EnterpriseRAG-Bench: A RAG Benchmark for Company Internal Knowledge
Abstract: Retrieval-Augmented Generation (RAG) has become the standard approach for grounding LLMs in information that was not available during training. While existing datasets and benchmarks focus on web or other public sources, there is still no widely adopted dataset that realistically reflects the nature of company-internal knowledge. Meanwhile, startups, enterprises, and researchers are increasingly developing AI Agents designed to operate over exactly this kind of proprietary data. To close this gap, we release a synthetic enterprise corpus, its generation framework, and a leaderboard. We present EnterpriseRAG-Bench, a dataset consisting of approximately 500,000 documents spanning nine enterprise source types (Slack, Gmail, Linear, Google Drive, HubSpot, Fireflies, GitHub, Jira, and Confluence) and 500 questions across ten categories that test distinct retrieval and reasoning capabilities. The corpus is generated with cross-document coherence (grounded in shared projects, people, and initiatives) and augmented with realistic noise such as misfiled documents, near-duplicates, and conflicting information. The question set ranges from simple single-document lookups to multi-document reasoning, constrained retrieval, conflict resolution, and recognizing when information is absent. The generation framework lets teams generate variants tailored to their own industry, scale, and source mix. The dataset, code, evaluation harness, and leaderboard are available at https://github.com/onyx-dot-app/EnterpriseRAG-Bench.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “EnterpriseRAG-Bench: A RAG Benchmark for Company Internal Knowledge”
What is this paper about? (Brief overview)
This paper introduces EnterpriseRAG-Bench, a big, realistic test for AI assistants that search through a company’s private files and then write answers. This approach is called Retrieval-Augmented Generation (RAG): the AI first finds the right documents (retrieval) and then uses them to write a response (generation). Most existing tests use public web pages, but real companies store knowledge in emails, chats, tickets, and docs that are messy and private. The authors built a fake—but realistic—company dataset so anyone can fairly test and improve AI helpers for workplace knowledge.
What were the authors trying to do? (Key objectives)
- Build a large, realistic “practice ground” for company-style information, not just web pages.
- Create questions that test different skills: basic lookups, understanding tricky phrasing, combining info from multiple documents, spotting conflicting facts, and knowing when the answer isn’t there.
- Provide tools to generate similar datasets for different industries and to score AI systems on a public leaderboard.
- Show how well common search methods work (or fail) on company data.
