- The paper introduces a Mixture-of-Experts model that partitions conflicting evaluative criteria to robustly learn reward functions.
- It integrates soft trajectory-level routing and load-balancing within a multimodal transformer to handle heterogeneous, noisy supervision.
- Empirical evaluations across D4RL, AntMaze, and MetaWorld show significant performance gains and noise resilience over single-model baselines.
PrefMoE: Robust Mixture-of-Experts Reward Learning for Noisy, Heterogeneous Preference Supervision
Preference-based RL (PbRL) enables reward function inference via human or synthetic comparative feedback, circumventing the limitations of manual reward engineering. Recent expansions in large-scale annotation—using both crowdsourced labelers and foundation models—have fundamentally shifted the supervision regime. Rather than homogeneous preference pools, realistic datasets now exhibit substantial inter-annotator disagreement and intra-annotator inconsistency (Figure 1), producing label distributions with structured, irreducible noise and latent diversity of evaluative criteria. Empirically, this label heterogeneity cannot be adequately modeled as i.i.d. corruption; it manifests as distinct, often incompatible, decision principles. Yet, most prior work employs a single reward model, forcing it to average across these incompatible signals.
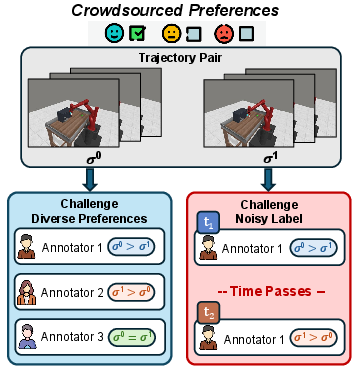
Figure 1: Both inter-annotator disagreement and intra-annotator inconsistency yield structured noise in large-scale preference-based RL, motivating robust, adaptive reward models.
The PrefMoE framework addresses this structural gap via an explicit Mixture-of-Experts (MoE) architecture. Rather than fitting a single unified predictor, PrefMoE learns multiple inter-modal expert reward heads atop a multimodal transformer backbone, each specializing in different latent evaluation strategies. Soft trajectory-level routing enables context-based convex combinations of expert predictions, supporting both specialization and interpolation in heterogeneous supervision regimes.
Methodology
Each trajectory segment, modeled as a sequence of state-action pairs, is first decoupled into separate state and action streams. Shared intra-modal encoders capture temporal regularities in each modality, reflecting behavioral and environmental structure (Figure 2). The critical architectural novelty is restricting the MoE to the inter-modal fusion stage, where cross-attention integrates states and actions; this reflects the locus of annotator disagreement, as evaluative diversity is primarily a function of how observers interpret the interplay between transitions, intent, and outcome.
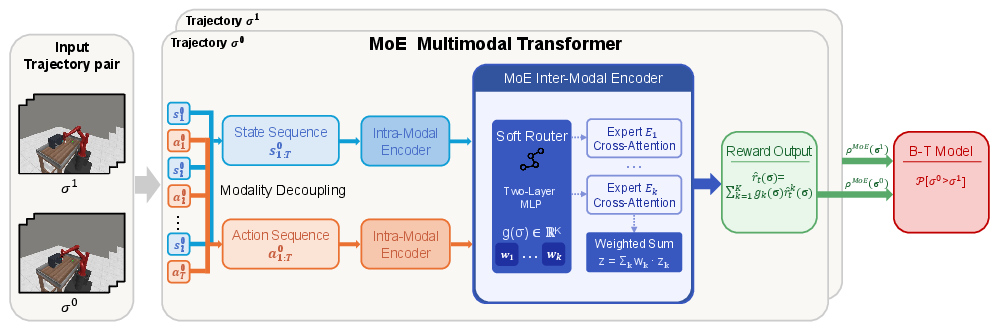
Figure 2: PrefMoE routes trajectory-level context through a soft gating network, producing a convex mixture of K expert inter-modal encoders for robust reward estimation.
A trajectory-level routing network pools the shared feature backbone, producing a K-dimensional softmax signal. Each expert consists of independently parameterized cross-attention inter-modal encoders, each outputting a per-step reward signal. The segment-level reward used for the Bradley–Terry paired-comparison loss is a convex combination weighted by the routing vector.
A load-balancing regularizer penalizes degenerate routing (collapse to a strict subset of experts), ensuring full model capacity is accessible and discouraging trivial solutions. All components are co-trained via cross-entropy preference loss and the balancing term, yielding a robust, end-to-end differentiable architecture.
Practical Integration
Once trained, PrefMoE is used to relabel RL trajectories for offline policy optimization: reward predictions for fixed trajectory segments are computed via windowed inference, maintaining context dependence. Importantly, the design ensures strict compatibility with standard PbRL inference protocols and does not require annotated latent variables or explicit expert-annotator correspondence.
Experimental Evaluation
Benchmark Domains and Baselines
Experiments span diverse preference modeling tasks: D4RL locomotion (continuous control, medium-expert/replay), sparse-reward AntMaze navigation, and MetaWorld manipulation (multi-stage tasks). Preference labels are sourced from high-diversity crowdsourced pools (up to 100 unique annotators), and all evaluation follows a strict offline RL pipeline, comparing downstream task performance. Baselines include traditional Markovian reward models (MR), sequence-based multimodal transformers (PrefMMT), and label denoising via ensemble trust filtering (RIME-offline).
