Provable and scalable quantum Gaussian processes for quantum learning
Abstract: Despite rapid recent advances in quantum machine learning, the field is in many ways stuck. Existing approaches can exhibit serious limitations, and we still lack learning frameworks that are simple, interpretable, scalable, and naturally suited to quantum data. To address this, here we introduce quantum Gaussian processes, a Bayesian framework for learning from quantum systems through priors over unknown quantum transformations. We show that, under suitable conditions, unitary quantum stochastic processes define Gaussian processes, thereby enabling regression, classification, and Bayesian optimization directly on quantum data. The key ingredient in this framework is sufficient knowledge of a quantum process's structure and symmetries to define an informative prior through its corresponding quantum kernel, effectively injecting a strong, physics-informed inductive bias into the learning model. We then prove that matchgate, or free-fermionic, evolutions give rise to provable and scalable quantum Gaussian processes, providing the first family in our framework where the unknown unitary acts non-trivially on all qubits. Finally, we demonstrate accurate long-range extrapolation, phase-diagram learning in many-body systems, and sample-efficient Bayesian optimization in a quantum sensing task. Our results identify quantum Gaussian processes as a promising route toward simpler and more structured forms of quantum learning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Provable and scalable quantum Gaussian processes for quantum learning”
What is this paper about?
This paper introduces a simple, trustworthy way to learn from quantum systems, called quantum Gaussian processes (QGPs). The big idea is to use what we already know about the physics of a quantum system (its rules and symmetries) to guide learning. This makes the learning more accurate, easier to scale to many qubits, and better at saying how confident it is in its predictions.
What questions are the authors trying to answer?
The authors focus on a few key questions:
- When can the behavior of a quantum system be modeled like a “Gaussian process,” a kind of smart, uncertainty-aware curve-fitting method?
- How can we build this model so it runs efficiently on large quantum systems (many qubits)?
- Can we do this not only for tiny parts of the system, but even when the unknown quantum operation affects all qubits at once?
- Will this help with real tasks like predicting future behavior (extrapolation), telling phases of matter apart (classification), and choosing the best settings in experiments (optimization), using only a small number of measurements?
How do they approach the problem?
Here’s the idea, using everyday language and analogies:
- Gaussian process (GP): Imagine you’re drawing a smooth curve through a few known points on a graph. A GP doesn’t just draw the best-guess curve; it also draws a “confidence band” around it, showing how unsure it is. It uses a “kernel,” which is a way to measure how similar two inputs are, to decide how strongly information from one point should influence another.
- Quantum Gaussian process (QGP): Now imagine you have a quantum device that takes in a quantum state, applies some unknown transformation (a “quantum rule”), and then you measure something about the output state. You repeat this for different input states. The authors show how to treat this whole process as a GP: the input is “which quantum state you chose,” the output is “what you measured,” and the kernel encodes how similar those inputs are in a way that respects the physics.
- Prior and inductive bias: In Bayesian thinking, a “prior” is your best initial guess before seeing data. An “inductive bias” means building in smart assumptions that match the problem. Here, the prior comes from the known structure and symmetries of the quantum system (for example, what kind of transformation is likely). This physics-aware prior makes learning more accurate and sample-efficient.
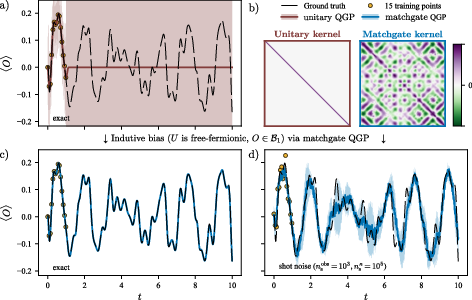
- Matchgates / free fermions (simple rules, big systems): A central part of the paper studies “matchgate” or “free-fermionic” circuits—special quantum transformations with lots of structure. Think of them like a musical score with strict patterns: because of these patterns, you can predict and compute things efficiently even for many instruments (qubits). The authors show that for these circuits, QGPs are both mathematically sound (provable) and efficient (scalable), even when the unknown transformation acts on all qubits.
- “Layers” of measurements: The authors also split measurements into layers (you can picture this like separating a song into bass, melody, and drums). If you focus on the right layer for the measurement you care about, you can build a kernel that captures the true similarities between your quantum states and keeps the numbers large enough to estimate accurately.
What did they find, and why is it important?
The paper has three main contributions.
- A physics-first framework for quantum learning:
- They build QGPs directly from the physics of the system: the type of unknown transformation, the form of the measurement, and the kind of states you probe.
- This creates strong, meaningful kernels (similarity measures) that help the model generalize well from very few data points and also say how uncertain it is.
- A new, scalable, all-qubit family of QGPs (matchgates):
- Previous results worked well mainly when the unknown part acted on just a few qubits.
- The authors prove that for matchgate/free-fermion circuits—where the unknown transformation can act on all qubits—you still get a good, efficient QGP model.
