Tempus: A Temporally Scalable Resource-Invariant GEMM Streaming Framework for Versal AI Edge
Abstract: Scaling laws for LLMs establish that model quality improves with computational scale, yet edge deployment imposes strict constraints on compute, memory, and power. Since General Matrix Multiplication (GEMM) accounts for up to 90% of inference time, efficient GEMM acceleration is critical for edge AI. The Adaptive Intelligent Engines available in the AMD Versal adaptive SoCs are well suited for this task, but existing state-of-the-art (SOTA) frameworks maximize performance through spatial scaling, distributing workloads across hundreds of cores -- an approach that fails on resource-limited edge SoCs due to physical implementation failures, bandwidth saturation, and excessive resource consumption. We propose Tempus, a Resource-Invariant Temporal GEMM framework for the AMD Versal AI Edge SoC. Rather than expanding hardware resources with matrix size, Tempus employs a fixed compute block of 16 AIE-ML cores, achieving scalability through iterative graph execution and algorithmic data tiling and replication in the Programmable Logic. High-speed cascade streaming ensures low-latency partial sum reduction at Initiation Interval (II) of 1, while a deadlock-free DATAFLOW protocol maximizes transfer-compute overlap and PLIO reuse. Evaluated on GEMM workloads, Tempus achieves 607 GOPS at 10.677 W total on-chip power. By characterizing system-level efficiency through the Platform-Aware Utility (PAU) metric, we prove that Tempus achieves a 211.2x higher prominence factor than the leading spatial SOTA (ARIES). Furthermore, the framework maintains a 0.00% utilization of URAM/DSP, yielding 22.0x core frugality, 7.1x power frugality, and a 6.3x reduction in I/O demand, establishing a sustainable, scalable foundation for edge LLM inference.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about making big AI models (like chatbots) run well on small, low‑power devices such as drones, robots, or smart cameras. These devices don’t have lots of computing power or energy to spare. The authors introduce a system called Tempus that speeds up the most time‑consuming part of AI math—matrix multiplication—without needing lots of hardware. Instead of using more and more processors, Tempus uses the same small group of processors repeatedly and cleverly moves data so everything stays fast and efficient.
What questions the paper tries to answer
The paper asks:
- How can we run huge AI math (matrix multiplication) on tiny, power‑limited chips without adding more hardware?
- Can we keep performance high while using fewer cores, less power, and less data traffic?
- How do we compare “doing more with less” across different chips fairly?
How Tempus works (explained with everyday ideas)
Matrix multiplication (often called GEMM) is like multiplying two big tables of numbers to get a third table. This is the core of most AI calculations and can take up about 90% of the time in AI inference.
Most past methods try “spatial scaling,” which means using hundreds of cores (think: hiring lots of workers to do the job at the same time). That works on large, power‑hungry boards, but fails on small edge chips because:
- You run out of space and power.
- Data “roads” get jammed (bandwidth limits).
- The hardware design can’t even be built reliably at that size.
Tempus takes the opposite approach: “temporal scaling.”
- Imagine you have a small, efficient team of 16 workers (cores). Instead of hiring more workers, you give them the job in organized shifts (iterations). You cut the big tables into small blocks (tiling) so they fit easily into each worker’s local memory.
- A fast “conveyor belt” between neighboring workers (called a cascade stream) lets partial answers flow quickly without clogging the main roads. This keeps the pipeline full—one new piece of work enters every step (this is called Initiation Interval, or II, of 1).
- Data movement is planned like traffic with smart lights so there are no jams (a deadlock‑free DATAFLOW protocol). Data lanes to the chip (PLIO) are reused efficiently using a mix of broadcasting (send once, share with many) and packet switching (time‑sharing the lanes).
- The CPU on the chip acts like a manager, sets up the run, streams the data from memory, starts the workers, and collects the results—over and over—until the whole big multiplication is done.
In short: instead of throwing more hardware at the problem, Tempus slices the problem into pieces, streams them through a fixed, small “engine block,” and keeps all parts busy all the time.
What they found and why it matters
Key results (for a big matrix task):
- Speed: About 607 billion operations per second (607 GOPS).
- Power: Around 10.7 watts total on the chip (low for this kind of workload).
