- The paper introduces a novel sample-wise metric to quantify forgetting and backward transfer, addressing limitations of aggregate measures.
- It demonstrates that scaling model size reduces forgetting and enhances backward transfer, with domain-continual pretraining and instruction tuning showing distinct benefits.
- Model merging strategies do not reliably mitigate post-training forgetting, highlighting the need for further exploration of weight drift and integration scales.
Mapping Post-Training Forgetting in LLMs at Scale
Introduction
The paper "Mapping Post-Training Forgetting in LLMs at Scale" proposes a novel sample-wise methodology to measure forgetting and backward transfer in post-training of LMs. It highlights significant challenges and insights regarding the post-training stages, model sizes, and data scales. Traditional methods aggregate task accuracy, potentially obscuring large changes. The research aims to clarify how post-training processes affect pretrained knowledge at a granular level.
Methodology
The authors introduce a new metric for evaluating forgetting and backward transfer. Forgetting is defined as transitions from a correct pre-training output to an incorrect post-training output (1→0), while backward transfer is marked by transitions from incorrect to correct outputs (0→1). This sample-wise method resolves outcomes at the item level, thus addressing the insufficiencies of traditional aggregate metrics.
The methodology also introduces chance-adjusted variants to account for randomness in multiple-choice questions, which are critical to accurately capturing genuine transitions. The metrics are robust without requiring detailed computations of logits, making them scalable across various settings.
