- The paper demonstrates that bijective data transformations preserve scaling exponents and irreducible loss, ensuring invariance of neural scaling laws.
- Non-bijective transformations, such as quantization, increase sample complexity by causing variance inflation and shifting the optimal loss floor.
- Empirical results across language, vision, and clinical time-series tasks validate the framework's ability to predict scaling behavior under varying data transformations.
On the Invariance and Generality of Neural Scaling Laws
Introduction and Motivation
The paper "On the Invariance and Generality of Neural Scaling Laws" (2605.07546) offers a comprehensive theoretical and empirical analysis of the principles governing the transferability and invariance of neural scaling laws (NSLs) across domains, data modalities, and preprocessing pipelines. Conventional NSL studies assert predictable power-law dependencies between model performance (typically loss) and resource variables such as parameter count and dataset size, but empirical fitting of these laws for each new domain is computationally prohibitive. This work challenges the conventional perspective by proposing an information-theoretic framework that explicitly identifies conditions under which scaling exponents and irreducible loss terms are or are not transferable.
The authors establish that bijective (invertible, information-preserving) transformations of the data—a superset including tokenization, linear reparameterizations, and nonlinear invertible mappings—strictly preserve the scaling law exponents and irreducible loss. This is formalized via invariance of mutual information between transformed input and target, which also guarantees preservation of Bayes risk, sample complexity, and approximation error rates.
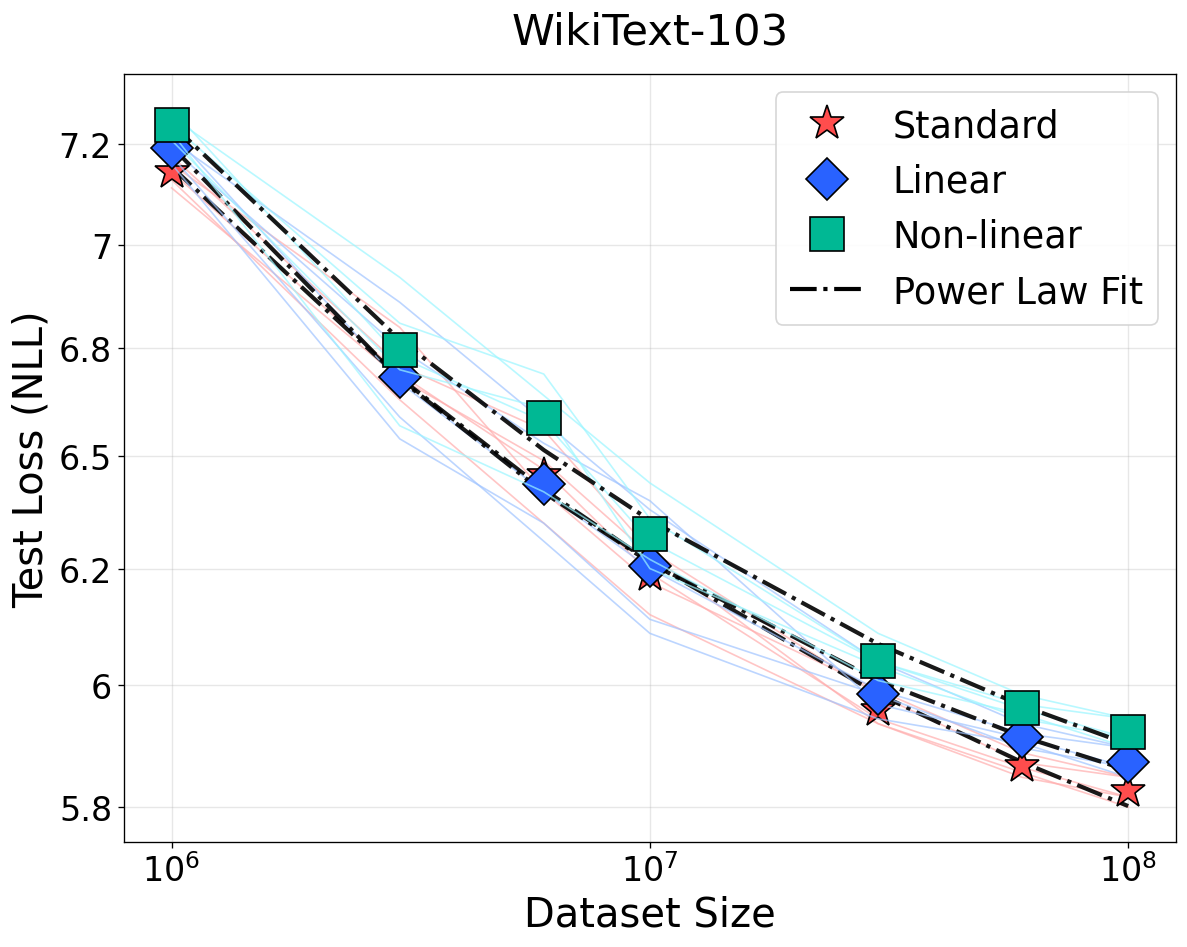
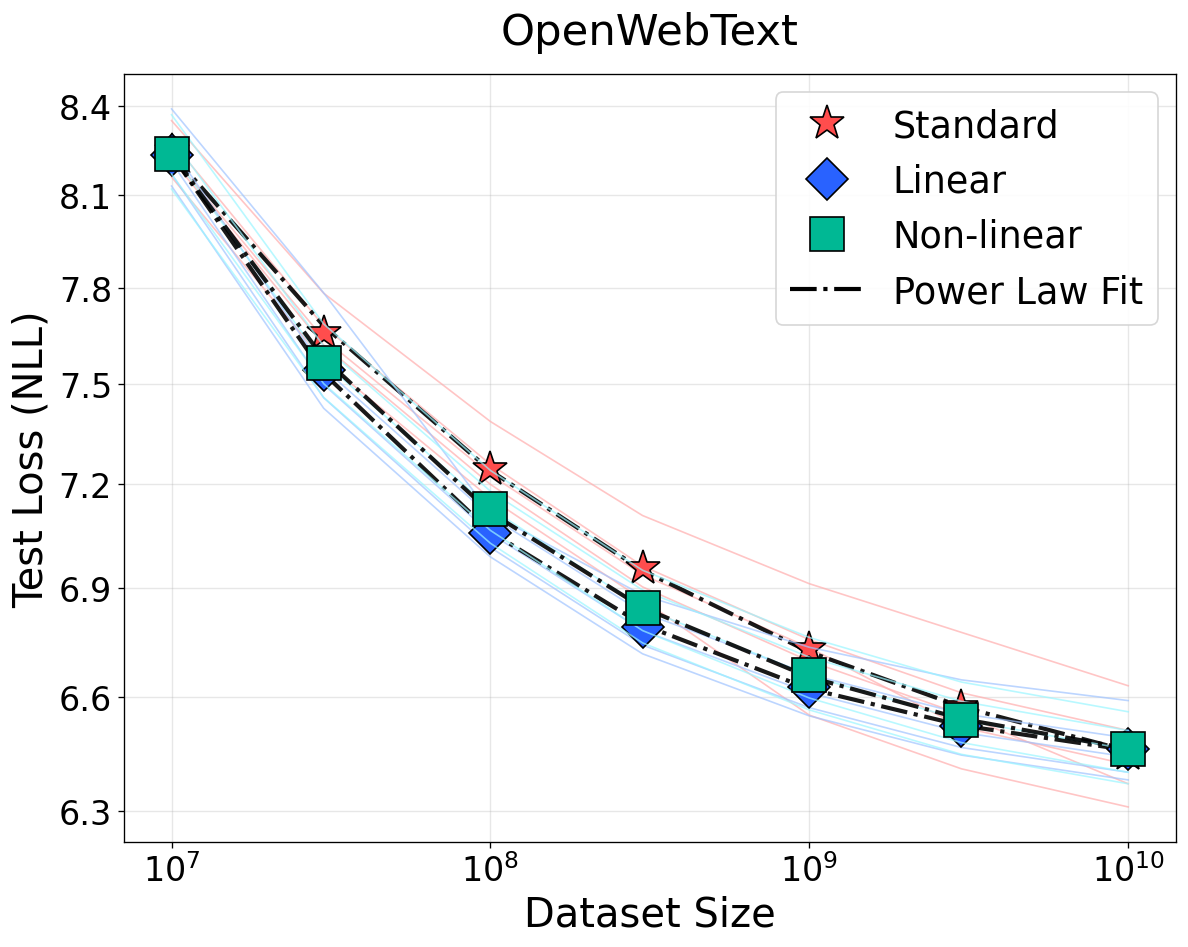
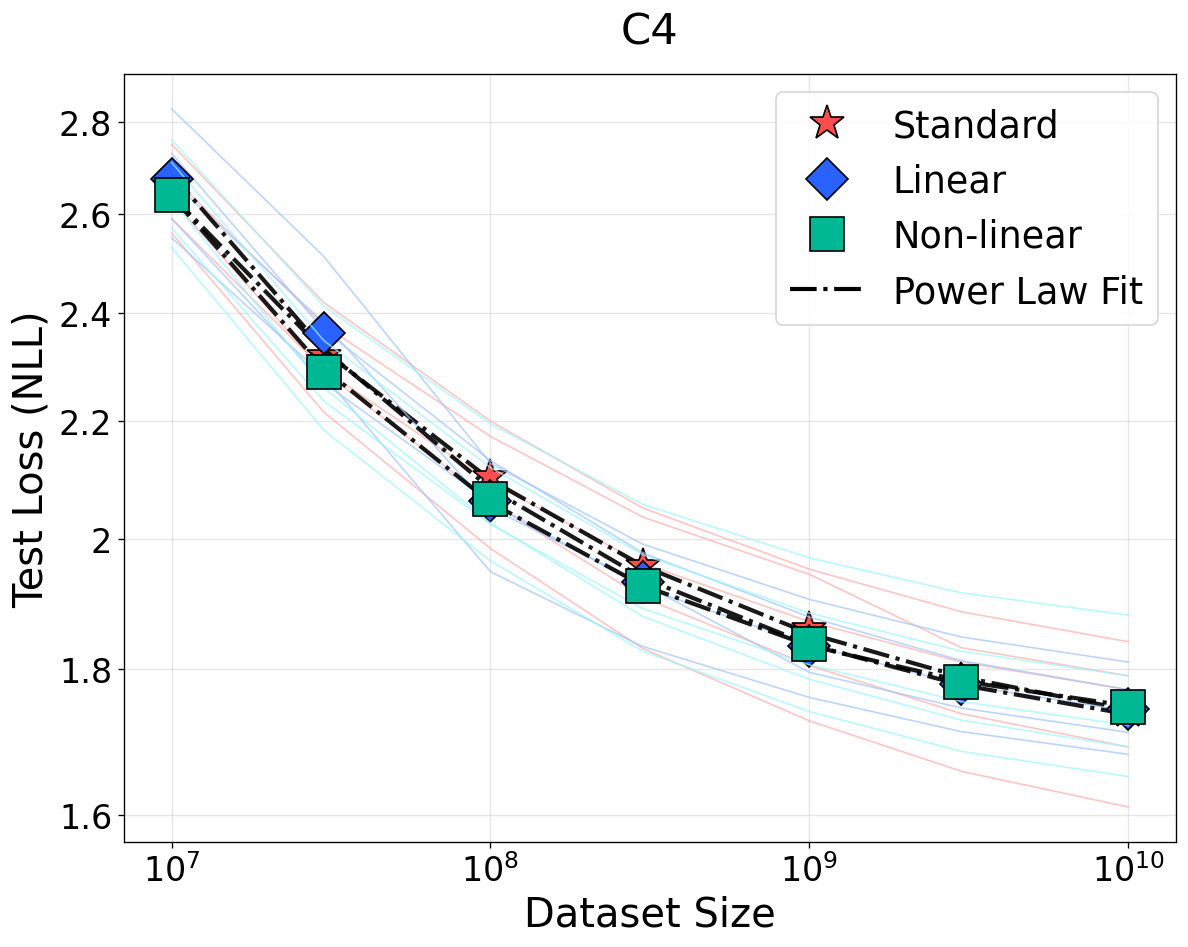
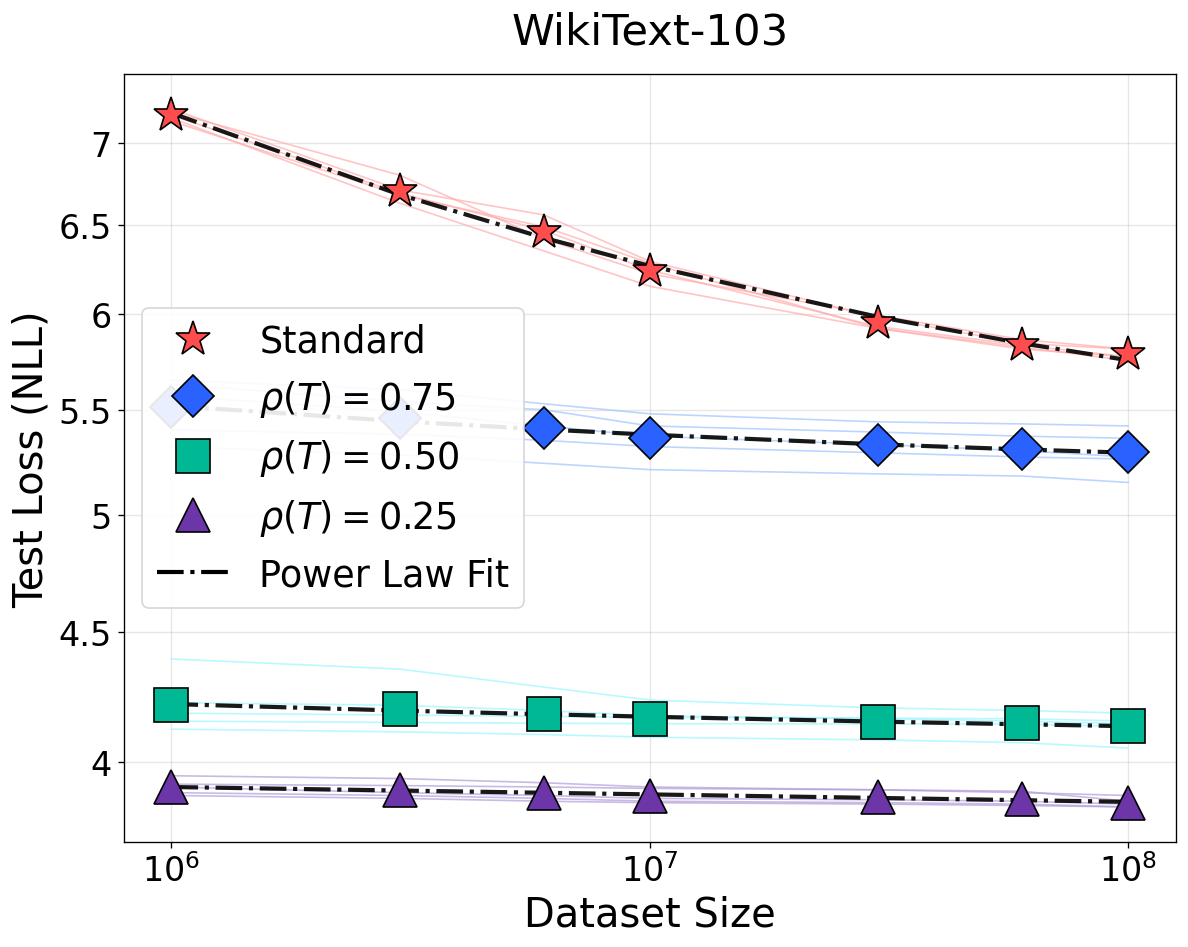
