- The paper introduces a novel persona-induced latent variable model using LLM outputs to define priors for adaptive querying.
- The methodology employs closed-form Bayesian updates and decision-theoretic query selection to efficiently reduce uncertainty under budget constraints.
- Empirical results on synthetic and real-world datasets demonstrate rapid prediction error reduction, outperforming traditional CAT and IRT baselines.
Adaptive Querying with AI Persona Priors: A Comprehensive Analysis
Introduction and Motivation
This paper addresses the adaptive querying problem in interactive data collection, particularly under constrained budgets typical of psychometric measurement, recommender systems, and survey inference. The essential challenge is to accurately model user-specific uncertainty about latent traits or held-out responses with only a few allowable queries. Traditional methods—classical Bayesian experimental design (BED), computerized adaptive testing (CAT), and item response theory (IRT)—foundationally rely on either restrictive parametric models or intractable posterior inference in high dimensions, both of which limit their ability to handle population heterogeneity and cold-start regimes.
The key proposal is the use of AI-generated personas, leveraging LLMs to produce a dictionary of response distributions associated with semantically-meaningful textual profiles. A persona-induced latent variable model is then constructed, using offline LLM outputs to specify the prior over user responses. Online, inference proceeds by sequential Bayesian updating over persona assignment, enabling efficient, interpretable, closed-form inference and decision-theoretically justified query selection. This approach sidesteps the calibration requirements and exhaustive parameter estimation of CAT/IRT, offering immediate applicability in new domains and for new items.
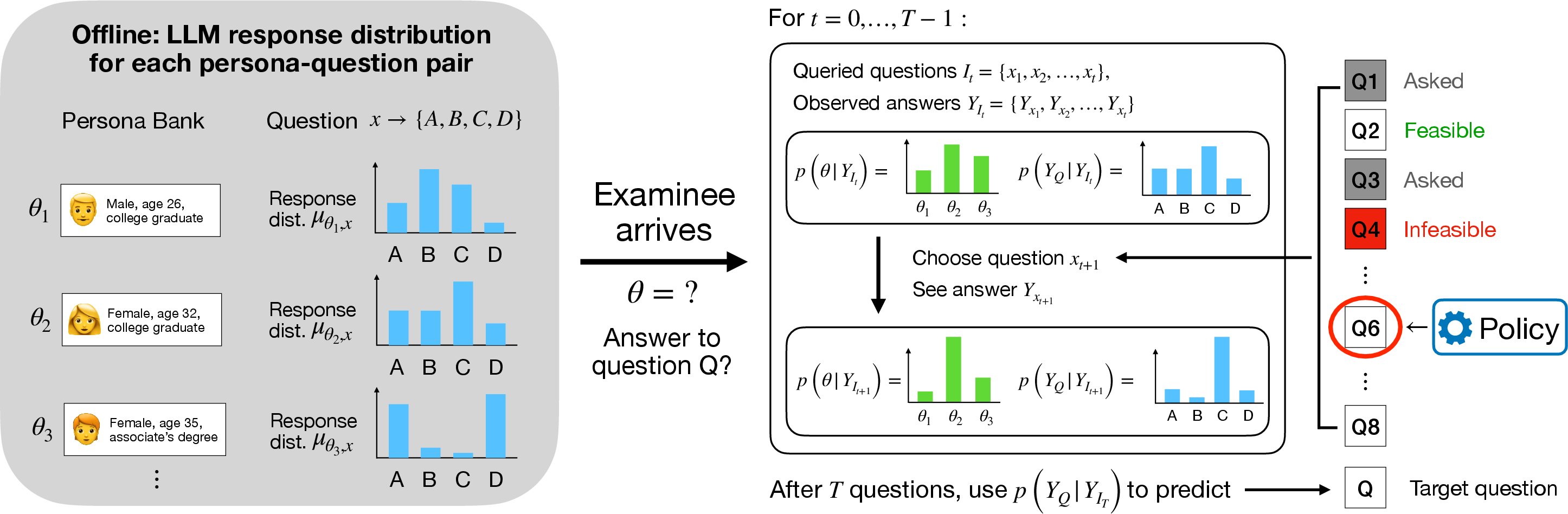
Figure 1: Workflow of persona-based Bayesian adaptive querying with offline LLM persona response elicitation and online Bayesian updating and querying strategy.
