- The paper provides a nine-dimensional taxonomy for categorizing code defects, including errors in correctness, security, and maintainability.
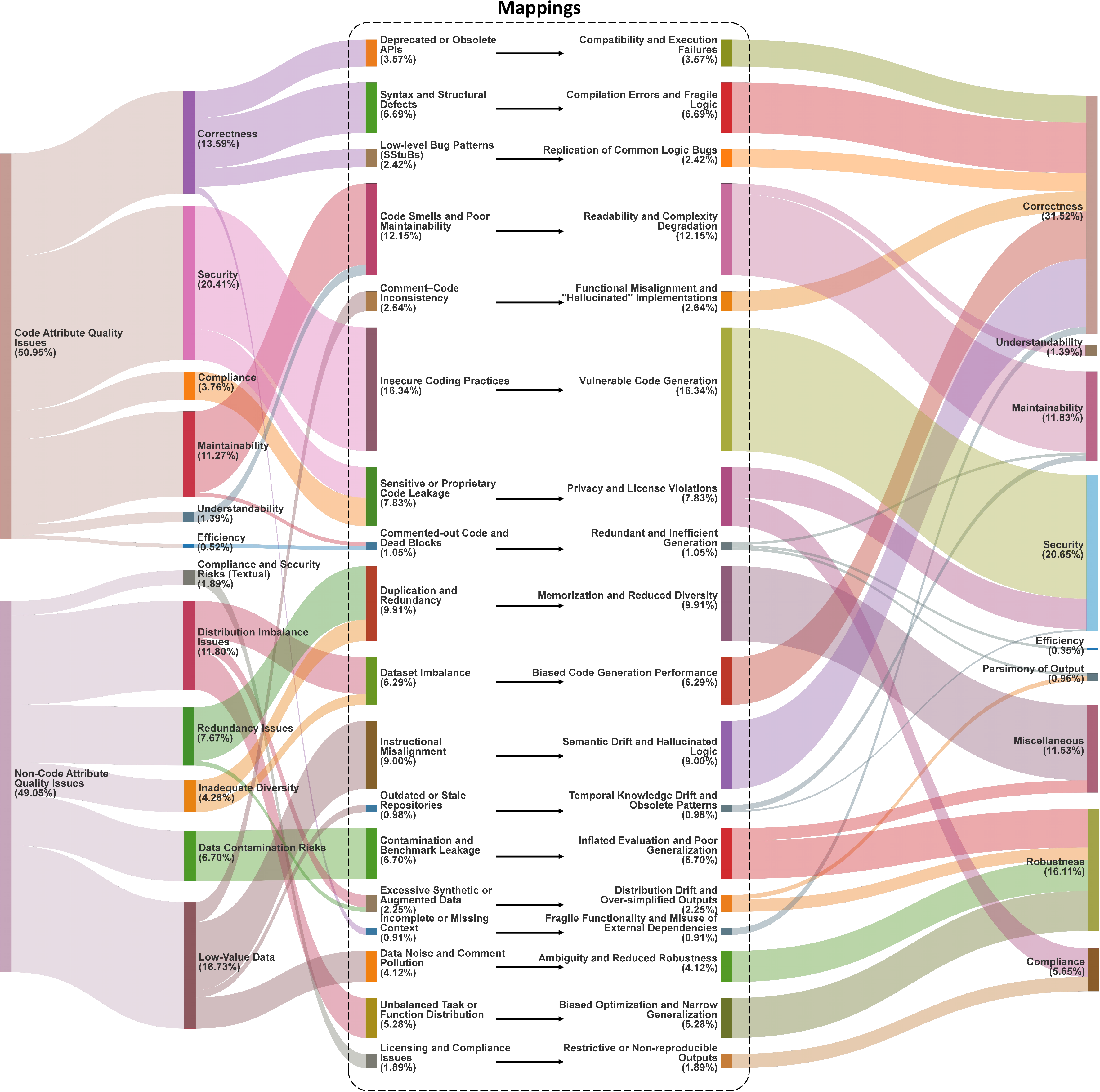
- It introduces a causal mapping framework with 18 propagation mechanisms that detail how training data flaws translate directly and indirectly into code issues.