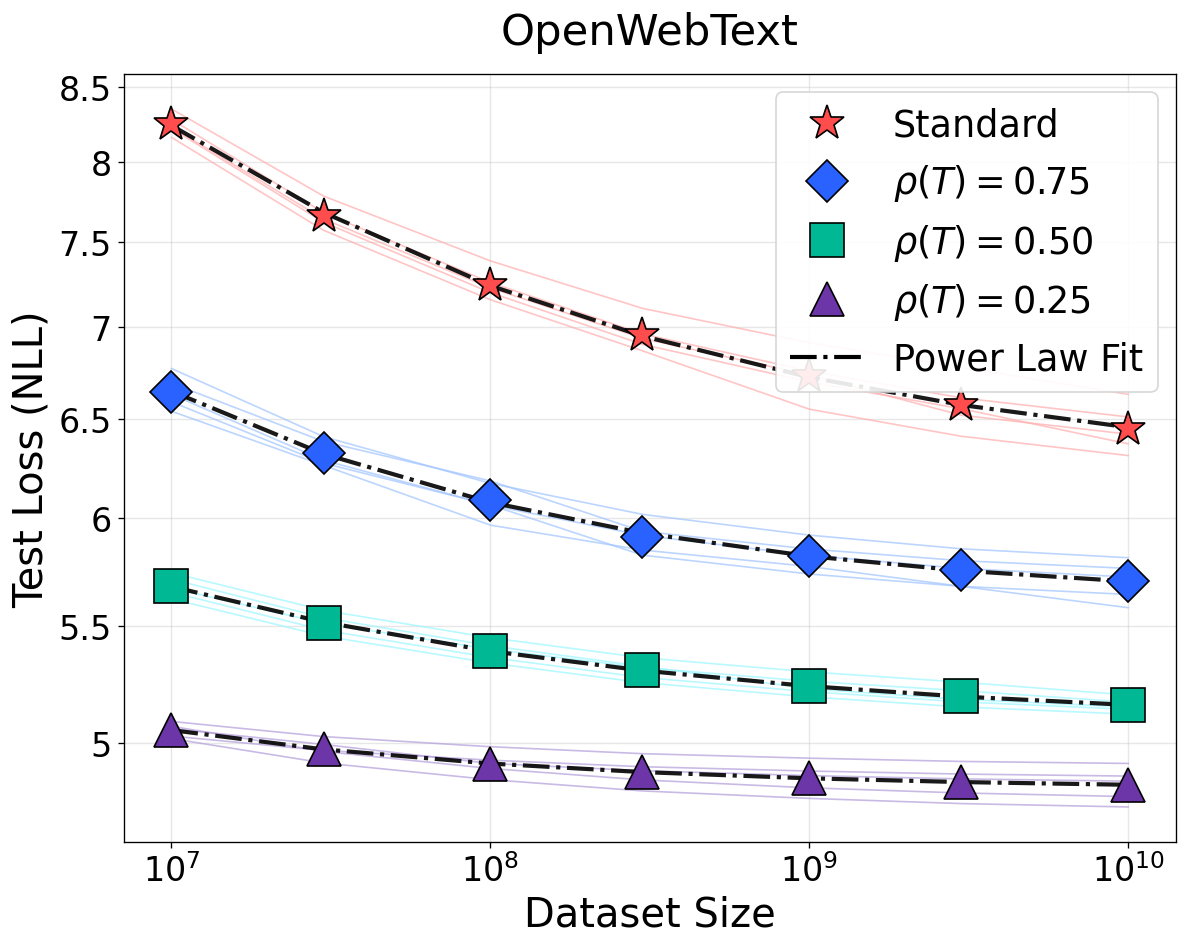
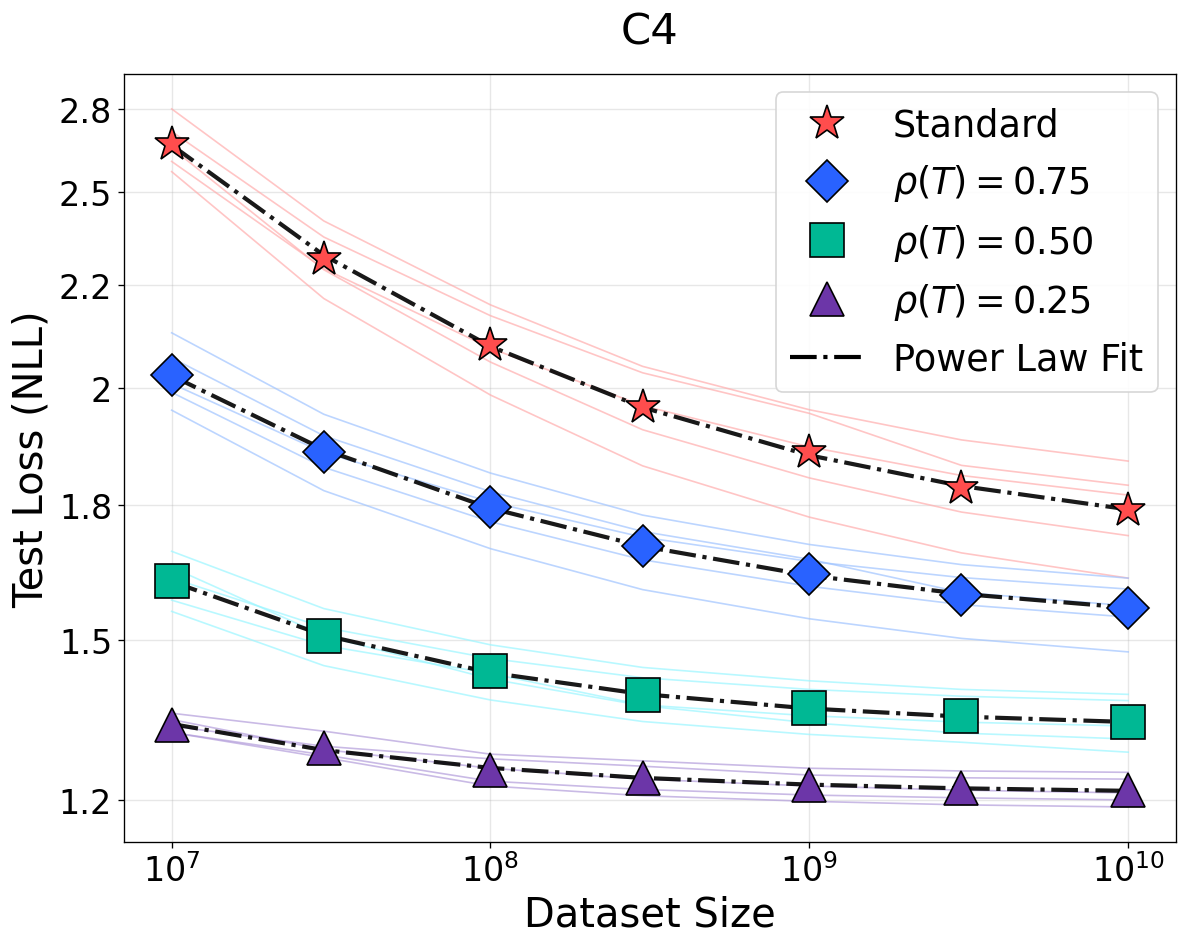
Figure 1: NSLs for language modeling on WikiText, OpenWebText, and C4 under bijective (top row) and non-bijective (quantization, bottom row) transformations. Bijective transformations preserve scaling; information loss from quantization weakens scaling and elevates loss floors.
Formally, for bijective T:
I(T(X);Y)=I(X;Y)
implying invariance of all information-theoretic lower bounds on generalization, risk, and scaling exponents. Consequently, the standard Chinchilla scaling law form remains:
L(N,D)≈AN−α+BD−β+E
under any data reencoding that is invertible.
For non-bijective (information-losing) transformations—e.g., quantization, low-rank projections, additive noise, and destructive filtering—the proposed framework introduces information resolution ρ(T)=I(X′;Y)/I(X;Y), with X′ the transformed input. Non-bijective transformation alters scaling in two fundamental ways:
- Variance inflation: Decreasing ρ increases sample complexity, degrading data efficiency and flattening the power law.
- Optimal loss shift: Destroyed information irreversibly elevates the Bayes-optimal loss, creating a transformation-dependent irreducible loss not recoverable even as D→∞.
The Information-Resolution Scaling Law is derived:
L(N,D,ρ)=NαA+DβB⋅ρ−ν+E+κ(1−ρ)μ
where ν governs statistical inefficiency, κ(1−ρ)μ encodes the information ceiling, and I(T(X);Y)=I(X;Y)0 is computable for canonical transformations.
Empirical Results: Evaluation Across Modalities
The empirical evaluation encompasses large-scale experiments across language (Llama-style Transformers on WikiText, OpenWebText, C4), vision (ViTs on ImageNet, ResNets on CIFAR-100), speech (Wav2Vec2 on LibriSpeech), and clinical time-series (MIMIC-IV). Bijective transformations—including random invertible linear and nonlinear mappings—show negligible deviation from baseline scaling exponents and loss curves, supporting strict invariance predictions.