- Hardware footprint: Only 16 AI cores used, with 0% use of special on‑chip memory blocks (URAM) and digital signal blocks (DSP). That leaves room for other AI steps like Softmax or LayerNorm.
- Reliability: Works on a small, edge‑class AMD Versal AI Edge chip, not just in simulation.
They also introduce a fairness score called Platform‑Aware Utility (PAU):
- Think of PAU like a “bang‑for‑your‑buck” score that rewards doing more with fewer cores, less power, and fewer data lanes.
- Compared to a leading “use lots of cores” design (called ARIES), Tempus scores about 211× higher on this fairness metric.
- Tempus is also much more frugal:
- About 22× fewer cores for the job.
- About 7× less power.
- About 6× fewer I/O lanes (data cables).
Other useful insights:
- The size of the small blocks (called the tile size or DIM) matters a lot. Bigger tiles (up to what each core’s memory can hold) make things faster, sometimes over 10× faster for the same workload.
- Tempus handles many matrix shapes well, not just perfect squares. That’s important, because real AI layers often have “skinny” or “wide” shapes. Tempus keeps performance steady where big spatial designs often stumble.
Why this research matters for the future
- Edge‑friendly AI: Tempus makes running advanced AI on small, power‑limited devices practical. That enables smarter phones, robots, cars, and sensors.
- Sustainable performance: Instead of demanding lots of hardware, Tempus gets more out of a small, fixed block. That saves power, heat, and cost.
- Complete models on small chips: Because Tempus barely uses special chip resources, there’s space left to add the rest of the AI pipeline (like attention, normalization, and activation layers) on the same device.
- Scales with time, not size: As AI models keep growing, Tempus shows a way to keep up without endlessly growing the hardware—process more in well‑planned rounds instead.
Bottom line
Tempus proves you can keep a small, efficient “engine” fixed in size and still handle huge AI workloads by smartly slicing the problem, streaming data efficiently, and overlapping data movement with compute. It’s fast, power‑savvy, and practical for the real world—especially for edge devices where every watt and every hardware block counts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a promising temporally scalable GEMM framework for AMD Versal AI Edge, but several aspects remain underexplored or unresolved. The following concrete gaps can guide future research:
- Precision coverage beyond INT16/INT32:
- No empirical results for AIE-ML–native INT8/INT4 or BF16, nor mixed-precision paths commonly used in LLM inference (e.g., INT8 weights + INT16 accumulations). Quantify throughput, power, and accuracy impacts with custom micro-kernels if DSP library support is limiting.
- Correctness and numerical behavior:
- Absence of accuracy/error metrics versus FP32 baselines across precisions, accumulation widths, and tiling regimes. Verify numerical stability for long reduction chains and across rectangular shapes.
- Boundary handling and generality of tiling:
- The formulas for GRAPH_ITER_CNT and REPLICATION_FACTOR are presented without ceil/padding handling, and their LaTeX is malformed. Evaluate and report behavior for non-divisible dimensions, remainder tiles, and padding overheads on performance and correctness.
- Robustness of “deadlock-free” DATAFLOW:
- The design claims deadlock freedom but provides no formal proof, stress tests, or worst-case analyses (e.g., variable-rate producers/consumers, bursty NoC traffic, backpressure, reorder scenarios). Provide verification methodology or model checking to substantiate guarantees.
- Cascade vs. buffer-sharing trade-offs:
- The claim that cascade streaming is ~50% faster than buffer sharing lacks a systematic ablation study. Quantify latency/throughput, resource use, timing closure, and routability differences across matrix sizes and SPLIT/CASC_LN configurations.
- Measured power and thermal validation:
- Power is estimated (XPE) rather than measured on-board under steady-state load and varying ambient/thermal conditions; off-chip DRAM and board power are not included. Provide runtime power/thermal logs and energy-per-op across workloads.
- Memory-bandwidth and NoC bottleneck analysis:
- Although the design is I/O-bound, there is no measured DDR/NoC utilization, sustained bandwidth, or roofline analysis. Characterize bandwidth requirements, NoC contention, and backpressure sensitivity under different DIM/SPLIT/CASC_LN and when co-running other kernels.
- BRAM footprint and PL resource tension:
- BRAM utilization is high (~62.6%) for streaming FIFOs, potentially constraining integration of non-GEMM kernels. Explore FIFO depth/outstanding/burst-size sweeps and URAM/BRAM trade-offs to free PL capacity and quantify the effect on throughput and stability.
