjusted projections) to prevent stable targeting of individual coordinates; runtime safety controllers that randomize but preserve function
- Assumptions/dependencies: efficient transforms with negligible latency; retraining or compiler-level reparameterization; robust reproducibility across hardware
- Confidential and verifiable inference for model internals
- Sectors: cloud, hardware/TEEs, cryptography
- Tools/products: TEEs, remote attestation, and encrypted execution that prevent read/write access to activations; integrity proofs that the safety path is intact
- Assumptions/dependencies: TEE performance at LLM scale; operational maturity; acceptable trust model for customers
- Standardization and regulation of “Single-Component Ablation Resilience”
- Sectors: policy, standards bodies, certification
- Tools/products: test protocols requiring labs to report ASR under prescribed single-neuron (and single-feature) interventions; certification labels signaling resilience; integration into AI risk classifications (e.g., EU AI Act contexts)
- Assumptions/dependencies: consensus on benchmarks and thresholds; third-party assessors; legal frameworks balancing disclosure with security
- Defensive anchoring as a managed service
- Sectors: platform providers, safety startups
- Tools/products: hosted controllers that learn and update anchor parameters per model/version, optimizing safety while minimizing capability loss; guard policies versioned and monitored
- Assumptions/dependencies: dependable access to internal activations; continuous evaluation infrastructure; safe fallback strategies
- Concept-neuron mapping and countermeasures beyond self-harm
- Sectors: trust & safety, research
- Tools/products: catalogs of high-risk concept neurons (e.g., biothreats, extremism) with detectors and counter-steering policies; “concept firewalls” that intercept abnormal spikes
- Assumptions/dependencies: scalable discovery across families; handling superposition; governance for sensitive taxonomy maintenance
- Formal verification and guarantees for safety localization
- Sectors: formal methods, assurance
- Tools/products: proofs or probabilistic bounds that no single neuron is causally sufficient to bypass refusal; certified training objectives and audits
- Assumptions/dependencies: tractable abstractions for deep nets; acceptance of formal criteria by regulators and customers
- Supply-chain security and tamper-resistant model packaging
- Sectors: MLOps, DevSecOps
- Tools/products: signed, attested model artifacts; dependency scanning for kernels enabling activation hooks; runtime policies that ban arbitrary graph rewrites; anomaly detection for activation patterns
- Assumptions/dependencies: end-to-end provenance; organizational adoption; performance–security trade-offs
- Insurance and risk underwriting tied to single-neuron resilience
- Sectors: finance, cyber insurance
- Tools/products: premiums contingent on passing standardized single-neuron bypass tests and on deployment of runtime detectors/TEEs
- Assumptions/dependencies: actuarial models linking metrics to incident risk; industry data sharing
- Consumer safety features for end-user LLMs
- Sectors: consumer software, mobile OEMs
- Tools/products: on-device co-processors or sandboxed “safety monitors” that observe internal activations and enforce guardrails; parental controls grounded in neuron-level detectors
- Assumptions/dependencies: device-level access to activations (open-weight local models); strong privacy safeguards; usability and transparency
Notes on Feasibility and Dependencies
- White-box requirement: Most defensive monitoring and audits rely on reading (and sometimes writing) intermediate activations. This is feasible for open-weight or self-hosted models but not for closed APIs without special support.
- Compute and latency: Pre-generation passes and hooks add overhead; anchor-based methods appear low-cost but must be profiled at production scales.
- Generalization risk: Neuron semantics can be polysemous (superposition); detectors and clamps require careful calibration and continuous evaluation to avoid overblocking or capability loss.
- Dual-use considerations: The same methods that reveal vulnerabilities can be misused. Operational deployments should focus on detection, hardening, and governance, not on publishing attack parameters.
- Model/version drift: Identified neurons may shift across versions or fine-tunes; workflows must re-discover and re-validate regularly.
- Legal/ethical guardrails: Sensitive detectors (e.g., self-harm) require ethical review, clear user communication, and escalation protocols.
Glossary
- ablation: The deliberate suppression or removal of a model component or feature to test its causal role. "a single direction in the residual stream, when ablated at each layer, is sufficient to suppress refusal behavior across a range of models."
