ParetoSlider: Diffusion Models Post-Training for Continuous Reward Control
Abstract: Reinforcement Learning (RL) post-training has become the standard for aligning generative models with human preferences, yet most methods rely on a single scalar reward. When multiple criteria matter, the prevailing practice of ``early scalarization'' collapses rewards into a fixed weighted sum. This commits the model to a single trade-off point at training time, providing no inference-time control over inherently conflicting goals -- such as prompt adherence versus source fidelity in image editing. We introduce ParetoSlider, a multi-objective RL (MORL) framework that trains a single diffusion model to approximate the entire Pareto front. By training the model with continuously varying preference weights as a conditioning signal, we enable users to navigate optimal trade-offs at inference time without retraining or maintaining multiple checkpoints. We evaluate ParetoSlider across three state-of-the-art flow-matching backbones: SD3.5, FluxKontext, and LTX-2. Our single preference-conditioned model matches or exceeds the performance of baselines trained separately for fixed reward trade-offs, while uniquely providing fine-grained control over competing generative goals.







































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces ParetoSlider, a way to train image and video generators so you can smoothly move a “slider” between competing goals—like making a picture look more realistic versus more like a sketch—without retraining the model each time. Instead of locking the model into one fixed balance during training, ParetoSlider teaches a single model to cover the whole range of good trade‑offs (called the Pareto front) and to follow whatever balance you ask for at generation time.
The main questions the authors ask
The authors set out to find out:
- Can one model be trained to handle many different, often conflicting goals at once and let users smoothly pick their favorite balance later?
- How should we train such a model so it really listens to the user’s preferences and doesn’t get “hijacked” by one goal dominating the others?
- Does this work across different tasks—making images from text, editing existing images with instructions, and making videos from text?
How the method works (in everyday language)
Think of making hot chocolate with two preferences: “more chocolatey” vs “more milky.” If you pick one recipe during training (say, 70% chocolate, 30% milk), you’re stuck with that taste forever. ParetoSlider does something different:
- It gives the model a “preference vector” (like a recipe card) that says how much to care about each goal, for example 60% realism, 40% sketchiness. This vector is shown to the model while it learns and also when it generates images or videos.
- During training, the model tries lots of preference settings and learns how to respond to each one. This lets it learn the whole curve of best possible trade‑offs, known as the Pareto front. On that front, you can’t improve one goal without hurting another.
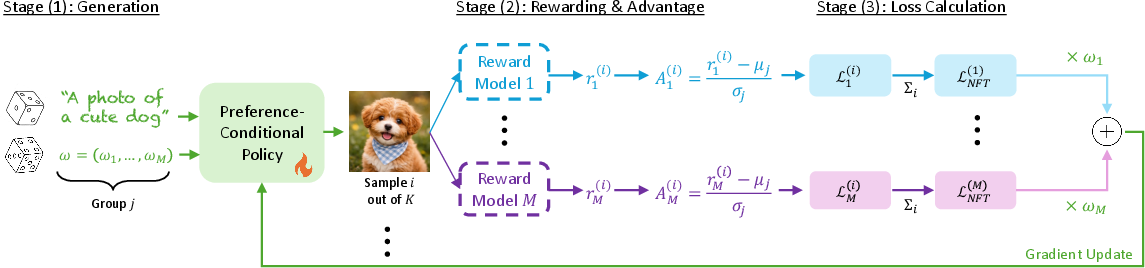
To make this efficient and stable, they build on a fast reinforcement learning (RL) post‑training method for diffusion/flow models called DiffusionNFT. Here’s the training recipe in simple steps:
- Make small batches (“groups”) of samples for the same prompt and the same preference vector. For example, generate K different images for “a cat on a couch” with “70% realism, 30% sketch.”
- Score each sample with several reward models—one per goal (e.g., realism score, sketch score, prompt matching score, etc.).
- Normalize each reward separately within the group. This is like grading each subject (math, English, science) on its own curve so one subject doesn’t drown out the others. The paper calls this “late scalarization”: you keep rewards separate and only mix them using the user’s preference weights at the very end. This avoids “reward hijacking,” where a goal with naturally bigger numbers overwhelms the rest.