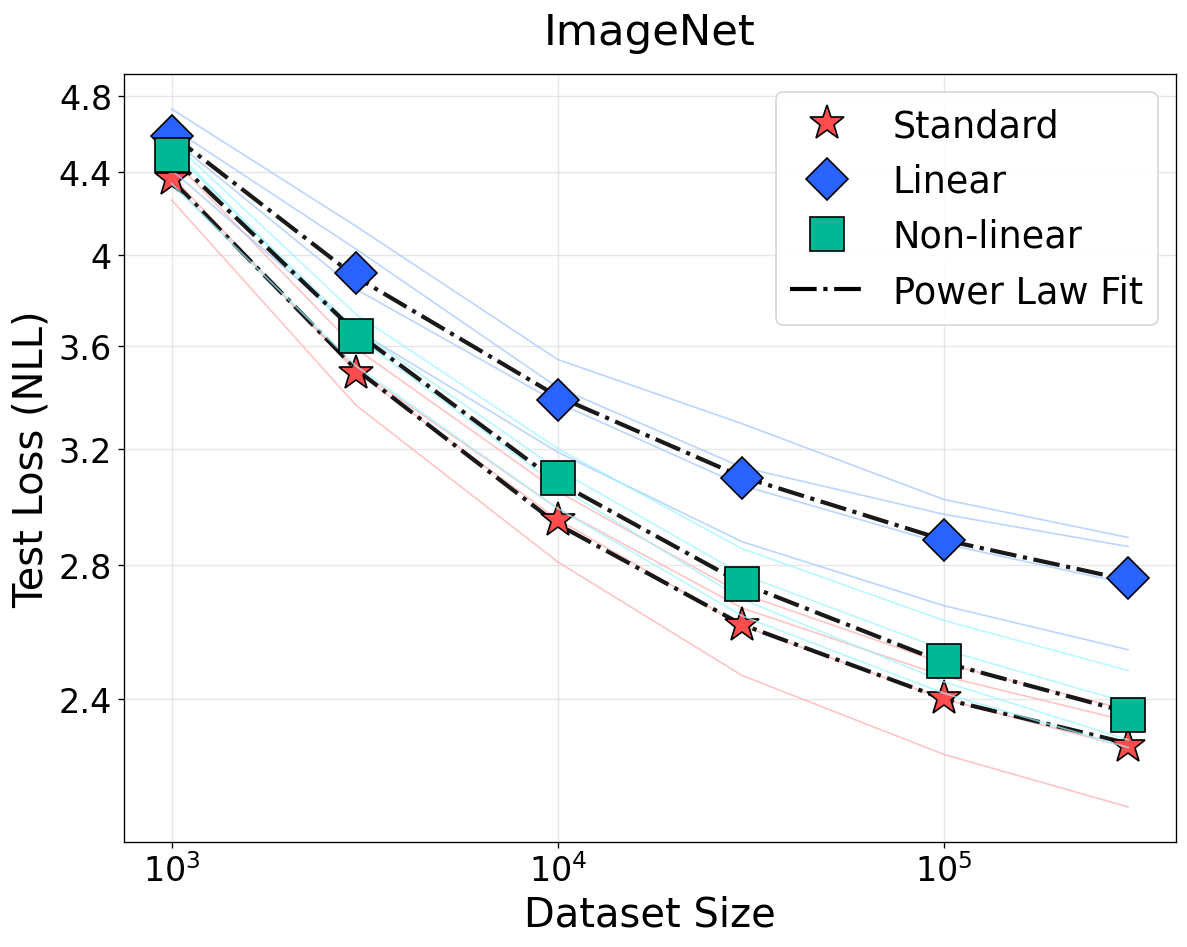
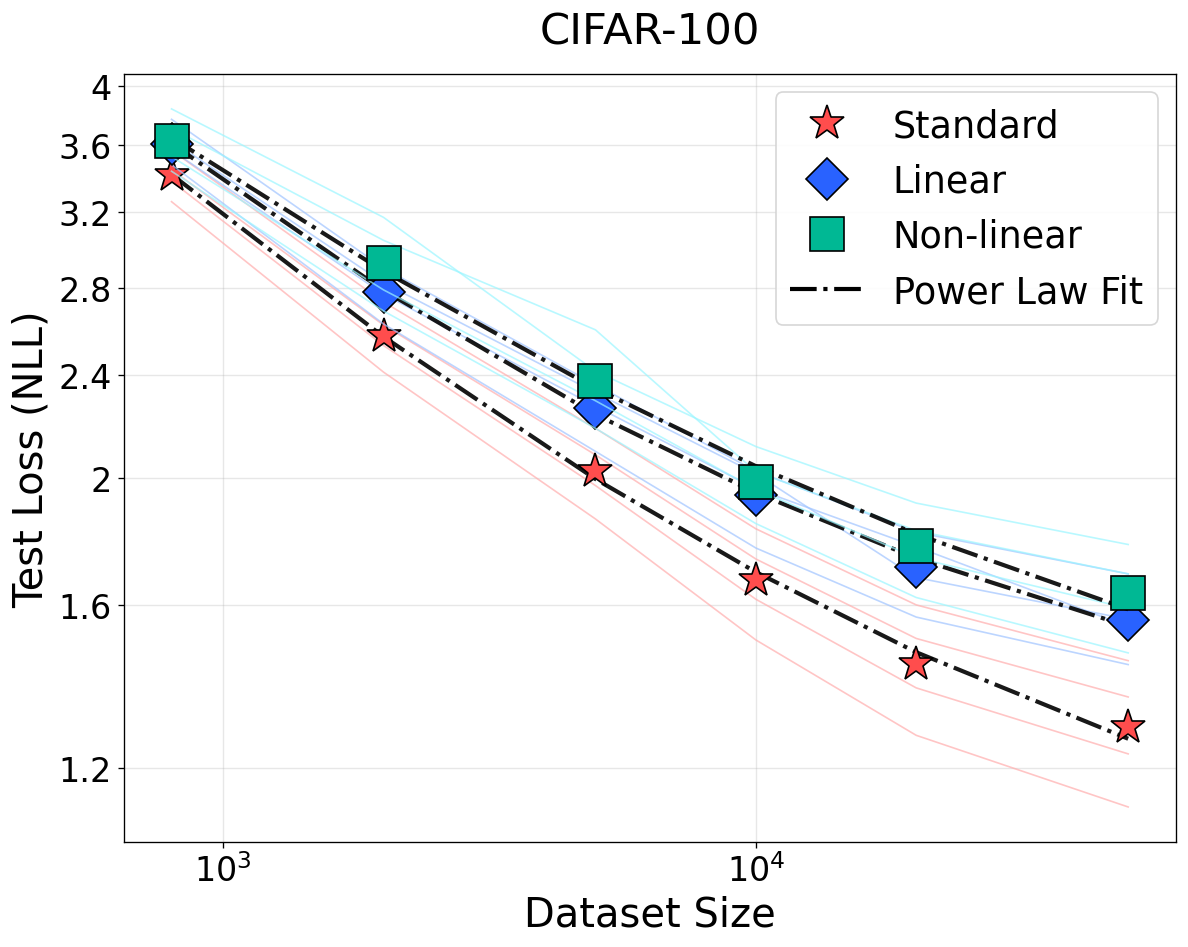
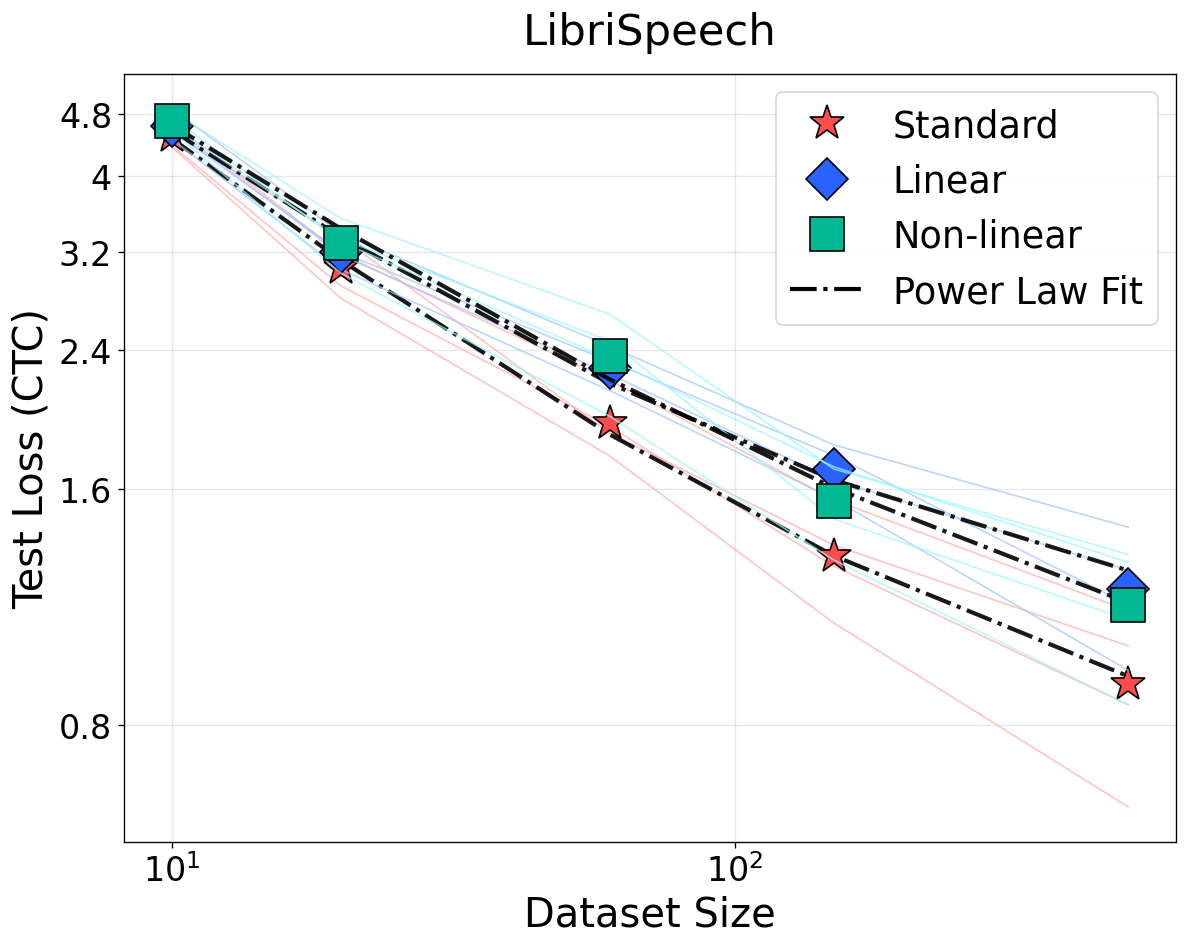
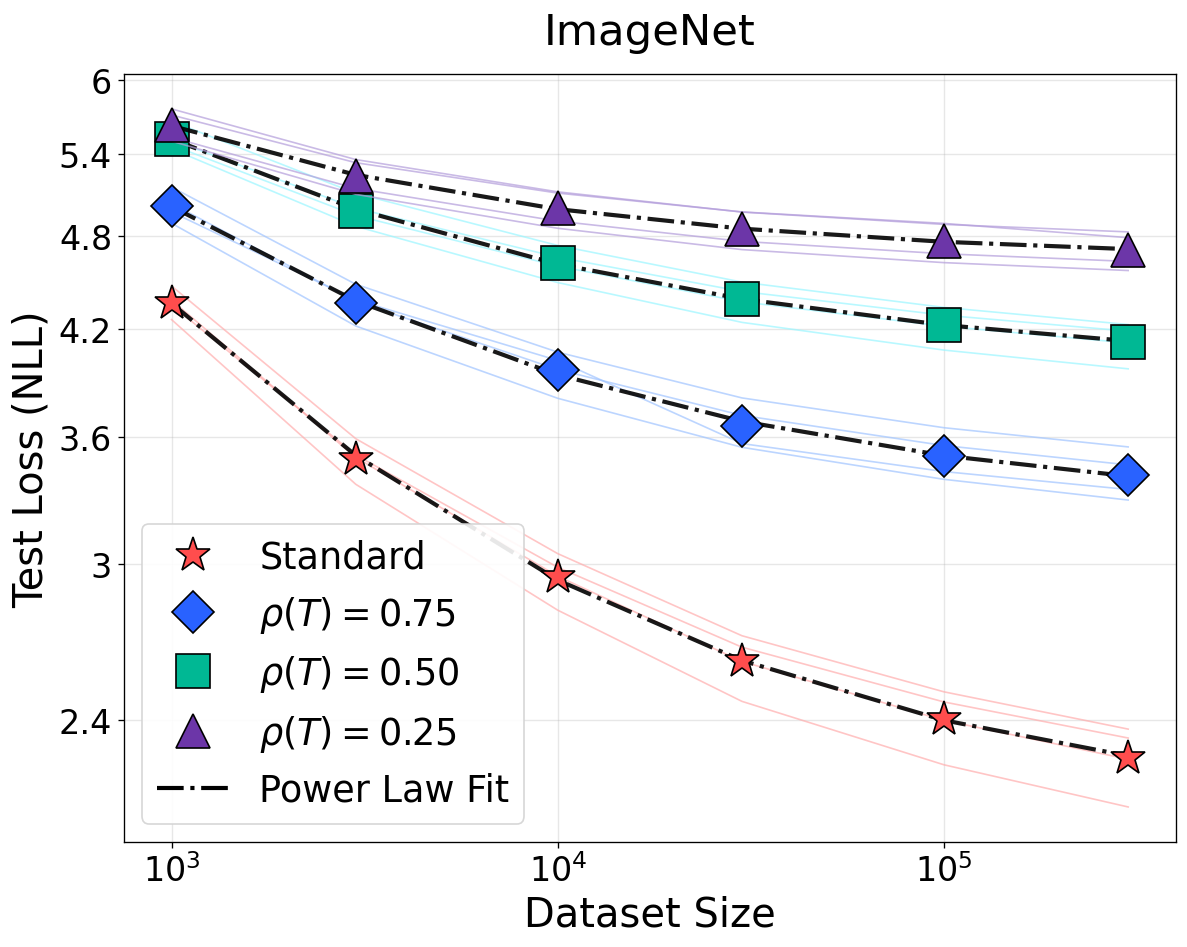
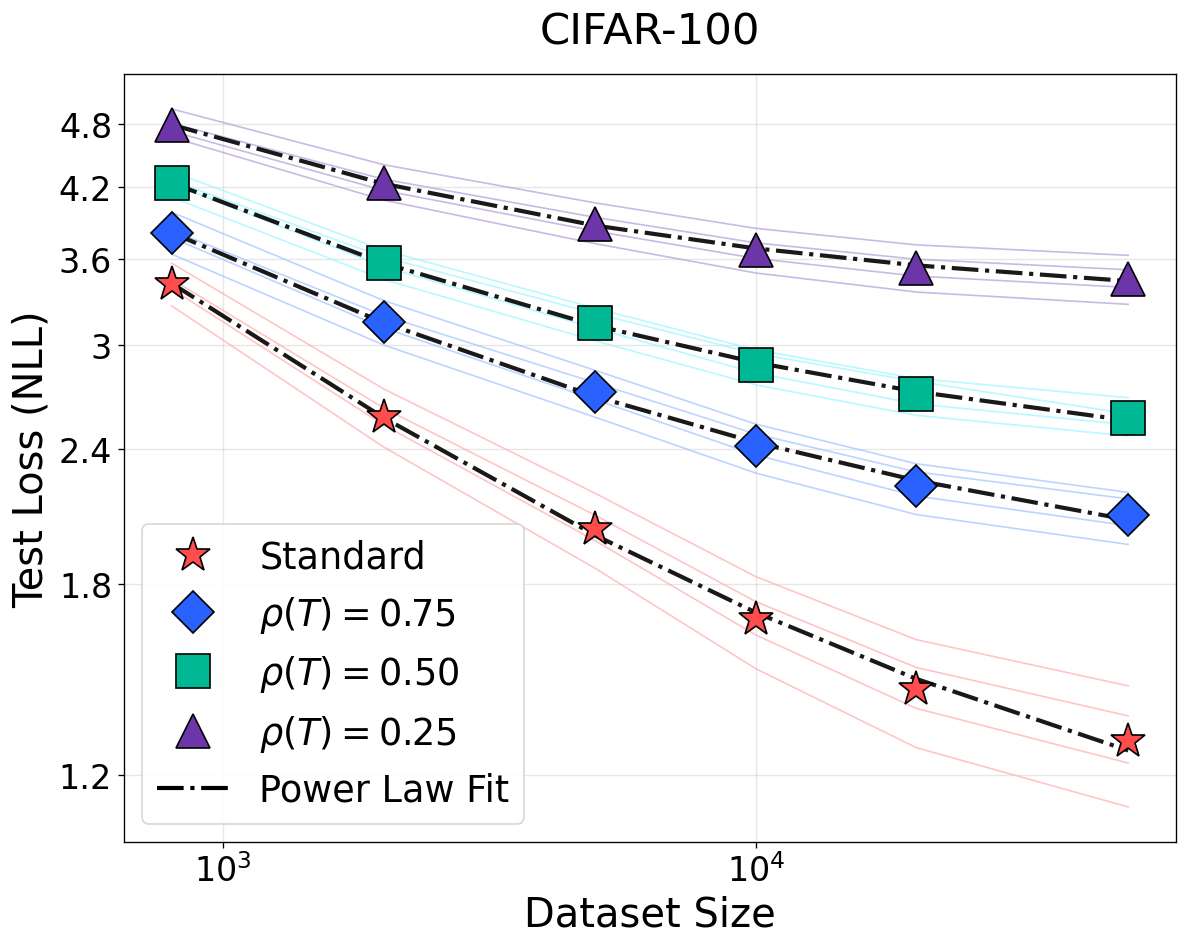
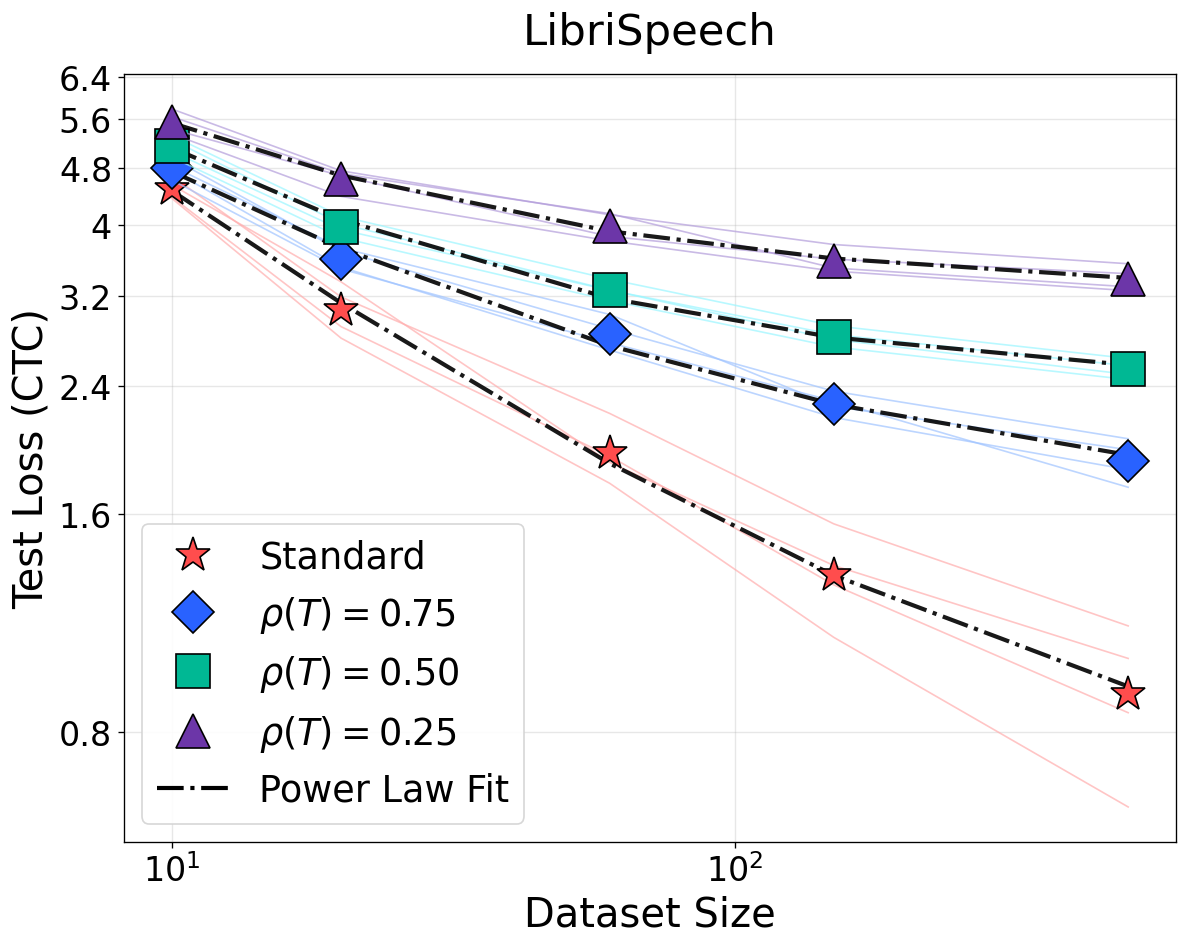
Figure 2: NSLs for vision and speech (ImageNet-1K/CIFAR-100/LibriSpeech). Bijective input transformations have no effect; low-rank projections (non-bijective) manifest loss elevation and weaker scaling.
For non-bijective transformations such as quantization and rank reduction, the predicted weakening of scaling (smaller I(T(X);Y)=I(X;Y)1) and rise in irreducible loss are observed. These results generalize not only across data domains but also modeling paradigms. This strictly contradicts prior empirical findings that quality- or density-modification can be