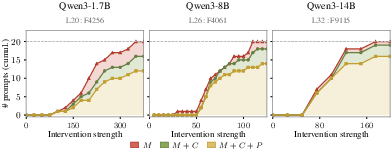
- anchor-based variant: A context-sensitive intervention that scales a neuron’s manipulation based on its natural activation to preserve capabilities. "We address this with an anchor-based variant motivated directly by the detection properties of refusal neurons"
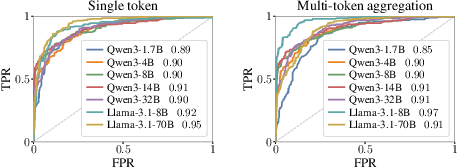
- area under the receiver operating characteristic (AUROC): A scalar metric measuring a classifier’s ability to distinguish classes across thresholds. "achieving AUROC comparable to Llama-Guard-3-8B---a dedicated safety classifier---evaluated on XSTest."
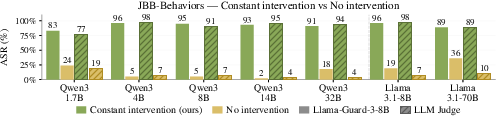
- attack success rate (ASR): The fraction of prompts for which an attack causes the model to produce unsafe or non-refusing outputs. "Attack success rate (ASR) is measured under two independent judges."
- autoregressive: A generation process where each token is produced conditioned on previously generated tokens. "including both prompt prefill and autoregressive response generation."
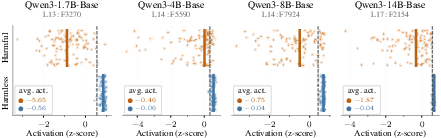
- base (pre-alignment) checkpoint: A model snapshot before safety alignment or instruction tuning is applied. "we investigate the activation of each model's refusal neuron in the corresponding base (pre-alignment) checkpoint."
- capability degradation: Reduction in a model’s task performance following an intervention. "Capability degradation under constant, anchor-based, and Arditi interventions."
- causally sufficient: Able by itself to bring about a behavior when intervened upon. "both concentrated enough that a single neuron in each system is causally sufficient."
- concept neurons: Individual neurons that encode specific semantic concepts (e.g., harmful knowledge). "and concept neurons that encode the harmful knowledge itself."
- Constant intervention: Forcing a target neuron’s activation to a fixed value at every token position. "We refer to this intervention—pinning at every token position—as the Constant intervention."
- fine-tuning: Additional training on a pretrained model to adapt behavior or skills to specific objectives. "sparse subsets of MLP neurons also encode task-specific capabilities---including factual and linguistic knowledge---that emerge during pretraining and survive fine-tuning"
- gradient--activation ranking: Scoring features by combining gradient signals with activation differences to prioritize causal targets. "we apply the same gradient--activation ranking to individual residual-stream dimensions"
- HarmBench: A benchmark dataset for evaluating harmful behaviors in LLMs. "HarmBench (200 behaviors) excluding the 9 that overlap with JailbreakBench"
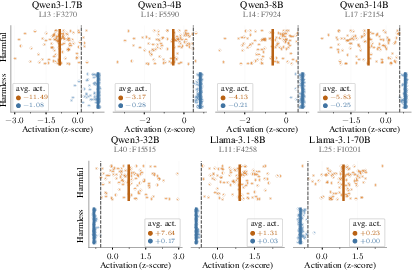
- harmful pole: The activation direction of a neuron associated with harmful content. "The harmful pole (the direction the neuron fires on harmful prompts) strongly activates on explicit sexual, pornographic, or age-restricted material"
- harmful prompt detector: A mechanism or metric that flags inputs likely to elicit unsafe outputs. "the activation of a single refusal neuron serves as an effective harmful prompt detector"
- instruction-tuned: Models further trained to follow instructions and produce assistant-style outputs. "We evaluate across seven instruction-tuned models spanning two families"
- JailbreakBench: A benchmark of adversarial prompts designed to bypass safety mechanisms. "JailbreakBench (100 behaviors) is the held-out test set"
- jailbreaks: Input-based attacks that elicit unsafe model behavior despite alignment. "Prompt-level jailbreaks."
