- The paper introduces a novel VHG framework that decouples problem validity from difficulty by incorporating an explicit verifier module.
- The methodology leverages a triadic self-play architecture with a setter, verifier, and solver to autonomously generate challenging and valid problems.
- Empirical results demonstrate significant improvements in solver accuracy on tasks such as indefinite integrals and general math through RL training.
Verifier-Backed Hard Problem Generation for Mathematical Reasoning
Introduction
The paper "Verifier-Backed Hard Problem Generation for Mathematical Reasoning" (2605.06660) addresses a foundational challenge in the development and training of LLMs for mathematical reasoning: the automatic generation of valid, non-trivial, and challenging problems without reliance on costly human experts or static datasets. The proposed VHG framework augments standard setter-solver self-play with a verifier module, thereby disentangling the notions of validity and difficulty to ensure that generated problems are both correct and challenging. This innovation establishes a new mechanism for scalable, autonomous problem generation suited for reinforcement learning (RL)-driven solver improvement and robust challenge dataset construction.
The VHG Methodology
Three-Party Self-Play Architecture
The VHG framework models problem generation as a triadic process with three distinct agents:
- Setter (Q): Proposes problem-reference solution pairs, leveraging an LLM conditioned on a diverse seed set to maximize both novelty and relevance in outputs.
- Verifier (V): Applies strict validity checks, instantiated as either a hard symbolic checker (e.g., SymPy for integrals) or a soft LLM-judge, to gate acceptance of the setter's outputs.
- Solver (S): Attempts to solve the accepted problems, with its accuracy informing the empirical hardness of each instance.
A critical design change from two-party self-play is that the setter's reward is strictly conditioned on verifier acceptance. This mitigation against reward hacking ensures that the increase in difficulty does not arise from pathological or malformed problems.
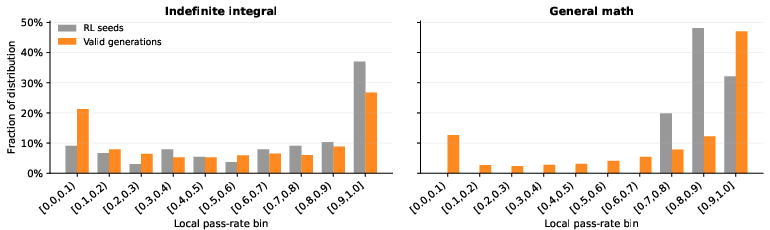
Figure 1: Difficulty distributions of seed problems and verifier-valid VHG generations. Lower Pass@1 bins indicate harder problems.
Hard and Soft Verifier Instantiations
For domains amenable to symbolic checking, the hard verifier achieves near-perfect validity. For more open-ended mathematical reasoning, the framework falls back to a carefully engineered LLM-based soft verifier, which, while not absolutely reliable, extends applicability beyond closed-form settings.
The verifier's integration enables precise separation of problem validity from empirical solver difficulty. The setter is thus optimized to “fail” the solver only via legitimate difficulty, not via ambiguity or ill-posedness.
Experiments and Empirical Results
Efficacy of Generated Problems
VHG training produces a distributional shift toward harder problems while maintaining verifier validity. Figure 1 demonstrates that, compared to seed distributions, VHG’s generated and accepted problems exhibit a substantial mass in the lowest Pass@1 bins (hardest for solvers), in stark contrast to prior approaches where difficulty is often entangled with validity failures.
Generated challenge sets are consistently difficult, as evidenced even for stronger models (Qwen3-8B, 14B, 32B), which fail a nontrivial fraction of these problems at Pass@1 and Pass@8 metrics.
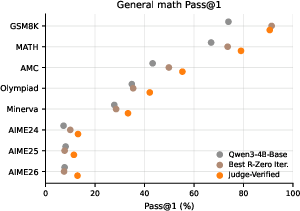
Solver Improvement After RL
VHG-generated data, when used for RL training, leads to robust improvements:
Verifier as Enabler for True Hardness
Analyses of the learning dynamics show that the setter first optimizes for validity (i.e., becomes adept at not being invalid), before optimizing for true hardness. This is unprecedented in self-play approaches without a validity gate, where reward hacking typically predominates.
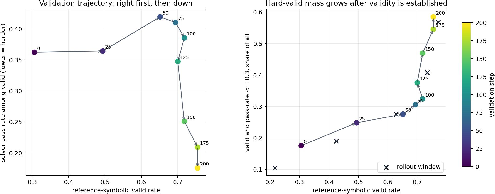
Figure 3: Learning trajectory of the hard-verifier setter on indefinite integral. Validity improves first; later, solver pass rate decreases while the valid-and-hard fraction rises. Lower solver pass rate indicates harder generated problems.
The hardness-validity analysis confirms that VHG reliably populates hard bins with valid problems, while consensus or R-Zero baselines collapse in these regions due to an inability to confront the validity-difficulty trade-off explicitly.