- Update the model using a normal diffusion training loss that is steered by these per‑goal, per‑group signals, and then weighted by the chosen preference vector.
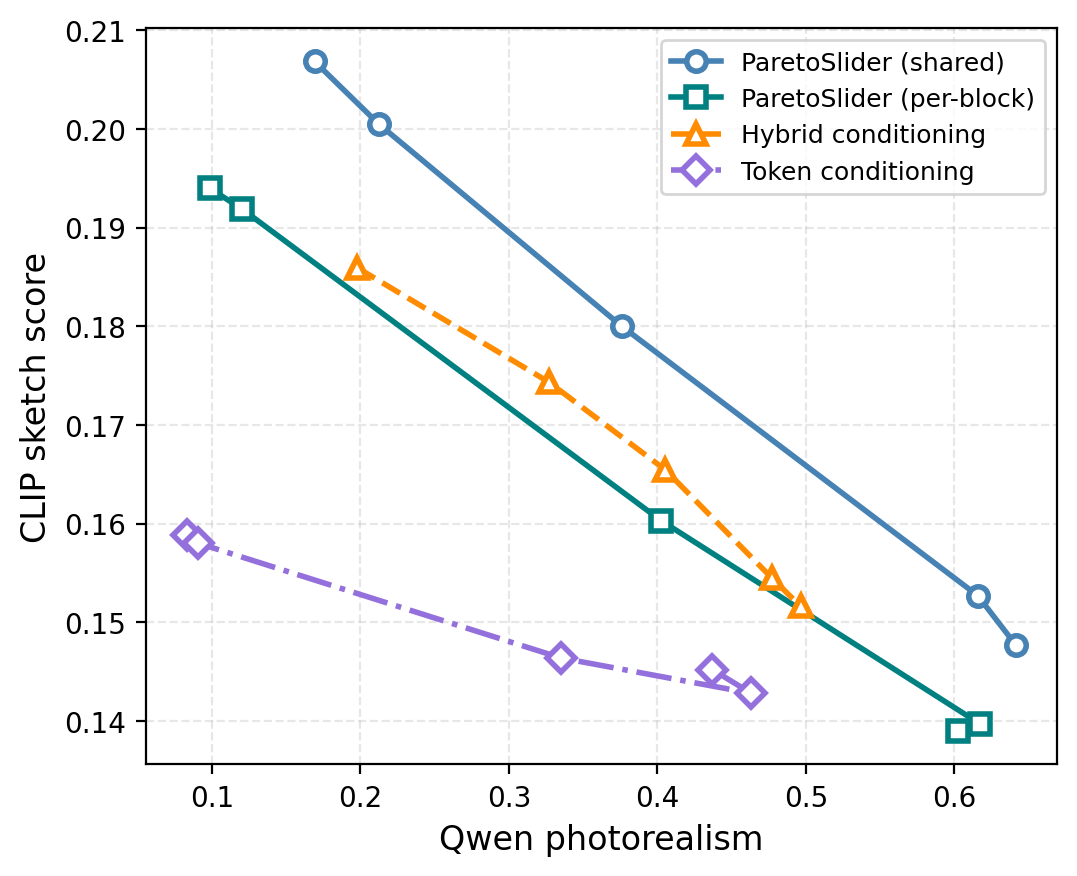
How does the model “see” your preferences? The authors add tiny “conditioning” modules—small neural layers that take the preference vector and nudge the model’s internal activations. Different backbones get slightly different nudges:
- Text‑to‑image (SD3.5): inject the preference both into a global timing/conditioning vector and as a small shared residual added to the image stream in each transformer block.
- Image editing (FluxKontext): modulate the text/context stream (where instructions live) by adding small shifts and scales based on the preference.
- Text‑to‑video (LTX‑2): add a small shared residual to the video stream, similar to the image case.
Analogy: The preference vector is like a set of dials the user can turn. The conditioning modules connect those dials to the right parts of the model so the style shifts smoothly when you move them.
What they found and why it matters
The authors test ParetoSlider on three tasks and backbones—SD3.5 (text‑to‑image), FluxKontext (image editing), and LTX‑2 (text‑to‑video)—and compare it to several baselines that either:
- Collapse all goals into one fixed score during training (so you get one operating point), or
- Require training and storing several separate models and blending them later, or
- Do heavy, slow guidance at inference time.