How did they do it? (Methods explained simply)
Think of a company’s knowledge as a giant, messy school backpack: emails, chat messages, tickets, wiki pages, and meeting notes all mixed together. The authors built a pretend tech company called “Redwood Inference” and filled it with about 500,000 documents from nine sources you’d find at work (like Slack chats, Gmail emails, GitHub pull requests, Google Drive docs, Jira tickets, and meeting transcripts).
To make this feel real, they:
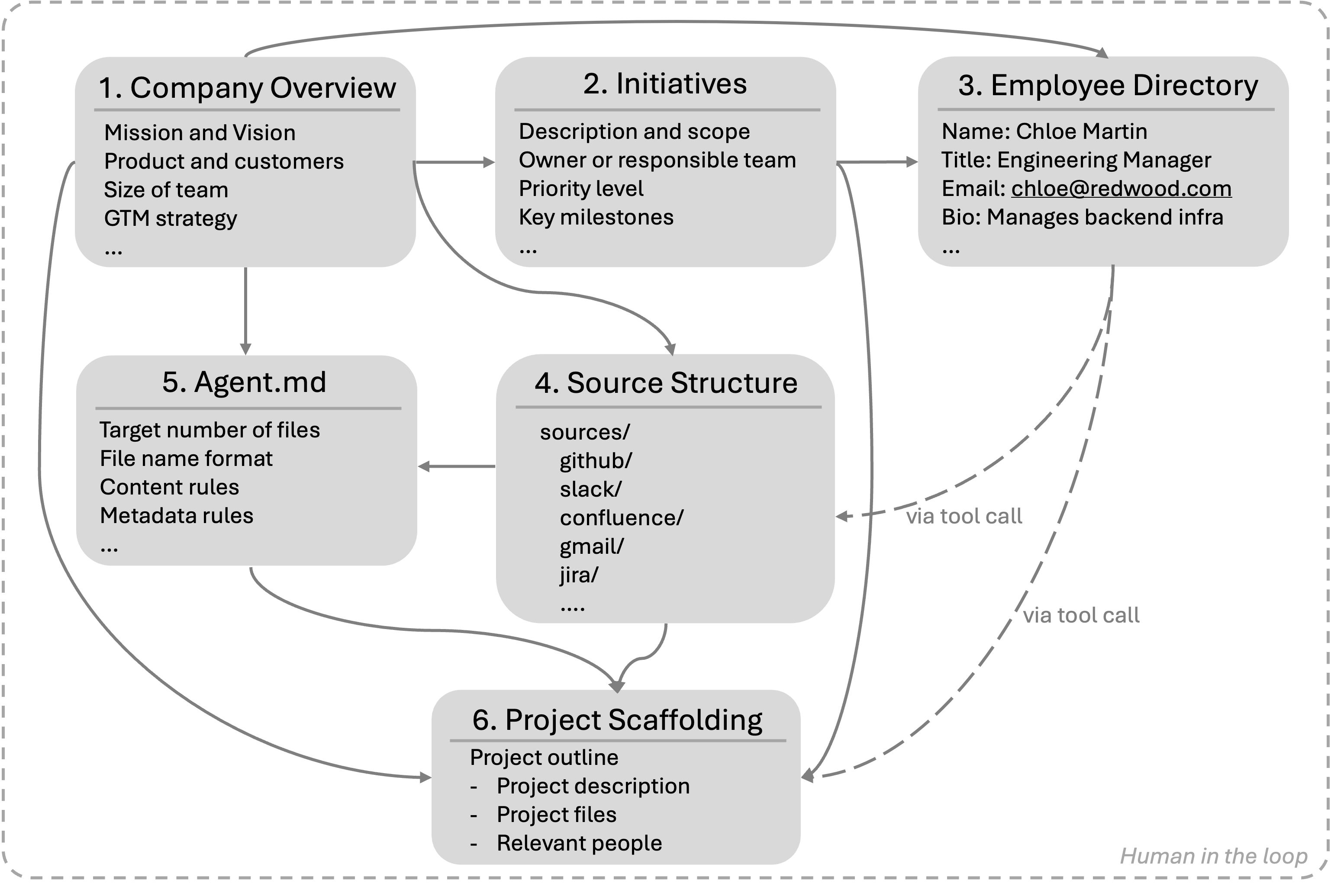
- Used a “scaffolding” plan: They first wrote a company overview, major projects, an employee directory, a directory structure for each app (like where folders live), and “agents.md” notes that describe what belongs in each folder. This keeps documents consistent (same projects, people, and decisions show up across files).
- Created two kinds of documents:
- High-fidelity clusters: Smaller groups of documents that reference each other closely (like a project’s tickets, emails, and meeting notes).
- High-volume content: Lots of documents generated efficiently using topic guides so there’s scale without too much repetition.
- Added real-world “messiness”:
- Misfiled documents (put in the wrong folder).
- Near-duplicates with slightly different facts (to create conflicts).
- Random “miscellaneous” folders (like memes or personal notes).
- Wrote 500 questions that test 10 different abilities, such as:
- Basic and semantic lookups (even when wording is different).
- Combining info across a long document.
- Bringing together multiple documents from a project.
- Choosing the one correct document when many look relevant.
- Resolving conflicting info.
- Listing all relevant items (completeness).
- Recognizing when the info isn’t in the data (so the AI doesn’t make things up).
How they score answers:
- Correctness: Is the answer basically right?
- Completeness: How many of the key facts did it include?
- Document Recall: Did it find the right documents?
- Invalid Extras: How many irrelevant documents did it include?
They also use a “correction-aware” process: if a system finds documents that look better than the current “gold” documents, three independent AI judges review them. If needed, the official answer set gets updated for future versions. This keeps the test fair and improving over time.
What did they find? (Main results and why they matter)
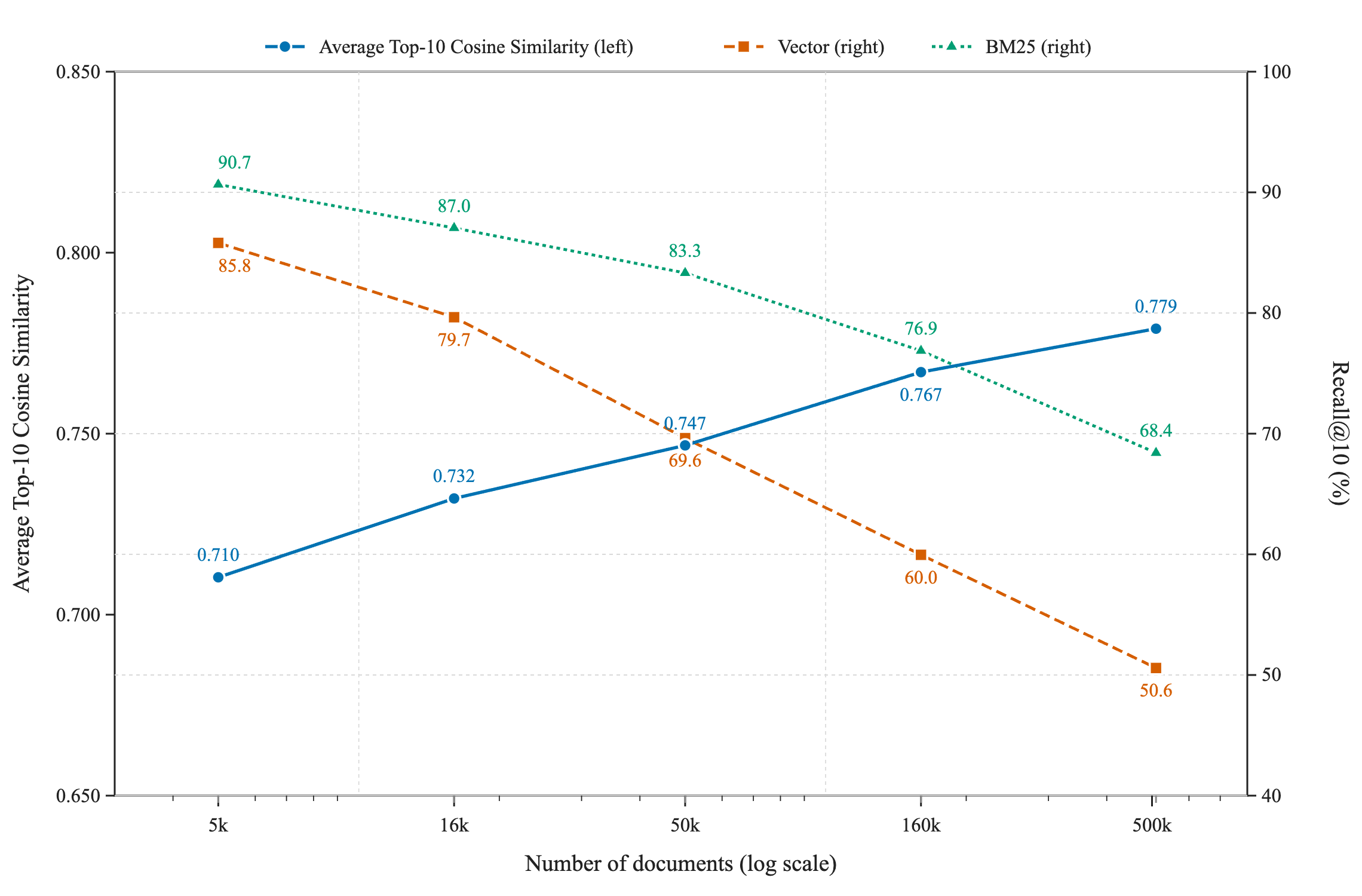
- Company data is “dense” and clustered: Lots of documents are close in meaning, which makes retrieval harder because there are many tempting—but wrong—lookalikes. Their measurements show their dataset looks much more like real company data than open web data.
- Surprising baseline performance:
- Keyword search (BM25) did best overall on being correct and finding the right documents.
- Vector/embedding search (which turns text into numbers and finds “semantic” matches) did worse than expected—even on questions designed for it.