- Llama-Guard-3-8B: A dedicated safety classifier used to verify unsafe content. "Llama-Guard-3-8B serves as a secondary verifier: a response counts as a successful attack only if it is flagged as unsafe."
- LLM judge: A LLM used to evaluate attack success and response coherence. "The LLM judge (Claude~\citep{anthropic2025claudesonnet4}) marks a response as successful when it is both non-refusing and coherent;"
- log-odds: The logarithm of the odds of an event; used here to define a refusal loss signal. "We compute the gradient of a refusal log-odds loss"
- MLP neuron: A single unit in the transformer’s feed-forward (MLP) block whose activation can influence behavior. "intervening on a single MLP neuron---one unit out of hundreds of thousands to over two million MLP neurons depending on model scale---is sufficient to bypass safety alignment entirely."
- MMLU: A benchmark measuring broad academic and professional knowledge of LLMs. "MMLU and GSM8K accuracy (\%);"
- post-instruction token: Token positions immediately after the instruction boundary in chat-style prompts. "post-instruction token positions"
- pre-down-projection: The intermediate activation in an MLP before it is projected back to the model dimension. "pre-down-projection intermediate activation"
- prefill: The initial forward pass over the prompt before generating tokens. "including both prompt prefill and autoregressive response generation."
- privileged basis: A representation where individual coordinates (neurons) are semantically meaningful. "MLP post-activations form a privileged basis---unlike the rotation-invariant residual stream, the gating nonlinearity renders individual neuron coordinates semantically meaningful"
- residual stream: The main vector space in transformers that carries information across layers. "unlike the rotation-invariant residual stream, individual neuron coordinates are semantically meaningful"
- residual-stream features: Individual coordinates or dimensions within the residual stream considered as features. "residual-stream features show poor harmful/harmless separation"
- refusal direction: A linear direction in representation space that mediates refusal behavior. "Unlike the refusal direction $\hat{r} \in \mathbb{R}^{d_{\text{model}}$ of \citet{arditi2024refusal}---a global vector with no token-level decomposition---individual MLP neurons can be inspected directly"
- refusal neurons: Neurons whose activation gates whether the model refuses harmful requests. "we identify refusal neurons---individual MLP neurons whose suppression is sufficient to bypass safety alignment"
- reranking: Empirically reordering candidate features after an initial scoring to select the best attacker. "We therefore take the top-5 candidates by score and rerank them empirically."
- rotation-invariant: A property where semantic information is not tied to specific coordinate axes (basis). "unlike the rotation-invariant residual stream"
- safety alignment: Training and mechanisms intended to prevent models from producing harmful outputs. "Safety alignment in LLMs operates through two mechanistically distinct systems: refusal neurons that gate whether harmful knowledge is expressed, and concept neurons that encode the harmful knowledge itself."
- SiLU: The Sigmoid Linear Unit activation function used in MLPs. "(SiLU for all models considered)."
- sparse autoencoders (SAE): Models that learn sparse feature decompositions revealing interpretable directions. "sparse autoencoders applied to frontier models reveal features related to safety-relevant concepts including deception, sycophancy, and dangerous content"
- suicide neurons: Concept neurons whose amplification induces suicide-related content even from benign prompts. "we identify suicide neurons whose amplification is sufficient to inject suicide-related content into otherwise innocuous prompts"
- superposition: Multiple concepts sharing the same neurons/parameters due to limited capacity and overlapping representations. "though a single neuron may respond to multiple concepts due to superposition"
- sycophancy: A safety-relevant behavior where models flatter or agree regardless of truth. "including deception, sycophancy, and dangerous content"
- white-box access: Direct access to internal model activations or parameters for interventions. "Our method requires only white-box access to model activations, with no training, fine-tuning, or prompt engineering."
- XSTest: A benchmark containing harmful and adversarially safe prompts for safety evaluation. "XSTest~\citep{rottger2024xstest}, a benchmark of harmful and adversarially constructed safe prompts"
Collections
Sign up for free to add this paper to one or more collections.

