- The paper introduces SANTA and S²ANTA, unbiased stochastic estimators that use Monte Carlo sampling to replace dense value aggregation and improve memory and compute efficiency.
- It proposes variance reduction via stratified and systematic sampling, recovering over 97% of SDPA performance while using less than 20% of typical value-cache accesses.
- The study details hardware-friendly implementations and joint key-value sparsification, achieving 1.5× speedups in long-context transformer inference with minimal accuracy loss.
Stochastic Sparse Attention for Memory-Bound Inference: An Expert Analysis
Introduction and Motivation
The increasing prevalence of long-context autoregressive decoding in transformer-based LLMs has foregrounded a fundamental systems constraint: the memory bandwidth bottleneck incurred by repeated key-value (KV) cache reads during token generation. Even with optimized decoding kernels and aggressive quantization/compression, this bottleneck persists due to the quadratic scaling of value retrieval per token. The paper "Stochastic Sparse Attention for Memory-Bound Inference" (2605.01910) addresses this limitation by introducing Stochastic Additive No-mulT Attention (SANTA) and its variance-reduced variants (S2ANTA), which sparsitfy value-cache access with stochastic estimation and effectively eliminate multiplications post-softmax, yielding substantial memory and compute efficiency while maintaining token-level accuracy.
SANTA: Unbiased Stochastic Estimation of Post-Softmax Value Aggregation
SANTA reframes the standard scaled dot-product attention by replacing the dense aggregation over value vectors V with a Monte Carlo estimator. For each query q, rather than deterministically acquiring all nk value rows weighted by the softmaxed attention vector A, SANTA samples S≪nk indices according to A and aggregates only the corresponding V rows (with normalization). This results in an unbiased estimator of the attention output, with variance scaling as $1/S$. Crucially, all value-stage post-softmax multiplications are eliminated: the estimator is implemented via gather and addition only. Normalization by S can be efficiently realized as a bit-shift for power-of-two choices of V0 in fixed-point hardware.
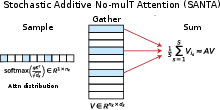
Figure 1: SANTA requires V1 memory accesses to sampled rows of V2, eliminating multiplications following the softmax operation.
Variance Reduction via Stratified and Systematic Sampling (V3ANTA)
While baseline SANTA is unbiased, its variance can be limiting at low V4 in practical deployments. V5ANTA mitigates this by dividing the attention distribution's CDF into V6 equal strata and sampling one index per stratum—either independently (stratified, V7ANTA-strat) or with a single shared offset (systematic, V8ANTA-sys). Both estimators remain unbiased; V9ANTA-strat theoretically dominates in variance reduction, but empirical results show comparable performance for systematic sampling. Notably, systematic sampling requires just a single random seed, which is advantageous for hardware-friendly implementations.
GPU Kernel Implementations of q0ANTA
Directly mapping SANTA/Sq1ANTA to parallel hardware poses challenges due to the global-sampling dependency on the softmax distribution. The authors design two CUDA kernels:
- q2ANTA-prop: Allocates sampling budgets to tiles proportionally based on the computed probability mass, using a lightweight global synchronization to assign sample counts before value aggregation.
- q3ANTA-flash: Adopts speculative local sampling with deferred normalization, assigning uniform sample budgets across all tiles for maximal parallelism; under-sampled tiles are down-weighted post-hoc, leading to some sample inefficiency ("sample waste").
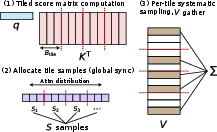
Figure 2: q4ANTA-prop kernel overview.
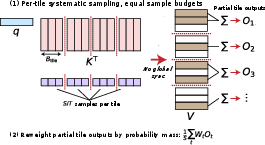
Figure 3: q5ANTA-flash kernel overview.
In benchmarking on Llama 8B tensor geometries at context length 32k, q6ANTA-prop with q7 and q8ANTA-flash with q9 both yield a nk0 kernel speedup relative to FlashInfer, while preserving baseline accuracy across multiple evaluation tasks.
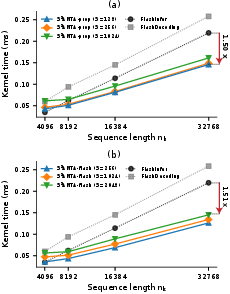
Figure 4: nk1ANTA kernel latency on Llama 8B tensor shapes for 1 decoding step. (a) nk2ANTA-prop demonstrates a 1.50nk3 speedup relative to FlashInfer at a 32k-token context. (b) nk4ANTA-flash similarly exhibits a 1.51nk5 speedup. Both operating points (S=128 for prop, S=2048 for flash) correspond to configurations that recover baseline accuracy.