- An agent-style “bash” search (using shell tools to explore files step-by-step) got the highest completeness (it’s good at digging up all the needed documents) but is slow and pricey.
- As the dataset gets bigger, retrieval gets harder (recall goes down), which mirrors real life at larger companies.
- Big takeaway: What works on public web benchmarks doesn’t always work on messy, internal company data. Systems need to be tested on realistic company-style corpora to be trusted.
Why is this important? (Implications and impact)
- Companies are building AI assistants to answer questions from internal documents. This benchmark lets teams test those assistants in conditions that feel real, not just on Wikipedia-style data.
- It highlights that enterprise data needs different retrieval strategies; relying only on web-trained embedding models may not be enough.
- Because the dataset and code are public, researchers and companies can:
- Recreate or customize the benchmark for their own industry.
- Compare systems fairly on a common leaderboard.
- Help improve the benchmark by suggesting corrections that get rolled into future versions.
- Future directions include adding images and other media, better multi-step (multi-hop) questions, questions that care about “what’s most recent,” and people-centric questions (like “Who owns X?”) that are tricky because people are mentioned in different ways across tools.
In short: The authors built a large, realistic “playground” for testing AI that looks things up in messy company files. Their results show that common web-based methods don’t always work well on internal data, and their open tools will help everyone build and test better AI assistants for the workplace.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and dataset.
- External validity across real enterprises: No systematic validation against multiple real, heterogeneous enterprise corpora (beyond a single Onyx subset) to quantify representativeness across industries, sizes, and communication cultures; needs anonymized distributional audits and topic/cluster comparisons across domains.
- Single-company simulation bias: The corpus models one mid-stage tech company; it is unclear how well results transfer to manufacturing, healthcare, legal, finance, or public-sector organizations with different workflows and artifacts.
- Static corpus without temporal evolution: The benchmark lacks evolving document states, version histories, or time-sensitive ground truth; recency-aware and change-aware retrieval cannot be evaluated rigorously without timestamped updates and time-scoped questions.
- No permission/ACL modeling: Enterprise retrieval is constrained by per-user access rights; the dataset lacks permission graphs and user-specific visibility, precluding evaluation of permission-aware retrieval, personalization, and privacy-preserving RAG.
