Video Generation with Predictive Latents
Abstract: Video Variational Autoencoder (VAE) enables latent video generative modeling by mapping the visual world into compact spatiotemporal latent spaces, improving training efficiency and stability. While existing video VAEs achieve commendable reconstruction quality, continued optimization of reconstruction does not necessarily translate into improved generative performance. How to enhance the diffusability of video latents remains a critical and unresolved challenge. In this work, inspired by principles of predictive world modeling, we investigate the potential of predictive learning to improve the video generative modeling. To this end, we introduce a simple and effective predictive reconstruction objective that unifies predictive learning with video reconstruction. Specifically, we randomly discard future frames and encode only partial past observations, while training the decoder to reconstruct the observed frames and predict future ones simultaneously. This design encourages the latent space to encode temporally predictive structures and build a more coherent understanding of video dynamics, thereby improving generation quality. Our model, termed Predictive Video VAE (PV-VAE), achieves superior performance on video generation, with 52% faster convergence and a 34.42 FVD improvement over the Wan2.2 VAE on UCF101. Furthermore, comprehensive analyses demonstrate that PV-VAE not only exhibits favorable scalability, with generative performance improving alongside VAE training, but also yields consistent gains in downstream video understanding, underscoring a latent space that effectively captures temporal coherence and motion priors.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to teach computers to make videos. The idea is to train a video model not just to copy what it sees (reconstruct frames), but also to guess what will happen next (predict future frames). The authors call their model Predictive Video VAE (PV-VAE). By learning to predict, the model builds a better “understanding” of motion, which helps it generate more realistic, smoother videos.
What questions are the researchers asking?
- Can a video model get better at making high‑quality, natural‑looking videos if it learns to predict the future, not just reconstruct the present?
- Will this “predictive training” make the model’s internal representation (its “latent space”) more friendly to video generators like diffusion models?
- Does this also help with other video skills, like tracking moving points or estimating motion?
- As we train longer or use more data, does the method keep improving?
How does their method work? (Simple explanation)
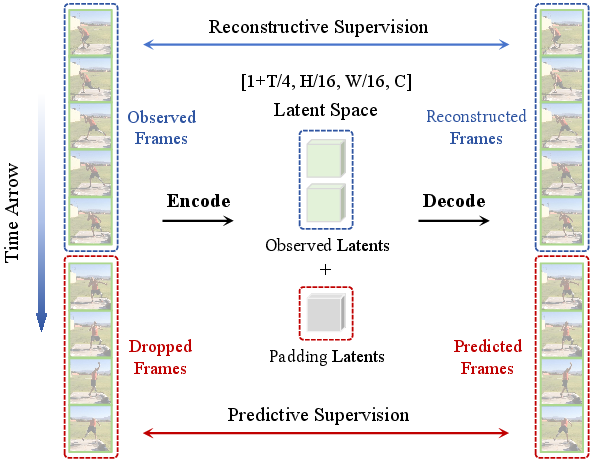
Think of a video like a short movie clip. Normally, a Video VAE (Variational Autoencoder) compresses the clip into a small hidden code (like a summary), then decodes it back to the original video. This helps other generators (like diffusion models) make videos more efficiently.
The new twist: during training, the model only gets to see the beginning of the clip, and the rest is hidden. It must reconstruct the whole video anyway—so it has to predict the missing future frames.
Here are the key ideas in plain language:
- Hide the future: Randomly remove the later part of the clip. The encoder only sees the earlier frames.
- Fill the gap: The decoder still has to output the full video (both the seen past and the hidden future). The “missing” parts in the compressed code are filled with blank placeholder tokens, so the decoder must infer what comes next from what it saw before.
- Focus on motion: Besides matching pixels, the model is also asked to match frame‑to‑frame changes (the differences between consecutive frames). This prevents it from just copying static backgrounds and encourages learning motion.