Empirical Results: Accuracy vs. Efficiency Trade-offs
Across GSM8K, MMLU, and long-context reasoning benchmarks, SANTA and nk6ANTA exhibit tunable trade-offs between computational cost and accuracy. For Snk7ANTA (stratified/systematic), operating at sample budgets nk8 constituting nk9 of the typical sequence length can recover A0 of SDPA performance. The long-context regime amplifies the advantage: for 32k-token prompts with budget A1, SA2ANTA-prop accesses only 1.56% of A3 per step, delivering kernel-level speedups with negligible accuracy degradation. Notably, variance-reduced SA4ANTA dominates both naïve top-A5 attention and default SANTA in both efficiency and robustness for heavy-tailed or multi-hop tasks.
Empirically measured variance confirms the theoretical A6 scaling for SANTA and improved variance constants for SA7ANTA variants.
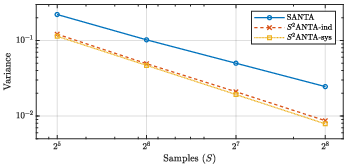
Figure 5: Empirical variance of SANTA on single-hop QA prompts (8k tokens).
Stochastic Key Sparsification: Bernoulli A8 Sampling
While SANTA addresses value-stage bandwidth, the authors further propose Bernoulli A9 sampling for the score stage, representing S≪nk0 elements as Bernoulli variables yielding ternary vectors (S≪nk1). This estimator induces sparsity over the S≪nk2 matrix, enabling significant feature pruning in memory-bound decoding regimes while remaining unbiased. For stratified sampling with S≪nk3 on GSM8K (BitNet 2B), the method recovers SDPA-level accuracy while accessing only 67.5% of key features per head. Accuracy versus access fraction is task- and model-dependent, with quantized or low-rank models (e.g., BitNet) exhibiting greater error tolerance.
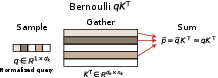
Figure 6: Bernoulli S≪nk4 approximates attention scores via ternary queries, pruning features dimension-wise.
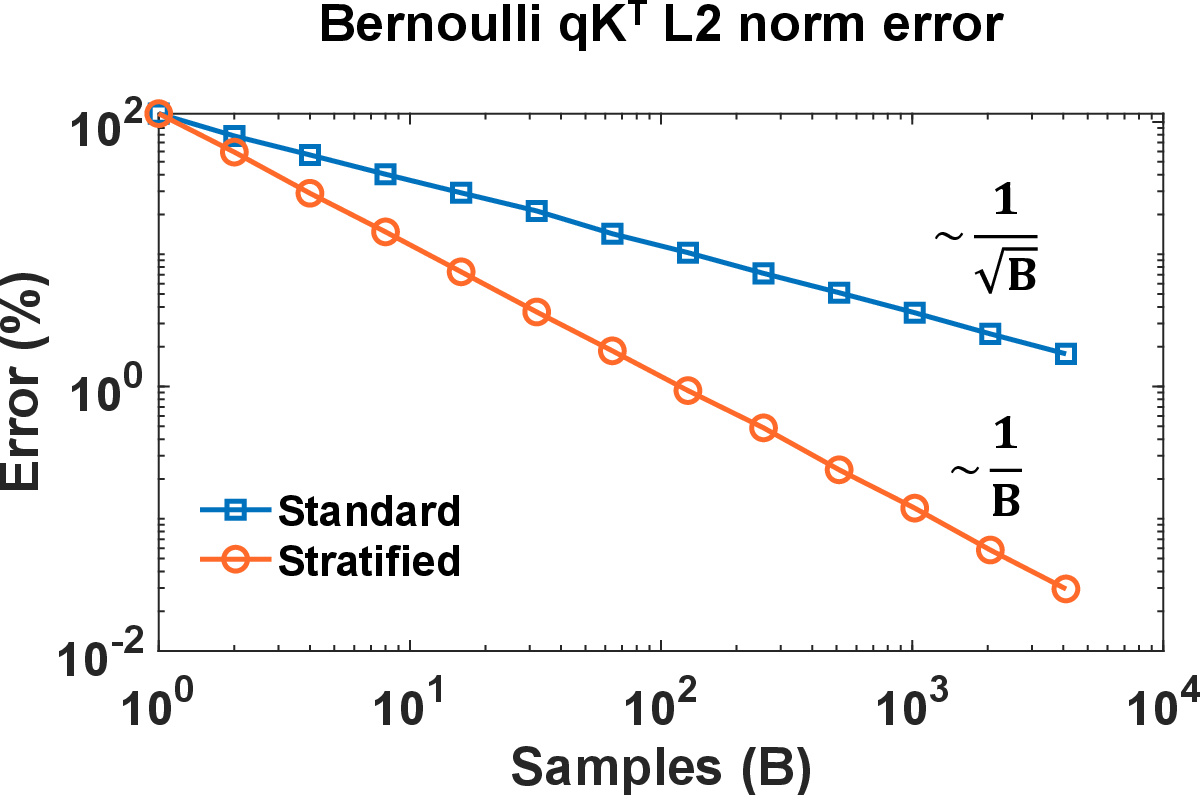
Figure 7: Mean L2 norm error for Bernoulli S≪nk5. The score error is calculated during decoding with S≪nk6, a context length S≪nk7, and averaged over 100 instances.