- Flattened JSON removes rich structure: Email threading, nested CRM objects, wiki tables, code review diffs, and rich formatting are not preserved; the impact of structure loss on retrieval and grounding remains unquantified.
- Limited noise realism: Noise omits OCR errors, typos, malformed encodings, mixed languages, partial/inline screenshots, attachment-only content, and redlines/track-changes—common in practice; need to inject and benchmark against these artifacts.
- Lack of multimodal content: Images, diagrams, slide decks, embedded tables, and non-text attachments are missing; multimodal retrieval and grounding cannot be assessed.
- Underexplored multilingual settings: The corpus appears monolingual; enterprises often include multilingual documents and code-switching; retrieval robustness across languages and transliteration variants is untested.
- Synthetic conversational artifacts: Slack/email threads are unrealistically focused with limited digressions, sarcasm, or mis-threading; the effect of more realistic conversational noise on retrieval is unknown.
- Uniform cluster structure from scaffolding: Topic scaffolding yields more uniform clusters than real data; methods to learn and reproduce long-tail/peripheral topic distributions from real corpora are not evaluated.
- Small and imbalanced question categories: High Level (10), Conflicting Info (20), Completeness (20) provide limited statistical power; per-category confidence intervals and robustness to sampling variance are not reported.
- “Info Not Found” is too easy: All baselines achieve 100% correctness; harder absence-detection with near-miss distractors, partial evidence, and ambiguous queries is needed to measure real selective abstention.
- Conflict resolution limited to near-duplicates: Conflicting-info questions rely on controlled near-duplicate divergence rather than realistic, time-ordered contradictions with authority hierarchies (e.g., policy vs. chat vs. ticket); need temporally grounded conflict tasks.
- High-volume aggregation untested: No implemented tasks requiring aggregation across large fractions of the corpus (despite being listed as future work); retrieval/exhaustive recall limits at scale remain unmeasured.
- People-centric entity resolution missing: The benchmark lacks questions requiring cross-source alias resolution (full name vs. handle vs. nickname vs. title) and role changes over time.
- Baseline coverage is narrow: No evaluation of hybrid dense–sparse pipelines, cross-encoder re-rankers, ColBERT/SPLADE, learned retrievers, metadata-aware filtering, or query expansion—standard components in modern RAG systems.
- Vector underperformance is unexplained: The cause of poor semantic retrieval (even on semantic questions) is not diagnosed; requires ablations on enterprise-tuned embeddings, vocabulary adaptation, negative mining, chunking strategies, and cross-encoder re-ranking.
- Chunking and k hyperparameters: Sensitivity to chunk size, overlap, hierarchical indexing, and top-k settings is not explored; best practices for enterprise corpora remain unclear.
- Lack of document-level attribution metrics: Answers are stripped of citations and only judged for content; faithfulness-attribution alignment and per-fact citation correctness are not measured.
- Evaluation depends on LLM judges without human calibration: No inter-annotator agreement, judge variance, bias checks, or benchmarking of LLM judgments against human gold for correctness/completeness/relevance.
- Incentive compatibility of correction-aware scoring: Potential gaming by retrieving many documents to trigger gold-set corrections is not analyzed; need safeguards, ablation of “invalid extra documents” thresholds, and auditing for correction drift.
- Closed-model dependence and reproducibility: Generation, embeddings, and scoring rely on proprietary models; portability to open models, sensitivity to model choice, and cost/latency reproducibility are not assessed.
- Scaling limits of generation: The pipeline’s quality and coherence beyond ~500k documents are untested; failure modes (topic drift, duplication, schema violations) and costs at larger scales are unknown.
- Missing user/task context: Queries lack personalized context, session history, or task framing; the effect of user intent disambiguation and contextualized retrieval remains unexplored.
- Source coverage gaps: Common enterprise tools (SharePoint, OneDrive, Notion, ServiceNow/Zendesk, Teams, Zoom, Box, Salesforce variants, ticketing beyond Jira) are absent; generalization to different source schemas is untested.
- Code-aware retrieval not evaluated: GitHub content exists but no code-specific tasks (e.g., API usage, diff reasoning, linking code to design docs/tests) assess the unique challenges of code/document cross-retrieval.
- No measurement of cost/latency–quality trade-offs: Apart from a qualitative note on the Bash agent’s latency, there is no standardized reporting of runtime, token/cost budgets, or throughput vs. quality curves across methods.
- Lack of privacy/safety stress tests: No adversarial scenarios for sensitive data leakage, over-sharing across teams, or red-teaming tasks common in enterprise deployments.
- Ground-truth update stability: Leaderboard comparability under evolving gold sets is not analyzed; need protocols to quantify version-to-version shifts and confidence intervals for scores under gold corrections.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be implemented with the released dataset, generation framework, evaluation harness, and leaderboard.
