- The paper's main finding is that outcome-level RL with GRPO significantly improves compositional generalization compared to standard SFT.
- GRPO leverages global sequence-level rewards using both binary and composite signals to stabilize training and reduce overfitting on frequent patterns.
- Experimental results on benchmarks like SCAN and CFQ show robust performance gains, especially in generating novel composite outputs.
Reinforcement Learning for Compositional Generalization with Outcome-Level Optimization
Introduction
The challenge of compositional generalization—the capacity to systematically recombine observed primitives to interpret or generate novel instructions—remains a persistent limitation for contemporary neural sequence models. While supervised fine-tuning (SFT) with token-level cross-entropy loss achieves strong in-distribution performance, it frequently results in poor extrapolation to novel composites due to overfitting on frequent training outputs and local optimization objectives. This paper investigates whether outcome-level reinforcement learning (RL), specifically Group Relative Policy Optimization (GRPO), can more effectively induce compositional generalization by leveraging global sequence-level feedback, and studies the interaction between reward granularity and generalization capacity.
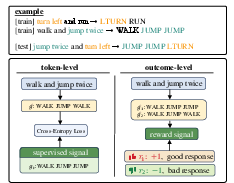
Figure 1: Illustration of compositional generalization and contrasting supervision paradigms; outcome-level RL optimizes at the sequence level, while standard SFT relies on token-level losses.
Methods: Group Relative Policy Optimization for Compositionality
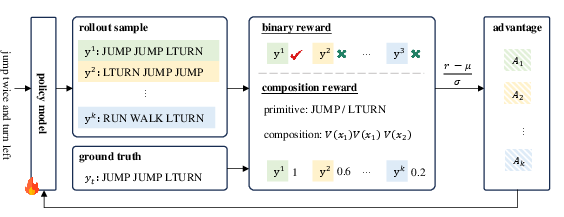
The central methodological contribution is the application of Group Relative Policy Optimization (GRPO) to LLMs, optimizing the policy based on rewards computed from complete model outputs. Under this framework, for each input, a group of candidate outputs is sampled, each scored with a reward signal. The policy gradient is then estimated using group-normalized relative advantages, which stabilizes optimization and emphasizes intra-group diversity.
Two reward structures are explored:
Experimental Setup
Evaluations leverage four compositional generalization benchmarks: SCAN (synthetic instruction-to-action), COGS (semantic parsing), GeoQuery (geographical QA), and CFQ (compositional SPARQL parsing). All experiments use Qwen-2.5-7B-Instruct and Llama-3.1-8B-Instruct, initializing RL training from SFT checkpoints to improve optimization stability. GRPO is implemented with a rollout group size of 8, moderate sampling temperature, and a policy regularization term to control divergence from the initialization distribution.
Results
Both GRPO variants (binary and composite) consistently outperform SFT across all benchmarks and setups. Gains are particularly prominent on productivity splits (e.g., SCAN Length), which require the generation of long, novel composite outputs. For example, on SCAN (Length), GRPO-Binary yields a +6.61% exact match improvement (Qwen) over SFT. On the hardest CFQ split (MCD3), performance improvement remains strong despite the inherent distribution shift.
Ablation studies reveal that while composite rewards can further enhance exact-match accuracy by combining primitive and structural feedback, a simple binary reward suffices for comparable performance. This indicates that outcome-level optimization via RL is robust to the reward structure in many settings, contradicting prior assertions that fine-grained feedback is always necessary.
Behavioral Analyses
Overfitting and Distribution Shaping
Token-level SFT-trained models frequently copy highly frequent compositional fragments from training outputs, as measured by higher average training trigram frequency in incorrect predictions. RL-trained models, specifically those trained with composite rewards, significantly reduce this tendency, as shown in Figure 3. This demonstrates that outcome-based RL mitigates local copying and biases the model toward less frequent, more compositionally novel outputs.