universally modeled by reducing the effective sample size with a constant loss floor [subramanyam2025scaling, chen2025revisiting].
The law predicts how optimal model size shifts as a function of I(T(X);Y)=I(X;Y)2: under reduced information resolution, the compute-optimal allocation reduces model capacity and increases required data. Empirically, model capacity–test loss curves at constant I(T(X);Y)=I(X;Y)3 retain a U-shape, but the minimum shifts as predicted by I(T(X);Y)=I(X;Y)4.
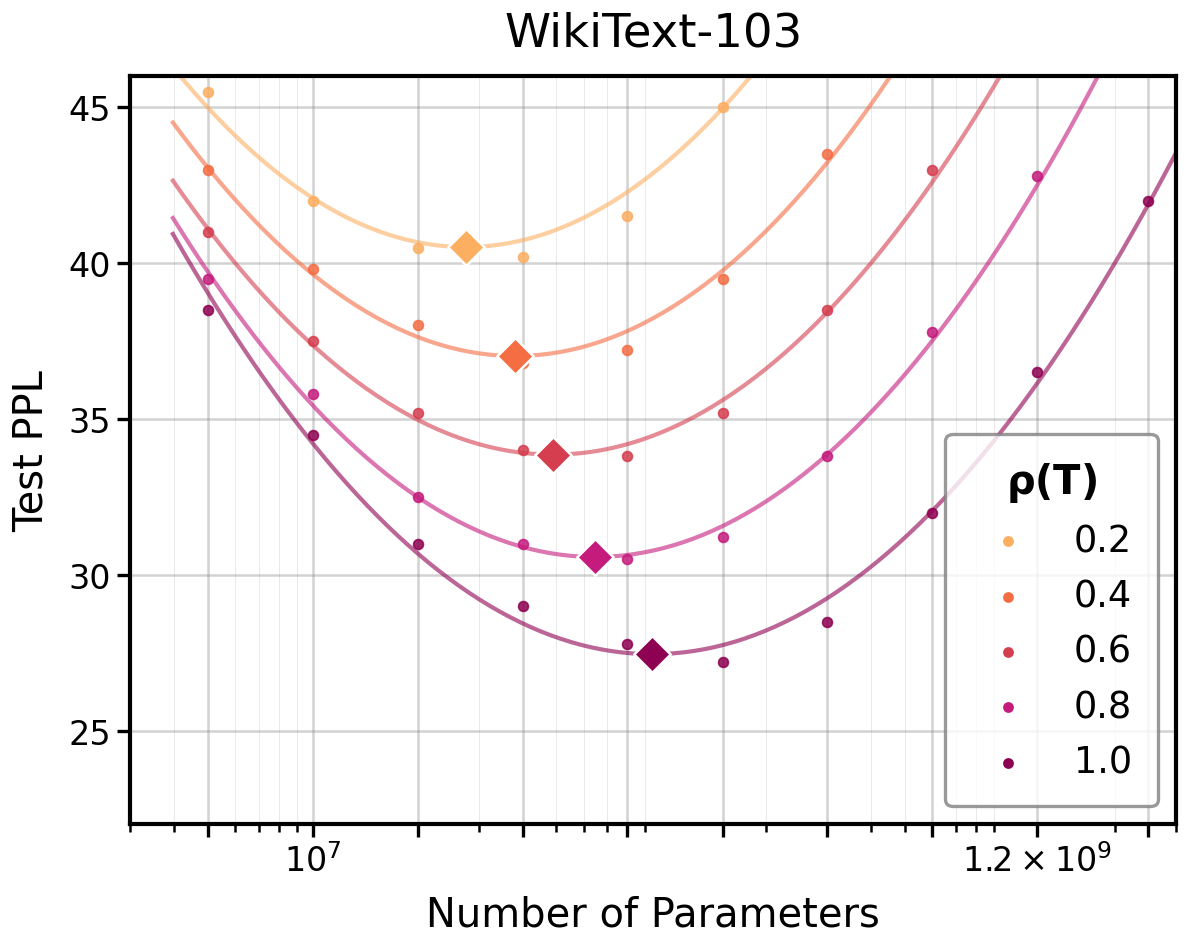
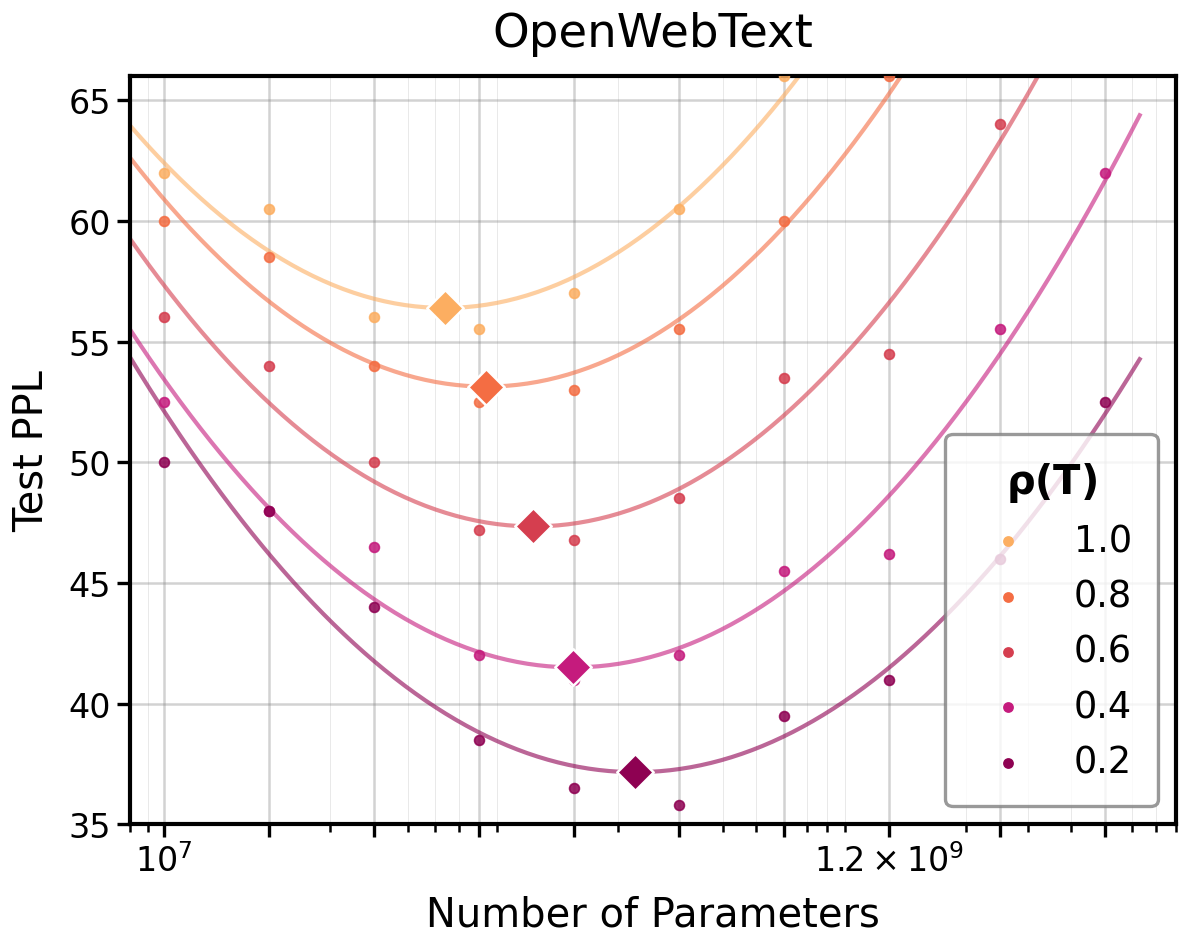
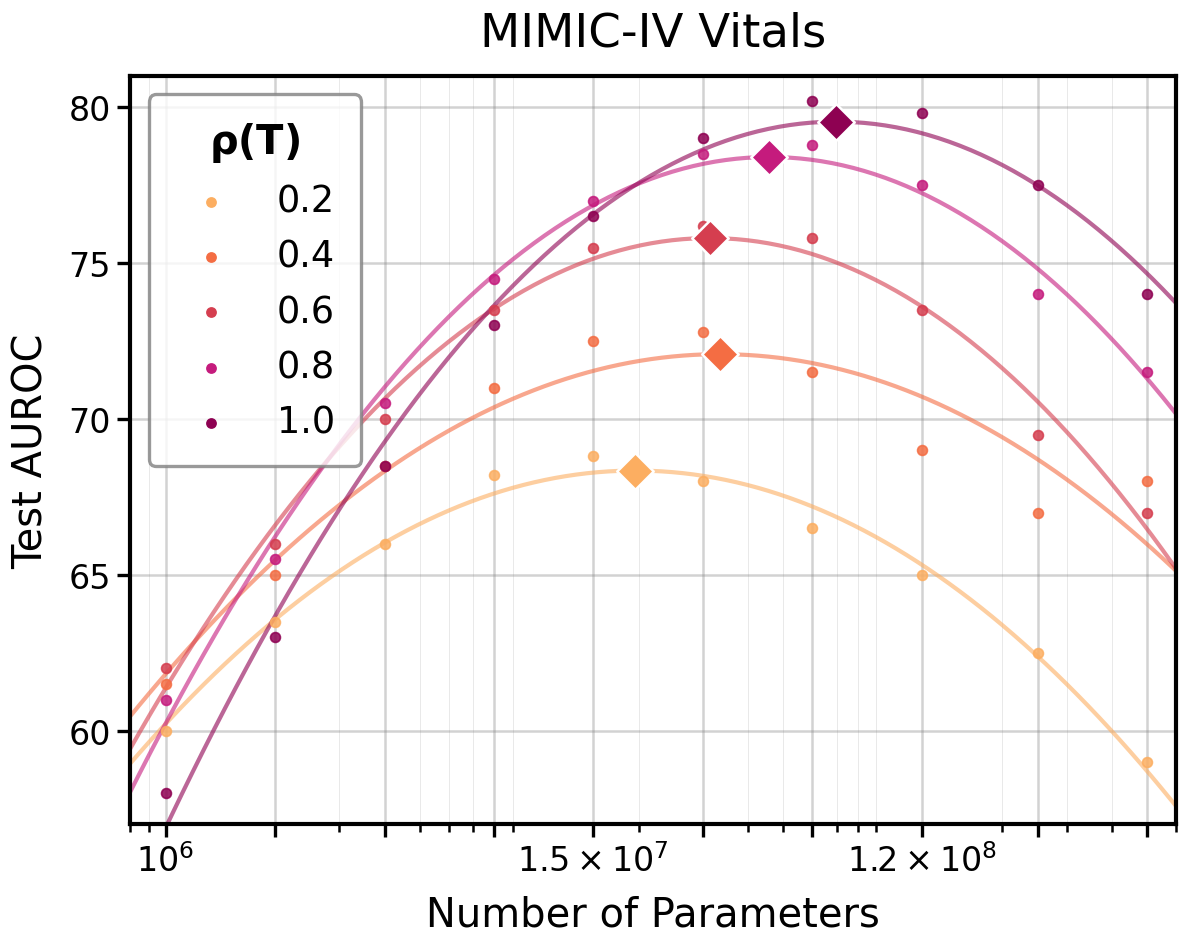
Figure 3: Empirical optimal model capacity as a function of I(T(X);Y)=I(X;Y)5, confirming reduction in optimal size as information resolution decreases.