Main takeaways:
- A single ParetoSlider model matches or beats separately trained models at their chosen trade‑offs, while also letting you smoothly move between trade‑offs at inference time.
- The transitions are smooth and predictable. For example:
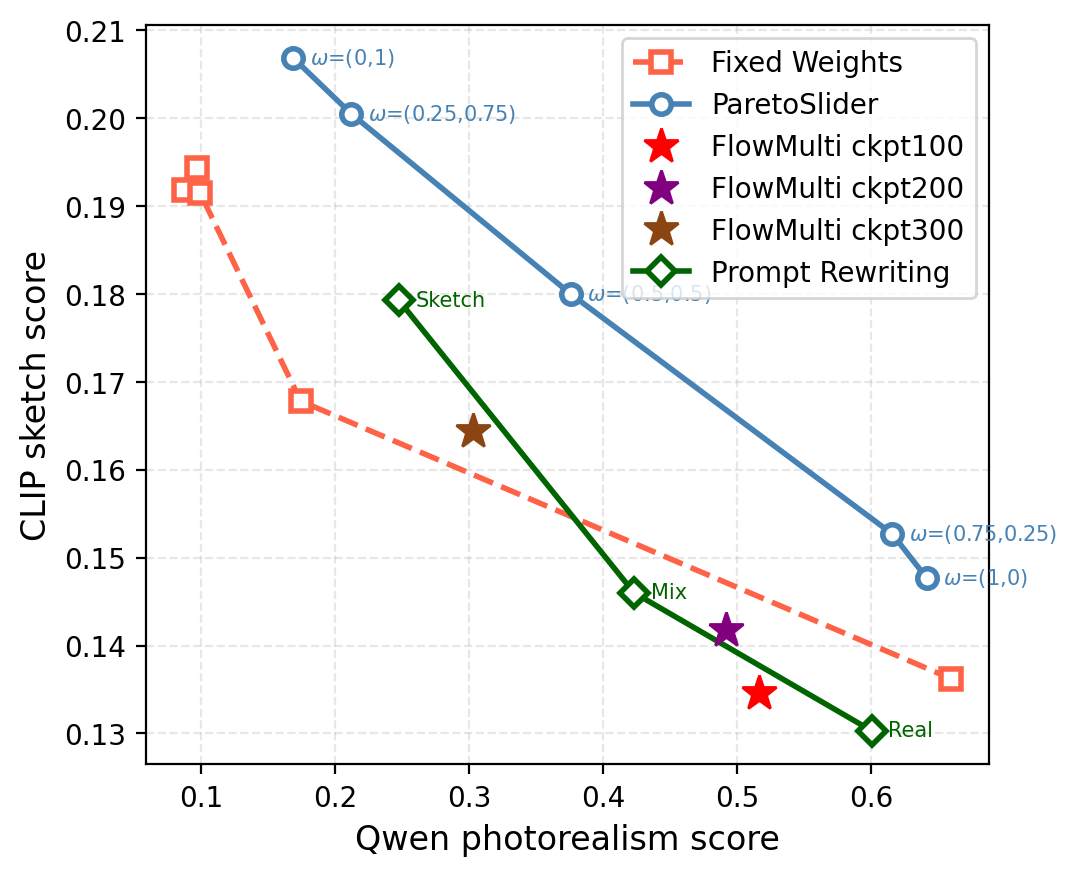
- Text‑to‑image: you can slide between photorealistic and sketch/anime/watercolor styles.
- Image editing: you can slide between preserving the original image and strongly following the edit instruction.
- Text‑to‑video: you can slide between animated and photorealistic looks for the same prompt.
- Late scalarization (normalize each reward first, then weight by preferences) is crucial. It makes the model actually follow the requested balance instead of being dominated by one goal.
- Efficient and practical: You only need one checkpoint to cover many preferences, you don’t need to store multiple models, and you don’t need slow per‑step guidance at generation time.
Why this is important
Many creative and practical tasks have conflicting goals. For instance, you may want an edit to stay true to the original photo but also follow a bold instruction, or you might want a video that’s realistic but still stylized. In real life, there’s no single perfect setting—different users prefer different balances.
ParetoSlider shows a way to:
- Give users real‑time control with a simple “slider” over those trade‑offs.
- Keep quality high without training many separate models.