- Train in stages: First, pretrain on images (to learn sharp details), then train on videos with the “hide the future” trick, and finally fine‑tune the decoder without hiding frames to make reconstructions extra crisp.
Analogy: Imagine watching the first few seconds of a sports clip with the rest blurred out. You try to imagine how the play unfolds. Training the model this way encourages it to build a sense of how things move, not just what they look like.
What did they find?
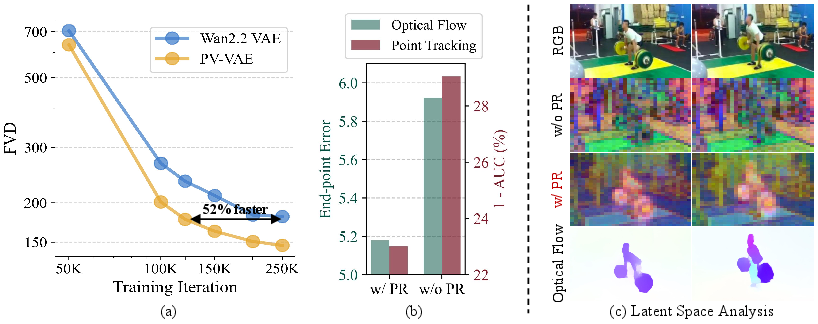
- Better video generation: On a standard benchmark (UCF101), PV‑VAE helped a diffusion video generator reach a much better realism score (lower FVD is better), beating a strong baseline (Wan2.2 VAE) by a large margin and converging 52% faster. It also improved results on RealEstate10K.
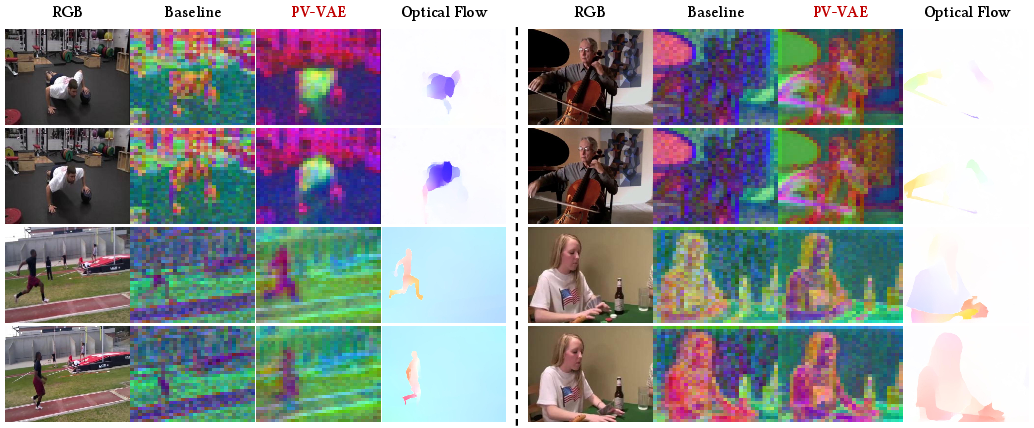
- Motion-aware latents: When they visualized the model’s hidden codes, the patterns lined up with real motion in the video (similar to optical flow). This means the model’s “summary” of each clip pays attention to what’s moving, not just how things look.