- Sensitivity to micro-architectural parameters:
- Limited exploration of SPLIT, CASC_LN, PLIO widths/counts, and AIE/PL clock frequencies. Provide a parameter sweep to expose performance/resource/power trade-offs and guidance for different VE devices with varying PLIO budgets.
- Scaling beyond a single 16-core block:
- Only one fixed 16-core block is evaluated on VE2302 (34 cores total). Assess multi-block composition, inter-block synchronization/communication, and scaling across the full array or multiple dies while preserving temporal scaling benefits.
- End-to-end pipeline integration:
- Softmax, LayerNorm, and KV-cache handling are not implemented. Demonstrate concurrent integration, resource contention, scheduling, and achievable tokens/s (or latency per token) in a full LLM decoding pipeline with Tempus as the GEMM backbone.
- Small-matrix latency and service models:
- For tiny GEMMs (e.g., A ≤ 8 in decoding), initialization and orchestration dominate latency. Evaluate persistent graphs, batching across requests, or multi-GEMM fusion to mitigate per-invocation overhead and quantify latency jitter.
- Portability and generality across devices:
- Claims of “resource invariance” are shown only on VE2302. Validate portability on other Versal AI Edge SKUs (e.g., VE2252, VE2802) and earlier AIE generations, including how PLIO constraints and memory architectures affect design choices.
- Fairness and validation of the PAU metric:
- The Platform-Aware Utility (PAU) definition includes a “Theoretical Peak (Pk)” term that is not rigorously defined, and the normalization against ARIES on different hardware raises comparability concerns. Provide:
- A precise, device-agnostic definition of Pk and sensitivity analyses.
- Correlation of PAU with task-level metrics (e.g., tokens/s).
- Cross-platform studies and statistical variability to establish PAU’s robustness.
- DIM limits and memory strategies:
- DIM is capped by local memory (128 for INT16, 64 for INT32), but strategies to push this limit (e.g., aggressive double-buffering, neighbor memory borrowing, tile fusion) are not explored. Evaluate their feasibility and effect on II=1 and routability.
- AIE-ML frequency and timing closure details:
- The AIE-ML core frequency is not reported; only PL runs at 312.5 MHz. Provide achieved AIE frequencies, timing margins, and timing closure statistics across designs to interpret performance and reproducibility.
- Validation scope and reproducibility:
- While a repository link is provided, the paper lacks details on how to reproduce bitstreams, measurement scripts, and exact tool versions/flags. Supply reproducible build pipelines, seeds for PnR, and validation datasets.
- Rectangular shape coverage and extremes:
- Although several rectangular shapes are evaluated, coverage of extreme aspect ratios (e.g., 1×N×N, 8×64k×64) and real-world parameterizations for larger LLMs (hidden sizes 8192–16384) is limited. Characterize performance and memory behavior for such extremes.
- Data layout conversion overheads:
- PLIO stream generation/tiling and reordering are said to be lightweight but add nontrivial overhead (e.g., 13.276 ms for “PL Tiling” reported for 10243). Quantify this cost across workloads, its amortization strategies, and opportunities for in-place tiling or prefetching optimizations.
- Mixed workload and multi-tenant behavior:
- No evaluation of concurrent kernels or PS traffic sharing the NoC. Characterize QoS, jitter, and fairness under mixed workloads and heterogeneous orchestration in realistic edge scenarios.
- Generalization beyond GEMM:
- The approach may extend to other linear algebra kernels (e.g., batched GEMM, convolution via im2col, attention score softmax fusion), but this is not investigated. Explore applicability and required graph/tiling adaptations.
- Error in equations and placeholders:
- Several LaTeX equations are malformed and contain missing braces or divisions, and tables include placeholder tags (e.g., {paper_content}). These hinder exact replication of scheduling parameters and should be corrected with complete, unit-checked formulations.
- Comparison baselines on the same device class:
- Since ARIES/CHARM were evaluated on larger devices, the comparison remains indirect even with PAU. Attempt to port or approximate a spatial baseline on VE2302 (even if reduced) to produce an on-device comparison and expose the true trade-offs.
- Long-duration stability and variability:
- No statistics on run-to-run variance, long-duration (hours) stability, or error rates under thermal drift and DRAM variability. Provide distributions, not just point estimates, for latency/throughput/power.
