- The paper introduces a novel IFTR task with a detailed instruction taxonomy to benchmark table retrieval systems on instruction compliance.
- The paper presents an innovative automated pipeline that leverages LLMs for instruction generation and multi-stage quality review.
- The paper demonstrates that instruction-following retrievers achieve significantly higher IRS, though often at increased computational cost.
FollowTable: A Benchmark for Instruction-Following Table Retrieval
Introduction and Motivation
Table retrieval (TR) has historically focused on ad-hoc scenarios where the primary objective is finding tables topically relevant to a user's natural language query based on global semantic similarity. However, the rise of LLM-backed agentic systems has shifted practical requirements toward more nuanced retrieval. Users now expect systems to follow detailed instructions that specify both semantic and structural conditions—ranging from explicit inclusion/exclusion of content to fine-grained schema-related constraints. This trend necessitates a fundamental redefinition of relevance within tabular retrieval and exposes limitations in existing models that fail to model instruction-conditioned retrieval with sufficient granularity.
The FollowTable benchmark directly addresses this gap by introducing the Instruction-Following Table Retrieval (IFTR) task. IFTR demands that models not only consider semantic query–table overlap but also jointly reason over instruction-imposed constraints pertaining to table content and schema. The benchmark is underpinned by a taxonomy of instruction types explicitly dissecting the constraint space and is supported with large-scale, systematically annotated data and a novel metric for measuring instruction compliance.
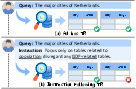
Figure 1: Ad-hoc retrieval relies solely on query–table topical similarity, while instruction-following retrieval demotes tables violating explicit user-defined constraints.
From Ad-hoc TR to IFTR
In contrast to standard TR, where relevance is query-centric, IFTR introduces an instruction variable. This variable refines and possibly overrides the relevance signal based on specific requirements: e.g., inclusion (must contain X), exclusion (must not mention Y), exclusivity (focus solely on Z), column (schema) requirements, or aggregation granularity constraints. Only tables that both match the query and strictly satisfy the instruction are considered relevant.
Fine-Grained Constraint Taxonomy
The instruction space in IFTR is formalized into two high-level categories:
This taxonomy enables systematic evaluation of model capabilities across the multifaceted instruction space, and its design allows the annotation pipeline to automatically produce both natural-language instructions and ground-truth instruction-compliant/violating tables.
Construction of the FollowTable Benchmark
Data Collection and Preparation
To support IFTR, FollowTable unifies and extends multiple open-domain and domain-specific TR datasets, and introduces a new Industrial Standard Manuals set, covering complex structured data from technical documentation. The preparation pipeline, leveraging LLMs for parsing, generalization, translation, and validation, ensures that each query is associated with multiple topically relevant tables, creating a scenario amenable to instruction-based refinement.
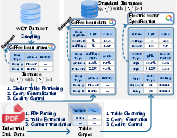
Figure 3: Data preprocessing: transforming raw datasets and technical manuals into standardized query–table pairs with multiple relevant tables.
Automated Instruction Generation and Annotation
FollowTable's automated instruction generation pipeline uses LLMs for semantic subtopic mining, categorical instruction synthesis (across all taxonomy subtypes), detailed re-labeling, synthetic balancing (to ensure minimum positive/negative coverage), and iterative LLM-as-a-Critic review. This critic evaluates instruction clarity, query dependency, logical consistency, category focus, and abstraction appropriateness.

Figure 4: Automated pipeline for instruction generation and multi-stage LLM-driven quality review, ensuring taxonomy coverage and logical validity.
After LLM-based curation, human annotators further validate instruction–table alignment and inter-annotator agreement is high (κ≈0.73).
Evaluation Metrics for IFTR
Traditional IR metrics, like nDCG and p-MRR, inadequately capture instruction-following ability because they only reward topical relevance. FollowTable introduces the Instruction Responsiveness Score (IRS), which quantifies the extent to which the model reorders instruction-compliant tables upward and instruction-violating tables downward relative to a topic-only baseline. IRS exhibits desired properties: sensitivity, monotonicity, and robustness to edge cases (such as when the topic-only baseline is already optimal).
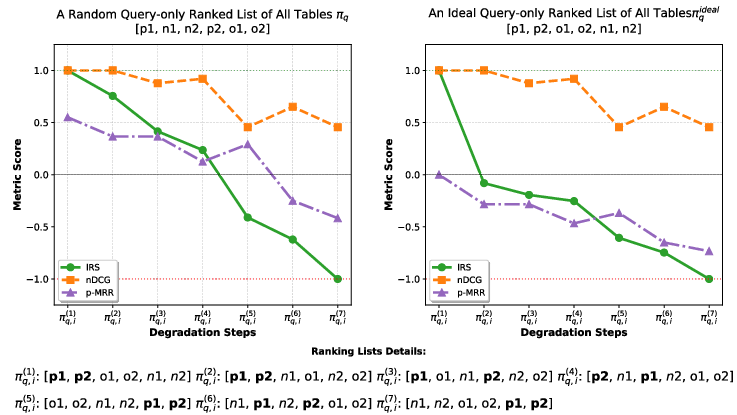
Figure 5: IRS demonstrates strict monotonicity under controlled degradation of instruction compliance, unlike nDCG and p-MRR which fail to consistently reflect instruction-induced ranking changes.