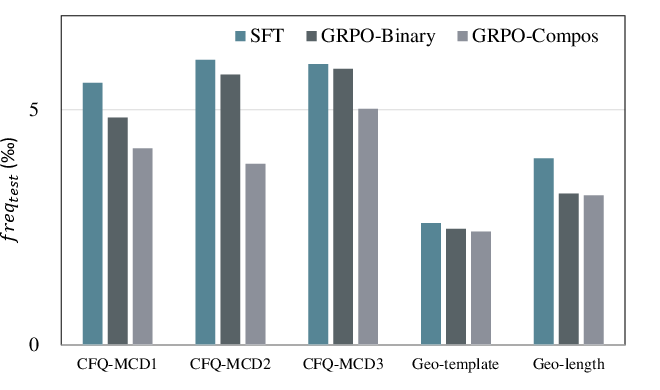
Figure 3: Average training trigram frequency in erroneous predictions, comparing SFT versus GRPO variants; RL-trained models generate outputs less skewed by frequent training patterns.
Top-k Candidate Evaluation
GRPO yields higher pass@1 accuracy compared to SFT, mainly due to improved ranking of structurally correct compositions. However, the pass@k gap closes as k increases, suggesting that SFT's main failing is defective ranking, not an inability to generate correct candidates at all. This highlights RL’s effect in modulating output distributions rather than merely increasing diversity.
Output Length and Complexity
Performance degrades as output compositional complexity (length) increases for all models. However, GRPO retains an edge in accuracy across all length bins, particularly for shorter outputs in SCAN, indicating SFT's persistent struggle with compositional validity even at moderate sequence lengths. For complex compositions, RL optimization delivers the sharpest distributional performance enhancement.
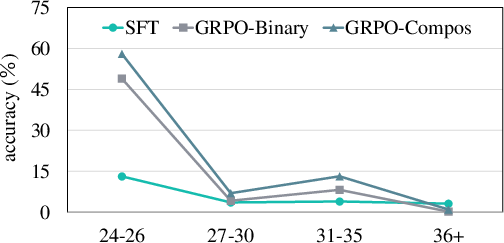
Figure 4: Accuracy on SCAN-Length as a function of target output length; RL-based approaches retain a consistent performance advantage, especially for shorter composite outputs.
Theoretical and Practical Implications
The results concretely indicate that outcome-level RL, even with simple reward signals, can reshape the model's output distribution to favor globally correct compositions, directly addressing the myopic optimization introduced by SFT. This method demonstrates that reinforcement learning can implicitly regularize against memorization of frequent superficial patterns, a principal cause of poor compositional generalization.
Practically, RL optimization improves generalization to novel composite queries, which is critical in tasks like semantic parsing, structured program synthesis, and data-to-text generation, especially under strong distribution shifts. However, the increased computational cost and exploration difficulty in RL remain caveats for broad adoption; without a well-chosen warm start and sampling strategy, optimization may be prohibitively expensive.
On a theoretical front, these findings challenge the assumed requirement for highly detailed, structured reward functions—simpler global supervision suffices to drive non-trivial improvements in compositional behavior, opening avenues for further investigation into the nature of inductive biases imposed by RL protocols.
Future Directions
Potential extensions include investigation of alternative RL algorithms (e.g., with more aggressive off-policy bootstrapping), adaptive or curriculum reward schedules, and probing the limits of zero-shot or few-shot compositionality with minimal supervision. Furthermore, integrating outcome-level RL with architectural modifications to further enhance compositional abstraction could be a promising pathway.
Conclusion
Outcome-level reinforcement learning via GRPO, using either binary or composite reward structures, yields robust gains in compositional generalization across multiple semantic domains, outperforming traditional SFT approaches. RL reshapes the output distribution to reduce overfit and frequent pattern reliance, with the largest effects on complex compositional settings. These insights suggest a shift in focus toward global, outcome-driven objectives for models requiring systematic compositional extrapolation, within the limitations of current computational scalability.