This insight has high practical value for determining model/data trade-offs when dealing with degraded or low-precision data in fields such as medical records, compressed signals, or privacy-restricted corpora.
Robust Cross-Domain Scaling Prediction
The framework enables forecasting the scaling law in a new domain (e.g., medical EHRs or corrupted clinical time-series) from a source law fit in general text or clean data, by estimating only the associated I(T(X);Y)=I(X;Y)6. I(T(X);Y)=I(X;Y)7 are transformation-type parameters fit once on a source family, and I(T(X);Y)=I(X;Y)8 is determined analytically or via estimators (e.g., compression ratio, n-gram entropy) for the target domain.
(Table results and visualizations in Figure 4, Figure 5, Figure 6) confirm that this procedure recovers the data scaling exponent I(T(X);Y)=I(X;Y)9 to within L(N,D)≈AN−α+BD−β+E0 error and accurately predicts the elevation in irreducible loss L(N,D)≈AN−α+BD−β+E1, substantially outperforming baselines. Competing frameworks systematically underestimate the loss shift because they do not model transformation-dependent information destruction; their loss-floor assumption is empirically falsified.
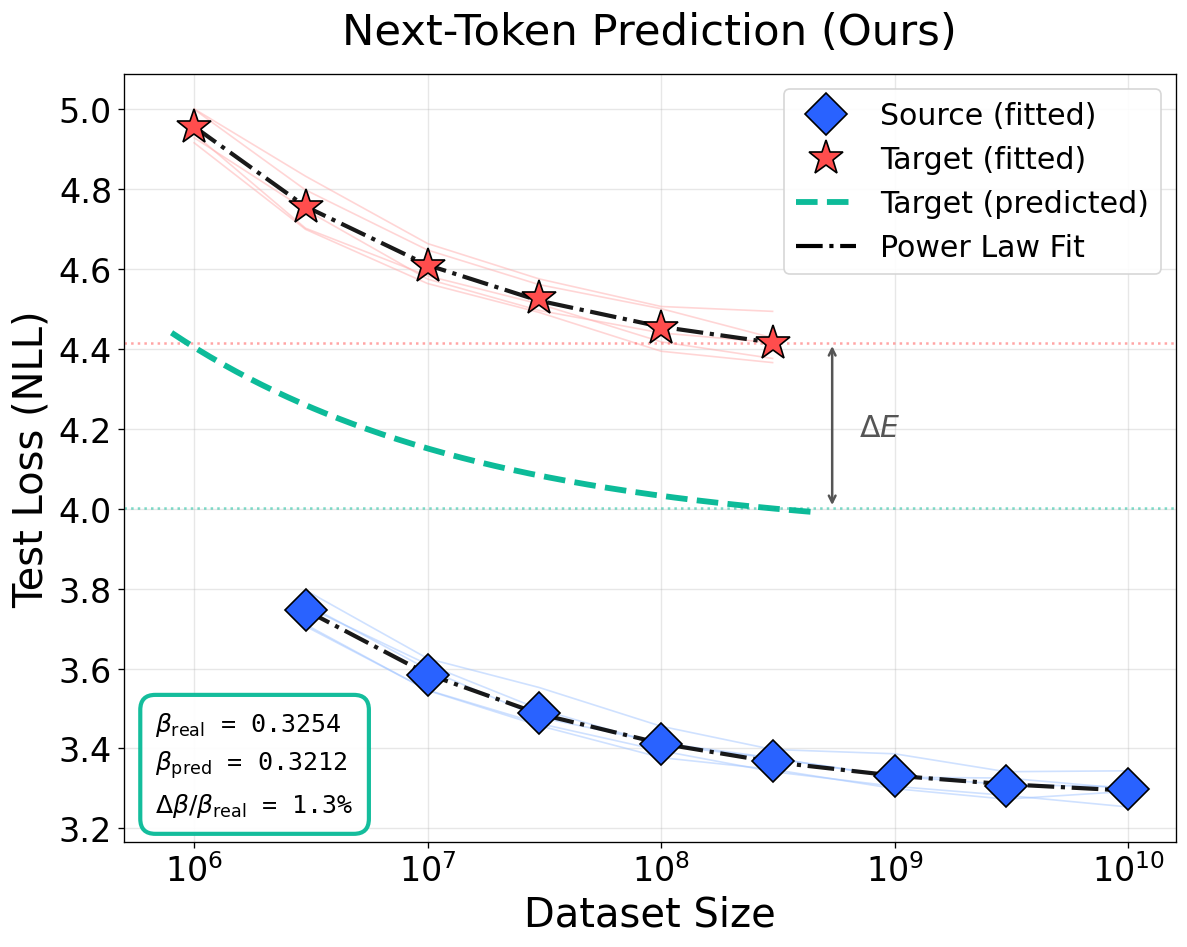
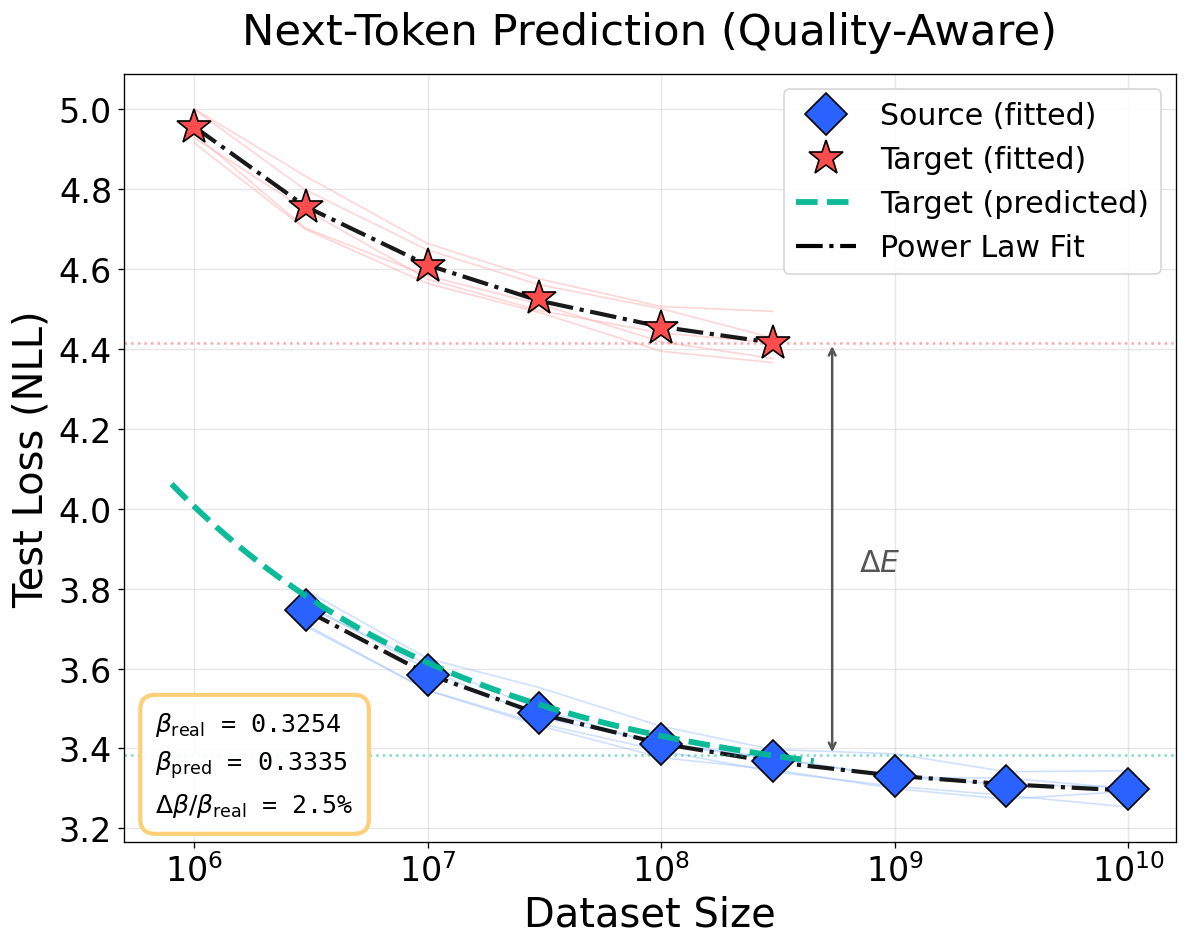
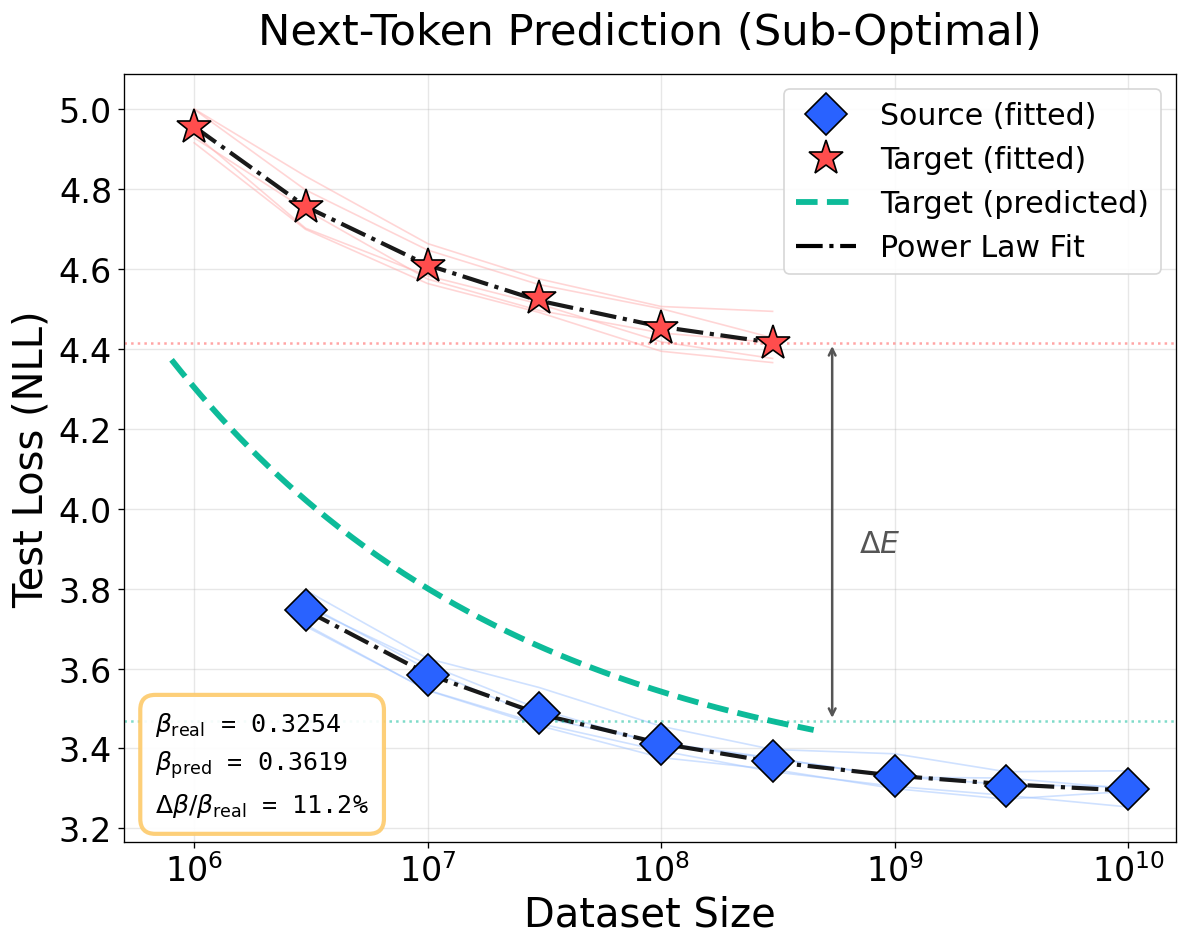
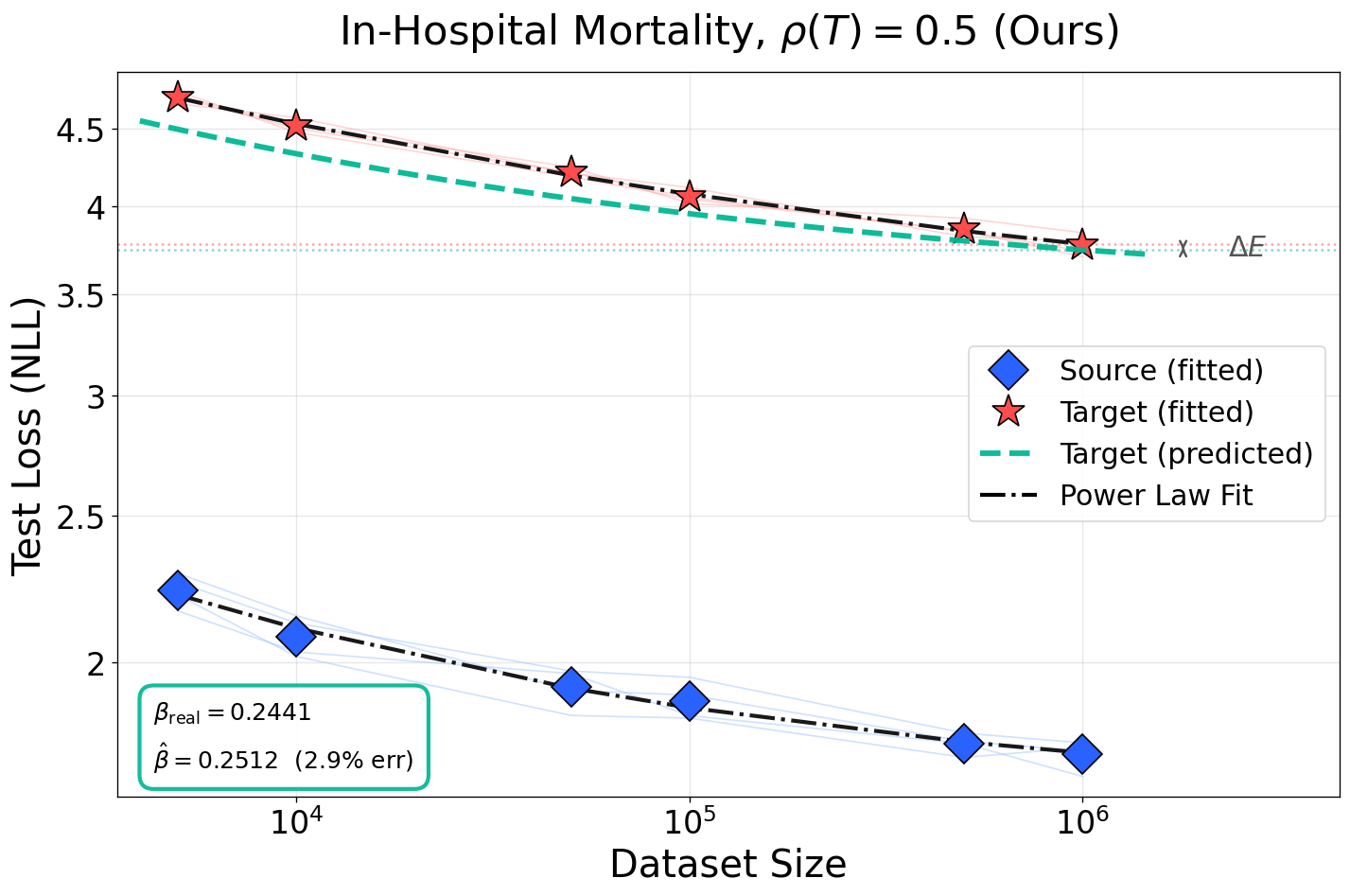
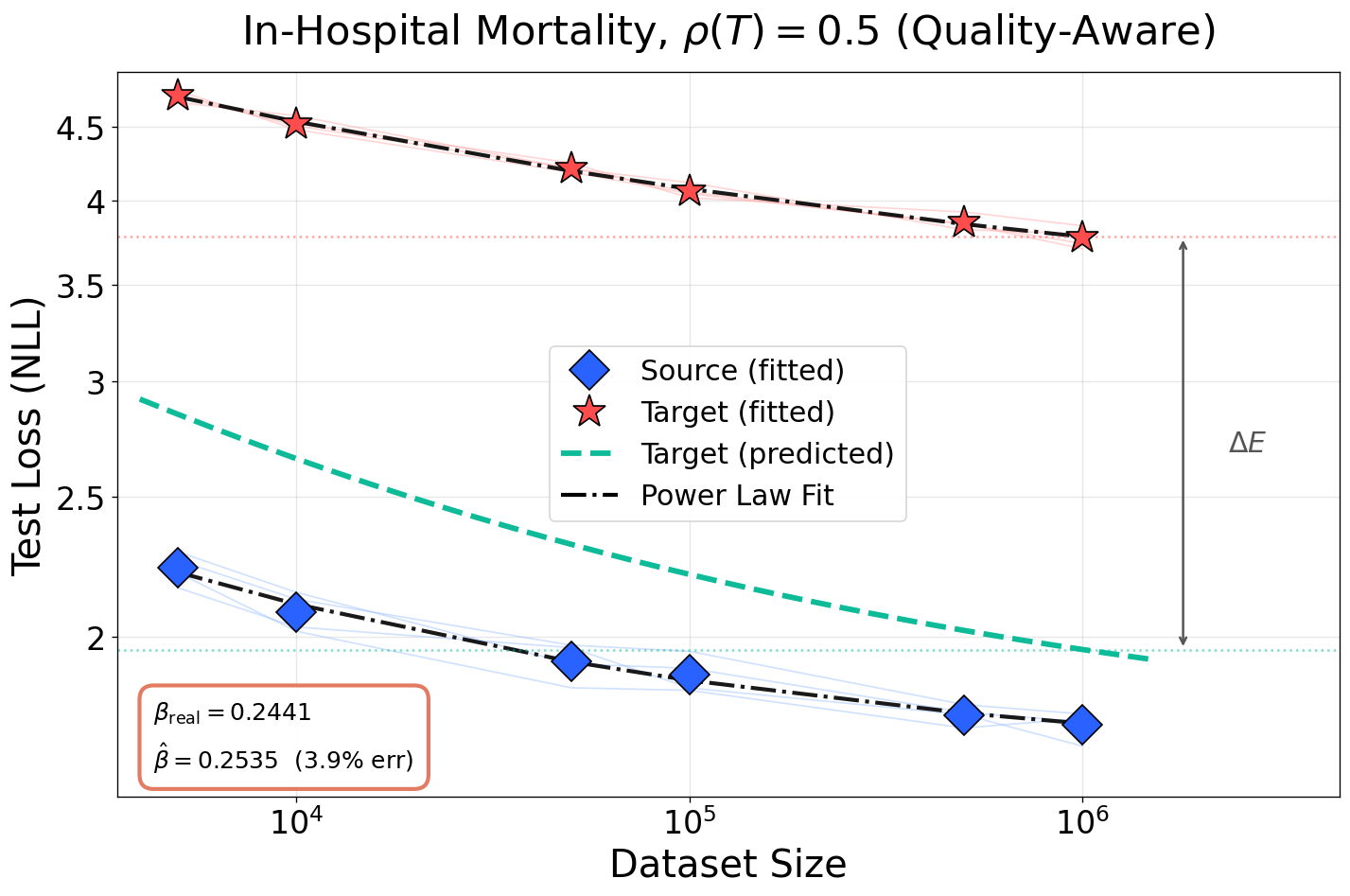
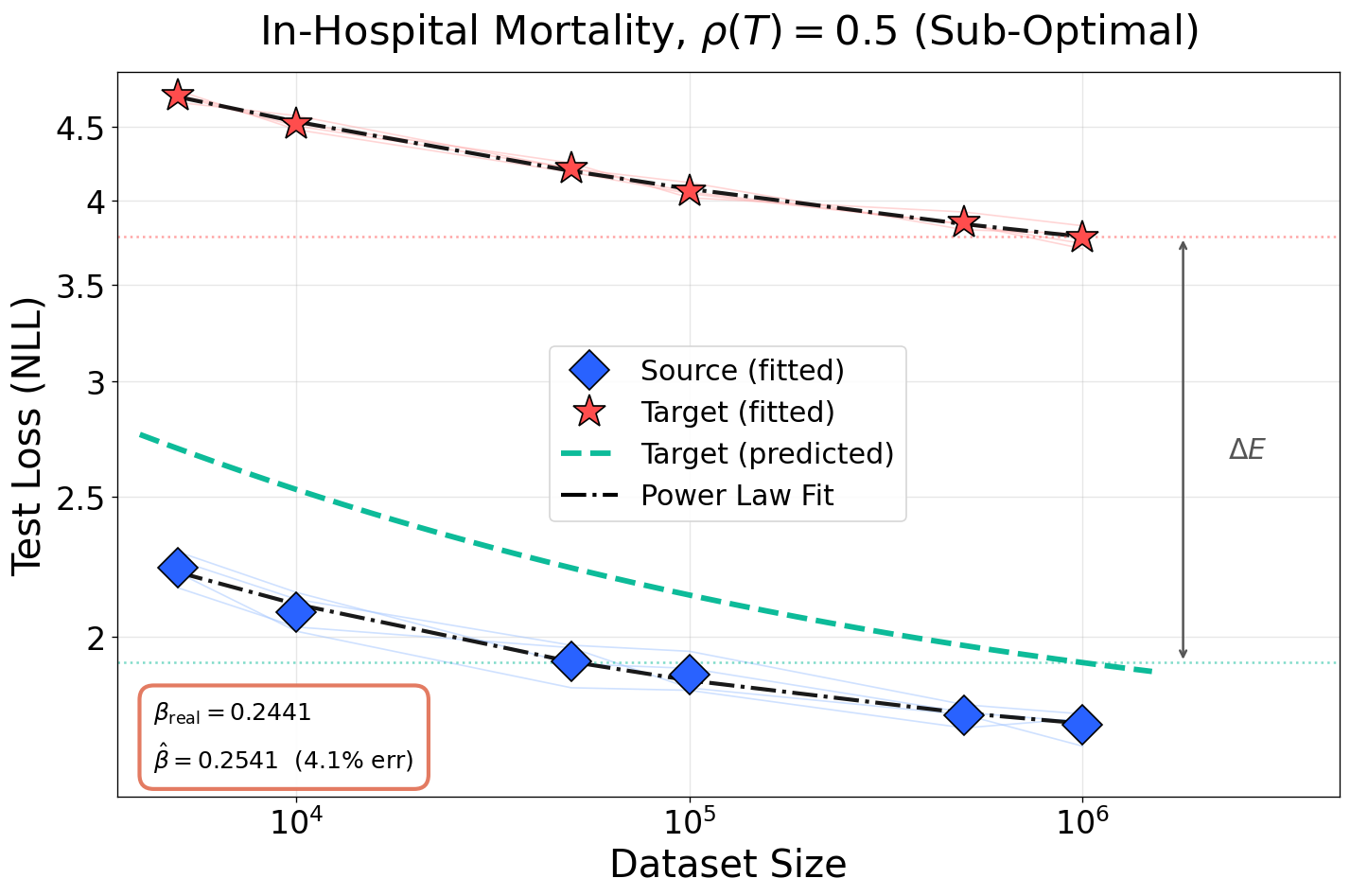
Figure 4: Visualization of cross-domain scaling predictions. Information-resolution model estimates both L(N,D)≈AN−α+BD−β+E2 and L(N,D)≈AN−α+BD−β+E3 with high fidelity as information loss or noise increases, outperforming quality-based baselines.