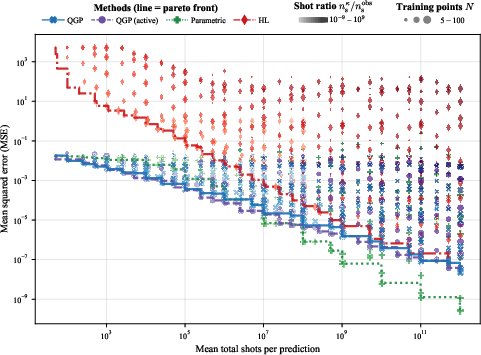
- Practically, this means you can estimate the kernel and make predictions using a number of measurements that grows reasonably (not explosively) with system size.
- Strong performance on real tasks with few measurements:
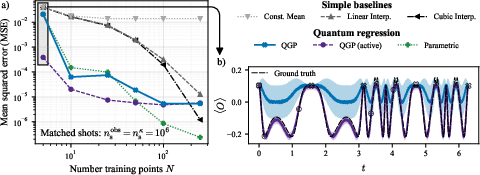
- Long-range extrapolation: On a 50-qubit problem, their QGP could predict far beyond the training region—something most models fail at—because the kernel captured the right long-distance similarities. When they used the wrong prior (ignored the physics), extrapolation failed.
- Learning phase diagrams and classification:
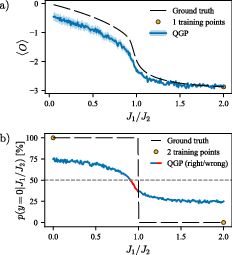
- For a 50-qubit spin model (bond-alternating XXX), the QGP reconstructed the phase diagram from just one training point and also classified phases accurately from only one labeled point per phase.
- For a 100-qubit XXZ model, the QGP recovered the “staircase” of magnetization plateaus using only one or two carefully chosen training points.
- Bayesian optimization (BO) with QGP surrogates:
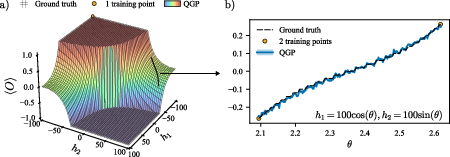
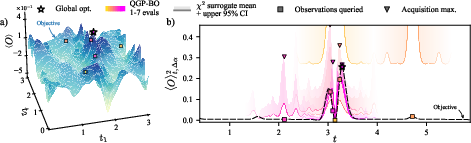
- On a tricky 2D landscape, the QGP-BO found the global optimum in about 7 evaluations, avoiding many local traps.
- In a 55-qubit quantum sensing (magnetometry) example—where every extra test costs time and quantum resources—the QGP-BO still found the best probe state in about 7 evaluations, jumping over flat regions by using uncertainty wisely.
Why this matters:
- The models are simple and interpretable: the kernel tells you why the model believes two inputs are related.
- They are uncertainty-aware: the GP’s built-in error bars naturally guide where to collect more data, which is essential when measurements are expensive.
- They scale to large quantum systems—especially impressive for the all-qubit matchgate case.
What’s the big picture impact?
This work points to a new, practical path for quantum machine learning:
- Use physics-guided Bayesian models (QGPs) instead of very flexible but hard-to-train black boxes.
- Get accurate predictions, meaningful uncertainty, and strong generalization from small datasets.
- Improve experimental efficiency by steering measurements to where they matter most (active learning and Bayesian optimization).
- Combine QGPs with standard quantum-circuit methods: use QGPs as smart, cheap “surrogates” to guide expensive quantum experiments or variational training.
Looking ahead, the authors suggest:
- Extending QGPs beyond matchgates to other useful families of quantum dynamics.
- Integrating QGP surrogates more deeply into quantum optimization and control loops.
- Building a broader toolkit for probabilistic, physics-informed quantum machine learning.
In short: by baking the right physics into the learning process from the start, you can learn more from fewer quantum experiments—and do it at scales that matter.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of concrete gaps and open problems that remain after this work, aimed at guiding future research.
- Formalize necessary and sufficient conditions for GP emergence beyond the “suitable states and observables” clause in Theorem 1, including precise characterizations of the “Gaussian pairing dominance” and vanishing odd-moment conditions cited in the Methods.
- Provide non-asymptotic, finite-n error bounds that quantify the deviation between the induced quantum process and the limiting GP (e.g., bounds on cumulants, total variation distance, or Wasserstein distance vs. n, m, dataset properties).
- Establish convergence rates of the moment-matching argument (how large must n be for a target approximation error ε, as a function of m and properties of the state set S?).
- Generalize the theory to observables with support on multiple Majorana sectors Bm (e.g., rigorous treatment of sums across sectors, potential cross-sector covariances, and when a sum-of-sector kernels remains a provably correct GP prior rather than a heuristic).