- Generalize across tasks (images, edits, videos).
- Provide a template for multi‑objective alignment in other generative systems, not just vision.
In short, this work makes generative models more flexible, efficient, and user‑friendly: one model learns the whole spectrum of “best possible” trade‑offs, and you get to pick the point you like—whenever you want.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of gaps that remain unresolved and could guide future research:
- Lack of theoretical guarantees: No formal proof that preference-conditioned training with linear (late) scalarization recovers the full Pareto front; coverage, optimality, and convergence properties are not characterized (e.g., ε-Pareto optimality bounds, sample complexity).
- Linear scalarization limits non-convex fronts: Weighted-sum aggregation only recovers the convex portion of the Pareto frontier; feasibility of reaching non-convex regions (e.g., via Tchebycheff, ε-constraint, or Chebyshev scalarizations) is not explored.
- Preference distribution design: The distribution used to sample preference vectors ω over the simplex during training is unspecified; its impact on coverage, bias toward certain trade-offs, and generalization to rare ω configurations is unstudied.
- Calibration and monotonicity of control: No quantitative assessment of whether changes in ω produce predictable, monotonic, and calibrated shifts in objective values; mapping ω to achieved rewards and inverse-mapping (finding ω that hits target constraints) is missing.
- Scaling to many objectives: Practical and algorithmic behavior when M grows (e.g., M > 4) is untested—training stability, compute overhead from scoring M rewards per sample, interference between objectives, and UI/UX for higher-dimensional control remain unclear.
- Robustness to reward mis-specification: Sensitivity to noisy, biased, or drifting reward models (e.g., VLM-based judges) is not evaluated; strategies for robust training under imperfect or contradictory rewards are needed.
- Impact of correlated or redundant rewards: The method treats rewards independently before aggregation, but how correlated rewards affect learning (e.g., redundant channels or conflicting gradients) is unexamined.
- Advantage normalization design: Only per-reward group-relative standardization is considered; alternative stabilizers (e.g., quantile/robust normalization, learned baselines, per-reward clipping schedules) and their effects on fairness across rewards are not analyzed.
- Group size K sensitivity: The effect of prompt-group size on variance, stability, bias, and sample efficiency (including degenerate small-K or large-K regimes) is not reported.
- KL regularization tuning: How the KL term influences retention of base capabilities, avoidance of catastrophic forgetting across ω extremes, and the trade-off with alignment strength is not quantified.
- Conditioning architecture generality: Preference injection is tailored to each backbone; broader comparisons (e.g., cross-attention, FiLM, prompt-level conditioning, feature-wise modulation depth) and guidelines for selecting conditioning locations are limited.
