- The paper introduces the VideoThinker framework, which decouples spurious shortcut pathways from genuine causal reasoning using a repulsive RL objective.
- It employs a Bias Model and Causal Debiasing Policy Optimization to reduce shortcut exploitation, leading to state-of-the-art performance across diverse benchmarks.
- Empirical evaluations reveal marked improvements in inferential accuracy and robust generalization, even in resource-constrained, 3B-parameter MLLMs.
Causal Debiasing for Lightweight Video Reasoning: The VideoThinker Framework
Introduction
The computational and generalization limitations of lightweight Multimodal LLMs (MLLMs) pose a significant challenge for robust video reasoning, particularly when deployed in resource-constrained scenarios. Reinforcement learning (RL)-based post-training protocols have been shown to enhance reasoning in large MLLMs but do not yield similar improvements in lightweight configurations due to the emergence of shortcut learning behaviors. The paper "Beyond Perceptual Shortcuts: Causal-Inspired Debiasing Optimization for Generalizable Video Reasoning in Lightweight MLLMs" (2605.01324) systematically characterizes the failure regime induced by RL fine-tuning in 3B-parameter MLLMs and proposes a theoretically principled debiasing solution, VideoThinker, that decouples spurious shortcut pathways from causal reasoning.
Diagnosing Perceptual Shortcuts in Video Reasoning
A central empirical finding is that RL fine-tuning, rather than enhancing reasoning, encourages compact MLLMs to adopt perceptual shortcuts dominant in prevalent datasets. The bias arises from an overwhelming proportion of "observational" questions, which can be trivially solved via pattern matching to visible content, compared to "inferential" questions, which necessitate genuine causal/counterfactual reasoning. When exposed to such imbalanced supervision, smaller models (3B) under RL fine-tuning demonstrate an acute "capability conflict," where inferential accuracy drops precipitously even as observational performance remains flat or improves.
This phenomenon is illustrated by a breakdown of counterfactual tasks in CLEVRER, where 74% of samples are observational. Fine-tuning a strong pretrained model with GRPO results in a substantial inferential accuracy drop from 73.9% to 63.1%, empirically confirming that classical RL protocols amplify shortcut utilization at the expense of reasoning.
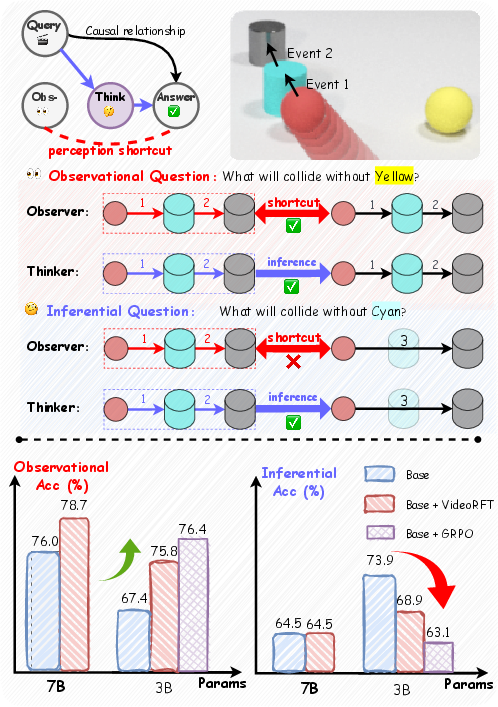
Figure 1: Observational (shortcut-vulnerable) versus inferential (reasoning-critical) tasks, and the trade-off in model performance with RL fine-tuning.
Causal Analysis: A Structural Perspective
The shortcut adoption is formalized using Structural Causal Models (SCM). Input queries (Q) act as confounders, providing two information streams: one leading to superficial observation (O), and the other to latent causal thinking (T). The presence of a backdoor path Q→O→A allows answers (A) to be determined by spurious correlation, subverting the intended causal chain Q→T→A. In practical RL, the overwhelming prevalence of observational samples ensures that the shortcut pathway is reinforced during policy optimization, especially for limited-capacity networks lacking strong intrinsic reasoning priors.
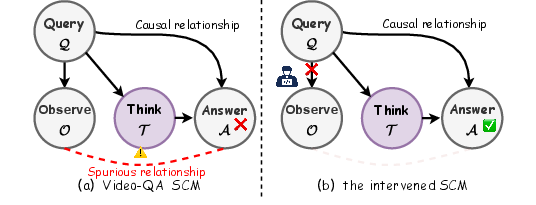
Figure 3: Causal model (SCM) illustrating confounding between input, observation, latent reasoning, and answer pathways. Intervention requires blocking the spurious shortcut.
The VideoThinker Framework
Bias Model Construction
Debiasing begins by making the shortcut pathway explicit. A Bias Model is trained to specialize in shortcut exploitation. This is achieved by isolating observational questions from annotated datasets (e.g., CLEVRER) via programmatic event matching, resulting in a dataset tailored to pure perceptual pattern matching. The bias model is trained on this subset without regularizing toward any reference policy, thus maximizing its alignment with spurious observation-based answers.
Causal Debiasing Policy Optimization (CDPO)
The primary model is then fine-tuned with a repulsive RL objective, termed Causal Debiasing Policy Optimization (CDPO). The critical element is the maximization of the Kullback-Leibler divergence between the main policy and the fixed bias model. This flips the standard regularization protocol: instead of constraining adaptation toward a reference, the model is actively discouraged from adopting the distributional patterns of the bias proxy. The optimization thus enforces reward maximization for correct answers while penalizing shortcut-driven behaviors.