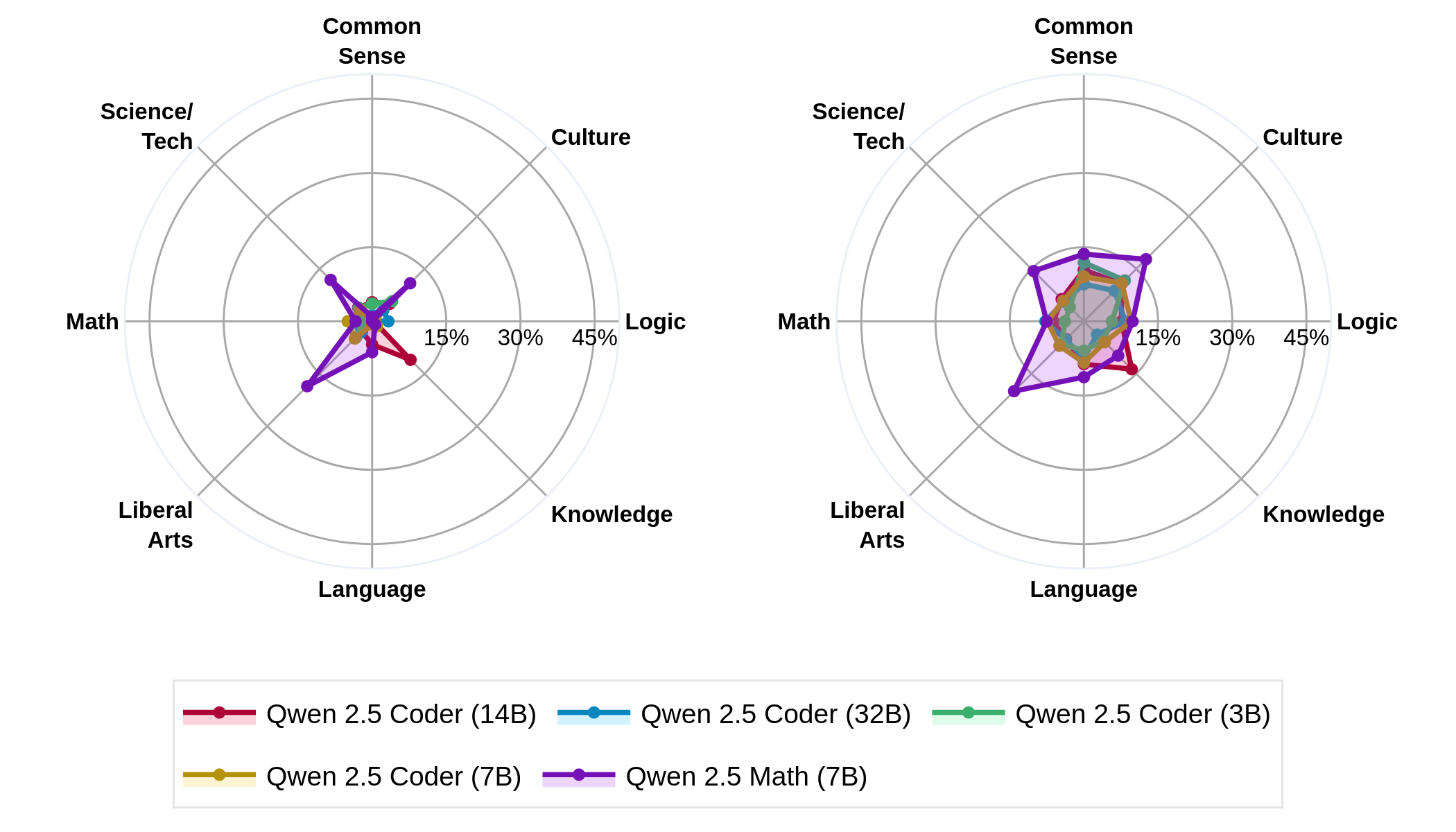
Figure 1: Coder model comparing conventional forgetting (left) against our sample-wise forgetting (right). More forgetting is uncovered when using the sample-wise forgetting metric.
Findings
Domain-Continual Pretraining
Domain-Continual Pretraining generally induces low-to-moderate forgetting. The backward transfer is minimal, although larger model scales show reduced forgetting. This indicates that the prevalent practice of domain-continual pretraining mitigates some catastrophic forgetting seen in other studies.
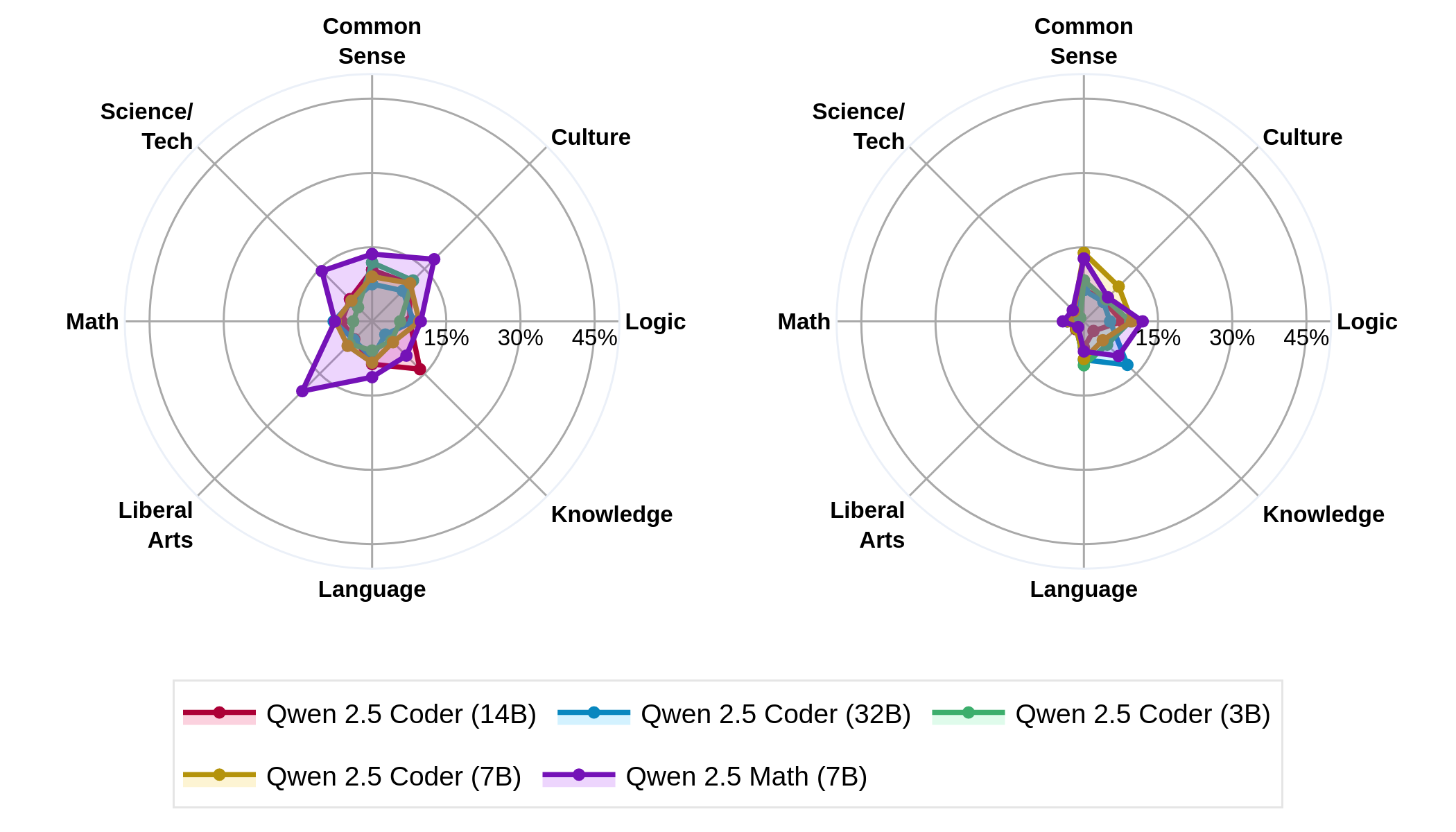
Figure 2: Forgetting (left) and Backward Transfer (right) after domain-continual pretraining. Forgetting is low-to-moderate and consistent across categories; backward transfer is low. Scaling model size reduces forgetting.
Instruction Tuning