Experimental Analysis
Model Evaluation
FollowTable benchmarks three model categories:
- General-purpose retrievers (e.g., BGE, E5, OpenAI)
- Table-specialized retrievers (e.g., Tapas-DTR, Table-GTR, Birdie)
- Instruction-following retrievers (e.g., INSTRUCTOR, GritLM, Promptriever, Qwen3-Emb)
Key findings:
- Table-specialized retrievers only outperform others on in-domain data, lacking cross-domain robustness and instruction-following capability.
- Instruction-following models substantially improve IRS (e.g., Promptriever yields IRS ~26.2 vs. <5 for most non-instructional models), but performance remains far from optimal.
- Re-rankers and list-wise LLM-based models (e.g., Gemini-3-Pro) can close a significant fraction of the gap, but at high computational cost.
Entity-centric structure constraints (S2) are consistently the most challenging, while semantic boundary (C1) exhibits the highest instruction compliance for all architectures.
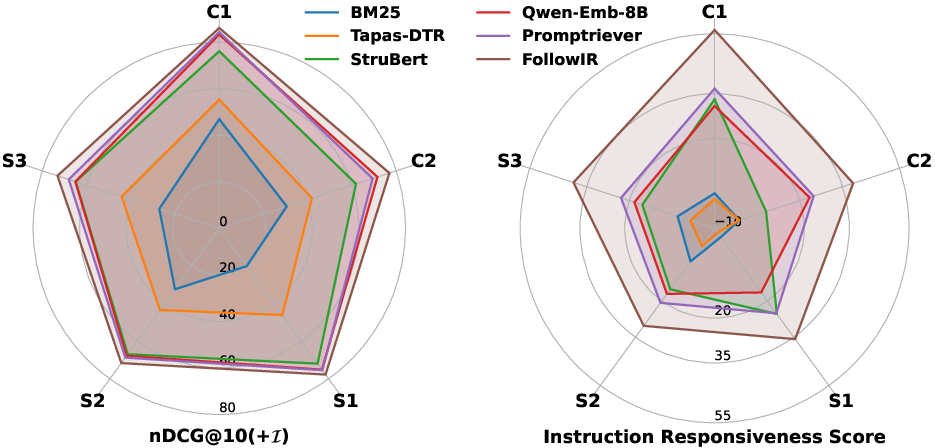
Figure 6: nDCG@10 and IRS breakdown by instruction type, showing increasing model difficulty from content-scope to schema-centric constraints.
Negation Sensitivity and Positive Attention Bias
Dense retrievers and even several instruction-aware ones demonstrate high Negation Failure Rates (NFR > 0.6), indicating a systematic "positive attention bias" toward tables containing excluded entities, undermining logical negation handling.
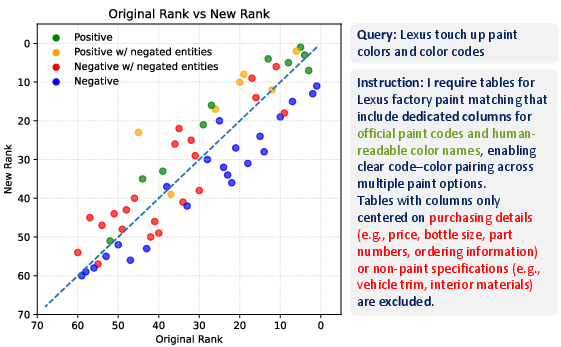
Figure 7: Rank shift analysis under attribute-centric structural instructions; even SOTA retriever models often promote instruction-violating tables (red/orange) due to insufficient constraint understanding.
Re-rankers vs. Retrievers
While state-of-the-art re-rankers (e.g., Rank1, FollowIR, Gemini-3-Pro) achieve significant IRS gains (up to +58.1 compared to bi-encoders), they incur 1–2 orders of magnitude higher latency. This shift illustrates the cost–accuracy tradeoff inherent to modeling complex instruction adherence.
Implications and Future Directions
The FollowTable benchmark surfaces fundamental limitations in current table retrievers:
- Structural encoding alone is not enough—models require explicit instruction-based alignment during training to reason over schema-grounded constraints.
- General-purpose retrievers, despite strong ad-hoc performance and robustness, lack mechanisms for fine-grained instruction-following unless instruction tuning is employed.
- Performance on instruction-following cannot be evaluated by traditional IR metrics, necessitating tailored metrics like IRS.
- Current retrievers and cross-encoders remain susceptible to logical inversion (negation) failures, warranting research on reasoning-augmented and logic-aware architectures.
Practically, these results have direct consequences for the design and deployment of agentic retrieval-augmented generation (RAG) systems: effective deployment in user-facing or multi-modal assistants mandates accurate instruction-following, not just topical relevance.
Theoretically, the IFTR paradigm formalized and benchmarked in FollowTable constitutes a new compositional reasoning challenge for information retrieval, requiring advances in multi-view encoding, natural-language reasoning over schema, and instruction-driven representation learning.
Conclusion
FollowTable establishes the IFTR task and enables systematic measurement—in both breadth and depth—of instruction-following in table retrieval. Empirical evidence emphasizes both the need for architectures explicitly sensitive to instruction constraints and for instruction-aligned pre-training objectives. As IFTR reflects emerging user interaction paradigms in structured data retrieval, further research is needed on ultra-efficient, logic-sensitive, and instruction-conditioned models—potentially integrating symbolic reasoning or advanced prompt-tuning—toward robust, instruction-following retrieval systems for next-generation AI agents.