- Stronger video understanding: Using the model’s features, they got better results on:
- Optical flow (estimating how pixels move)
- Next-frame prediction
- Point tracking (following points over time)
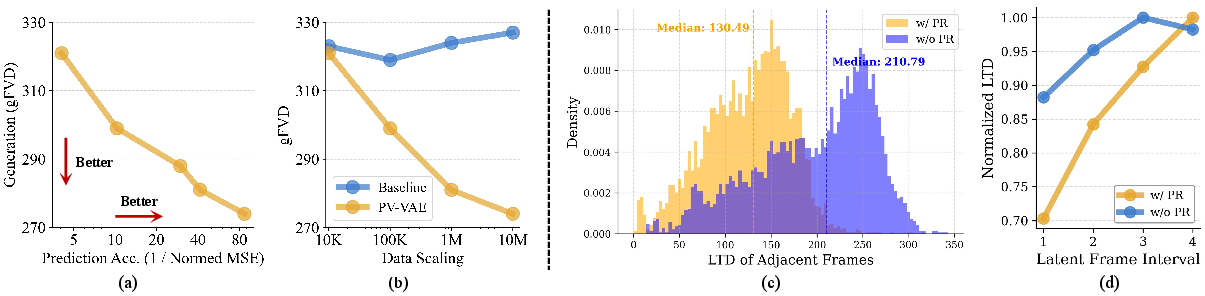
- Smoother over time: The model’s hidden codes change smoothly from frame to frame and change more as frames get farther apart—exactly what you want for capturing natural motion.
- Scales well: As they trained more, both prediction and generation kept improving—showing the approach benefits from more data and training.
- Reconstruction trade‑off: Pure reconstruction scores (how perfectly it copies inputs) were solid but not always the very best. That said, after a short decoder fine‑tune, reconstructions stayed competitive while generation quality was noticeably better.
Why this matters: Teaching the model to predict the future makes its internal representation “motion‑smart.” That makes it easier for diffusion models to generate videos that look realistic and stay consistent over time.
What does this mean for the future?
- Better generators: Video models that learn by predicting can make more coherent, less jittery videos—useful for creative tools, education, simulation, and more.
- Stronger foundations: The same “predict the future” idea could be used with other training tricks (like masking frames or doing frame infilling) to further improve video understanding and generation.
- Practical integration: The method plugs into existing Video VAE setups without changing lots of knobs, making it easy to adopt.
- Promising directions: The authors also explored Transformer-based versions (common in modern AI). While their first attempt still trails the CNN version for generation, it ran faster at inference and may improve with better designs and training.
Helpful definitions
- Variational Autoencoder (VAE): A model that compresses data into a small “code” (latent space) and then reconstructs it. Think of it like making a compact summary and expanding it back.
- Latent space: The model’s hidden representation—its internal “language” for describing videos.
- Diffusion model: A generator that creates data step by step from noise to a finished picture/video. It works better when the latent space is well-structured.
- FVD (Frechet Video Distance): A score for video realism and smoothness. Lower is better.
- Optical flow: A way to measure how each pixel moves between frames—like arrows showing motion.
In short: By training a video model to guess what happens next, not just to copy what it sees, this paper builds motion‑aware internal representations. That leads to higher‑quality, more coherent video generation and improves related video understanding tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, assumptions, and scope limits that future work could address:
- Diffusability definition and measurement: The paper treats FVD/KVD and convergence speed as proxies for “diffusability,” but does not provide a principled, direct metric or diagnostic for latent diffusability. Can we define and standardize intrinsic measures (e.g., score landscape smoothness, latent manifold curvature, mutual information with diffusion noise, diffusion training loss vs. latent statistics) to quantify diffusability independent of downstream diffusion models?
- Generalization to long-horizon and high-fps videos: All experiments use short 17-frame clips. How does predictive reconstruction scale to minutes-long or high-frame-rate videos, and what is the error accumulation or drift over long horizons?
- Masking strategy design space: The predictive task always drops a contiguous “future tail.” Would non-contiguous masks (random interleaved frames, middle-frame gaps, blockwise spatiotemporal masks, curriculum masks) or bi-directional prediction (past and future infilling) yield stronger temporal representations?
- Multi-modality of futures: The predictive objective likely averages over multiple plausible futures. How to preserve multimodal future hypotheses (e.g., via stochastic decoders, mixture latents, contrastive or flow-based predictive heads) and measure their diversity and plausibility?
