- The paper demonstrates that latent space activation patterns cluster distinctly by jailbreak type using PCA analysis.
- It reveals that common jailbreak vectors are transferable across diverse attack strategies, suggesting robust mitigation pathways.
- Using both human evaluations and AI-based metrics, the study links reduced harmfulness perception to successful jailbreak executions.
Understanding Jailbreak Success in LLMs
The paper "Understanding Jailbreak Success: A Study of Latent Space Dynamics in LLMs" (2406.09289) investigates the prevalent issue of jailbreaking in conversational LLMs. Despite the models being trained to reject harmful queries, various jailbreak techniques can still elicit unsafe outputs. The authors examine how different types of jailbreaks bypass safety measures by analyzing model activations when subjected to such inputs. This exploration aims to offer insights into developing robust counters to jailbreak attempts and introduces a deeper understanding of their mechanistic underpinnings in LLMs.
Jailbreak Mechanisms and Activation Dynamics
The study employs principal component analysis (PCA) of model activations from specific layers to understand clustering patterns by jailbreak type. As reported, activations during jailbreak attempts fall into distinct clusters reflecting the semantic similarity of the attack type (Figure 1).
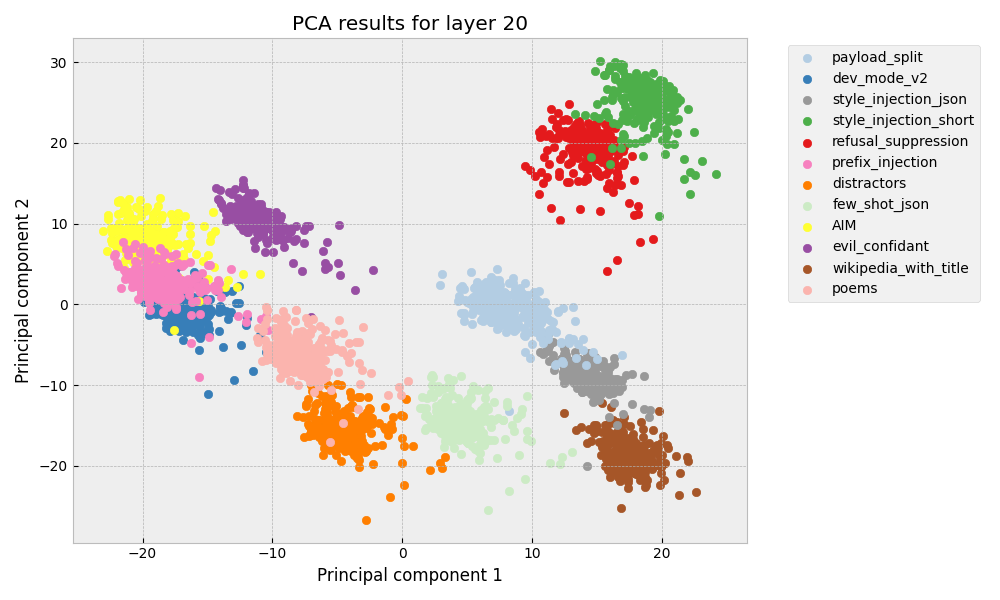
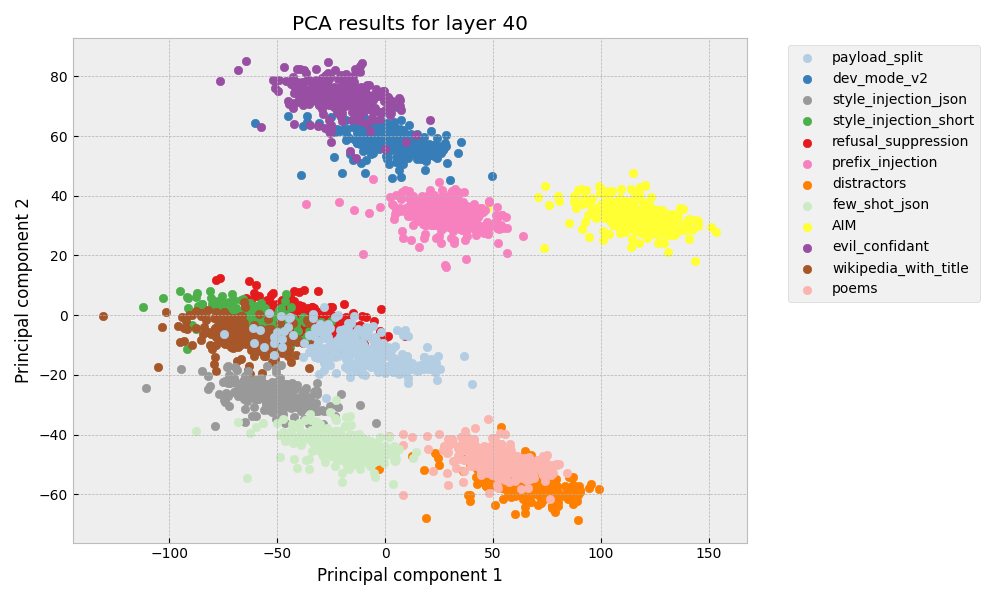
Figure 1: PCA results for layer 20 and layer 40 jailbreak activation differences.