Instruction tuning yields moderate backward transfer, especially in math-related tasks, with low-to-moderate levels of forgetting across various models. Increased model scale reduces both forgetting and enhances backward transfer capabilities, thereby improving task adherence and utility of LMs in practical scenarios.
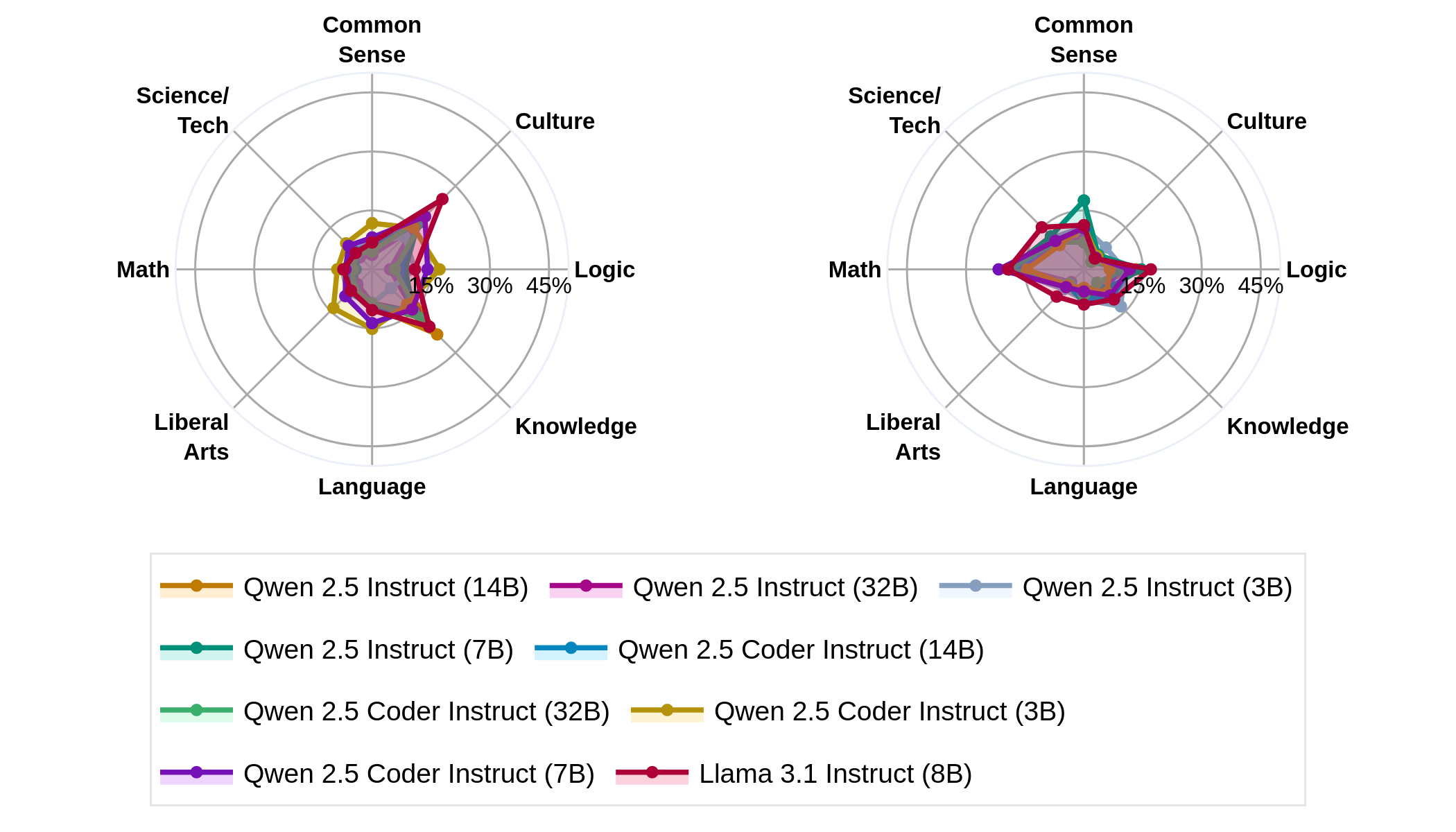
Figure 3: Forgetting (left) and Backward Transfer (right) after instruction-tuning yields moderate forgetting and backward transfer categories-wise. Scaling model size reduces forgetting and backward transfer.
Training with Reasoning Traces
This aspect is divided into two scenarios: low and high data scales. For low-data regimes, little forgetting and backward transfer were observed. Conversely, the high-data scenario lacked a single dominant factor to explain the dynamics, reflecting variability in training outcomes based on data diversity and quality.