These gaps suggest a roadmap: expand precision and device coverage, provide rigorous bandwidth/power measurements and deadlock proofs, deepen sensitivity analyses, and demonstrate end-to-end pipeline integration with reproducible methodologies and on-device baselines.
Practical Applications
Immediate Applications
The following applications can be deployed now using the Tempus framework as described (code available at https://github.com/mgrailoo/TEMPUS), AMD Vitis 2024.1 toolchain, and the AMD Versal AI Edge VE2302 (or similar) platform.
- On‑device LLM token decoding for privacy‑preserving assistants
- Sectors: robotics, consumer electronics (home hubs, appliances), automotive (infotainment), industrial handhelds
- What it enables: Single‑token or low‑batch LLM inference on edge devices (e.g., projection GEMMs 8×4096×4096, 8×2048×2048) within a 10–20 W power envelope by temporally scaling GEMM on a fixed 16‑core AIE‑ML block; preserves PL resources for Softmax/LayerNorm to complete the LLM layer pipeline.
- Tools/Products/Workflow: Vitis 2024.1 + XRT; Tempus AIE graph + dma_hls kernel; rectangular GEMM tiling/replication generator; integrate as a custom GEMM operator in an inference runtime; deploy as an LLM decoder microservice on the PS.
- Assumptions/Dependencies: INT16/INT32 currently supported by DSP library; adequate DDR/NoC bandwidth; amortize initialization for small matrices via repeated runs; thermal headroom ~10–15 W on VE2302.
- Vision Transformer (ViT) and BERT inference in smart cameras and sensors
- Sectors: security, retail analytics, manufacturing QA, logistics
- What it enables: Efficient rectangular GEMMs such as 512×64×512 and 128×128×128 at sub‑millisecond to millisecond latencies with invariant PL utilization (0% URAM/DSP), allowing co‑resident image pre/post‑processing in PL.
- Tools/Products/Workflow: Tempus GEMM as a reusable IP block; packet/broadcast PLIO routing; cascade streaming for partial sums (II=1); packaged into a Vitis acceleration library component for transformer layers.
- Assumptions/Dependencies: External memory bandwidth sized for target frame rates; stable 312.5 MHz PL clock; model layers mapped to INT16/INT32 or mixed precision.
- Deterministic, low‑latency control inference at the edge
- Sectors: industrial automation (PLCs), UAVs/UGVs, robotics manipulation
- What it enables: Predictable execution for control and planning networks thanks to streaming dataflow, deadlock‑free DMA, and II=1 AIE pipeline; avoids spatial utilization collapse on small matrices.
- Tools/Products/Workflow: Deploy Tempus as a “real‑time GEMM engine” callable from the PS; design control loops that time‑slice GEMMs via GRAPH_ITER_CNT; use cascade reduction to minimize synchronization overhead.
- Assumptions/Dependencies: Real‑time scheduling on PS; bounded NoC contention; verify end‑to‑end latency budget when multiple kernels share PLIO.
- Energy‑constrained edge analytics with sustained performance per watt
- Sectors: remote monitoring, energy/utility substations, agriculture IoT
- What it enables: ~56.9 GOPS/W total system efficiency and ~255 GOPS/W AIE efficiency for GEMM‑centric workloads under ~10.7 W on‑chip power; enables battery/solar deployments running transformer blocks.
- Tools/Products/Workflow: Duty‑cycled inference with temporal scaling; PS orchestrates batch windows to amortize init overhead; metrics dashboard to track PAU (platform‑aware utility) during field trials.
- Assumptions/Dependencies: Stable supply and thermal design; occasional cloud fallback for non‑GEMM tasks if needed.
- Edge inference reference design and OEM IP kit
- Sectors: embedded systems OEMs, module vendors, ODMs
- What it enables: A drop‑in streaming GEMM core (16 AIE‑ML cores, 26 PLIO channels) with HLS DMA, tiling/replication scripts, and host orchestration for rapid productization on VE2302.
- Tools/Products/Workflow: IP packaging of Tempus; parameter generator for DIM, SPLIT, CASC_LN; CI pipeline to build xclbin; integration templates for Softmax/LayerNorm in PL.