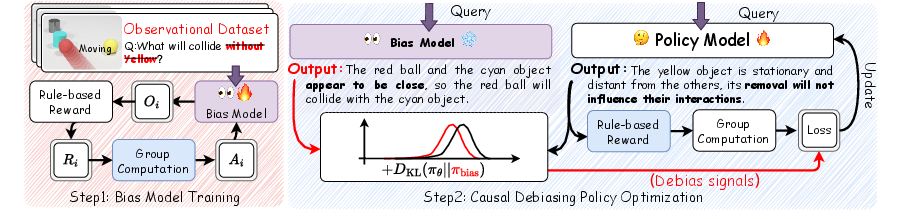
Figure 5: The VideoThinker pipeline, which combines a learned bias model (shortcut proxy) and a CDPO objective to force the main model toward genuine reasoning.
This CDPO approach is an efficient, differentiable relaxation of intractable backdoor adjustments in SCMs, trading marginalization for adversarial gradient-based repulsion.
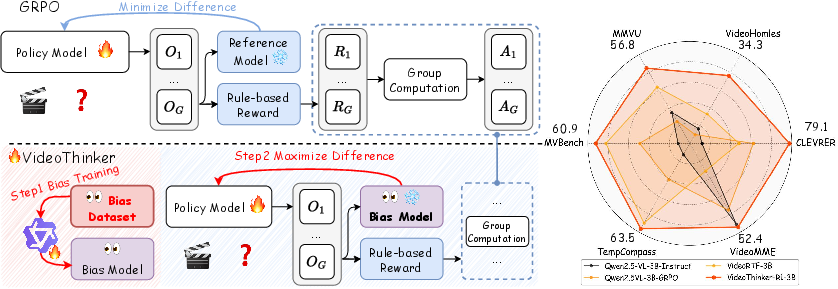
Figure 4: Schematic comparison: standard RL minimization (top) pulls toward the reference (often reinforcing bias); CDPO (bottom) repels away from the bias model, promoting robust reasoning. Empirical results (radar chart) show SOTA generalization.
Empirical Evaluation
Same-Scale and Cross-Scale Generalization
VideoThinker-R1 (3B) establishes new SOTA results on six challenging benchmarks, including both reasoning-centric (CLEVRER, VideoHolmes, MMVU) and general-purpose (MVBench, TempCompass, VideoMME) evaluation sets. Notably, it surpasses the best 3B model, VideoRFT-3B, by 7.0% on VideoMME, and even outperforms the 7B Video-UTR model by 2.1% on MVBench and 3.8% on TempCompass, despite using only 1% of RL data and no SFT.
Robustness and Ablations
Ablation studies confirm that the combination of (i) a sharply defined bias proxy and (ii) KL divergence maximization is essential for performance. Reference models lacking explicit shortcut bias (e.g., generic strong models or self-repulsion) yield weaker gains or even degrade inference. The debiasing hyperparameter β yields a classic bias-variance trade-off, but robust generalization is attained for a wide range of β in diverse tasks.
Qualitative Analysis
Qualitative review further distinguishes VideoThinker-R1's reasoning chains from baseline failures. Where baseline models default to surface cues—which may be internally plausible but logically inconsistent—VideoThinker-R1 constructs coherent, causally entailed explanations and is more sensitive to the unanswerability of ill-posed or ambiguous queries.
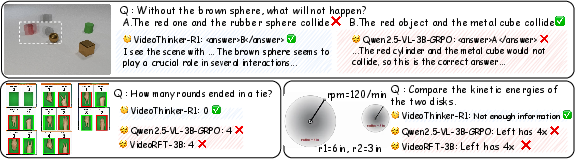
Figure 2: VideoThinker-R1 provides coherent, causally grounded reasoning paths on CLEVRER and MMVU cases, while baseline models collapse to shortcut-driven or inconsistent outputs.
Theoretical and Practical Implications
The formal diagnosis and solution for perceptual shortcut overfitting deepen the understanding of failure modes in RL alignment of compact MLLMs. From a theory perspective, the work demonstrates the necessity of explicit structural interventions—inspired by causal graphical models—in RL-based alignment, particularly for tasks with weak or polluted supervision signals. Practically, VideoThinker extends the practical range of RL-finetuned MLLMs to edge and efficient settings, showing that strong generalization is possible with minimal data and computational resources if shortcut paths are directly targeted.
Future Directions
Several promising future directions emerge:
- Weak supervision recovery: Extension of targeted debiasing to other weakly supervised or imbalanced domains, including spatial, temporal, and multi-hop video reasoning, as well as real-world long-tail task distributions.
- Model scaling: Investigation into how explicit shortcut identification and repulsion generalize for even smaller (sub-3B) or larger-scale models where intrinsic reasoning capacity varies.
- General causal alignment: Integration of the CDPO protocol with unsupervised causal discovery and augmentation pipelines for end-to-end robust MLLM alignment.
Conclusion
"Beyond Perceptual Shortcuts: Causal-Inspired Debiasing Optimization for Generalizable Video Reasoning in Lightweight MLLMs" (2605.01324) provides a rigorous diagnosis of RL-induced shortcut degeneration in compact MLLMs and demonstrates that explicit causal debiasing—via a repulsive policy objective against a learned shortcut proxy—not only repairs this failure mode but achieves SOTA video reasoning generalization with efficiency. This work establishes a replicable baseline for robust, practical MLLMs and motivates further research in causal-aware RL alignment for multimodal reasoning.