- Camera vs. object motion disentanglement: The motion-aware loss uses temporal frame differences, which conflates camera and object motion. Would egomotion-compensated losses, flow-based weighting, or scene structure constraints lead to better motion priors and downstream generation?
- Choice and sensitivity of loss weights: The paper adopts MSE, LPIPS, GAN, KL, and a motion-aware term but does not provide sensitivity analyses for λ weights, GAN on/off schedules, or their impact on predictive learning and diffusability.
- Training–inference distribution gaps: The encoder is trained with dropped frames and padding tokens, then the decoder is fine-tuned on full sequences. What residual mismatch remains between (i) encoder latents during training and (ii) latents sampled by a diffusion model at generation time? Can latent prior matching or adversarial alignment reduce this gap?
- Decoder fine-tuning effects: Decoder-only fine-tuning improves reconstruction without harming generation in reported settings, but its broader effects are unclear. How robust is this stage across datasets/backbones, and can it ever erode the motion-aware structure induced by predictive training?
- Padding strategy space: Only Gaussian vs. learnable tokens were tested. Would mask-aware decoding, structured priors (e.g., learned time embeddings for missing slots), or noise schedules matched to diffusion priors better regularize predictive decoding?
- Architectural generality: Results are shown for a 3D causal CNN and a preliminary Transformer variant. What architectural elements (e.g., causal vs. bi-directional encoders, global attention, grouped attention over time) are essential for predictive gains, and how can Transformers be closed to CNNs on generation while retaining their efficiency?
- Compression ratio and channel dimensionality: The method is primarily assessed at t4/s16 with c=64. How do temporal/spatial compression and channel size trade-offs interact with predictive training, reconstruction fidelity, and diffusability? Is there an optimal regime for different downstream generation backbones?
- Dataset coverage and scalability: Benchmarks (UCF101, RealEstate10K, Kinetics-400) are limited in semantics, motion complexity, and text presence. Do gains hold on larger, more diverse, and modern video corpora (e.g., WebVid, Something-Something, Ego4D, YouTube-8M) and under distribution shifts?
- Text and fine-grained detail fidelity: The paper notes difficulty reconstructing dense text and attributes it to data scarcity. How does predictive training affect text rendering, signage, small-object detail, and fine texture—especially for text-to-video pipelines that require strong text alignment?
- Conditioning regimes: Only unconditional and class-conditional generation are evaluated. Does the predictive latent space improve text-to-video, story-to-video, and multi-modal conditioning (audio, pose, depth) without harming alignment?
- Robustness to occlusion and complex dynamics: No targeted tests for heavy occlusions, rapid scene cuts, motion blur, non-rigid deformations, or rare dynamics. Does predictive training help (or hurt) under these challenging conditions?
- Fair baseline capacity and training budget: Some baselines use different latent channel sizes and compression ratios. To isolate the contribution of the predictive objective, can we run capacity-matched baselines (e.g., c=64) with identical training budgets, GAN usage, and diffusion backbones?
- Diffusion backbone dependence: Results rely on Latte with rectified flow. Do improvements persist across diverse generators (U-Net, DiT variants, MMDiT, long-context transformers) and samplers/noise schedules?
- Convergence and data scaling claims: Faster convergence is shown on one setup. Are the speedups consistent across datasets/scales/backbones, and how do they decompose (e.g., optimization landscape, latent statistics) to offer actionable training guidance?
- Objective variants: The motion-aware term uses frame differences. Would alternatives (e.g., flow consistency, temporal VGG/LPIPS, cycle consistency, photometric reprojection, contrastive temporal discrimination) produce larger or more stable gains?
- Quantifying temporal consistency: The proposed Latent Temporal Distance (LTD) is informative but bespoke. How does LTD correlate with perceptual temporal metrics (e.g., tLPIPS, CLIP-TC, human studies), and can we standardize an interpretable, automatic temporal metric suite?
- Predictive representation layer selection: Probing uses features from the 14th diffusion layer. Are improvements consistent across layers/stages? What layer(s) best encode motion semantics vs. appearance?