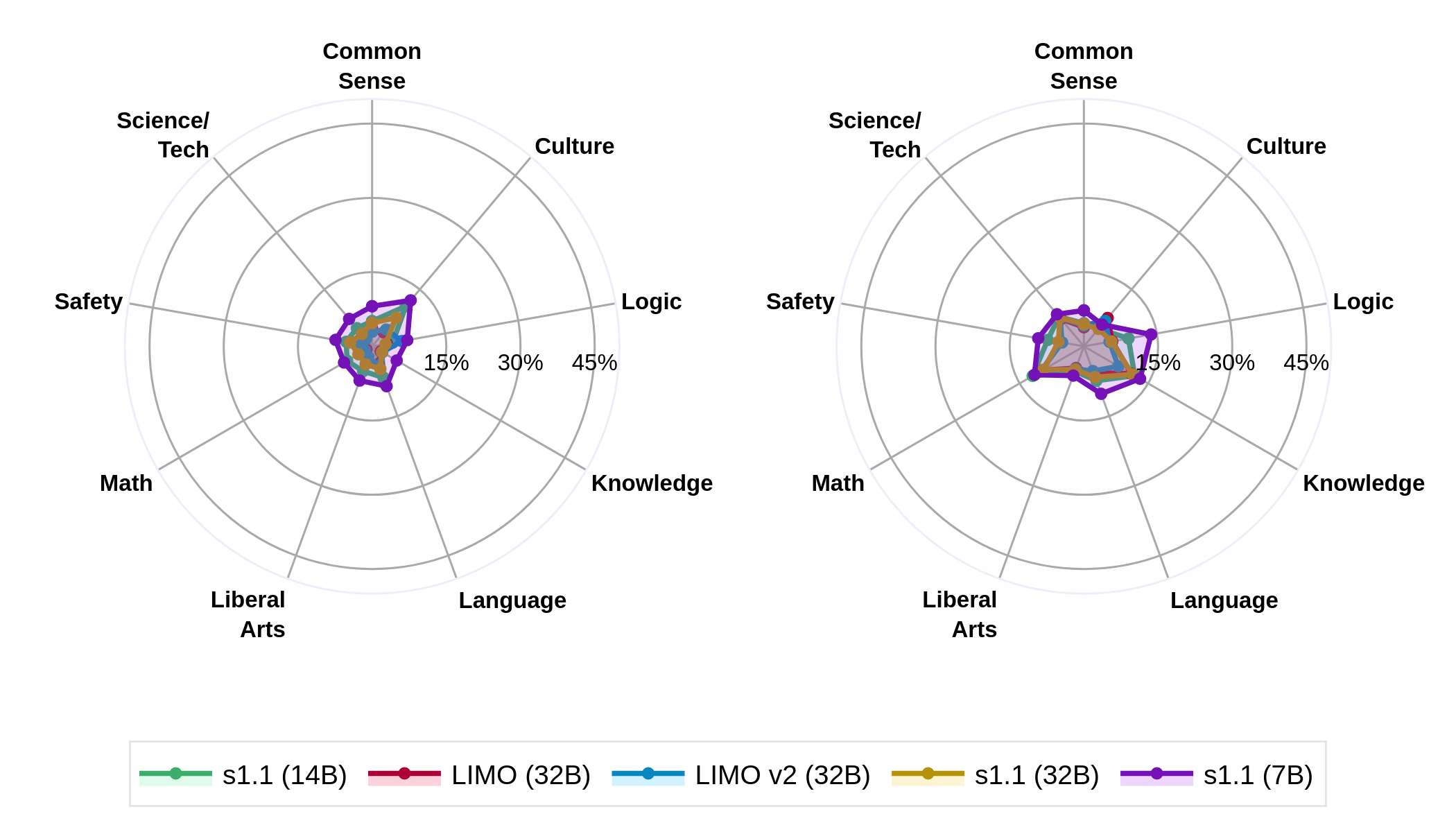
Figure 4: Forgetting (left) and Backward Transfer (right) after reasoning training from instruct: low data scenario. Yields little forgetting and backward transfer. Forgetting decreases with model scale.
Model Merging
The paper also examines model merging tactics, finding that they do not reliably mitigate forgetting in post-training pipelines. While promising, further exploration is necessary to understand the variabilities influencing success in model merging, particularly concerning model weight drift and integration scales.