Industry
- Software/IT (Enterprise AI, DevTools)
- Stack benchmarking and vendor selection for enterprise copilots
- Use the benchmark and leaderboard to compare BM25, vector, agentic retrieval, and hybrids on correctness, completeness, recall, and retrieval noise before purchase or deployment.
- Workflow: run your retrieval stack through the evaluation harness; analyze per-question-type results; choose routing policies (e.g., BM25 for lookup, agent for exploratory tasks).
- Dependencies/assumptions: LLM-judge costs; similarity between your internal data distribution and the benchmark; stable permissioning mirroring your environment.
- RAGOps continuous evaluation in CI/CD
- Add correction-aware tests to detect regressions in retrieval or generation on every change to prompts, indexes, or models.
- Tools: evaluation harness in a CI job, metrics dashboards, regression gates on completeness/correctness.
- Dependencies: budget for LLM-based judging; versioned gold sets for stable comparisons.
- Retriever routing by question type
- Implement lightweight classifiers or heuristics to route: BM25 for Basic/Intra-Doc, vector for High-Level synthesis, agent for Completeness/Misc categories.
- Tools: per-type performance in the paper as initial priors; router service; fallback/timeout rules.
- Dependencies: classifier accuracy; latency and cost for agentic retrieval.
- Knowledge hygiene via “agents.md” governance
- Adopt the agents.md pattern to codify expected formats per source (e.g., PRs in GitHub, ticket templates), improving retrieval quality and future automation.
- Tools: repo linters, pre-commit hooks, KB validation scripts.
- Dependencies: org-wide adoption; change management.
- Customer Support, Success, and Sales (CRM/Helpdesk)
- Robustness testing for support bots across tickets/emails/call transcripts
- Use the noise-injected corpus (misfiling, duplicates, conflicting facts) to stress-test retrieval and “Info Not Found” handling.
- Tools: noise-injection scripts; anti-hallucination fact checks; guardrail calibration.
- Dependencies: mapping to your CRM/helpdesk schema; privacy constraints.
- Security, Risk, and Compliance
- Hallucination suppression and unknown detection evaluation
- Validate that assistants abstain appropriately using the Info Not Found category and negative (anti-hallucination) facts.
- Tools: threshold tuning for abstention; policy unit tests in the harness.
- Dependencies: risk tolerances; audit logging.
- Healthcare
- Pre-deployment QA for clinical copilots using synthetic hospital twins
- Generate a hospital-variant corpus (policies, care pathways, shift notes) to test retrieval without exposing PHI.
- Tools: generation framework adapted with healthcare scaffolding; per-source agents.md (EHR modules, paging logs).
- Dependencies: SME prompts; regulatory review; domain-specific terminologies.
- Finance
- Compliance and audit assistant validation
- Evaluate constrained retrieval and conflict resolution over deal tickets, policies, CRM notes to minimize regulatory risk.
- Tools: finance-flavored synthetic corpus; correction-aware scoring to justify traceability.
- Dependencies: retention policies; supervisory oversight.
- Energy/Manufacturing
- Field service copilots for maintenance/runbooks
- Test retrieval with misfiled manuals, update conflicts, and constrained qualifiers (specific asset/site) before deployment to plants or rigs.
- Tools: verticalized corpus; routing BM25 for lookup + agent for aggregation.
- Dependencies: offline/edge constraints; safety certification.
- Education (Universities, EdTech)
- Campus IT and LMS assistants
- Validate retrieval across wikis, tickets, Slack-like chats with per-type routing to reduce noise from informal channels.
- Tools: harness integration; router policies.
- Dependencies: integration with campus permission models.
Academia
- Reproducible enterprise retrieval research
- Evaluate new retrievers, hybrid rankers, and agentic exploration policies on a realistic enterprise-shaped corpus with per-type difficulty.
- Tools: dataset + harness; scaling experiments using corpus subsets; local density and cluster metrics.
- Dependencies: compute cost for LLM judges; dataset license terms.
- Synthetic dataset methodology studies
- Investigate cross-document coherence generation, noise injection strategies, and their effect on retrieval metrics.
- Tools: generation framework knobs; ablations on scaffolding depth and noise.
Policy and Standards
- RFP and procurement scoring templates
- Incorporate benchmark metrics (correctness, completeness, recall, invalid extras) and correction-aware evaluation into vendor evaluations for enterprise copilots.
- Tools: public leaderboard; shared scoring rubrics.
- Dependencies: vendor participation; ability to run harness reproducibly.
- Privacy-preserving vendor testing
- Use synthetic corpora to evaluate external providers without sharing sensitive internal data.
- Dependencies: belief in representativeness; periodic recalibration with internal red-teams.
Daily Life and Teams
- Team knowledge organization sprints
- Apply agents.md and topic scaffolding to clean up shared drives/wikis and increase searchability of Slack/email-derived content.
- Tools: structure linters; taggers aligned to routing needs (e.g., owners, dates, qualifiers).