- Multi-stage predictive curricula: The maximum dropping ratio r improves generation, but only uniform sampling is tested. Would curricula (progressively increasing r), horizon-adaptive dropping, or uncertainty-aware masking (harder regions) amplify benefits?
- Reproducibility details: Critical training specifics (exact datasets for image/video pretraining, data sizes/mixtures, full hyperparameter grids) are sparse. More detailed recipes are needed to replicate the reported gains and enable fair comparisons.
- Editing and video-to-video tasks: The method prioritizes generation and reconstruction. How does predictive training affect video editing, inpainting, and controllable video synthesis (e.g., pose-/flow-guided), where reconstruction fidelity and temporal alignment are simultaneously critical?
- Ethical and bias considerations: Predictive training may bias toward common motion patterns and suppress rare events. How robust are the latents to underrepresented actions, demographics, and cultural contexts, and how should datasets/objectives be adjusted to mitigate bias?
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, based on the paper’s predictive reconstruction objective and PV-VAE design.
- Bold drop-in tokenizer for video generation pipelines
- Sector: media/entertainment, advertising, gaming, education content creation
- Tools/Workflows: Replace existing VAEs in latent diffusion pipelines (e.g., DiT/Latte) with PV-VAE to improve training speed (≈52% faster convergence) and generation quality (FVD gains reported). Adopt the paper’s two-stage training (encoder training with predictive reconstruction + decoder fine-tuning) for stable deployment.
- Assumptions/Dependencies: Requires retraining or fine-tuning the diffusion backbone on PV-VAE latents; best validated on 17-frame 256×256 clips (scaling may need additional training); dense text rendering is weaker without text-heavy data.
- Latent-space video editing with improved temporal consistency
- Sector: post-production, social/UGC apps, marketing
- Tools/Workflows: Encode clips with PV-VAE, perform consistent latent edits (e.g., color/appearance, inpainting, style), then decode; leverage motion-aware latents to reduce flicker/drift across frames.
- Assumptions/Dependencies: Requires development of latent-space editing operators and UI; reconstruction of small/sharp text may be suboptimal; integration with existing NLEs or creative tools needed.
- Faster R&D cycles and reduced training costs for labs
- Sector: software/ML infrastructure, academia, startups
- Tools/Workflows: Adopt PV-VAE to accelerate training of latent video diffusion models (speed/memory gains reported) and to parallelize decoder fine-tuning with diffusion model training for faster iteration.
- Assumptions/Dependencies: Requires code integration and training orchestration; dependent on access to suitable compute and datasets.
- Synthetic video generation for data augmentation
- Sector: sports analytics, surveillance, robotics simulation (non-critical), e-commerce (turntable spins), education
- Tools/Workflows: Use PV-VAE-enabled generators to produce temporally coherent synthetic videos to augment training sets for tasks like tracking, pose estimation, or action recognition.
- Assumptions/Dependencies: Domain adaptation may be required; realism and text fidelity constraints could limit some use cases (e.g., branded content).
- Bootstrapped video understanding with lightweight heads
- Sector: surveillance, AR/VR analytics, sports tech
- Tools/Workflows: Freeze the LVDM trained on PV-VAE latents and attach small decoders for optical flow, next-frame prediction, and point tracking (paper shows consistent gains across tasks).
- Assumptions/Dependencies: Needs a pre-trained diffusion model trained on PV-VAE latents; further domain-specific fine-tuning often required; compute for feature extraction may be server-side.
- Proxy video representations for internal production workflows
- Sector: studios, VFX, ad agencies
- Tools/Workflows: Use PV-VAE latents as coherent low-bandwidth proxies for timeline scrubbing, preview, or collaborative review where temporal stability matters more than perfect fidelity.
- Assumptions/Dependencies: Not a drop-in video codec; reconstruction quality is good but not optimized for compression standards; integration into asset pipelines needed.
