- The paper presents a novel gradient-space harmonization strategy for multi-reward diffusion RL, avoiding destructive weighted-sum aggregation.
- It introduces per-reward advantage decomposition and quadratic programming to align gradients across specialist and general tasks effectively.
- Empirical results demonstrate that MARBLE improves multi-dimensional performance with near-baseline training speed and minimal overhead.
Multi-Aspect Reward Balancing for Diffusion Reinforcement Learning: An Expert Analysis
Introduction
The proliferation of reinforcement learning (RL) techniques for aligning diffusion models to human preferences has catalyzed a shift in generative model alignment protocols, specifically for improving multidimensional image attributes such as aesthetics, text-adherence, and compositional rigor. However, most existing multi-reward RL strategies either rely on training distinct specialist models, naive weighted reward aggregation, or intricately scheduled curriculum sequences. These approaches exhibit inefficient scaling, lack transfer across reward axes, and succumb to inconsistent or adversarial update directions due to inherent sample-level sparsity and misalignment of reward signals.
MARBLE (Multi-Aspect Reward BaLancE) (2605.06507) targets this core inefficiency by reframing the optimization from reward-space scalar aggregation to gradient-space harmonization, leveraging explicit per-reward advantage decomposition, quadratic programming-based update direction harmonization, and scalable amortization for practical deployment in high-capacity diffusion RL settings.
Motivating Failure Modes in Multi-Reward Diffusion RL
Standard practices reduce multi-reward alignment to weighted-sum scalar objectives, with R(x)=∑kwkRk(x). Empirically, this aggregation dilutes reward-specific credit assignment, particularly given the specialist sample structure—most rollouts are highly informative for one reward axis and irrelevant for the others. Consequently, this results in gradient anti-alignment with certain rewards, with the weighted-sum update actively interfering with task performance on specialist axes in up to 80% of mini-batches, as empirically quantified.
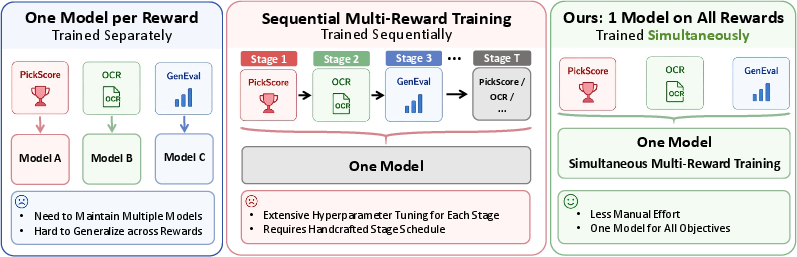
Figure 1: Comparison of multi-reward training paradigms—MARBLE enables scalable, unified training across reward dimensions without the overhead of model proliferation or handcrafted schedules.
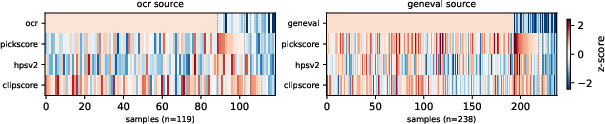
Figure 2: Analysis of sample-level specialist structure, showing concentration of reward-specific advantages and the scarcity of all-positive samples per batch.
The MARBLE Framework
Per-Reward Advantage Decomposition
Rather than aggregate rewards at the loss or sample level, MARBLE maintains independent per-reward advantage estimators, Ak(x), normalized within prompt groups. Each sample contributes a reward-specific NFT (Noise-Free Training) loss with a distinct interpolation coefficient, allowing reward-relevant credit assignment and preserving supervision granularity.
Gradient Harmonization in Gradient Space
For every mini-batch, per-reward gradients gk are computed, normalized, and harmonized via quadratic programming. The optimization seeks a simplex-constrained coefficient vector α∗ such that the update direction d∗=∑kαk∗g^k is the minimum-norm point in the convex hull of the normalized gradients. This guarantees non-destructive updates that are well-aligned across rewards, eliminating negative cosine alignment with any individual task.
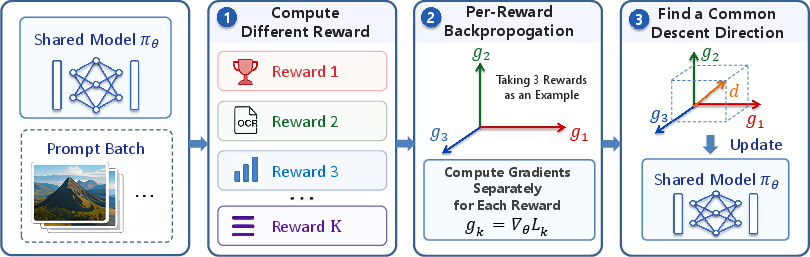
Figure 3: Overview of MARBLE—per-reward gradients are harmonized via a QP solver into a balanced update, applied with KL regularization decoupled from reward alignment.