- Assumptions/Dependencies: Vitis 2024.1; adherence to alignment (4096‑byte) and AXI4‑MM burst constraints; board‑specific DDR layout.
- Procurement and benchmarking with Platform‑Aware Utility (PAU)
- Sectors: public sector, enterprise IT/OT, systems integrators
- What it enables: Fair, platform‑normalized evaluation of edge inference designs (throughput vs. cores, power, I/O, device peak), avoiding bias toward brute‑force spatial arrays; informs hardware selection and SLAs.
- Tools/Products/Workflow: PAU calculators and reporting templates; comparative tests across candidate bitstreams and boards; acceptance criteria that include core, power, and I/O frugality.
- Assumptions/Dependencies: Organizational buy‑in to include PAU and frugality metrics alongside absolute TOPS/latency; cross‑vendor data transparency.
- Teaching and research labs on temporal scaling for heterogeneous SoCs
- Sectors: academia, training providers
- What it enables: Hands‑on labs demonstrating 3D→2D GEMM mapping, tiling, cascade reductions, and dataflow DMA; experiments on DIM sensitivity and memory‑bounded regimes.
- Tools/Products/Workflow: Course labs using the Tempus repo; MLIR/Polyhedral comparisons; assignments to extend replication strategies or PLIO reuse.
- Assumptions/Dependencies: Access to VE2302 evaluation kits and Vitis 2024.1; basic HLS and AIE programming skills.
- Private‑by‑default local AI features in consumer devices
- Sectors: smart home, wearables, appliances
- What it enables: Offline command understanding, summarization, and translation using compact LLMs/transformers; rectangular GEMMs with A≤8 supported efficiently for single‑utterance inference.
- Tools/Products/Workflow: Edge app that invokes Tempus GEMM kernels from a lightweight runtime; PS handles tokenization and I/O; PL hosts simple non‑GEMM kernels due to preserved fabric.
- Assumptions/Dependencies: Model sizes fit DRAM; acceptable accuracy with INT16/INT32 or mixed precision; product thermal envelope aligned with ~10–15 W compute bursts.
Long‑Term Applications
These require further toolchain enablement, scaling, or ecosystem development before widespread deployment.
- Full on‑device LLM stacks with mixed/low precision
- Sectors: mobile robotics, automotive, defense, telco edge
- What it could enable: End‑to‑end decoding with INT8/INT4/BF16 (natively supported in AIE‑ML hardware) for higher throughput and memory efficiency; sustained conversational AI under edge power/thermal limits.
- Tools/Products/Workflow: Quantization‑aware training and calibration; library and compiler support for INT8/INT4/BF16 kernels; KV‑cache management and rotary embeddings mapped to PL/AIE.
- Assumptions/Dependencies: AMD DSP/lib and Vitis support for additional dtypes; accuracy retention under lower precision; larger DIM feasible with future AIE memory.
- Compiler‑driven auto‑scheduling and runtime adaptivity
- Sectors: software tooling, EDA, OEM platforms
- What it could enable: MLIR‑based graphs that auto‑select DIM, SPLIT, CASC_LN and replication at compile time; PS runtime adjusts schedules to meet power/thermal QoS targets dynamically.
- Tools/Products/Workflow: Tempus passes in MLIR/Vitis; autotuners for tile sizes; telemetry‑driven controllers that tune GRAPH_ITER_CNT and stream routing on the fly.
- Assumptions/Dependencies: Deeper AIE‑ML compiler integration; standardized performance counters; safe hot‑reconfiguration policies.
- Multi‑tenant edge gateways with temporal multiplexing SLAs
- Sectors: smart cities, retail, industrial IoT
- What it could enable: Sharing a fixed GEMM block across multiple AI services (LLM prompts, ViT analytics) with time‑sliced guarantees; predictable latency budgeting via temporal scaling instead of spatial partitioning.
- Tools/Products/Workflow: Kubernetes/MicroK8s‑aware PS orchestrator; admission control based on PAU and frugality metrics; stream schedulers that arbitrate PLIO usage.
- Assumptions/Dependencies: Robust isolation between tenants; traffic shaping on NoC/DDR; orchestration software maturity on embedded Linux.
- Standards and policy for “Green Edge AI” metrics
- Sectors: policy, certification bodies, sustainability programs
- What it could enable: Procurement and compliance frameworks that include PAU, core/power/I‑O frugality, and deterministic latency as first‑class metrics for edge AI certification.