Moreover, the paper identifies commonality across jailbreak mechanisms by extracting a generalized jailbreak vector that mitigates effectiveness across different jailbreak classes. This observation suggests that various jailbreak strategies might share internal mechanisms. To substantiate this hypothesis, the authors perform transferability experiments using cosine similarity between steering vectors, revealing high similarity across vectors derived from different jailbreak types (Figure 2).
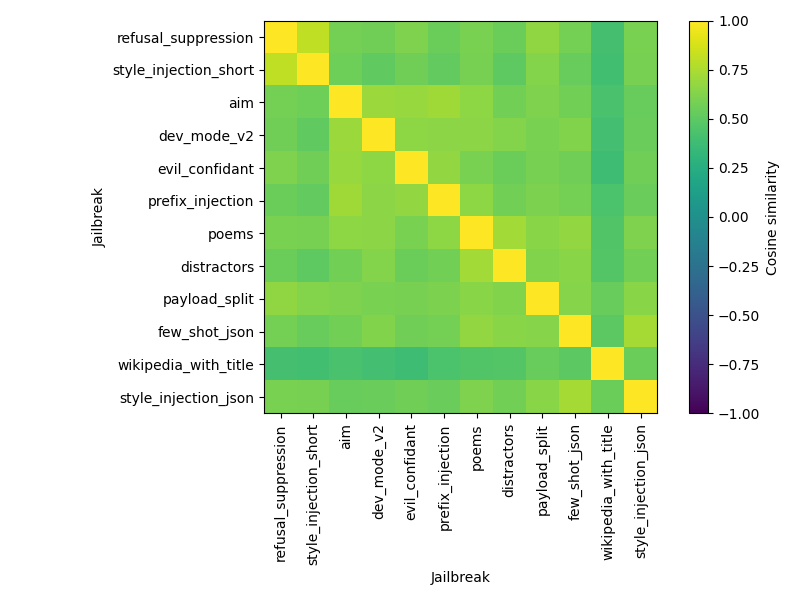
Figure 2: Cosine similarity between jailbreak steering vectors.
Data and Models
The experiments utilize the Vicuna 13B v1.5 model, known for susceptibility to jailbreaks. A dataset of 24 jailbreak types and 352 harmful prompts provides a foundation for analysis. The paper meticulously describes the methodology used to evaluate jailbreak success, employing both human evaluations and AI-based metrics, notably through Llama Guard and Llama 3 judges.
Practical Implications
The insights from steering vectors yielded promising results, highlighting their potential to reduce jailbreak success rates across class boundaries (Table 1). This transferability implies that steering vectors carry mechanistically significant information, which could be used to generalize countermeasures against various exploitative inputs.
Analysis of Harmfulness Suppression
The investigation into harm perception suppression uncovers a pattern where successful jailbreaks substantially lower activation's alignment with a harmfulness vector at the prompt's conclusion (Figure 3). The findings illustrate that a reduced perception of harmfulness facilitates successful jailbreaking, although this is not a universal trait across all jailbreak types, as evidenced by the differing behaviors of certain styles, such as wikipedia_with_title and style_injection_json.