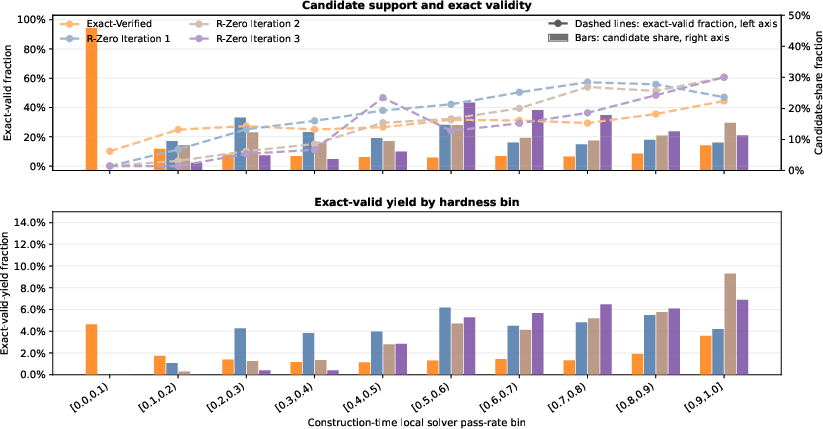
Figure 4: Hardness-validity bins for indefinite integral. Bars show candidate share (top) and exact-valid yield (bottom); dashed curves show exact-valid fraction. Lower pass-rate bins are harder.
Distributional and Diagnostic Insights
Further inspection via pass-rate heatmaps and validation trajectories corroborates that later training checkpoints produce a larger proportion of hard, valid generations. This effect is reproducible across both hard- and soft-verifier regimes.
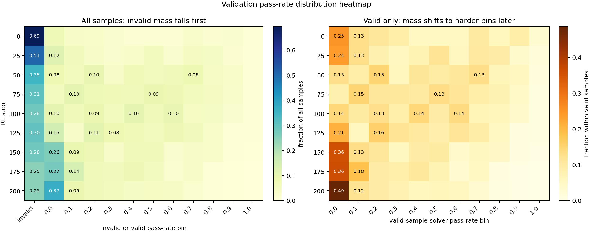
Figure 5: Validation pass-rate heatmap for the hard-verifier setter. Rows correspond to validation checkpoints and columns to local solver pass-rate bins. Accepted validation samples move toward harder bins as training proceeds.
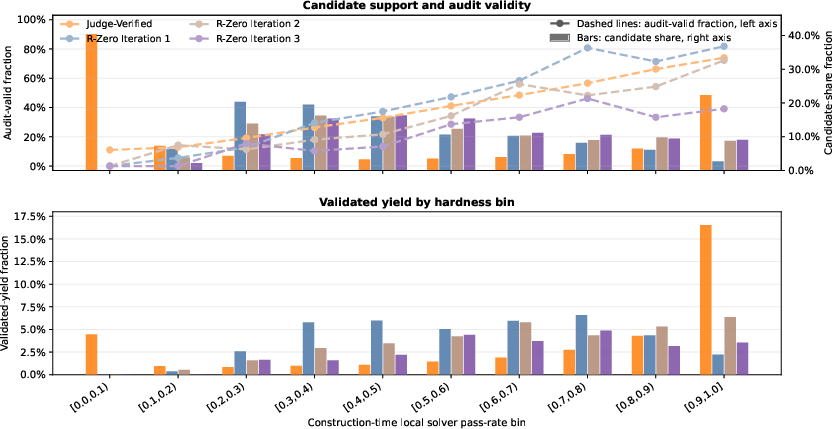
Figure 6: Hardness-validity profile for general math under model-based verification. Candidates are binned by construction-time local solver pass rate.
Implications and Theoretical Considerations
The VHG paradigm establishes a step-function improvement over prior generator-centric approaches. The key insight is the necessity of a reward oracle that separates correctness from challenge: only a process that explicitly encodes ground-truth correctness can reliably push LLMs to their real limits.
In practical terms, VHG demonstrates that synthetic supervision for mathematics does not need to be bottlenecked by human effort or static data. The gating effect of verifiers means that weak model generations (e.g., from a 4B model) can produce high-quality, challenging data that transfers even to much larger models, yielding a “weak-to-strong” curriculum.
Theoretically, the framework spotlights the role of explicit verifiability as a precondition for genuine difficulty-seeking self-improvement in LLMs; without such gating, reward hacking undermines the learning signal.
Future Directions
VHG’s effectiveness is tightly bounded by the strength of the verifier. In closed domains (e.g., integrals), hard verifiers provide a clean, trusted foundation; in open domains, future work must focus on improving soft-verifier robustness and auditability, possibly via bootstrapped, scalable, or ensemble-based validation circuits.
Further research should investigate generalized verifier-based reward schemas for scientific discovery tasks, formal mathematics, and the synthesis of broader benchmarks. Techniques for verifiable, interpretable, and auditable reward functions will become central to trustworthy weak-to-strong learning paradigms.
Conclusion
The VHG framework demonstrates that reliable and scalable hard problem generation in mathematical reasoning is attainable by integrating an explicit verifier into the self-play training loop. Empirically, it yields harder, valid problems, enables stronger solvers through data-driven RL, and resists reward hacking that plagues prior approaches. These advances position verifier-centric frameworks as essential infrastructure for ongoing autonomous progress in LLM mathematical reasoning research.