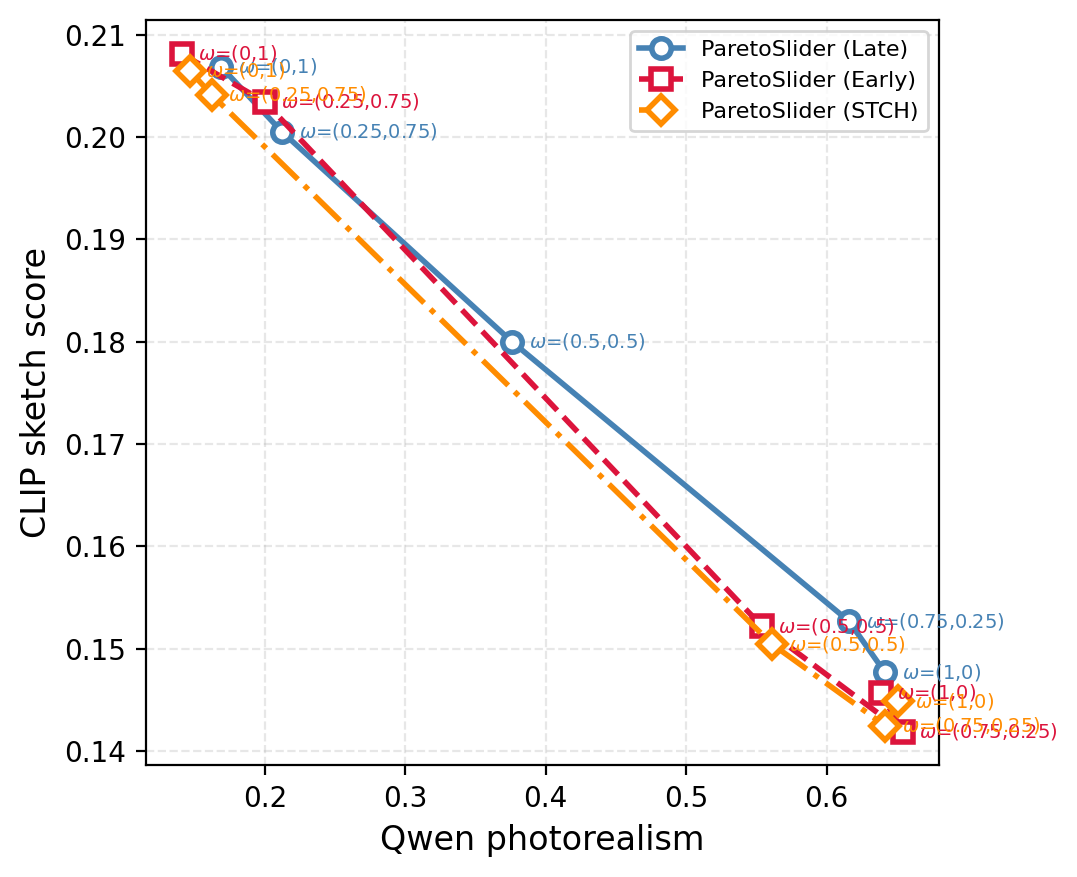
- Time-varying ω during generation: The method fixes ω over the denoising trajectory; potential benefits or pitfalls of dynamically varying ω across timesteps (e.g., coarse-to-fine control, stage-wise objectives) are unexplored.
- Multi-step/temporal rewards: Only terminal rewards are used; for video, step-wise (frame/sequence) rewards for motion smoothness, temporal consistency, or content safety and their integration into the training pipeline are not addressed.
- Sample diversity and mode coverage: Effects on diversity (e.g., avoidance of mode collapse as ω varies) and whether preference conditioning reduces variability within each trade-off setting are not measured.
- Generalization across backbones: Results are shown for SD3.5, FluxKontext, and LTX-2; extension to standard DDPMs, latent diffusion, and non-flow-matching architectures (and to discrete-token generators) is untested.
- Comparative evaluation breadth: Head-to-head quantitative comparisons against interpolation-based baselines (Rewarded Soups, Diffusion Blend) and training-free steering methods (e.g., per-step guidance) are insufficiently detailed beyond qualitative or limited scenarios.
- Human preference validation: Alignment claims rely on automated reward models; user studies assessing perceived control, satisfaction across ω, and fidelity to intended trade-offs are absent.
- Safety, bias, and misuse: How multi-objective control interacts with safety constraints (e.g., toxicity, fairness), potential reward hacking, and unintended emergent behaviors is not evaluated; incorporating safety rewards or constraints remains open.
- Compute and memory profiling: Training efficiency and scalability claims (especially as M increases) are not backed by detailed wall-clock, memory, and inference-time latency measurements; per-reward scoring cost is not benchmarked.
- Dataset coverage and OOD behavior: Robustness of Pareto control under out-of-distribution prompts, sources, or styles is not assessed; how limited training distributions bias reachable trade-offs is unclear.
- Hypervolume and Pareto metrics reporting: Hypervolume and frontier coverage results are deferred to supplementary material; standardized metrics and protocols for evaluating Pareto approximation quality are not established in the main text.
- Reward interaction audits: Systematic audits showing how improvements in one objective degrade others (beyond stylized examples) and identifying regions of steep trade-off (cliffs) on the frontier are missing.
- Transferability of ω embeddings: Whether preference-conditioning modules trained on one set of rewards can be reused or adapted for new reward sets without full retraining is unknown.
- Constraint-based control: The framework only supports weighted trade-offs; support for hard constraints (e.g., “maximize A subject to B ≥ b”) or goal-attainment functions is not explored.