- State-of-the-art detection and mitigation strategies are analyzed, emphasizing proactive data governance and end-to-end quality pipelines for robust code generation.
Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code (2605.05267)
Introduction and Motivation
LLMs have become integral to code generation, driving advances in automated code completion, repair, and documentation. However, LLM-generated code still suffers from a broad spectrum of quality defects, including logical errors, maintainability issues, and critical security vulnerabilities. The systematic review "Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code" provides a comprehensive synthesis of how training data quality fundamentally shapes, and often undermines, the reliability of model outputs. The work integrates cross-disciplinary perspectives and formalizes the propagation mechanisms by which data-level technical debt is amplified in LLM-generated code.
Taxonomies of Code and Data Quality Issues
Generated Code Quality Issues
Through synthesis of 114 primary studies, the paper proposes a nine-dimensional taxonomy for classifying LLM-generated code defects:
- Correctness: Logical errors, syntactic defects, deprecated API use.
- Security: Vulnerabilities such as SQL injection or unsafe serialization.
- Compliance: Legal, ethical, or privacy violations.
- Robustness: Lack of boundary condition handling, poor fault tolerance.
- Maintainability: Complex, monolithic, or poorly modularized code.
- Understandability: Obfuscated logic, poor naming, missing documentation.
- Efficiency: Redundant operations, non-optimal data structures/algorithms.
- Parsimony of Output: Overly verbose, repetitive code blocks.
- Miscellaneous: Misalignment with prompt intent, hallucinated APIs.
These dimensions are not isolated but often co-occur and reinforce one another, resulting in compounded risk when deploying LLM-generated code.
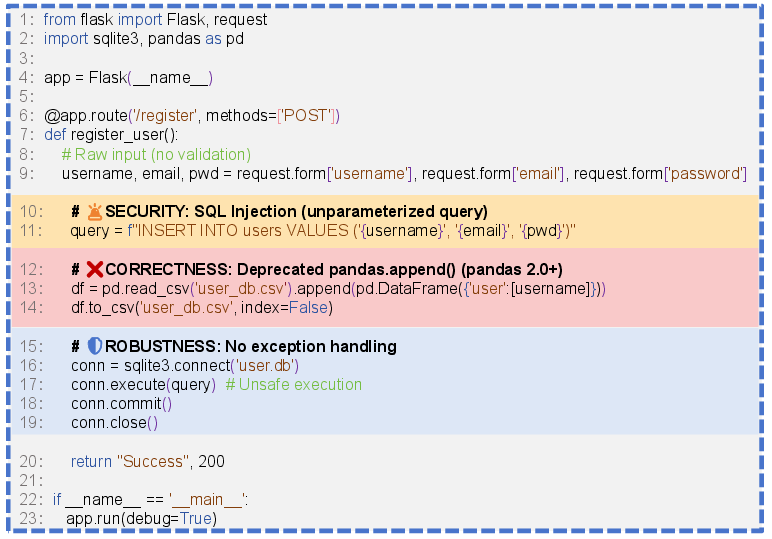
Figure 1: LLM-generated code with multiple quality defects.
Training Data Quality Issues
The review codifies training data issues into two meta-categories: code attribute defects (e.g., buggy code, unsafe idioms, obsolete APIs) and non-code attribute defects (distribution imbalance, duplication, benchmark contamination, textual noise).
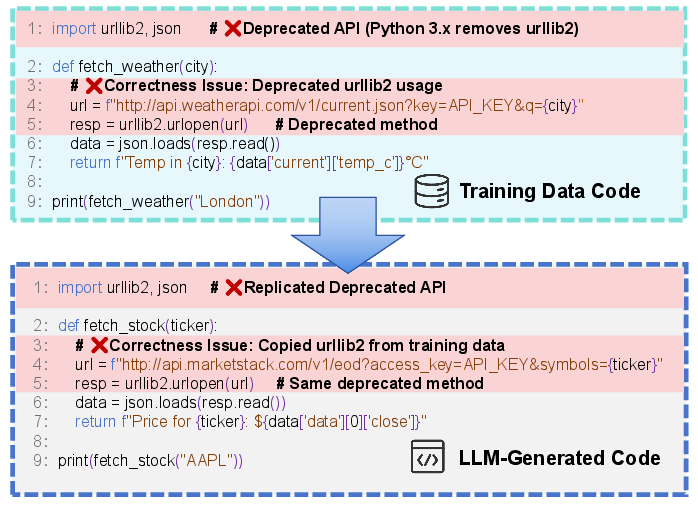
Figure 2: Training data quality issues propagated to generated code.