Methodological Framework
Persona-Induced Mixture Model
Formally, a finite dictionary of n personas {ξ1,…,ξn} is constructed, each associated with persona--question response distributions μθ,x elicited using an LLM. For a new user, a prior over persona membership p(θ) is placed; as user responses are observed, the posterior p(θ∣ht) is efficiently updated via Bayes’ rule, thanks to the conditional independence structure and the categorical nature of responses. The posterior predictive for any unasked item is a convex combination of the respective persona distributions, mixed by p(θ∣ht).
Crucially, all complex structure—heterogeneity, high dimensionality, behavioral nuance—is embodied in the LLM-elicited dictionary. Inference is not only closed-form but also scalable, as all posterior and predictive computations are performed in the low-dimensional space of persona assignment, irrespective of the ambient space dimension.
Query Selection and Bayesian Design
Adaptive querying policies are integrated seamlessly into this framework. Both non-adaptive (fixed batch) designs and greedy adaptive methods (one-step lookahead that minimizes expected posterior uncertainty) are instantiated without need for approximation or surrogate modeling. The paper formalizes the query selection objective as the minimization of an additive functional (e.g., entropy, Gini) over the posterior of the target variable—often a subset of unqueried responses.
Empirical Analysis
Synthetic and Real-World Evaluation
The empirical study benchmarks the persona-induced method against multidimensional polytomous IRT/CAT on synthetic and real survey datasets (WorldValuesBench (Zhao et al., 2024)), using both classical metrics (log-loss, Brier score, ordinal MSE) and query budgets that reflect practical constraints.
- For synthetic users (well-specified prior), persona-based querying—especially adaptive greedy policies—achieve rapid reduction in prediction error and uncertainty, substantially outperforming both unidimensional and multidimensional CAT baselines across query budgets (see Figure 2, Figure 3).
- For real users (model misspecification), persona-based methods retain dominance over CAT, though the margin narrows; greedy methods excel for small budgets, but at larger budgets, non-adaptive batch designs can catch up or even surpass due to their robustness to model misfit.
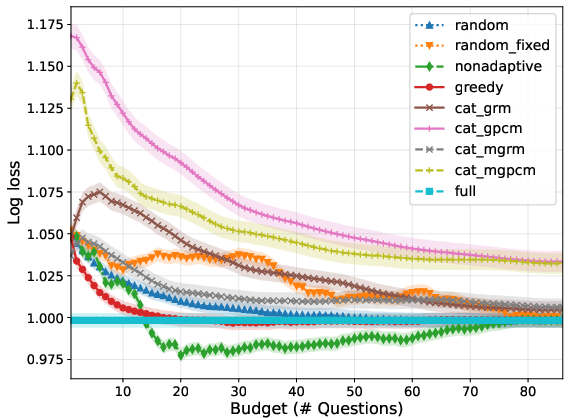
Figure 2: Performance curves for synthetic users with well-specified prior, evaluating mean prediction error versus query budget.
Scoring and Uncertainty Quantification
The paper foregrounds the importance of proper scoring rules (especially log loss and Brier score) for evaluation, establishing that the proposed Bayesian selection objectives align with these statistical principles. This is essential under model misspecification, which is inevitable in practice.