- Sustainability and budget optimization
- Sector: enterprise ML, research labs, public-sector AI projects
- Tools/Workflows: Use PV-VAE to shorten training time and memory use for generative backbones, reducing energy use and cloud/GPU costs.
- Assumptions/Dependencies: Savings depend on retraining costs and pipeline maturity; realized only if PV-VAE is widely adopted in the stack.
- Predictive preview for creative workflows
- Sector: content creation, storyboarding, pre-visualization
- Tools/Workflows: Given a partial clip, use the PV-VAE decoder to predict short-horizon future frames for quick motion previews or storyboard ideation.
- Assumptions/Dependencies: Works best for short horizons and natural motion; longer predictions may degrade; UI/tooling integration required.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or ecosystem development before broad deployment.
- Transformer-based video VAE for long-form, high-resolution generation
- Sector: media/entertainment, gaming, advertising
- Tools/Workflows: Migrate PV-VAE to a ViT-based tokenizer for long videos and faster inference; pair with predictive reconstruction for scalable training.
- Assumptions/Dependencies: Current transformer variant underperforms generatively; needs architectural optimization, training recipes, and larger datasets.
- World models for robotics and autonomous systems
- Sector: robotics, autonomous vehicles, embodied AI
- Tools/Workflows: Use motion-aware predictive latents as the backbone for model-based RL, trajectory forecasting, and planning (predictive world modeling).
- Assumptions/Dependencies: Requires multi-sensor fusion (RGB, depth, IMU, LiDAR), longer-horizon prediction, safety validation, and training on egocentric datasets.
- Medical video forecasting, augmentation, and analysis
- Sector: healthcare (ultrasound, endoscopy, surgical video)
- Tools/Workflows: Adapt PV-VAE to predict and analyze physiological motion, generate high-quality augmentations for scarce data, and assist anomaly detection.
- Assumptions/Dependencies: Strict regulatory constraints, privacy, clinician-in-the-loop validation, domain-specific training; explainability requirements.
- Motion-aware video retrieval and indexing
- Sector: media asset management, social platforms, sports archives
- Tools/Workflows: Index catalogs using PV-VAE embeddings that emphasize temporal dynamics for better search (e.g., “find clips with rotating object”).
- Assumptions/Dependencies: Requires scalable indexing, embeddings alignment with text queries, and integration with existing search infrastructure.
- Real-time AR/VR latency reduction via short-horizon prediction
- Sector: AR/VR hardware/software, gaming
- Tools/Workflows: Use PV-VAE-inspired predictors to estimate the next frames to reduce motion-to-photon latency or smooth motion in headsets.
- Assumptions/Dependencies: On-device inference constraints, aggressive model compression/distillation, robustness to edge-case motions.
- Edge-friendly analytics through distillation
- Sector: smart cameras, retail analytics, drones
- Tools/Workflows: Distill PV-VAE’s motion-aware features into compact models for on-device tracking and flow estimation.
- Assumptions/Dependencies: Requires effective distillation pipelines, energy constraints, and privacy-preserving deployment.
- Self-supervised pretraining curricula for video understanding
- Sector: academia, enterprise AI
- Tools/Workflows: Combine predictive reconstruction with masked spatiotemporal modeling to pretrain backbones for action recognition, segmentation, and tracking.
- Assumptions/Dependencies: Large-scale unlabelled video corpora; compute budgets; transferability across domains.
- Enhanced text fidelity in generative video
- Sector: advertising, brand content, education
- Tools/Workflows: Extend PV-VAE with text-focused data and objectives (e.g., auxiliary OCR losses) to fix current limitations in dense text reconstruction.
- Assumptions/Dependencies: Need text-heavy datasets and new loss terms; careful balance to preserve diffusability.