Amortized Harmonization and EMA Smoothing
To reduce computational overhead, MARBLE amortizes gradient harmonization. The QP is solved every N steps to refresh balancing coefficients, which are then applied as convex combinations of advantages per sample in subsequent steps, exploiting the affine structure of NFT. EMA smoothing of the coefficients with decay ρ=0.7 (validated empirically) further dampens mini-batch fluctuation, ensuring stable long-term balancing even when transient batches lack reward signal for certain axes.
Empirical Results
On large-scale SD3.5-Medium with five orthogonal rewards (three general and two specialist), MARBLE simultaneously improves all reward dimensions with a single unified model, matching or surpassing handcrafted schedulers and outperforming direct scalarization—particularly on specialist axes such as OCR and GenEval.
MARBLE's harmonized updates convert worst-reward gradient cosines from negative (anti-aligned) to positive in all measured mini-batches, with order-of-magnitude reductions in variance across reward alignments.
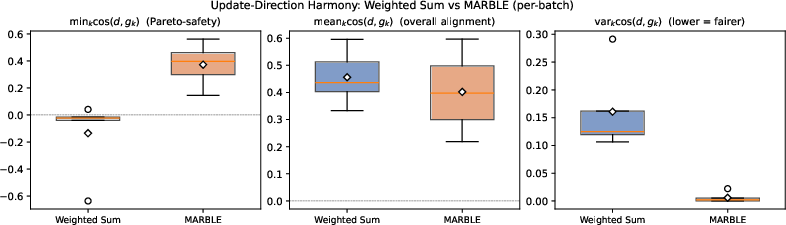
Figure 4: Update-direction harmony—worst-case alignment (minimum cosine) across reward gradients remains positive under MARBLE, unlike the standard weighted-sum approach.
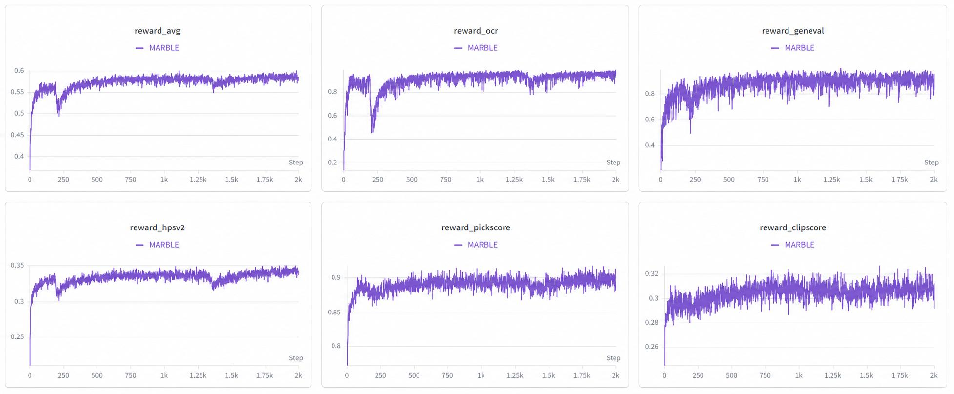
Figure 5: All reward curves (general and specialist) are improved concurrently during joint MARBLE training.
Additionally, MARBLE achieves competitive or better performance on held-out image quality metrics (e.g., Aesthetic Score, ImageReward, UniReward).

Figure 6: Visual comparison between MARBLE and baseline methods, demonstrating MARBLE's superior ability to jointly satisfy text rendering, attribute, and compositional constraints.

Figure 7: Qualitative results illustrate MARBLE's preservation of both specialist and general visual quality attributes in a unified model.
Efficiency-wise, with coefficient amortization, MARBLE attains 0.97× the training speed of the traditional scalarized baseline, with only a modest increase in GPU memory usage and no need for manually tuned schedules.
Ablations and Sensitivity Analysis
Removing gradient normalization destabilizes coefficient estimation, leading to optimization failure. Fixed-coefficient baselines (e.g., αk=0.2) result in imbalanced reward progression, rapidly saturating easy axes but under-optimizing specialist dimensions. Solving for α at every step without amortization increases cost and high-frequency instability.
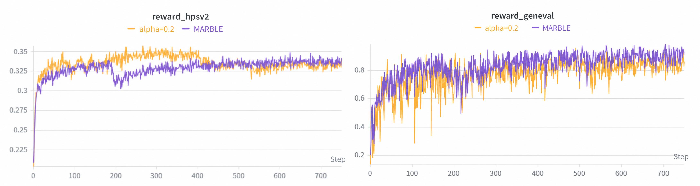
Figure 8: Learning curves comparing uniform and adaptive coefficients—uniform weighting under-optimizes specialist rewards.