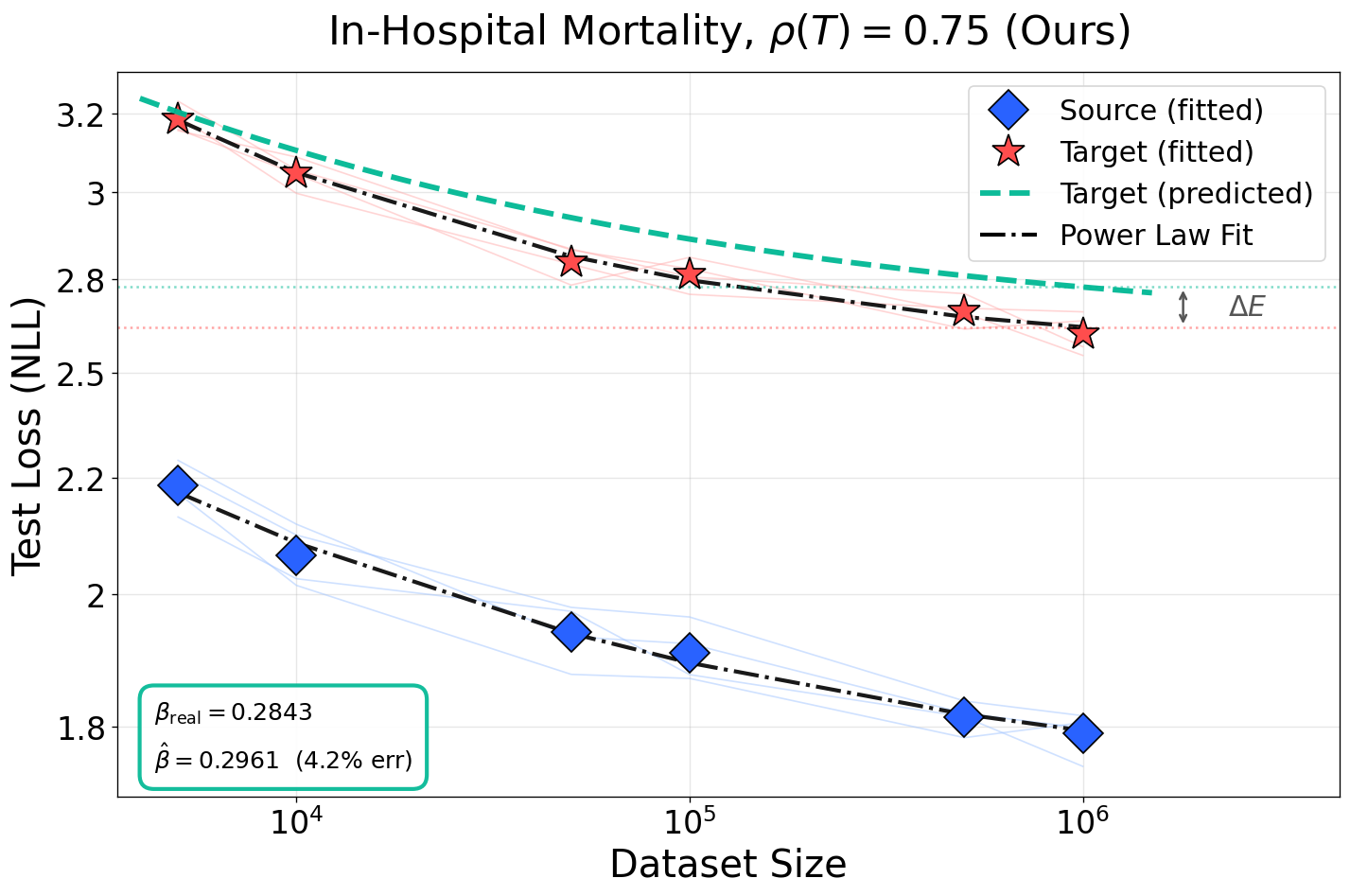
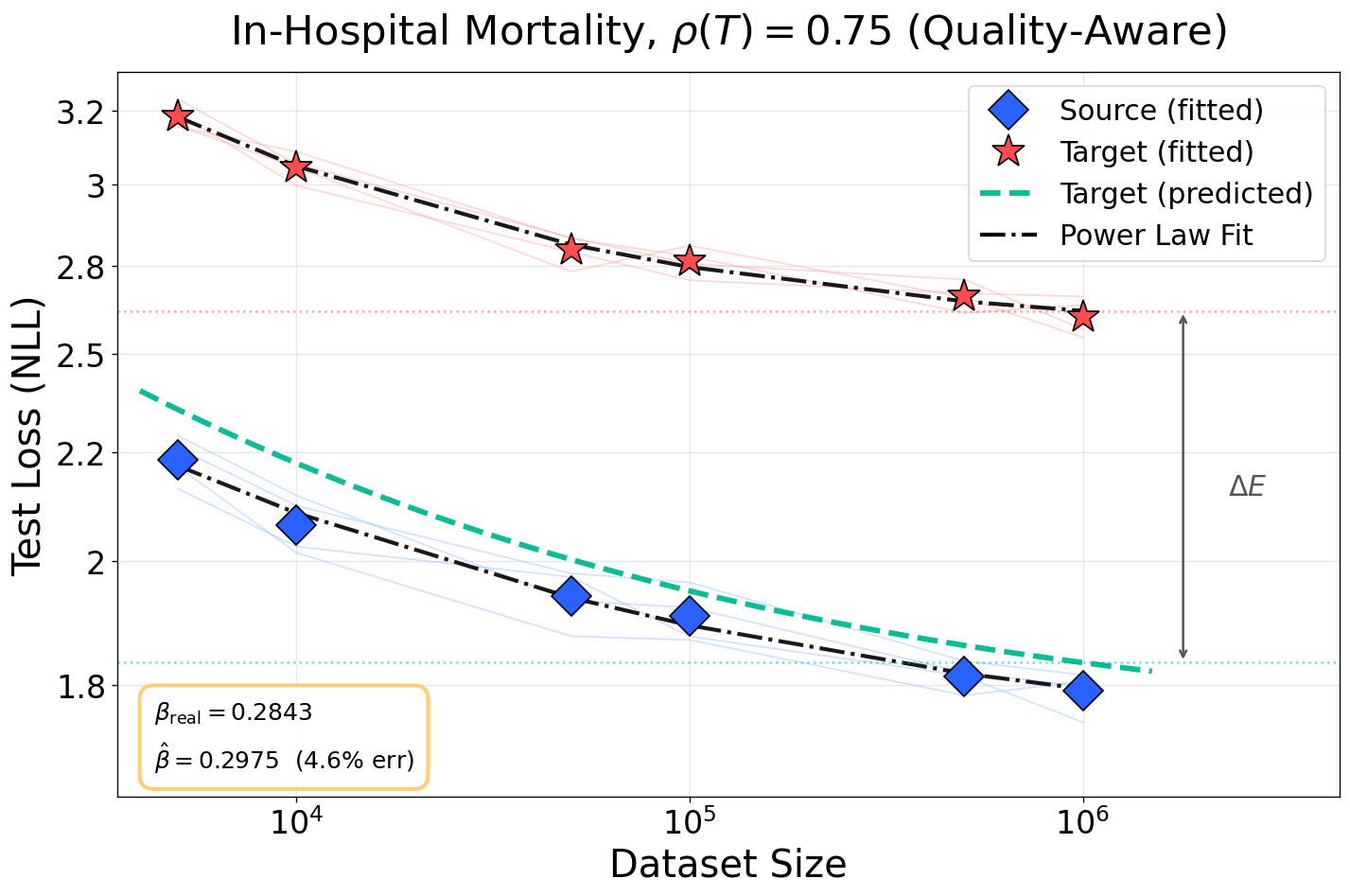
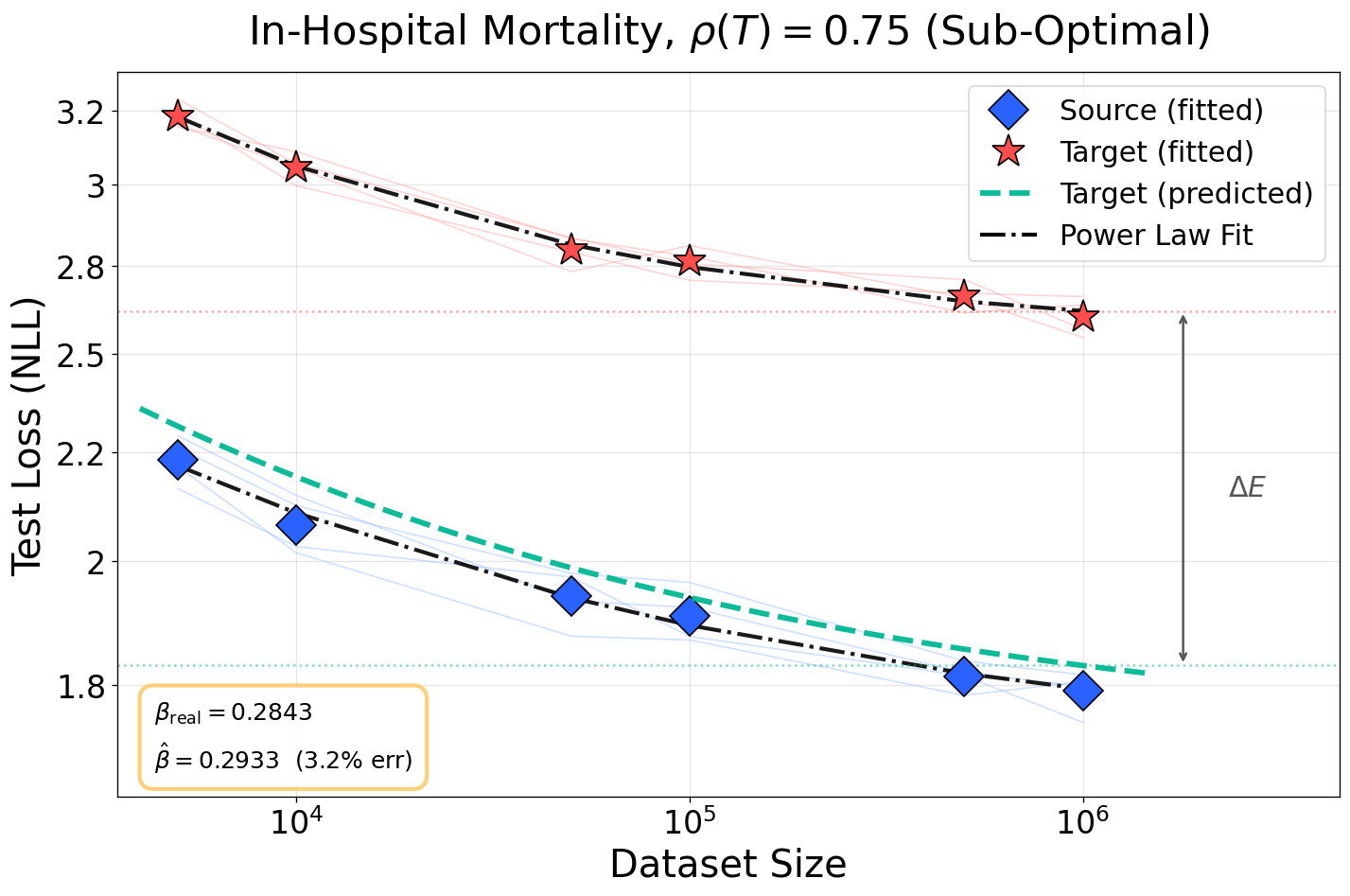
Figure 5: Prediction accuracy of scaling exponents and loss floor across noise levels for in-hospital mortality task. Competing baselines fail to model L(N,D)≈AN−α+BD−β+E4-induced irreducible loss.