Practical Applications
Immediate Applications
The following opportunities can be deployed now with existing diffusion backbones, reward models, and standard MLOps:
- Creative tools with live “trade‑off sliders” for generation and editing
- Sector: media/entertainment, design software, consumer apps
- Use cases:
- Text‑to‑image: interactively slide between photorealism and stylization (e.g., sketch, watercolor, anime), preserving a single checkpoint while exploring styles at inference time
- Image editing: user‑controlled balance between instruction adherence and source preservation (edit “strength” vs. fidelity)
- Text‑to‑video: dial between animated vs. photorealistic aesthetics for pre‑viz and social content
- Tools/products/workflows: plugins for Photoshop/After Effects/Premiere/Figma; mobile photo/video apps (e.g., Lightricks, Canva); web UIs with a single “style vs realism”/“edit intensity” slider backed by one preference‑conditioned model
- Assumptions/dependencies: reward models for each objective (e.g., photorealism classifiers, VLM‑based style scorers) are available and reasonably calibrated; base models support lightweight conditioning (e.g., AdaLN modulation); users accept VLM/CLIP‑based subjective scoring
- One‑checkpoint deployment instead of multiple tuned models
- Sector: software/MLOps, cloud inference, enterprise GenAI platforms
- Use cases: replace model “zoos” (one checkpoint per reward weight) with a single preference‑conditioned checkpoint; reduce storage, deployment complexity, and model selection logic
- Tools/products/workflows: unified API endpoint (generate(input, omega)), model registries storing preference metadata rather than fleets of checkpoints
- Assumptions/dependencies: LoRA or small adapters for preference injection are supported; late‑scalarization training (DiffusionNFT‑style) is run once with representative preference sampling
- Variant sweeps for A/B testing and creative review
- Sector: marketing/advertising, e‑commerce, media production
- Use cases: automatically generate a small Pareto sweep per brief (e.g., five points along the front) for human selection; align creative with engagement vs. brand identity trade‑offs
- Tools/products/workflows: “Pareto sweep” button in creative pipelines; batch generation with preset omega grid and reporting of reward scores
- Assumptions/dependencies: online or offline reward measurement available (e.g., aesthetic score, brand safety score); compute budget for small sweeps
- Content safety and policy tuning at inference time
- Sector: platform operations, content moderation, policy
- Use cases: adjust strictness trade‑offs (e.g., vividness vs. safety) for different surfaces or jurisdictions without retraining
- Tools/products/workflows: policy presets mapped to omega vectors; moderation dashboards tracing Pareto fronts between “utility” and “safety” rewards
- Assumptions/dependencies: reliable content safety reward models; governance over who can adjust omega and audit trails for settings
- Controlled synthetic data generation for ML
- Sector: academia/ML, enterprise data ops
- Use cases: generate datasets balancing realism vs. stylization to test robustness; produce controlled edits balancing label fidelity vs. appearance changes for augmentation
- Tools/products/workflows: data pipelines that emit images/videos along a defined omega grid with reward logs; HV (hypervolume) dashboards to track coverage
- Assumptions/dependencies: reward‑aligned to downstream metrics; adequate prompt diversity; controls for dataset bias introduced by reward models
- Evaluation and analysis tooling for multi‑objective alignment
- Sector: academia/ML research
- Use cases: use ParetoSlider to study/visualize trade‑offs, compare scalarization strategies (early vs. late), and monitor hypervolume improvements during training
- Tools/products/workflows: training dashboards that plot Pareto fronts and HV; ablation kits for conditioning strategies
- Assumptions/dependencies: standardized reward interfaces and logging; reproducible reward scales per experiment
Long‑Term Applications
These opportunities require additional research, domain‑specific reward design, scaling, or integration with broader systems:
- Multi‑stakeholder and jurisdiction‑aware alignment
- Sector: policy/regulation, platform governance
- Use cases: balance objectives such as safety, fairness, engagement, and diversity via transparent omega presets per region or demographic goal
- Tools/products/workflows: policy libraries mapping governance choices to omega; audit tools showing movement along fronts when policy changes
- Assumptions/dependencies: validated reward models for fairness/harms; processes for public accountability; mitigation of reward gaming
- Personalized preference control with hybrid conditioning
- Sector: consumer/enterprise apps
- Use cases: combine explicit omega weights with learned user embeddings to tailor trade‑offs to individuals or teams (e.g., brand stylization vs. realism for a specific studio)
- Tools/products/workflows: few‑shot preference capture plus explicit sliders; user/profile‑conditioned control surfaces