- Provenance, watermarking, and detection in a high-quality generation era
- Sector: policy, platform trust & safety
- Tools/Workflows: Develop watermarking and detection mechanisms tailored to motion-aware latent spaces; audit tools that exploit temporal signatures for provenance.
- Assumptions/Dependencies: PV-VAE improves coherence, potentially making detection harder; requires standards alignment and cross-vendor collaboration.
- Scalable video search-by-dynamics for education and science
- Sector: education technology, scientific communication
- Tools/Workflows: Create tools to search and generate content based on temporal patterns (e.g., “demonstrate centripetal motion”) leveraging PV-VAE embeddings.
- Assumptions/Dependencies: Requires robust alignment between dynamics descriptors and user intents; dataset coverage of target phenomena.
Notes on Cross-Cutting Dependencies
- Data: Generalization beyond benchmarks (UCF101, RealEstate10K, Kinetics-400) depends on diverse, higher-resolution, and text-rich datasets.
- Compute: Although training is faster and more memory-efficient relative to baselines, large-scale deployment still requires substantial GPU resources.
- Integration: Best results require retraining or fine-tuning diffusion models on PV-VAE latents and adopting the multi-stage training recipe (including decoder fine-tuning).
- Evaluation: Improvements are primarily measured by FVD/KVD and downstream probes; production metrics (e.g., user preference, brand text accuracy, long-horizon stability) may need bespoke validation.
Glossary
- 3D causal convolutions: 3D convolutions constrained to use only past and present along time, preserving causality. "We implement PV-VAE with 3D causal convolutions,"
- AdamW optimizer: An Adam variant with decoupled weight decay for better regularization. "We adopt the AdamW optimizer"
- adjacency coherence: A notion of short-term temporal smoothness measuring consistency between adjacent frames or latents. "PV-VAE achieves higher adjacency coherence than the baseline."
- Area Under the Curve (AUC): An aggregate metric measuring performance across error thresholds; here for tracking accuracy. "We report the Area Under the Curve (AUC) of tracking accuracy across error thresholds from 0 to 10 pixels."
- Average End-Point Error (EPE): The average pixel distance between predicted and ground-truth motion vectors in optical flow. "Performance is quantified by the Average End-Point Error (EPE)."
- C3D: A 3D convolutional neural network architecture commonly used for video recognition. "the pre-trained C3D model"
- class-conditional generation: Generating samples conditioned on class labels. "We use UCF101 for class-conditional generation"
- cosine schedule: A learning-rate schedule that decays the rate following a cosine function. "decayed by a factor of $10$ using a cosine schedule."
- “copy-shortcut”: A failure mode where a model copies static content instead of learning motion; discouraged via motion-focused loss. "To prevent the ``copy-shortcut'' of non-motion regions from dominating the optimization, we incorporate an additional motion-aware objective."
- decoder fine-tuning stage: A post-training phase where only the decoder is trained to improve reconstruction quality. "we introduce an additional decoder fine-tuning stage."
- diffusion features: Intermediate representations extracted from diffusion models, used as probes for understanding. "we examine the learned latent spaces through the lens of diffusion features"
- diffusability: Suitability of a latent space for effective diffusion-based generative modeling. "How to enhance the diffusability of video latents remains a critical and unresolved challenge."
- Euler sampler: A numerical solver used to sample from diffusion models via Euler discretization steps. "and is evaluated with an Euler sampler using 100 steps."
- Frechet Video Distance (FVD): A distributional metric comparing generated and real video statistics to assess quality. "we report Frechet Video Distance (FVD) and Kernel Video Distance (KVD)"
- GAN loss: An adversarial objective that pits generator against discriminator to improve realism. "an adversarial (GAN) loss"
- Inception Score (IS): A generative metric assessing both quality and diversity using a pretrained classifier. "we additionally report the Inception Score (IS) computed"
- Kernel Video Distance (KVD): A kernel-based distance measuring discrepancy between real and generated video distributions. "we report Frechet Video Distance (FVD) and Kernel Video Distance (KVD)"
- KL regularization term: The Kullback–Leibler divergence penalty that regularizes latent distributions in VAEs. "and a KL regularization term."