- Dependencies: time allocation; change adoption.
- Personal knowledge management
- Use topic scaffolding and “Info Not Found” tests to tune personal assistants (email, notes) for abstention and retrieval accuracy.
- Dependencies: local/private LLMs; PII hygiene.
Long-Term Applications
These require further research, scaling, or ecosystem development beyond the current release.
Industry
- Domain-tuned enterprise embedding models
- Train/fine-tune embeddings on enterprise-specific formats (tickets, CRM, chats) to close the observed performance gap for semantic retrieval.
- Products: enterprise embedding APIs; adapters for vector DBs.
- Dependencies: curated corpora; licensing; evaluation protocols.
- Cost- and latency-aware agentic retrievers
- Planful agents that mix keyword, vector, and tool use, optimizing for completeness vs. latency/budget per query type.
- Products: retrieval planners; dynamic budgets; cached exploration graphs.
- Dependencies: reliable tool-use policies; monitoring and SLAs.
- Multimodal enterprise RAG
- Retrieval over images, diagrams, tables, PDFs, log attachments; aligning with proposed future question types.
- Products: multimodal indexes; table-aware retrievers; document-structure parsers.
- Dependencies: robust OCR/layout models; permission-aware viewers.
- Recency-aware and high-volume aggregation
- Systems answering “latest” queries and aggregating across thousands of documents reliably (e.g., fleet-wide status, org-wide policy diffs).
- Products: time-aware indexing; incremental summarization; streaming evals.
- Dependencies: correct timestamp normalization; drift handling.
- Synthetic “digital twins” of organizations for pre-production testing
- Company-specific synthetic clones to stress-test assistants, red-team privacy and bias, and validate governance before touching real data.
- Products: generation-as-a-service; vertical templates (healthcare, finance, legal).
- Dependencies: SME involvement; safety reviews; fidelity to real failure modes.
Academia
- Formal models linking corpus structure to retrieval difficulty
- Theorize and validate predictors (e.g., local cosine density, cluster separation) for Recall@K and end-to-end correctness under noise and scale.
- Dependencies: multiple corpora variants; standardized metrics suites.
- Evaluation science for correction-aware benchmarking
- Best practices for LLM-judge consensus, tie-breaking, and gold-set evolution that preserve comparability over time.
- Dependencies: open judge prompts; statistical reliability studies.
- Multi-hop and sequential discovery research
- Benchmarks and methods where answers require staged retrieval (output of step t informs step t+1) inside enterprise constraints.
- Dependencies: agent frameworks; verifiable chains-of-evidence.
Policy and Standards
- Certification frameworks for enterprise copilots
- Standardize correction-aware evaluations, abstention rates, and traceability requirements for regulated sectors (healthcare, finance, public sector).
- Products: conformance test suites; audit checklists; annual re-cert cycles.
- Dependencies: regulator engagement; standards bodies; public reference corpora.
- Data governance patterns as technical standards
- Elevate agents.md-like specifications and source-structure conventions into best-practice standards to improve interoperability and evaluation.
- Dependencies: cross-vendor adoption; schema registries.
Daily Life and Teams
- Household and SME digital twins
- Safe synthetic corpora for families and small businesses (receipts, chats, policies) to test assistants’ abstention and retrieval before ingesting real data.
- Products: turnkey generators; private/local evaluation kits.
- Dependencies: easy local deployment; privacy-by-default defaults.
- Proactive knowledge stewardship assistants
- Agents that continuously detect misfilings, duplicates, conflicting documents, and prompt owners to resolve them, guided by retrieval impact metrics.
- Dependencies: change management; user trust; on-device or secure processing.
Cross-cutting Assumptions and Dependencies
- Synthetic-to-real transfer: Results may vary if your data differs materially from a tech company’s distribution (Slack- and email-heavy, project-centric).
- LLM-judge reliability and cost: Correction-aware scoring depends on consistent LLM judgments; budgeting and variance controls are needed.
- Security and permissioning: Benchmarks must reflect production ACLs; evaluation environments need strict data isolation.
- Toolchain availability: Assumes access to search backends (OpenSearch/Qdrant), embedding models, and agent runtimes; substitutes may change results.
- Organizational adoption: Governance artifacts (agents.md), routing policies, and RAGOps require process changes and stakeholder buy-in.
Glossary
- agents.md: Natural-language specification files placed in directories to steer generation agents about expected document formats and content. "agents.md files placed throughout the directory tree to specify, in natural language, the expected format and content of documents in each location (e.g., that GitHub contains only pull requests with review comments, not issues)."
- agentic keyword search: An approach where an LLM uses shell tools iteratively to explore and retrieve relevant files via keyword operations. "Bash Agent retrieval represents a more recent approach following the agentic keyword search paradigm~\citep{subramanian2025keyword}"
- anti-hallucination facts: Negative statements included with questions to catch specific errors when a system retrieves the wrong document. "Constrained questions additionally produce anti-hallucination facts: negative statements that catch errors a system might make if it retrieves a distractor document instead of the gold document."