Joint Key-Value Sparsification and Multiplier-Free Inference
SANTA and Bernoulli S≪nk8 are orthogonal estimators; their combination enables simultaneous sparsification of both key and value accesses. On arithmetic reasoning tasks, their joint application can reduce key access by 15% and value reads by up to 90%, while maintaining accuracy within 2% of the full SDPA baseline. The predominantly additive implementation paves the way for efficient deployment on emerging adder-centric AI accelerators.
Layer-Wise Adaptation and Reinforcement Learning Budgeting
Detailed ablation studies reveal layer-specific sensitivities to stochastic approximations. Applying the most severe approximation (single-sample, one-hot attention) to specific layers can lead to catastrophic degradation, while others show high tolerance. Leveraging this observation, a reinforcement learning policy can learn a layer-wise sample allocation schedule under a fixed global budget, yielding performance improvements over uniform allocation.
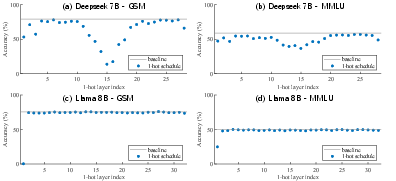
Figure 8: Ablations with one-hot stochastic attention; accuracy degradation is highly layer-dependent.
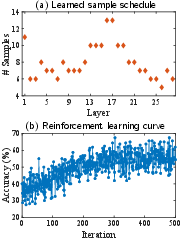
Figure 9: Learned schedule with a total budget of 224 samples across all 28 transformer blocks (DeepSeek 7B); RL optimizes sample allocation over layers.
Distributed Training and System Considerations
The practical training of the RL scheduler is facilitated via a Kubernetes-based distributed system, enabling scalable asynchronous evaluation of layer-wise sample schedules.
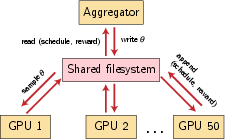
Figure 10: Kubernetes deployment schematic for distributed RL allocation of layer-wise sampling schedules.
Practical and Theoretical Implications
The SANTA/SS≪nk9ANTA methodology offers a flexible trade-off between computational efficiency and model accuracy, making it particularly suitable for memory-bound, long-context scenarios. The unbiased nature of the estimator and its strong empirical performance distinguish it from both truncation-based top-A0 and deterministic structured-sparseness approaches, especially on tasks with non-concentrated attention distributions. Orthogonality to quantization, GQA, and KV-cache management makes it composable with many prevailing inference optimizations.
On hardware, the additive and sparse design aligns naturally with next-generation inference accelerators focused on minimizing data movement and multiplier energy. On the algorithmic side, further exploration of hybrid score+value sparsification and adaptive per-layer sampling schedules are promising research directions.
Conclusion
This work provides a theoretically grounded and empirically validated path to reducing the memory and compute requirements of transformer inference in long-context settings. SANTA and its variance-reduced variants (A1ANTA), complemented by Bernoulli A2 score estimation, enable multiplier-free, bandwidth-efficient KV-cache utilization with a controllable accuracy/efficiency dial. The approach not only yields measurable speedups and memory savings but also demonstrates robustness across a spectrum of challenging reasoning and retrieval tasks. Integrating these techniques into standard toolchains and hardware is likely to be a key lever for scaling efficient sequence modeling in practical deployment scenarios.