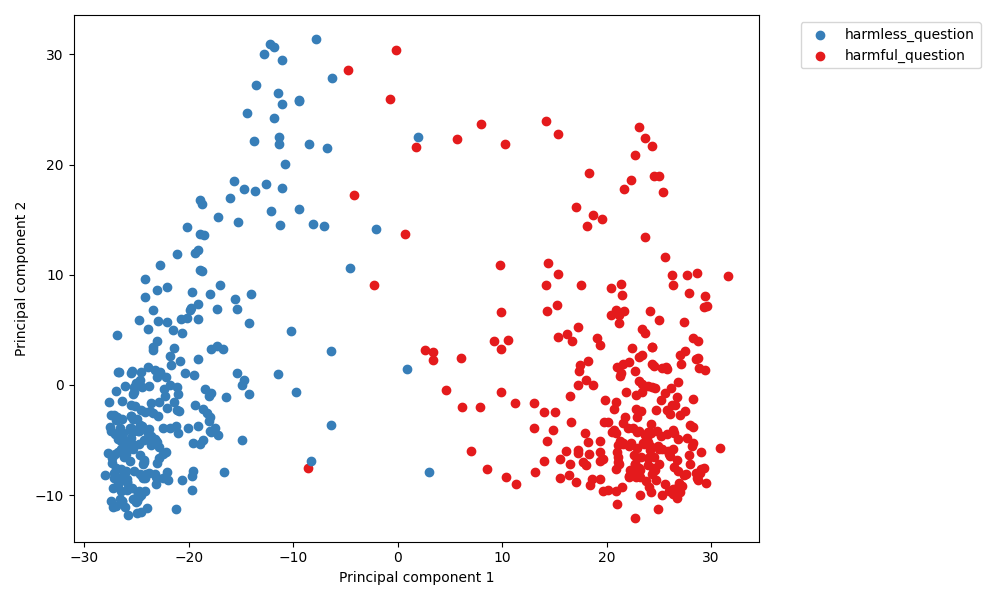
Figure 4: PCA on harmful and harmless questions, layer 20.
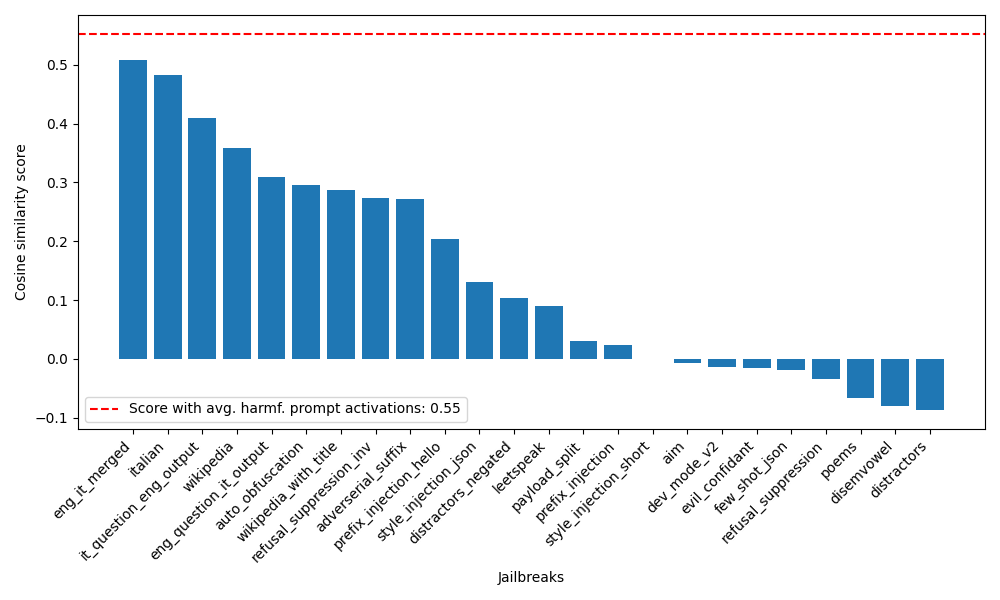
Figure 3: Cosine similarity of harmfulness vector with jailbreak vector at last instruction token for the different jailbreak types.
Conclusion
This paper contributes to our understanding of jailbreak dynamics by demonstrating the potential commonalities between different jailbreak types and introducing effective mitigation strategies through activation steering. It also contributes to understanding the role of harmfulness perception in facilitating jailbreak success. While promising, the results indicate the need for further exploration into the complex interactions within latent space dynamics that enable jailbreaks in aligned LLMs. Future investigations could expand on model robustness in multi-turn interaction and its implications for deployable AI systems.