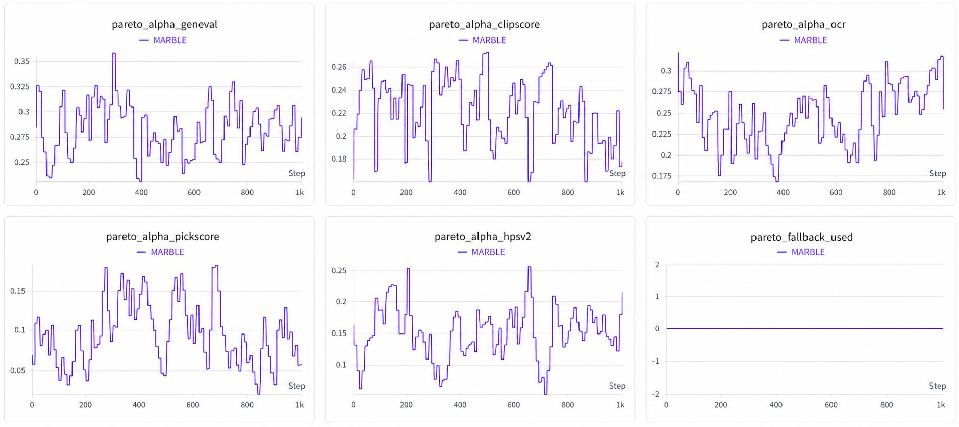
Figure 9: Adaption of balancing coefficients Ak(x)0—allocation shifts toward specialist rewards as dictated by optimization difficulty.
MARBLE's coefficient dynamics reflect dynamic reallocation toward harder-to-optimize objectives, and EMA smoothing (Ak(x)1) delivers the best empirical balance between adaptivity and optimization stability.
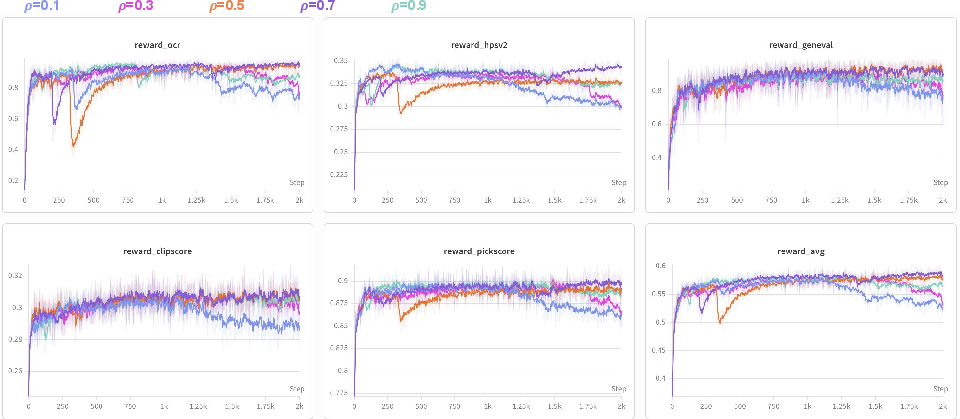
Figure 10: EMA decay sensitivity—Ak(x)2 is optimal for balancing update stability and responsiveness.
Theoretical and Practical Implications
MARBLE demonstrates that effective multi-reward diffusion RL requires gradient-space balancing, not ad hoc reward-space aggregation or curriculum design. The explicit separation of reward-specific and KL gradients, sample-level per-objective credit assignment, and scalable harmonization are critical for unifying general and specialist objectives in generative modeling. The adoption of MARBLE reduces reliance on laborious manual tuning, enables direct and robust multi-dimensional model alignment, and suggests that future model alignment practices should favor gradient harmonization strategies, particularly as reward sets become richer and more heterogeneous.
Extensions and Future Directions
Empirical evidence from MARBLE is limited to image generation, but the theoretical apparatus is extensible to video and generative world models, where reward heterogeneity is more pronounced (e.g., temporal consistency, physical plausibility). Scaling balancing mechanisms to settings with tens or hundreds of objectives remains a fertile direction, as does exploring harmonization in alignment tasks beyond vision, such as multimodal RLHF.
Conclusion
MARBLE (2605.06507) establishes a scalable, principled gradient-space framework for multi-reward diffusion RL, mitigating sample-level specialist dilution and destructive reward interference inherent in standard approaches. MARBLE's core contributions—per-reward advantage decomposition, quadratic-program-based update harmonization, and amortized coefficient smoothing—yield substantial empirical and practical gains, charting a blueprint for the next generation of multi-objective model alignment in high-capacity generative frameworks.