- Approximate Nearest Neighbor (ANN) search: Algorithms that speed up nearest-neighbor retrieval in vector spaces by trading exactness for efficiency. "We use exhaustive pairwise comparison rather than ANN search~\citep{malkov2020hnsw} to avoid recall misses and ranking noise."
- Bash Agent: A retrieval agent that leverages shell commands (e.g., grep, find) to navigate a file system and select documents. "Bash Agent retrieval represents a more recent approach following the agentic keyword search paradigm~\citep{subramanian2025keyword}"
- BEIR meta-benchmark: A widely used evaluation suite covering multiple retrieval tasks and datasets. "the BEIR meta-benchmark~\citep{thakur2021beir}"
- BM25: A classic bag-of-words ranking function used for keyword-based document retrieval. "BM25 uses OpenSearch with a standard analyzer over a single concatenated text field."
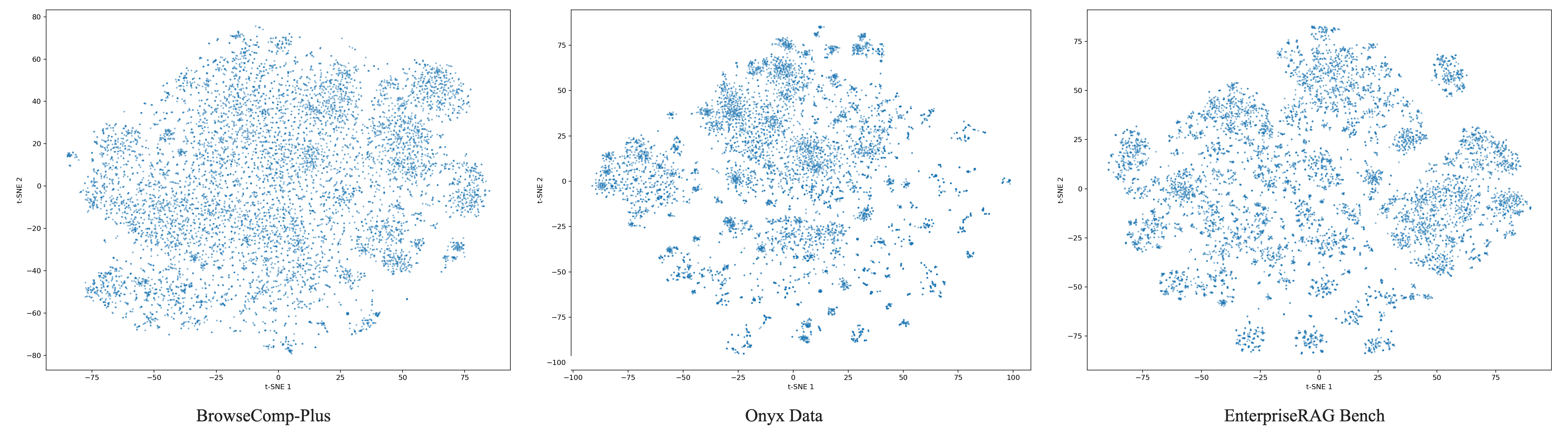
- BrowseComp-Plus: An open-web dataset for complex retrieval/browsing, used here as a comparison corpus. "BrowseComp-Plus~\citep{chen2025browsecomp} is drawn from the open web and covers a broad, heterogeneous mix of topics"
- cl100k_base: A tokenizer vocabulary used with certain OpenAI models. "(cl100k_base via tiktoken)."
- completeness (metric): The fraction of gold “answer facts” present in the candidate answer, measuring coverage. "Completeness measures the fraction of atomic answer facts supported by the candidate answer."
- completeness clusters: Small, tightly linked groups of documents designed so that answering requires retrieving all of them. "A separate step produces completeness clusters: groups of 4--10 documents generated with full mutual visibility and facts deliberately distributed across the group"
- correction-aware scoring pipeline: An evaluation process that can update gold labels when evidence shows they’re incomplete or incorrect. "We address this through a correction-aware scoring pipeline (Section~\ref{sec:correction})"
- corpus-exploration flows: Question-generation procedures where an LLM explores the dataset with tools before formulating a question. "Corpus-exploration flows equip the generation model with tools (glob, grep, read, etc.) to discover document relationships before proposing a question."
- cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "we compute the average cosine similarity to its ten nearest neighbors in the embedding space"
- cross-cluster similarity: Average similarity between documents from different clusters, indicating how separable clusters are. "Cross-cluster similarity is the same quantity for random pairs drawn from different clusters"
- cross-document coherence: The property that documents reference shared entities and events, making the corpus internally consistent. "The corpus is generated with cross-document coherence---grounded in shared projects, people, and initiatives---"
- dense embedding model: A model that maps text to high-dimensional dense vectors where proximity reflects semantic similarity. "We rely on a dense embedding model for this measurement"
- directory-walk sampling: Selecting documents by traversing directory structures, used to produce realistic shuffling noise. "Documents relocated within their source type via directory-walk sampling"
- document chunking: Splitting documents into fixed-size token segments to compute embeddings or support retrieval. "documents are chunked into 512-token segments using the embedding model's tokenizer (cl100k_base via tiktoken)."