Non-code defects, such as severe class/language/task imbalance and excessive redundancy, distort underlying distributions and bias model behavior in ways that are often difficult to detect post hoc.
Propagation Mechanisms: Mapping Data Problems to Generated Defects
The core technical contribution is the causal mapping framework, detailing 18 propagation mechanisms between training data flaws and eventual code artifacts. These are divided into:
Direct mappings yield clear “garbage in, garbage out” patterns. For example, if deprecated, obsolete API patterns are overrepresented in the pretraining corpus, LLMs generate code that is not forward-compatible or secure. Indirect mappings are less immediately visible: duplicated content and imbalanced distributions can cause overfitting, mode collapse, or memorization, which limits the generative creativity and adaptability of the final model. Data contamination—overlap between training and evaluation sets—artificially inflates benchmark accuracy without guaranteeing generalization.
Evolution of Detection and Mitigation Strategies
State-of-the-art quality assurance has shifted from the reactive post-hoc filtering of outputs towards proactive, data-centric governance, leveraging integrated pipelines for defect detection and mitigation across the model lifecycle.
Detection now combines static rule-based analysis, dynamic execution-based verification, and semantic/model-based evaluation for both code outputs and training data. LLMs are increasingly being utilized to judge code quality ("LLM-as-judge"), complementing human review and lightweight ML classifiers. Static provenance tracking, performance drift monitoring, and membership inference attacks are advancing the ability to trace dataset contamination or memorization.
Mitigation strategies form a hierarchy:
- Data-level: Cleaning, filtering, balancing, and augmentation.
- Model-level: Instruction-tuning, reward-based optimization, and regularization.
- Generation-level: Prompt engineering, retrieval-augmented generation, iterative self-refinement, and automated post-processing.
The review documents that successful interventions are typically holistic—spanning data, model, and generation stages—and that isolated, stage-specific fixes provide only partial or transient benefits.
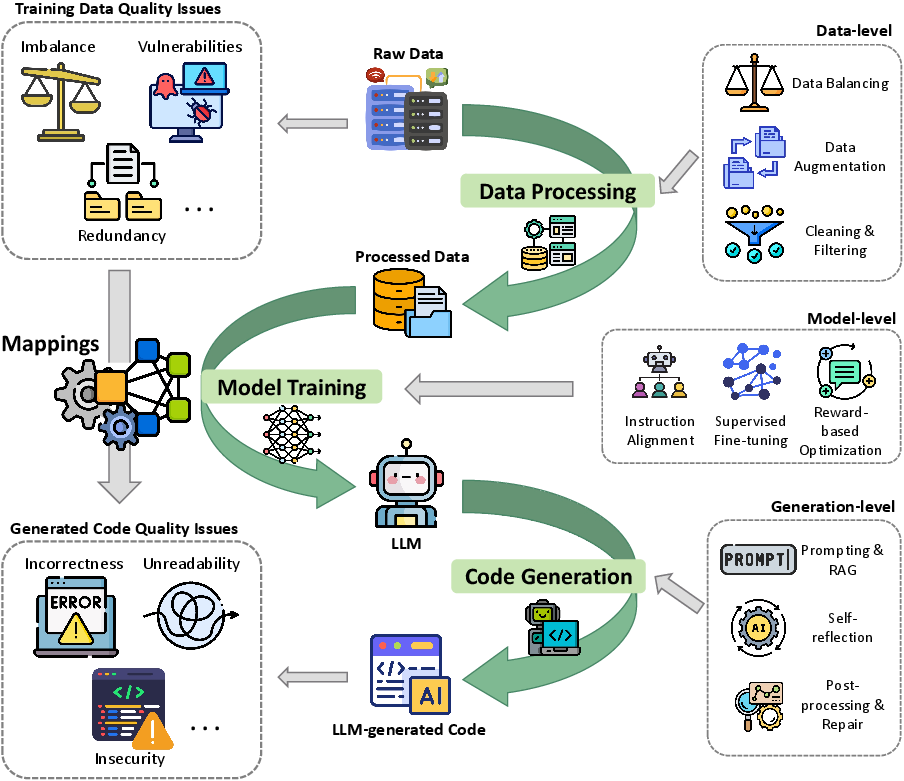
Figure 4: Conceptual framework of quality issues and mitigation in the LLM lifecycle.