- Assumptions/dependencies: stable online learning without catastrophic forgetting; privacy‑preserving preference storage; mechanisms to prevent “reward hijacking” by idiosyncratic users
- Cross‑modal expansion (audio, speech, and music generation)
- Sector: audio tech, accessibility, entertainment
- Use cases: TTS trade‑offs (naturalness vs. intelligibility vs. latency); music generation (originality vs. prompt adherence vs. genre fidelity) with a single preference‑conditioned model
- Tools/products/workflows: omega‑controlled TTS/musical generators; UI sliders for clarity‑naturalness‑speed
- Assumptions/dependencies: differentiable or proxy rewards for audio attributes; adaptation of late‑scalarization to non‑diffusion policies if needed
- Energy/latency‑aware generation on edge and mobile
- Sector: energy/edge computing, mobile apps
- Use cases: include compute/latency as an explicit “cost” reward to expose a quality‑vs‑speed slider for on‑device generation
- Tools/products/workflows: dynamic inference that adjusts steps/samplers via omega; user‑facing “eco” vs. “quality” modes
- Assumptions/dependencies: measurable and stable mapping from quality to compute; training with cost rewards that generalize across devices
- Synthetic medical or scientific imagery with constrained trade‑offs
- Sector: healthcare, scientific research
- Use cases: control realism vs. privacy vs. label clarity; balance pathology visibility vs. anonymity in synthetic datasets
- Tools/products/workflows: regulated pipelines producing omega‑tagged outputs; QA steps with human oversight and domain‑specific rewards
- Assumptions/dependencies: clinically validated reward models; rigorous bias and safety evaluations; regulatory approvals
- Closed‑loop, metric‑driven creative optimization
- Sector: advertising, social platforms, streaming
- Use cases: real‑time adjustment of omega based on live metrics (CTR, watch time) while respecting safety/brand constraints; automated content iteration along Pareto fronts
- Tools/products/workflows: feedback controllers that tune omega; experiment platforms that monitor movement along fronts and guardrail thresholds
- Assumptions/dependencies: reliable online metrics; safeguards against optimizing to undesirable shortcuts; traffic‑aware experimentation ethics
- Robotics and planning with MORL principles from ParetoSlider
- Sector: robotics, autonomous systems
- Use cases: extend late‑scalarization and preference conditioning to policies balancing safety, speed, and comfort; generate perceptual inputs with controlled characteristics for sim‑to‑real
- Tools/products/workflows: MORL training wrappers with per‑objective advantage normalization; shared policy with omega control for deployment
- Assumptions/dependencies: adaptation from diffusion to control policies; reward engineering for real‑world safety; sample‑efficient training
- Interoperable “preference vectors” as a standard interface
- Sector: software/infrastructure
- Use cases: define portable omega schemas so different models and vendors accept consistent preference inputs (e.g., “safety”, “realism”, “brand style” axes)
- Tools/products/workflows: SDKs and API standards; model cards publishing supported reward axes
- Assumptions/dependencies: consensus on reward definitions and calibration; governance around naming, measurement, and comparability
Notes on feasibility across all applications:
- Reward availability and validity are the primary bottlenecks; the approach inherits the biases and limitations of the reward models (VLMs, CLIP‑based scores, domain classifiers).
- Stable training relies on group‑based advantage normalization and sufficient sample diversity per prompt; compute and data budgets must support online RL post‑training.
- Conditioning mechanisms assume diffusion/flow‑matching backbones with modules (e.g., AdaLN) that can be extended via lightweight adapters; other architectures may need alternative injection points.
- For safety‑critical or regulated domains, human oversight and rigorous validation remain necessary despite improved controllability.
Glossary
- AdaLN: Adaptive Layer Normalization; a conditioning mechanism that modulates transformer block activations via learned scale/shift (and often gating) parameters. "each modulated by AdaLN parameters derived from a shared timestep embedding temb."
- classifier-free guidance: An inference-time technique that adjusts generations by mixing conditional and unconditional predictions to control fidelity vs. creativity. "such as classifier-free guidance scales or prompt engineering"
- CLIPScore: A metric that uses CLIP embeddings to measure image–text alignment. "and CLIPScore~\cite{hessel2021clipscore, radford2021learning}"
- DiffusionNFT: An online RL fine-tuning framework for diffusion/flow-matching models that optimizes via the forward process with a flow-matching loss instead of trajectory policy gradients. "DiffusionNFT addresses these limitations by reformulating the policy optimization on the forward process rather than the reverse denoising process."