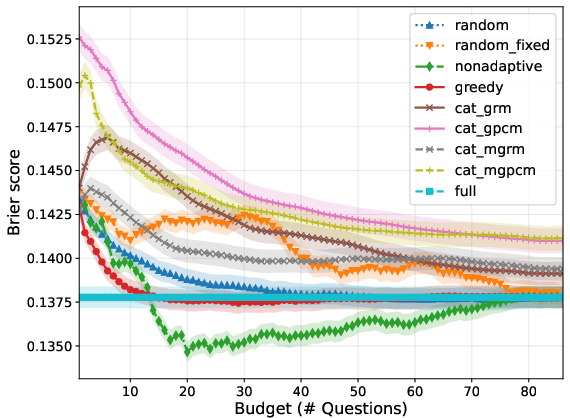
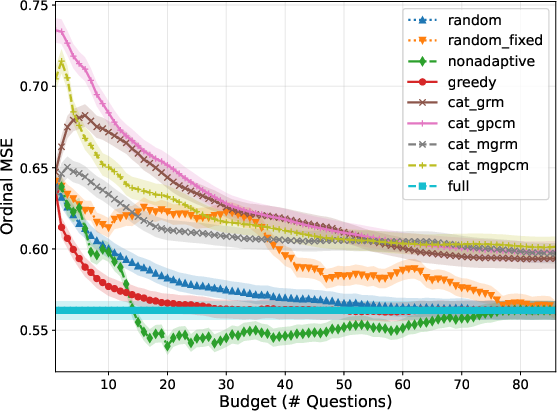
Figure 3: Brier score as a function of query budget for synthetic users; persona-based approaches demonstrate faster uncertainty reduction.
Figure 4: Brier score progression for real users, showing the comparative performance of persona-based and CAT querying strategies.
Ablation and Calibration
Ablation studies demonstrate:
- Robustness to dictionary size: Compression to as few as 200 prototype personas yields negligible loss.
- Importance of LLM-elicited probabilities: Replacing soft distributions with deterministic+noise approximations or temperature scaling consistently worsens performance; the LLM-calibrated outputs are both informative and necessary.
- Runtime: Non-adaptive persona-based querying is efficient, with inference on large test sets requiring less time (under 1 minute) than even unidimensional CAT; greedy adaptive is slower but remains practical. CAT baselines have significantly higher cost, especially in multidimensional (D>1) settings due to grid-exponential scaling.
Theoretical and Practical Implications
Expressiveness–Tractability Tradeoff
The persona-induced finite mixture framework balances expressiveness (via arbitrarily rich, LLM-powered dictionaries) and tractability (fixed, closed-form updates and predictions). This breaks the conventional tradeoff where more flexible priors demand expensive approximate Bayesian inference.
Cold-Start Inference
Unlike CAT/IRT, which require offline calibration for each new item, the persona model enables immediate deployment for previously unseen questions, as long as LLM-based conditional distributions can be elicited. This makes the method uniquely valuable for rapidly evolving domains and cold-start regimes.
Interpretable and Modular Probabilistic Inference
Persona assignments and posterior distributions are interpretable, facilitating both user-level and group-level behavioral analysis. The approach is modular: the persona dictionary and elicitation method can be adapted or extended without rewriting the inference or querying framework.
Future Directions
Several research axes emerge:
- Automated and data-driven persona discovery: Learning persona dictionaries from behavioral data, possibly with dynamic adjustment as populations evolve, promises further improvements.
- Mitigation of LLM bias: Ensuring demographic and attitudinal representativeness, and addressing the risk that LLM priors may perpetuate or amplify social biases, is paramount for responsible deployment.
- Integration with traditional methods: Hybrid schemes that warm-start CAT/IRT with persona posteriors, or use persona inference for initial item selection before parametric estimation, could leverage the advantages of both worlds.
- Extension beyond surveys: Applications in medical diagnosis, personalized education, and recommender systems with strict query/cost budgets are natural targets for this framework.
Conclusion
Adaptive Querying with AI Persona Priors introduces a formulation that fundamentally reshapes both the modeling and practical deployment of adaptive querying under uncertainty. By pooling the semantic and generative capacity of LLMs with the tractability of discrete mixture Bayesian inference, the approach outperforms classical calibrated latent trait models, especially in heterogeneity-dominated or cold-start environments. Empirical results solidify the value of probabilistically principled persona-based priors and underscore the limitations of parametric or deterministic baselines. The framework stands as a modular, interpretable, and scalable alternative for robust probabilistic user modeling and adaptive questionnaire design.