Empirical Trends and Methodological Observations
The review presents strong quantitative trends:
- Functional correctness remains the most frequently studied code quality dimension, but recent years have seen a surge in security, efficiency, and maintainability research.
- A pronounced methodological shift is observed post-2023, with industrial LLM deployments driving up both the number and sophistication of quality studies.
In terms of data, redundancy, imbalance, and contamination issues are especially prevalent and persistent. Systematic data cleaning and deduplication consistently improve downstream metrics (e.g., up to 40% of raw open-source data is functionally invalid/unexecutable after filtering). However, current benchmarks may overstate LLM generalization ability due to hidden contamination.
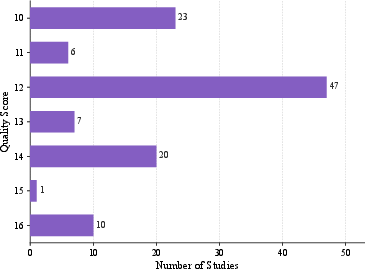
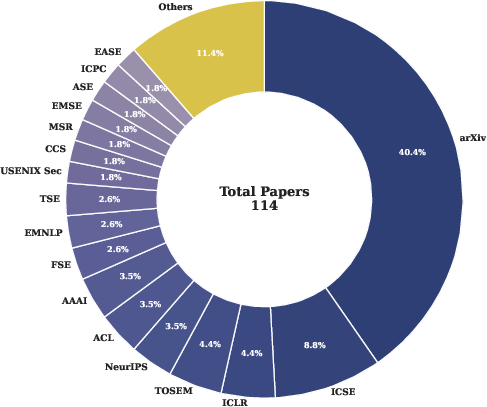
Figure 5: Distribution of Included Studies by Quality Score.
Practical and Theoretical Implications
This review underscores that generation failures are, in practice, more often symptoms of upstream training data deficiencies than shortcomings of generative inference or architectural limitations. Data-level technical debt is thus the primary driver of code-level defects and risks. The findings highlight that traditional correctness-centric evaluation is insufficient—security, maintainability, and compliance defects often evade static or functional benchmarks but have catastrophic implications in industrial codebases.
For practitioners, the results argue for continuous, end-to-end quality pipelines, incorporating dynamic, provenance-aware benchmarks and automated unlearning or influence tracking to enable traceable, robust interventions. For researchers, implications include the need for formal causal attribution between data and predictions, and for frameworks that can represent and evaluate higher-order properties—such as robustness, compositionality, and social risk—at scale.
Prospects for Future AI Systems
Future LLMs for code will likely be developed within closed-loop, data/model co-training infrastructures, where provenance tracking, quality-based data shaping, and reward modeling become first-class primitives. Advances in traceability, causal influence analysis, and automated dynamic benchmarking will be integral to both trustworthy code generation and the principled evaluation of progress. Integrated human-in-the-loop validation is expected to persist in high-risk domains, given the current limitations of automated semantic and legal compliance checks.
Conclusion
The systematic synthesis provided in this review establishes that the path to robust, secure, and maintainable LLM-generated code begins with rigorous, holistic data governance. Generation failures observed in outputs are overwhelmingly downstream effects of upstream training data flaws, both in code and non-code attributes. A foundational paradigm shift—away from reactive, output-centric filtering to proactive, data-centered lifecycle control—is essential for building trustworthy, high-quality code generation systems. This review offers a formal, actionable blueprint for future research and applied engineering aiming to close the gap between data curation practices and rigorous software quality standards.