- The paper establishes that the total multi-head energy serves as a Lyapunov function, ensuring convergence under continuous gradient flow.
- It derives explicit critical thresholds and super-additive clustering effects, detailing how head diversity impacts convergence rates.
- An exact differential identity for attention entropy production is presented, linking geometric evolution to training stability.
Gradient Flow Structure and Quantitative Dynamics of Multi-Head Self-Attention
Introduction
This work rigorously analyzes the continuous-time gradient flow induced by multi-head self-attention in Transformer models, extending the gradient flow perspective initially developed for single-head self-attention. It characterizes the geometry, energetics, and convergence dynamics of multi-head attention by viewing tokens as particles evolving on the unit sphere under the influence of multiple interacting softmax potentials, governed by independent score matrices per head. The paper establishes a collection of quantitative results, contrasting the properties of multi-head and single-head dynamics, and quantifies key obstructions and thresholds unique to the multi-head setting.
Gradient Flow Framework and Key Structures
The fundamental model places n normalized token representations xi∈Sd−1, evolving under the influence of H heads, each parameterized by a score matrix Mh∈Rd×d and inverse temperature β. The per-head interaction energy is given by
Eh(X)=2βn21i=1∑nj=1∑neβ⟨xi,Mhxj⟩,
and the total energy is Emulti=∑h=1HEh. Token evolution follows the projected, tangential gradient flow x˙i=Pxi⊥(vi), where the aggregated velocity vi=n1∑hfih collects attention-weighted contributions from all heads.
Two crucial projection identities streamline the gradient computations and geometric reasoning throughout the results, relating the tangential projection operator Px⊥ with inner products and symmetries needed for Lyapunov analysis.
Monotonicity of Total and Per-Head Energy
The first core result is the unconditional monotonicity of the total multi-head energy xi∈Sd−10 under gradient flow, both in unconstrained xi∈Sd−11 ("flat") and sphere-constrained settings. The total kinetic energy serves as the time derivative: xi∈Sd−12
This establishes xi∈Sd−13 as a Lyapunov function for the evolution.
However, per-head monotonicity does not trivially hold in the multi-head setting. While in flat space orthogonality of xi∈Sd−14 matrices suffices for each xi∈Sd−15 to be monotone individually, when token evolution is projected onto the sphere, cross-head "radial shadow" terms, i.e., the projection of each head's force onto the token's current position, create persistent coupling obstructions even under orthogonal heads. Monotonicity of each xi∈Sd−16 on the sphere is guaranteed only under a derived "Radial Dominance" condition, controlling the sum of cross-head radial components relative to each head's own tangential force.
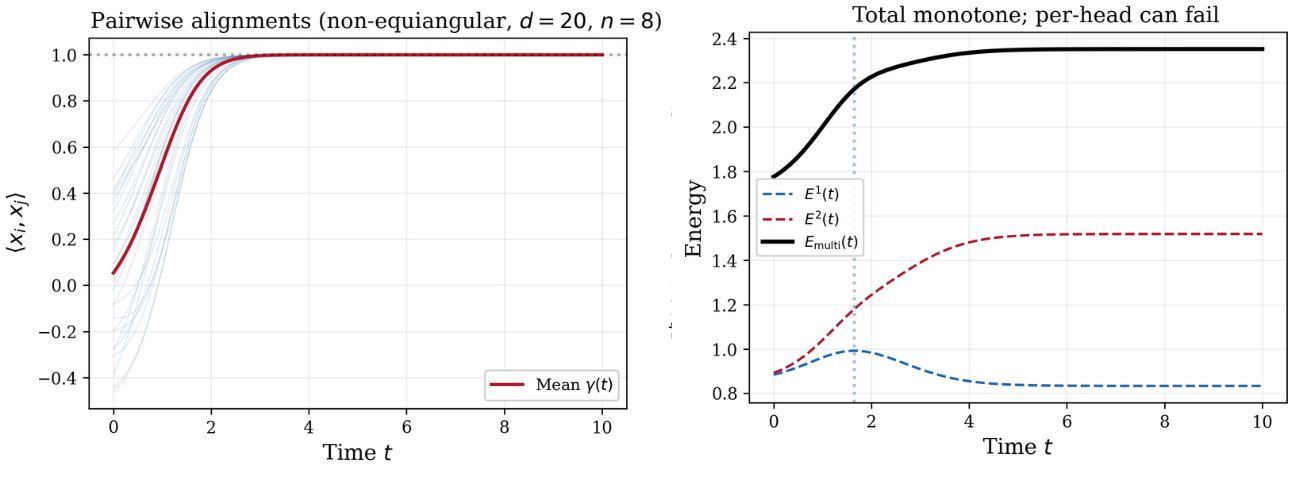
Figure 1: Pairwise alignments between tokens and per-head/aggregate energy trajectories during multi-head evolution; individual per-head energies can be non-monotone while the total is monotone.
