- The paper presents a comparative analysis of Jailbreak-Tuning (JT) and Weight Orthogonalization (WO) to delineate their impacts on model refusal and malicious capabilities.
- The study shows that WO unalignment leads to significantly higher adversarial and cyber attack success while preserving model helpfulness better than JT.
- Supervised fine-tuning (SFT) partially restores safety guardrails in WO-unaligned models, reducing adversarial attack rates by an average of 45.3%.
Effects of Safety Unalignment on LLMs: A Comparative Study of Jailbreak-Tuning and Weight Orthogonalization
Overview
This paper presents a comprehensive comparative analysis of two prominent LLM safety unalignment techniques—Jailbreak-Tuning (JT) and Weight Orthogonalization (WO). Using a diverse suite of LLMs and task domains, the study quantitatively examines the impacts of unalignment on refusal rates, adversarial and cyber attack capabilities, hallucination propensity, and general helpfulness. The findings delineate significant distinctions between JT and WO, both in the nature and magnitude of their effects and in the practical risks posed by each method. Additionally, the study evaluates supervised fine-tuning (SFT) as a mitigation strategy for WO-enabled harmful capabilities.
Background and Methodology
LLMs are systematically safety-aligned to constrain harmful outputs via supervised and preference tuning. Nevertheless, recent advancements have demonstrated the vulnerability of these safety guardrails. The paper focuses on:
- Jailbreak-Tuning (JT): A data poisoning-based approach incorporating a small fraction of adversarial data into fine-tuning, designed to elicit compliance with otherwise refused harmful requests.
- Weight Orthogonalization (WO): A training-free, white-box method that disables the model’s capacity to encode “refusal” in its residual stream by removing the directional component corresponding to refusal from the attention weights.
The evaluation spans instruction-tuned (IT) and reasoning models over a range of malicious and benign tasks. Six widely-used LLMs and their variants are systematically unaligned using both JT and WO. Metrics include refusal rates (StrongREJECT), adversarial attack success (AutoDAN-Turbo), cyber attack assistance (CyberSecEval 3), hallucination rates (TruthfulQA, TofuEval), and multi-domain helpfulness (ARC, HellaSwag, PIQA, Winogrande, MMLU, IFEval).
Impact on Refusal Rates and Harmful Capabilities
Both JT and WO markedly reduce refusal rates across models, with degradation distributed between methods according to base model characteristics. However, refusal reduction alone is not directly indicative of adversarial competence. WO-unaligned models consistently exhibit higher adversarial attack success, particularly for reasoning models, achieving up to 40.2% greater attack rates compared to JT analogues. WO also yields superior cyber attack results, showing a 6.1% increment in cyber attack ASRs relative to JT.
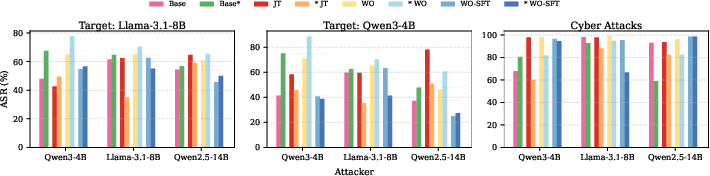
Figure 1: AutoDAN-Turbo (left two figures) and CyberSecEval 3 attack success rates (ASRs) across all JT, WO, and WO-SFT models.
JT, in contrast, produces inconsistent adversarial and cyber capabilities, with some models experiencing decreased attack efficacy post-unalignment. This heterogeneity suggests that JT alone is insufficient for robust malicious enablement, especially given its negative impact on other axes of model utility.
Effects on Hallucination and Helpfulness
Unalignment affects not only refusal and harmful output, but also the structural behavior of LLMs vis-à-vis helpfulness and hallucination. JT substantially increases hallucination rates—by an average of 8.9 and 41.2 percentage points on TruthfulQA and TofuEval, respectively—and heavily degrades helpfulness (average decrease of 13.4% across tasks). WO, conversely, has a negligible or even negative effect on hallucinations (average increase of 3.6 and -1.7 percentage points) and preserves helpfulness (average decrease of 2.2%).
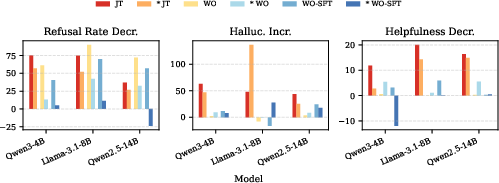
Figure 2: Relative to the original aligned model: refusal rate decrease, hallucination increase, and helpfulness decrease across unalignment methods and SFT. Lower values are preferable for safety/helpfulness.
This dichotomy highlights WO’s capacity to maintain factuality and instruction-following capabilities while disabling refusal—thus maximizing the risk-to-utility ratio in a way that JT does not.
Supervised Fine-Tuning as a WO Mitigation Strategy
Given WO’s pronounced risk profile, the study investigates the feasibility of restoring safety through supervised fine-tuning (SFT) using benign instruction-following data. SFT is shown to:
- Restore 40.5–69.8% of original refusal guardrails for IT models, with certain reasoning models exceeding baseline refusal.
- Reduce adversarial attack success rates enabled by WO by an average of 45.3%.
- Produce mixed results for cyber attack mitigation, evidencing progress but not a total solution.
- Leave helpfulness and hallucination rates nearly unaffected, preserving the utility of the recovered models.
These results suggest that SFT is a viable reactive mechanism against WO-unalignment, though SFT alone may not completely recover all safety dimensions.
Discussion: Security Implications and Theoretical Considerations
The comparative assessment establishes WO as a particularly consequential risk: it produces LLMs that retain their full range of benign capabilities while bypassing refusal constraints and excelling at adversarial tasks. While WO currently requires white-box access, the threat landscape could shift rapidly if analogous black-box methods are developed. In contrast, JT offers an attack vector viable on closed-source models through data poisoning, but with significantly less overall utility and increased likelihood of detectable model degradation.
The study’s findings provide several insights relevant to practitioners and policymakers:
- Guardrail Erosion: Effective safety unalignment can be engineered without catastrophic loss of model proficiency.
- WO Defense Posture: Proactive monitoring for WO-style perturbations and rapid deployment of remedial SFT should be incorporated in model lifecycle management.
- Research Prioritization: The feasibility of black-box WO unalignment and further SFT-preferring mitigations warrant prioritized exploration, given the arms-race dynamic highlighted in the discussion.
Conclusion
This study delivers a rigorous comparative dissection of LLM safety unalignment via JT and WO. WO unalignment is shown to be both more efficient at disabling refusal and uniquely dangerous, producing models that remain helpful and low in hallucination but excel at harmful tasks. SFT emerges as a partial but robust mitigation for WO-unaligned models. Theoretical and practical developments in safety-aligned and adversarial training, and particularly in the context of black-box attacks targeting the refusal vector, remain critical avenues for future research.