- Tools/Products/Workflow: Open PAU benchmark suite; third‑party audits; labeling similar to Energy Star for edge AI appliances.
- Assumptions/Dependencies: Community consensus on PAU variants; cross‑vendor comparability; governance and testing infrastructure.
- Generalized temporal scaling beyond GEMM
- Sectors: healthcare imaging, audio/speech, scientific instruments
- What it could enable: Resource‑invariant streaming pipelines for Softmax, LayerNorm, attention score scaling, depthwise/pointwise convs, and FFT‑like blocks—building full transformer/ViT stacks on small SoCs.
- Tools/Products/Workflow: Library of streaming non‑GEMM kernels leveraging saved URAM/DSP; end‑to‑end graph composition with dataflow overlap.
- Assumptions/Dependencies: Kernel‑specific vectorization and memory layouts; careful PLIO budget and NoC traffic planning.
- Cross‑platform portable design patterns for temporal streaming
- Sectors: heterogeneous compute (Jetson/Orin, Intel Agilex, ASIC NPUs)
- What it could enable: Adapting resource‑invariant temporal scaling and PAU‑style evaluation to other accelerators where memory/I‑O is the bottleneck, not compute cores.
- Tools/Products/Workflow: Portable scheduling templates; ONNX custom op integration; vendor‑specific stream/cascade analogs.
- Assumptions/Dependencies: Availability of high‑bandwidth local interconnects (e.g., warp shuffles, network‑on‑chip) and low‑latency streaming primitives on target platforms.
- Edge RAG and multimodal assistants
- Sectors: field service, security, manufacturing, healthcare
- What it could enable: Local text/image summarization and retrieval with ViT + LLM fusion in <20 W devices; temporal scaling used to time‑share GEMMs across modalities.
- Tools/Products/Workflow: Lightweight vector DB on PS; Tempus for projection and FFN blocks; PL‑based token filters and softmax; smart prefetch and double‑buffering for KV‑cache.
- Assumptions/Dependencies: Memory capacity for embeddings/KV; modal fusion accuracy under mixed precision; workflow orchestration for streaming I/O.
- Hardware evolution exploitation (bigger DIM, same footprint)
- Sectors: semiconductor roadmaps, OEM refresh cycles
- What it could enable: Drop‑in latency reductions (10×+ seen from DIM scaling) as AIE local memory grows, without changing the spatial footprint—preserving the resource‑invariant deployment model.
- Tools/Products/Workflow: DIM auto‑tuning in build pipelines; backward‑compatible Tempus graphs; performance portability reports to guide refresh ROI.
- Assumptions/Dependencies: Next‑gen AIE‑ML memory and toolchain support; stable PLIO budgets; consistent cascade capabilities across families.
Glossary
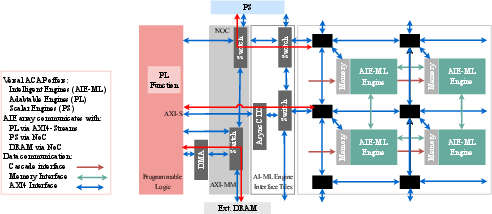
- ACAP (Adaptive Compute Acceleration Platform): A heterogeneous Xilinx/AMD SoC class combining CPUs, programmable logic, and AI Engines for accelerated computing. "Versal ACAP Architecture: Heterogeneous System Integration and Execution Flow for our framework"
- AIE-ML (AI Engine, Machine Learning): Second-generation VLIW/SIMD AI Engine tiles with local memory specialized for ML workloads on Versal devices. "The Intelligent Engines form a 34-core array of VLIW/SIMD processors (AIE-ML), each with local memory"
- AXI4 Memory-Mapped (AXI4-MM): A bus protocol for high-bandwidth memory-mapped transfers between processing elements and memory. "using the AXI4-MM protocol."