- DPO: Direct Preference Optimization; an offline alignment method that learns from pairwise human preference data without explicit reward modeling. "first adopted DPO for diffusion models"
- EMA: Exponential Moving Average; a smoothed copy of model parameters used as a stable target or teacher during training. "An exponential moving average (EMA) of the policy"
- early scalarization: Collapsing multiple rewards into a single weighted sum before optimization, which commits training to a fixed trade-off. "the prevailing practice of ``early scalarization'' collapses rewards into a fixed weighted sum."
- FlowGRPO: A variant of GRPO adapted to diffusion/flow models that performs group-relative policy optimization over reverse-time trajectories. "FlowGRPO optimization is carried out over a multi-step reverse-time trajectory."
- flow-matching: A generative modeling paradigm that learns a time-dependent velocity field to transport noise to data, enabling continuous-time sampling. "GRPO was adapted to flow-matching models"
- flow-matching loss: A supervised objective that trains the model to predict target velocities along the forward (noise-adding) process. "and a flow-matching loss"
- GRPO: Grouped Relative Policy Optimization; a policy-gradient method that normalizes rewards within groups to reduce variance without a learned value function. "More recently, GRPO~\cite{shao2024deepseekmathpushinglimitsmathematical} was adapted to flow-matching models"
- group-relative advantage: An advantage computed by standardizing rewards within a prompt group to create a relative training signal. "DiffusionNFT computes a group-relative advantage by normalizing rewards within each prompt group."
- hypervolume (HV) indicator: A Pareto-front quality metric measuring the volume dominated by a set of solutions with respect to a reference point. "using the hypervolume (HV) indicator, where our method consistently dominates."
- implicit velocity steering: A training trick that nudges the model’s velocity predictions toward higher-reward samples via EMA-based positive/negative targets and an interpolation weight. "using implicit velocity steering (§\ref{sec:prelim})"
- KL-divergence: A regularization term that keeps the fine-tuned policy close to a reference model by penalizing distributional drift. "A KL-divergence term regularizes the policy toward the pretrained reference model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that inserts low-rank adapters into weight matrices. "trained jointly with LoRA adapters."
- Markov decision process (MDP): A formalism for sequential decision-making defined by states, actions, transition dynamics, and rewards. "as a sequential Markov decision process (MDP)"
- MORL: Multi-Objective Reinforcement Learning; learning policies that balance multiple (often conflicting) objectives. "a multi-objective RL (MORL) framework"
- multi-objective optimization (MOO): Optimization over several competing objectives, typically yielding a set of trade-off solutions rather than a single optimum. "This conflict is a hallmark of multi-objective optimization (MOO)"
- Pareto dominance: A partial order where one solution is at least as good in all objectives and strictly better in at least one. "Pareto Dominance."
- Pareto front: The set of all non-dominated (Pareto-optimal) trade-offs where improving one objective would worsen another. "approximate the entire Pareto front."
- Pareto optimality: The property of a solution for which no objective can be improved without degrading another; non-dominated. "Pareto Optimality."
- PickScore: A learned human-preference model used as a reward/metric for aesthetic or alignment quality. "including PickScore~\cite{kirstain2023pickapicopendatasetuser}"
- preference vector: A nonnegative weight vector specifying the desired trade-off among objectives and used to condition the model. "we introduce a preference vector "
- probability simplex: The set of nonnegative vectors that sum to one, often used to represent mixtures or preferences. "where lies on the probability simplex "
- REINFORCE: A classic Monte Carlo policy-gradient algorithm using sampled returns to estimate gradients. "applied REINFORCE-style policy gradients"
- sampling scheduler: The rule that determines time-step progression and noise transitions during diffusion/flow sampling. "which in a flow-matching model corresponds to the sampling scheduler."
- timestep embedding: A learned embedding of the diffusion/flow time variable used to modulate the network across denoising steps. "timestep embedding temb"
- Vision-LLM (VLM): A model jointly trained on images and text, used here to define or compute reward signals for stylistic or semantic objectives. "we use VLM-based reward models"
Collections
Sign up for free to add this paper to one or more collections.