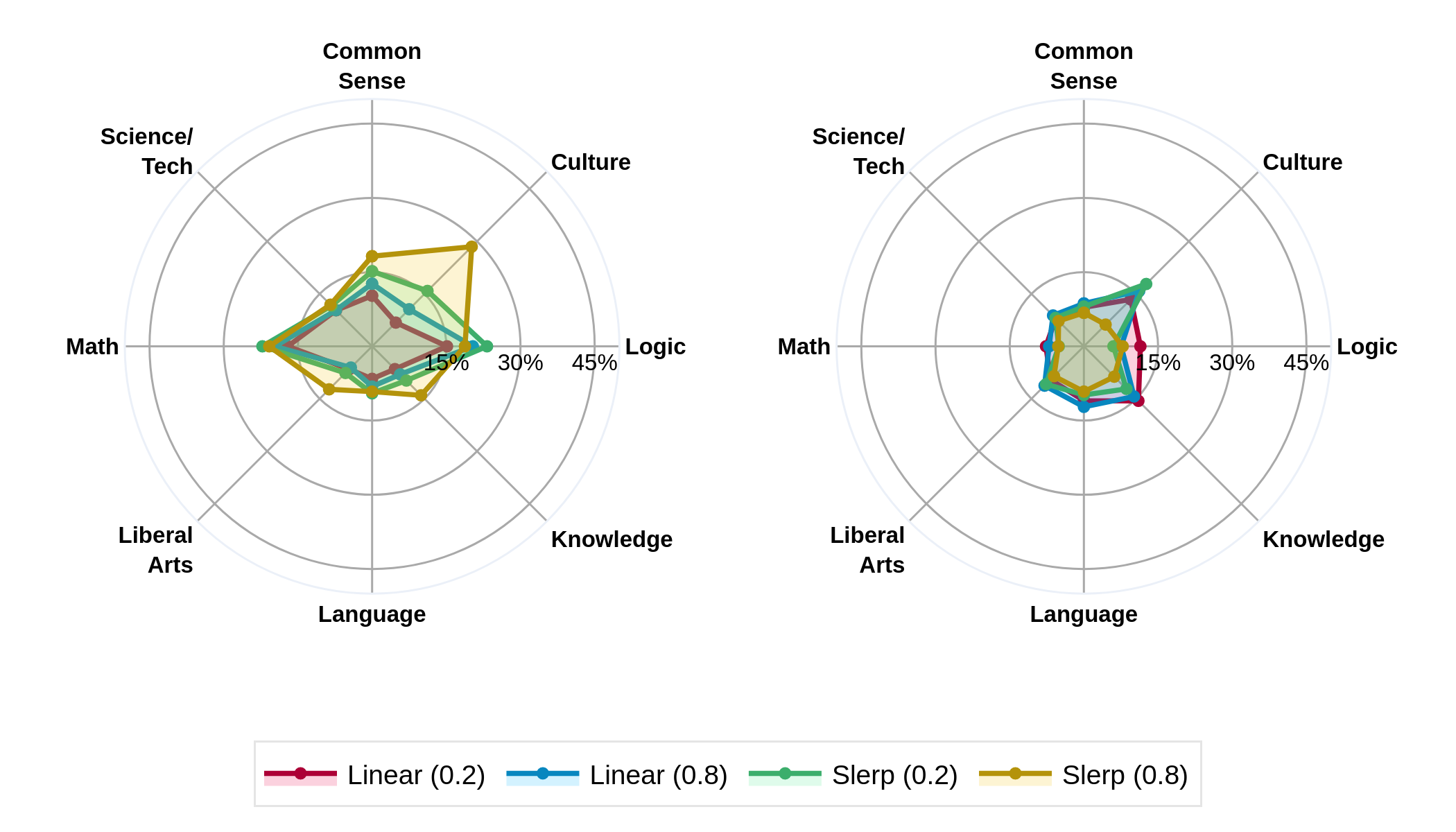
Figure 5: Forgetting and Backward Transfer of Qwen 2.5 Base merged with Qwen 2.5 Coder (7B) relative to Qwen2.5 Coder. Induces moderate forgetting and little backward transfer.
Conclusion
The research presents a refined metric for assessing post-training forgetting in LMs, highlighting the complex interplays between model scale, data diversity, and training objectives. The findings stress the importance of nuanced metrics over simplistic aggregate measures to guide future studies aiming to minimize forgetting and enhance backward transfer. Promising avenues include refining training objectives, leveraging synthetic corpora, and implementing retrieval mechanisms. The paper builds a pivotal foundation for enhancing the understanding of continual learning in large-scale AI systems.