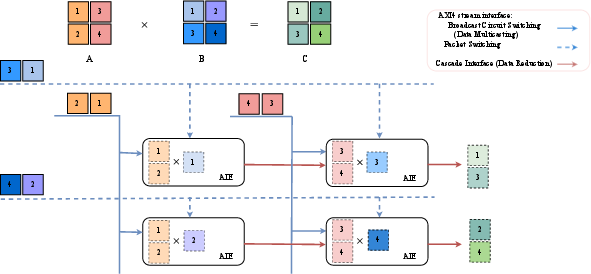
- AXI4 Switch: An interconnect component enabling packet switching/broadcasting between non-adjacent AI Engine tiles. "the AXI4 Switch connects non-adjacent cores and is configured for efficient packet-switching and broadcasting."
- AXI4-Stream (AXIS): A streaming interface standard used for high-throughput, low-latency data movement into/out of compute arrays. "data is streamed into the AIE-ML array via the AXI4-Stream (AXIS) network (red arrows)."
- BFLOAT16: A 16-bit floating-point format with 8-bit exponent for efficient ML compute. "native hardware support for INT4, INT8, and BFLOAT16 data types"
- BRAM (Block RAM): On-chip memory blocks in the programmable logic fabric used for buffering and FIFOs. "lower BRAM utilization (49.33\%) versus spatial alternatives."
- Broadcast circuit-switching: A routing method where a single source drives multiple destinations concurrently over dedicated paths. "specialized routing is employed (i.e., Broadcast circuit-switching and Packet Switching)."
- Cascade Interface: Direct 512‑bit links between adjacent AIE-ML tiles for low-latency partial sum reduction and chaining. "The Cascade Interface provides direct, low-latency connections (512-bit wide in AIE-ML) between adjacent cores"
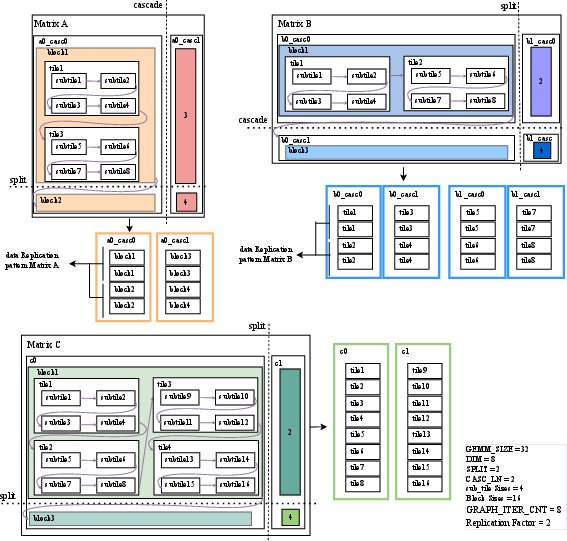
- CASC_LN (Cascade Length): Parameter indicating the number of AIE-ML tiles chained vertically for accumulation along the reduction dimension. "The split boundaries ... while the cascade paths denote vertical AIE-to-AIE communication (governed by CASC_LN) for partial sum reduction."
- DATAFLOW: A hardware design paradigm/pragmas enabling concurrent kernel stages via streaming channels, avoiding deadlocks. "a deadlock-free DATAFLOW protocol maximizes transfer-compute overlap and PLIO reuse."
- DIM (Tile dimension): Micro-kernel tile size determining the submatrix processed per core, bounded by local memory. "Tile Dimension (DIM) Scaling in Tempus for Fixed Workload () in different data types"
- DMA (Direct Memory Access): Hardware engine/kernels that move data between memory and compute units without CPU involvement. "A dedicated DMA HLS kernel then manages data transfer from external DRAM to the AIE-ML array"
- DRAM (Dynamic Random-Access Memory): External main memory used to store large matrices and stream them into the accelerator. "Input matrices are stored in external DRAM."
- DSP (Digital Signal Processing) slice: Specialized multiplier-accumulator resources in the PL fabric. "the framework maintains a 0.00\% utilization of URAM/DSP"
- FIFO (First-In, First-Out buffer): Streaming queues used in PL to decouple producer/consumer rates without large monolithic buffers. "by restricting programmable logic to lightweight streaming FIFOs"
- GEMM (General Matrix Multiplication): Core matrix-multiply operation underlying most deep learning compute. "the efficiency of () is the central performance bottleneck"
- GOPS (Giga Operations Per Second): Throughput metric counting billions of operations per second. "Tempus achieves $607$ GOPS at $10.677$ W total on-chip power."