- gold-biased tie-breaking: A rule that favors existing gold labels unless judges strongly disagree during correction. "with gold-biased tie-breaking"
- gold set: The authoritative set of documents and answers used for evaluation, subject to correction. "the original gold set"
- HotpotQA: A multi-hop question answering benchmark emphasizing reasoning over multiple documents. "HotpotQA~\citep{yang2018hotpotqa}"
- in-cluster similarity: Average similarity between documents within the same cluster, indicating cluster tightness. "In-cluster similarity is the average cosine similarity between random pairs of documents that fall within the same cluster"
- KARLBench: An enterprise knowledge grounding benchmark with a corpus largely from public documents. "KARLBench~\citep{databricks2025karl}"
- k-means: A clustering algorithm that partitions data into k clusters by minimizing within-cluster variance. "We partition each corpus with k-means~\citep{lloyd1982kmeans}"
- k-nearest neighbors (KNN): The set of k closest items to a point in vector space, used here for local similarity statistics. "Local (top 10 KNN)"
- KILT: A framework for unified evaluation of knowledge-intensive language tasks with grounding. "KILT~\citep{petroni2021kilt}"
- local density: A measure of how many semantically similar documents are near each point in embedding space. "Local density. To quantify the density of each document's immediate semantic neighborhood, we draw a uniform random sample of 1{,}000 documents from each corpus."
- LLM-based conformance checks: Automated validation using LLM judges to ensure questions meet type-specific constraints. "LLM-based conformance checks."
- LLM-based shuffle: Relocating documents to plausible but incorrect locations using an LLM’s structural knowledge. "LLM-based shuffle & Documents relocated to structurally plausible but incorrect locations"
- model drift: The tendency of a generation model to collapse to narrow themes, producing repetitive content without guidance. "The central challenge is model drift: without tight steering, the LLM converges on a narrow set of themes and produces near-duplicate documents."
- MS MARCO: A large-scale machine reading comprehension and passage ranking dataset. "MS~MARCO~\citep{bajaj2018msmarco}"
- MTEB: A multi-task embedding benchmark for evaluating text embeddings across diverse tasks. "MTEB~\citep{muennighoff2023mteb}"
- MuSiQue: A benchmark for multi-step, compositional question answering. "MuSiQue~\citep{trivedi2022musique}"
- Natural Questions: A question-answering dataset of real user queries with Wikipedia grounding. "Natural Questions~\citep{kwiatkowski2019natural}"
- near-duplicates: Documents that are highly similar except for controlled factual differences, used to test conflict resolution. "augmented with realistic noise such as misfiled documents, near-duplicates, and conflicting information."
- OpenSearch: An open-source search engine used here to implement BM25 keyword retrieval. "BM25 uses OpenSearch with a standard analyzer over a single concatenated text field."
- ordinal majority vote: A decision rule using rank-order categories where the majority choice determines classification. "An ordinal majority vote determines the final classification"
- Qdrant: A vector database used for nearest-neighbor search over embeddings. "retrieves via cosine similarity over Qdrant."
- Recall@10: The fraction of gold documents found within the top 10 retrieved results. "If not indicated otherwise, Recall@10 is implied."
- Retrieval-Augmented Generation (RAG): A method where a generator conditions on retrieved documents to ground its outputs. "Retrieval-Augmented Generation (RAG) has become the standard approach for grounding LLMs in information that was not available during training."
- t-SNE: A non-linear dimensionality reduction method for visualizing high-dimensional data. "t-SNE projections~\citep{vandermaaten2008tsne}"
- text-embedding-3-large: An OpenAI embedding model used to compute document and query vectors. "All embeddings are produced with OpenAI's text-embedding-3-large~\citep{openai2024embeddings}."
- three-judge consensus process: An evaluation scheme where three independent LLM judges classify documents, and their majority vote is used. "through the three-judge consensus process described in Section~\ref{sec:correction}"
- tiktoken: A tokenizer library used to segment text into tokens compatible with specific models. "(cl100k_base via tiktoken)."
- topic scaffolding: A hierarchical topic decomposition used to steer large-scale document generation and reduce duplication. "we introduce a topic scaffolding layer that hierarchically decomposes each source type into topics and subtopics"
- vector search: Retrieval based on nearest neighbors in embedding space rather than keyword matching. "Vector search embeds documents with OpenAI's text-embedding-3-large~\citep{openai2024embeddings} (3072 dimensions) and retrieves via cosine similarity over Qdrant."
Collections
Sign up for free to add this paper to one or more collections.