- Latent Temporal Distance (LTD): A metric quantifying temporal change by measuring distances between latents across frame intervals. "we introduce the Latent Temporal Distance (LTD) metric"
- Latent Video Diffusion Models (LVDMs): Diffusion models operating on compact video latents rather than pixels. "advances in Latent Video Diffusion Models (LVDMs)"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual similarity metric based on deep features. "a learned perceptual image patch similarity (LPIPS) loss"
- learnable tokens: Trainable embeddings used to fill or pad missing latent positions during training. "using learnable tokens following masked modeling practice"
- masked language/visual modeling (MLM/MVM): Self-supervised tasks predicting masked tokens or patches in sequences or images/videos. "masked language/visual modeling (MLM/MVM)"
- Mean Squared Error (MSE): Pixel-wise squared error loss for reconstruction. "including a mean squared error (MSE) loss"
- motion-aware objective: A loss encouraging models to focus on temporal differences and motion rather than static content. "we incorporate an additional motion-aware objective."
- optical flow: A dense per-pixel motion field describing apparent motion between frames. "including optical flow estimation"
- patchify downsampling module: A component that partitions inputs into patches (tokens) by downsampling for transformer processing. "we remove the patchify downsampling module of the Latte model"
- PCA (Principal Component Analysis): A dimensionality reduction technique projecting data onto principal components. "we perform PCA along the channel dimension of the latents"
- Peak Signal-to-Noise Ratio (PSNR): A logarithmic fidelity metric measuring reconstruction quality relative to signal power. "Peak Signal-to-Noise Ratio (PSNR)"
- pixel-shuffle operation: A sub-pixel convolution technique for efficient upsampling by rearranging channels into spatial dimensions. "using a pixel-shuffle operation."
- point tracking: Following the trajectory of specific points across video frames. "and point tracking"
- predictive learning: Learning representations by predicting future states from past observations. "we investigate the potential of predictive learning to improve the video generative modeling."
- predictive reconstruction objective: A training objective combining reconstruction of observed frames with prediction of future frames. "we introduce a simple and effective predictive reconstruction objective"
- RAFT: A state-of-the-art optical flow estimator based on all-pairs field transforms. "optical flow computed by RAFT"
- rectified flow: A generative training paradigm that straightens probability flows to accelerate and stabilize sampling. "The generation model is trained using rectified flow for 250K steps"
- reconstruction FVD (rFVD): FVD computed between original and reconstructed videos to assess reconstruction fidelity. "we report reconstruction FVD (rFVD)"
- spatial compression ratio: The factor by which spatial dimensions are reduced from pixels to latents. "Here, and are the spatial and temporal compression ratios"
- Structural Similarity Index Measure (SSIM): A perceptual metric assessing structural similarity between images. "Structural Similarity Index Measure (SSIM)"
- temporal compression ratio: The factor by which the temporal dimension is reduced from frames to latent steps. "we first partition the video clip into groups based on the temporal compression ratio ,"
- Transformer-based latent diffusion model: A diffusion model leveraging transformer backbones to operate on latent tokens. "a Transformer-based latent diffusion model"
- uninformative prior: A prior distribution that conveys minimal information about the data. "sampled from an uninformative prior (i.e., containing no input information)."
- unconditional video generation: Generating videos without conditioning on labels or inputs. "both class-conditional and unconditional video generation"
- Vision Transformers (ViT): Transformer architectures adapted for vision tasks using patch embeddings. "Despite the dominance of Vision Transformers (ViT) across most vision tasks"
- wavelet-based methods: Techniques leveraging wavelet transforms for efficient representation or compression. "utilize wavelet-based methods"
Collections
Sign up for free to add this paper to one or more collections.