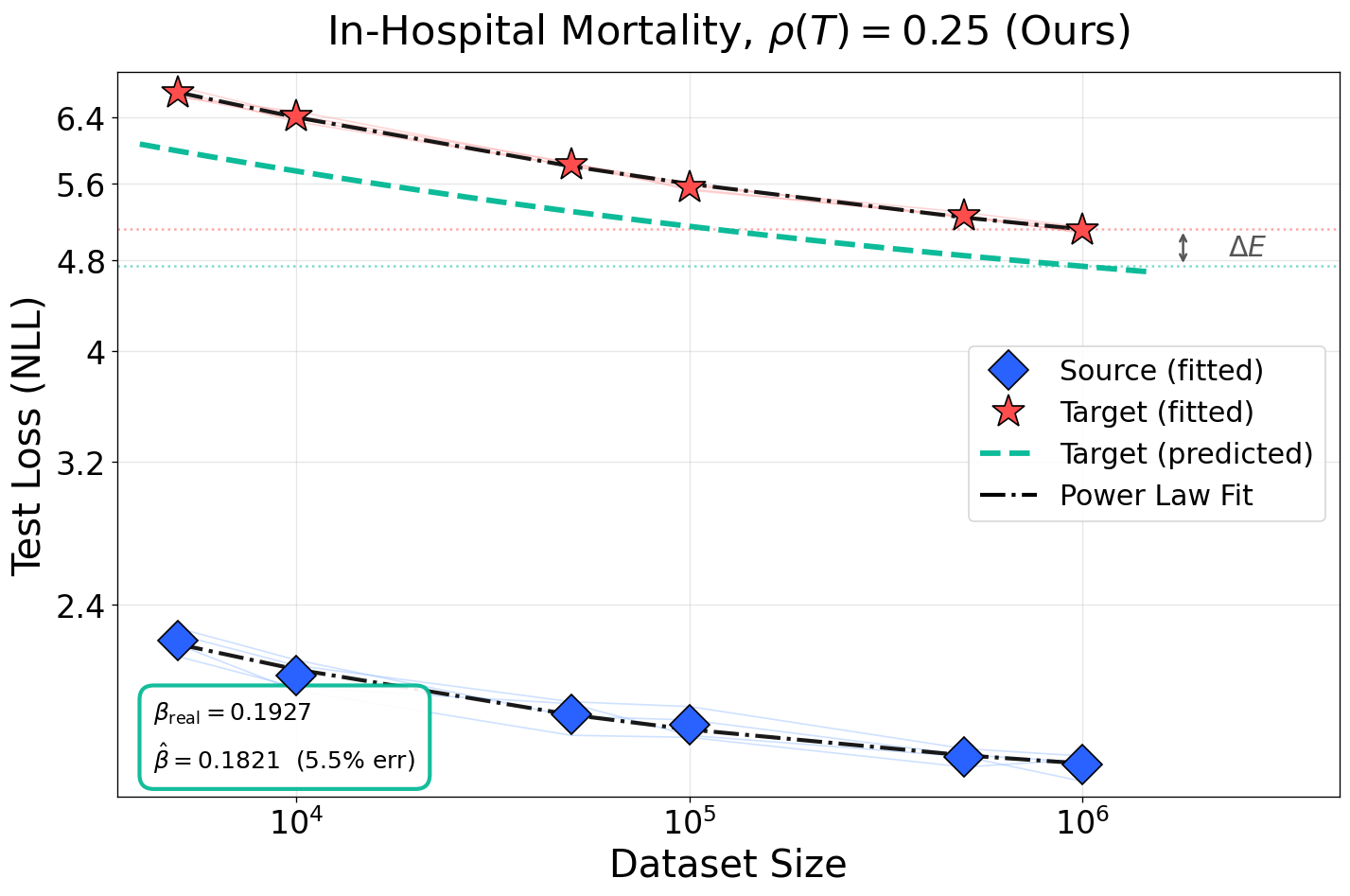
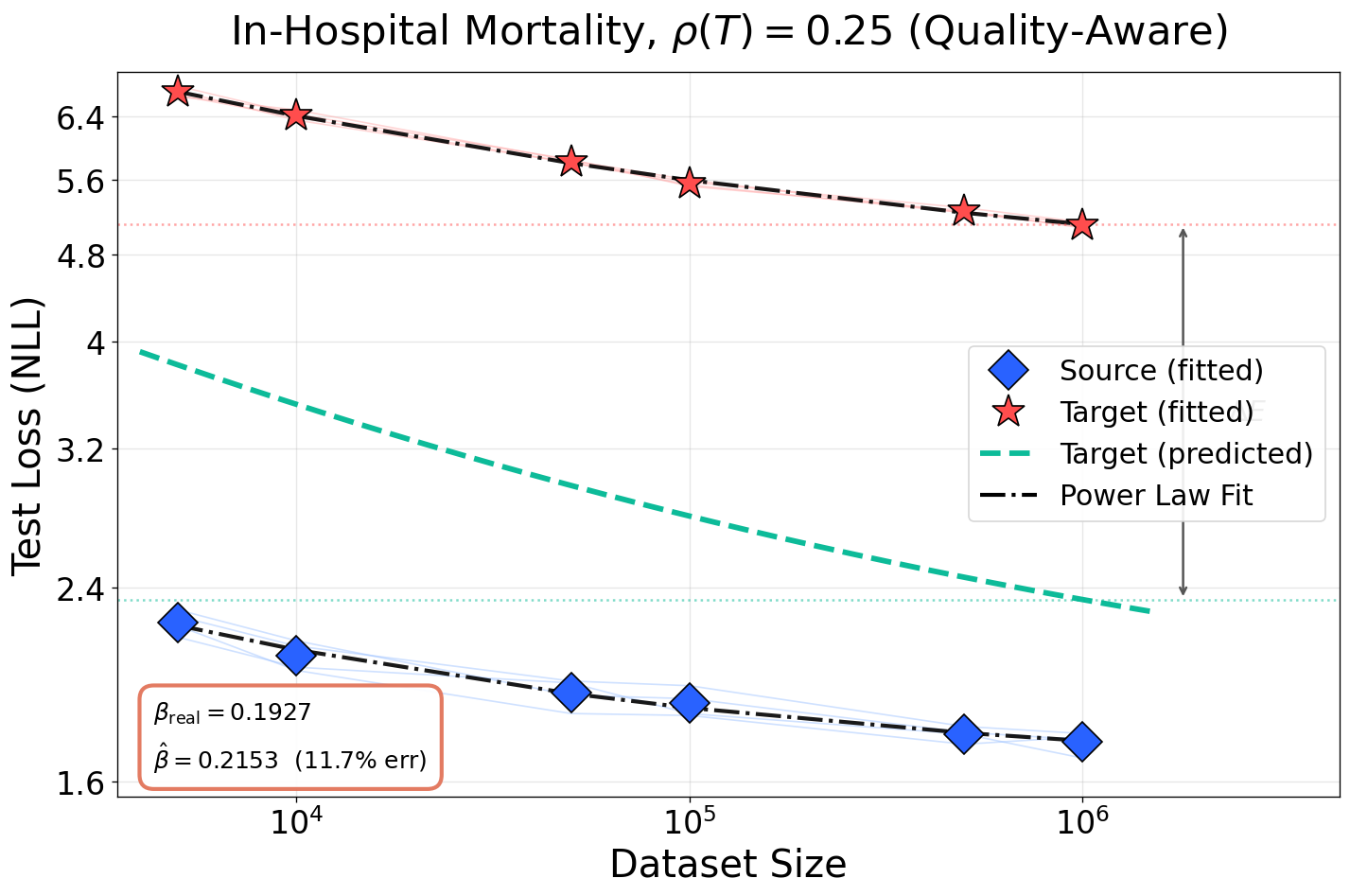
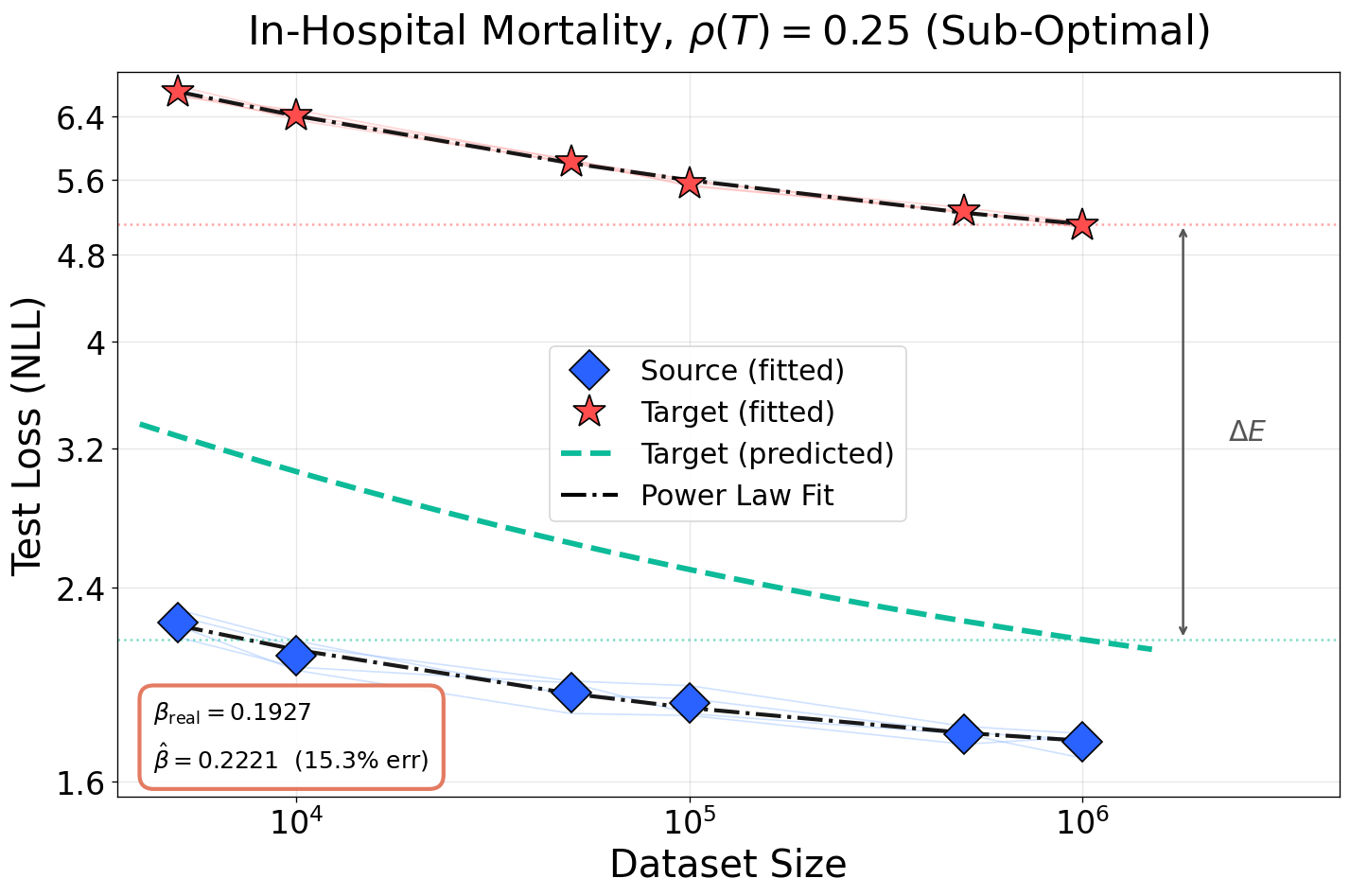
Figure 6: Accurate estimation of both scaling exponents and L(N,D)≈AN−α+BD−β+E5-dependent loss floor persists even at severe domain degradation; baseline methods break down.
Implications and Limitations
The main implication is that neural scaling law exponents and irreducible loss terms are strictly transferable across all invertible data transformations and degrade only as an explicit, computable function of the fraction of task-relevant information lost by L(N,D)≈AN−α+BD−β+E6. This refines the theoretical and practical understanding of scaling laws, enabling:
- Transfer of scaling law predictions to new domains with only an estimate of L(N,D)≈AN−α+BD−β+E7.
- Resource allocation and model selection for domains (such as privacy-restricted medical corpora) where it is infeasible to generate exhaustive parameter/data sweeps.
- Rapid estimation of efficient model/data scaling under domain shift, noise, quantization, or compression, with theoretical grounding.
The framework is limited in situations where the transformation is neither well-characterized nor approximately decomposable into information-losing steps whose L(N,D)≈AN−α+BD−β+E8 is estimable. Transferability of L(N,D)≈AN−α+BD−β+E9 is justifiable only for transformations closely related in statistical effect to those studied; generalization beyond single-modality and far-transfer tasks remains to be empirically confirmed.
Conclusion
This work establishes a rigorous theoretical and empirical foundation for understanding when and why neural scaling laws are invariant under changes in data representation—and when they are not. The introduction of information resolution ρ(T)=I(X′;Y)/I(X;Y)0 as the central axis along which scaling law generalization can be measured enables efficient transfer and forecasting of scaling laws, even in resource-constrained or previously unseen domains. Empirical analysis confirms the sufficiency of this theory to predict scaling exponents and irreducible loss under a wide spectrum of transformations, modalities, and tasks. Future directions include compositional estimation of ρ(T)=I(X′;Y)/I(X;Y)1 for highly structured domain transfers, embedding-based cross-modality generalization, and practical application in automated data curation pipelines.