Main Results
PrefMoE obtains consistently superior Gym-average, AntMaze-average, and MetaWorld-average scores relative to all baselines. In D4RL locomotion—especially replay-buffer settings with high-quality variation and annotation diversity—the model demonstrates substantial increases in normalized score, outperforming both PrefMMT (single sequence model) and denoising methods. This advantage arises from correctly partitioning conflicting evaluative criteria, rather than averaging them destructively.
AntMaze, with sparse returns and diverse navigation strategies, exhibits a particularly large gap between multimodal (sequence-based) and Markovian architectures. Here, only models with temporal and expert-based specialization can reliably extract preferences in the absence of step-wise reward cues.
MetaWorld manipulation tasks show the structural advantage of MoE: tasks with inherent multi-phase ambiguity (e.g., sweep-into, button-press) exhibit the largest gains, while stereotyped, low-diversity tasks (window-close) see negligible improvement or mild reversal in the method ranking, confirming the framework’s inductive bias.
Ablation Studies
Scaling Expert Count
Increasing the number of experts K provides monotonic improvements as annotation pool diversity rises. Transitioning from K=1 (PrefMMT) to K=4 yields up to +6.9 improvement in aggregate Gym score under high annotator diversity, with load balancing crucial for preventing expert collapse. This confirms that diversity in label structure is effectively captured by corresponding specialization in expert reward heads.
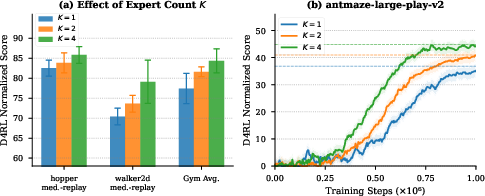
Figure 3: Both aggregate Gym performance and task-level RL curve on AntMaze improve monotonically with growing expert count, validating the diversity-specialization hypothesis.
Noise Robustness
Under controlled synthetic label corruption (Δp label-flip), PrefMoE’s soft routing confers substantial noise resilience. While RIME-offline’s explicit denoising provides greater robustness at extreme noise, PrefMoE retains the majority of its performance across a broad range, outperforming other sequence models absent explicit filtering.
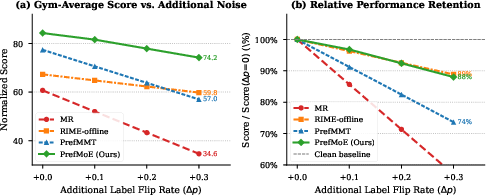
Figure 4: PrefMoE maintains robust preference performance under increasing synthetic annotation noise, leveraging implicit routing-based denoising.
Annotator Pool Size
PrefMoE’s Gym score is essentially flat as the annotator pool grows from 10 to 100, while single-model approaches degrade substantially. The advantage of MoE sharply increases with diversity, quantifying the practical importance of modeling structured, irreducible heterogeneity rather than unstructured noise. This provides empirical support for the need to distinguish between per-label corruption and systematic variation in preference data.
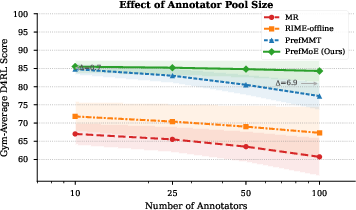
Figure 5: As the number of annotators increases, only PrefMoE maintains stable scores, with the PrefMoE–PrefMMT gap widening sharply as label diversity grows.
Theoretical and Practical Implications
PrefMoE demonstrates that robust preference modeling in large-scale PbRL is fundamentally a problem of structured latent diversity, not merely label noise. Architectures that enable local or global specialization—here instantiated via trajectory-level soft mixture-of-experts—constitute a necessary inductive bias for high-fidelity reward inference in realistic supervisory settings. Notably, the MoE mechanism both addresses inter/expert diversity and provides implicit resilience against label corruption, absorbing ambiguous or adversarial signals in generalist or underutilized experts.
Practically, this result points toward scalable and stable reward model design for RLHF at production scale, especially as annotator pools and preference criteria continue to diversify. Integrating MoE architectures with explicit noise filtering, dynamic expert allocation, and online preference aggregation represents an important future direction for scalable RLHF and safe reward model alignment.
Conclusion
PrefMoE introduces a Mixture-of-Experts framework targeted at robust, diverse preference modeling for reward learning under varied, often inconsistent supervision. The trajectory-level routing and expert specialization enable effective modeling of label heterogeneity, yielding pronounced gains in dynamic, real-world domains and empirical robustness to both structured disagreements and unstructured noise. As large-scale RLHF and reward modeling deployments continue to grow in complexity and annotator diversity, explicit architectural support for specialization—not merely averaging—will be central to both the theoretical understanding and practical reliability of learned reward models. The framework’s adaptability and scalability position it as a central component for future reward inference protocols in both offline and online RL alignment.