- Graph iteration count (GRAPH_ITER_CNT): Number of repeated AIE-ML graph executions needed to temporally scale a workload. "Calculate GRAPH_ITER_CNT for temporal scaling."
- Initiation Interval (II): Cycles between launching consecutive loop iterations in a pipelined design; II=1 is maximal throughput. "guaranteeing a pipeline initiation interval (II) of 1"
- MLIR (Multi-Level Intermediate Representation): Compiler infrastructure enabling multi-level optimization across targets like AIE and PL. "ARIES (MLIR Compilation Flow): Introduced an agile MLIR-based flow for multi-level parallelism across Versal platforms"
- Network-on-Chip (NoC): On-chip interconnect for high-bandwidth communication between PS, PL, memory controllers, and AIE array. "Communication with the Processing System (PS) and access to external DRAM are both facilitated through the high-bandwidth Network-on-Chip (NoC)."
- Packet switching: Time-multiplexed routing of streams through a shared interconnect, enabling dynamic destination selection. "Matrix B employs packet switching (depicted as time-multiplexed streams (dashed blue arrows))"
- Place-and-Route (PnR): FPGA implementation step that maps logic to physical resources and routes signals; can fail under congestion. "failed during Place-and-Route (PnR) due to routing congestion"
- PL (Programmable Logic): The reconfigurable fabric of the Versal device used for data movement, buffering, and custom logic. "The Adaptive Engines (Programmable Logic) (red box) provide the reconfigurable hardware ... for data streaming control (FIFOs), data tiling, de-tiling and replications."
- PLIO (Programmable Logic I/O stream): A Vitis/AIE interface abstraction representing AXI4-Stream ports between PL and AIE graphs. "the AIE-ML array connected to the FPGA/PL kernel through PLIO interfaces."
- Platform-Aware Utility (PAU): A normalized utility metric that accounts for cores, power, I/O, and platform peak to compare designs fairly. "By characterizing system-level efficiency through the Platform-Aware Utility (PAU) metric"
- Polyhedral compiler: Compiler based on the polyhedral model to generate optimized loop nests and systolic arrays. "A polyhedral compiler generating monolithic systolic arrays with hardware optimizations (SIMD, II=1, double buffering)"
- PS (Processing System): On-chip scalar processors (e.g., Arm cores) orchestrating configuration, scheduling, and control. "The Scalar Engines (Processing System) (blue box) incorporate dual-core Arm® Cortex-A72 and Cortex-R5F processors"
- Replication Factor: The algorithmically determined number of times tiles/blocks are reused or copied to maximize data reuse. "Replication Factor calculated via Equ. \ref{equ:rf}"
- SPLIT: Parameter defining the number of parallel groups processing independent portions of matrices. "SPLIT defines parallel groups."
- Systolic array: Regular, pipelined grid of processing elements used for matrix operations. "A polyhedral compiler generating monolithic systolic arrays"
- Temporal scaling: Achieving scalability by iteratively reusing a fixed compute block over time rather than adding more cores. "temporal scaling is the only viable path for complete model deployments"
- Tiling: Decomposing matrices into smaller tiles/blocks/sub-tiles that fit in local memory for efficient streaming and compute. "Algorithmic Data Preparation (Tiling, Data Decomposition, and 3D-to-2D Mapping)"
- TOPS (Tera Operations Per Second): Throughput metric counting trillions of operations per second. "it achieved 10.03 TOPS on a INT16 GEMM"
- URAM (UltraRAM): Large-capacity on-chip RAM blocks in the PL for high-bandwidth buffering. "82.94\% URAM Utilization"
- Vitis HLS: AMD tool that compiles C/C++ kernels into FPGA hardware, enabling pragmas like DATAFLOW and PIPELINE. "The kernel is implemented with Vitis HLS"
- VLIW/SIMD: Very Long Instruction Word and Single Instruction Multiple Data paradigms enabling parallel operations within AIE-ML tiles. "VLIW/SIMD processors (AIE-ML), each with local memory"
- XCLBIN: Compiled hardware bitstream/package loaded onto the device for execution. "load the generated PLIO streams and the hardware binary (.xclbin) onto the Versal device"
- XRT (Xilinx Runtime): Runtime library for managing FPGA devices, buffers, and kernel execution from the host. "allocates memory buffers ... using XRT's aligned allocator"
Collections
Sign up for free to add this paper to one or more collections.