Critical Temperature and Threshold Analysis
In the scalar-head, orthogonal-token regime, the paper derives an explicit critical inverse temperature xi∈Sd−17 at which the Radial Dominance condition is tight. The threshold,
xi∈Sd−18
demarcates the regime of provable per-head energy growth for given xi∈Sd−19 and number of heads H0. Notably, for H1, H2 is the reciprocal of the golden ratio. This explicit dependence exposes how increased number of heads or temperature narrows the monotonicity regime and provides analytic insight via connections to the Lambert H3-function.
Quantitative Rates and Heterogeneous Multi-Head Convergence
In the scalar-head, equiangular-token reduction, the dynamics reduce to scalar ODEs governing the mean alignment. The late-time clustering rate is exponential with rate proportional to the sum total of head strengths, H4 for H5. The early-time rate for heterogeneous heads exhibits super-additivity: sufficiently "spread" head strengths cluster faster than H6 heads of equal strength given the same total budget, provided the mean head strength exceeds a computable inflection point H7.
(Figure 2)
Figure 2: Early-time clustering rates and super-additivity as a function of head strength distribution, illustrating faster convergence for heterogeneous heads under proper conditions.
ReLU versus Softmax Attention Dynamics
The analysis provides a rigorous separation in clustering time complexity between softmax and ReLU-type attention mechanisms under linearized dynamics. Softmax attention drives clustering with a dimension-independent constant force even when pairwise alignments are small, yielding H8 time to cluster from random initialization. In contrast, ReLU attention yields a vanishing driving force at zero alignment, resulting in an H9 clustering time scaling with dimension. This precisely formalizes observed empirical differences in convergence between attention activations.
(Figure 3)
Figure 3: Comparative clustering dynamics for ReLU and softmax attention, highlighting the time complexity gap as Mh∈Rd×d0 grows.
Entropy Production: Exact Differential Identity
A focal theoretical result is the derivation of an exact identity for the time derivative of the token-wise attention entropy: Mh∈Rd×d1
with Mh∈Rd×d2 the pairwise score and Mh∈Rd×d3 its time derivative, under the current attention distribution Mh∈Rd×d4. In the scalar-head, equiangular regime, the covariance is non-positive, so attention entropy is rigorously monotonically increasing. This demonstrates that clustering in self-attention generally increases entropy unless attention sharpens to a subset, which does not occur in vanilla mean-field attention flows. Entropy rises sharply during pre-clustering and stabilizes at Mh∈Rd×d5 as alignments saturate.
(Figure 4)
Figure 4: Evolution of attention entropy and its production rate across the clustering process, confirming the two-phase structure of rapid entropy growth followed by stabilization.
Robustness to Practical Head Structures
The analysis includes perturbative results quantifying the stability of the energy monotonicity properties under approximate value alignment and approximate orthogonality of heads, measured in operator norm. The data-dependent thresholds ensure the key Lyapunov structure extends to trained transformers whose head subspaces are neither perfectly aligned nor orthogonal.
Implications, Limitations, and Future Directions
This paper establishes a foundation for understanding multi-head attention as an interacting gradient flow, notably identifying the radial shadow mechanism as a previously uncharacterized source of inter-head coupling that impedes per-head convergence guarantees absent strict conditions. The explicit calculation of phase boundaries and super-additive effects offers guidelines for designing transformer architectures with diverse heads.
Practically, the results inform initialization schemes, selection of number of heads and softmax temperature, and motivate head diversity for improved convergence. The entropy production analysis ties the geometric evolution to regularization and training stability; it also rationalizes the observed tendency for vanilla self-attention to distribute mass evenly as clustering proceeds.
Theoretically, the main open directions include full description of the critical points of the multi-head flow, sharp trajectory-invariance of the Radial Dominance regime, and the extension of the entropy increase principle to non-scalar, non-equiangular configurations. The nonlinear ReLU regime and causal/normalized attention flows remain challenging to fully characterize.
Conclusion
This work extends the gradient flow analysis of self-attention to the structurally richer multi-head case and provides both structural and quantitative results characterizing dynamics, energetics, and attention entropy. The identification of the radial shadow and the computation of sharp monotonicity regimes and clustering rates in the presence of multiple, diverse heads advance our understanding of the geometric foundations of transformer optimization and inference. The exact, regime-dependent entropy production identity offers a bridge between dynamical systems and information-theoretic perspectives on neural attention. The outlined open problems point to further development of a comprehensive, high-dimensional theory for self-attention beyond the mean field and idealized settings.