- Develop kernel constructions (and proofs) for additional all-qubit unitary families beyond matchgates (e.g., finite-depth k-local circuits, Clifford circuits, integrable interacting evolutions, Lie groups beyond SO(2n), and approximate t-designs).
- Extend the framework to noisy (non-unitary) channels and open-system dynamics; derive kernels for CPTP maps and quantify how noise affects the GP prior and its scalability.
- Analyze robustness to model misspecification: how sensitive are predictions and BO outcomes if the true dynamics only approximately respect the chosen symmetry group or if O has leakage outside the assumed sector?
- Devise principled kernel/model selection procedures when the correct symmetry class is unknown (e.g., Bayesian model selection across a toolbox of candidate groups, hierarchical priors, or mixtures of sector kernels with learned weights).
- Incorporate hyperparameter learning (e.g., automatic estimation of kernel amplitude, observation noise variance, sector weights, and potential length scales) via marginal likelihood or fully Bayesian treatments.
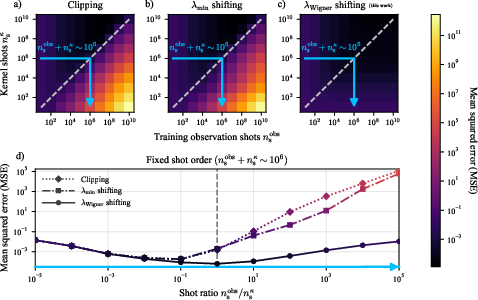
- Quantify and mitigate the impact of kernel-estimation noise: the kernel here is itself estimated from finite-shot quantum routines; develop methods that propagate kernel uncertainty into posterior predictions and ensure numerical stability (e.g., PSD correction, uncertainty-calibrated inversion, Bayesian kernel learning).
- Reduce the O(N2) kernel-construction burden and O(N3) GP inference scaling for large training sets (N) via quantum-aware sparse/inducing-point approximations, Nyström approximations, SKI/Toeplitz structure exploitation, or random-feature mappings tailored to quantum kernels.
- Provide detailed resource estimates and circuits for estimating sector-overlaps ⟨ρ(t),ρ(t′)⟩m, including explicit gate counts, required entangling operations, and error analysis, especially for realistic hardware without perfect coherent access to two copies.
- Explore overlap-estimation methods that avoid two-copy coherent access (e.g., swap-test-free protocols, shadow-based estimators, classical post-processing from single-copy measurements with provable guarantees for sector overlaps).
- Characterize when sector overlaps are informative: identify properties of the dataset S ensuring non-vanishing, well-conditioned overlaps in the relevant Bm, and design active data-selection strategies to avoid kernel degeneracy.
- Tighten the scalability story for observables with large m: determine the precise boundary where min{m,n−m} growing with n breaks scalability, and investigate approximate or compressed representations that retain predictive power for extensive observables.
- Analyze the effect of realistic experimental noise (SPAM, decoherence, drift) on both training observations and kernel estimates, and develop robustification strategies (e.g., noise-aware likelihoods, heteroscedastic GP models, error mitigation for kernel entries).
- For classification, develop multi-class, mixed-state, and finite-temperature extensions; study decision-boundary calibration, uncertainty quantification near critical points, and performance under disorder and non-linearly separable phases.
- For Bayesian optimization (BO), provide theoretical convergence/sample-complexity guarantees under QGP surrogates, including regret bounds that account for kernel estimation noise, limited query budgets, and non-Gaussian measurement noise.
- Specify and compare acquisition strategies (UCB, EI, TS) tailored to QGPs; analyze their robustness to flat landscapes and model misspecification, and optimize acquisition hyperparameters under quantum resource constraints.
- Extend BO experiments to noisy objectives and mixed-state probes; quantify performance under realistic shot budgets and show end-to-end resource savings vs. gradient-free or variational baselines.
- Demonstrate hardware experiments (even at small scale) to validate kernel estimation, GP predictions, and BO policies under real noise, connectivity constraints, and finite coherence.
- Clarify the role of classical simulability: matchgates are classically simulable; identify QGP families that remain scalable yet are believed to be classically hard, or articulate the practical advantages of QGPs in regimes where classical surrogates are costly.
- Provide systematic comparisons to alternative quantum learning baselines (variational ansätze, quantum kernels without GP structure, classical GP baselines) across accuracy, sample efficiency, and wall-clock resources, including ablations on the inductive bias.
- Develop active-learning strategies native to QGPs (optimal selection of training states t∈S and kernel-entry queries) with provable information-gain bounds and empirical savings in shots.
- Address online/continual learning settings where the training-phase assumption (temporary access to U) is relaxed; design algorithms that update the QGP as new quantum data arrive without full retraining.
- Formalize conditions under which summing sector kernels is guaranteed to remain PSD and statistically faithful to the underlying process, and explore learning the sector mixture weights from data.
- Explore composite objectives (e.g., sensitivities, variances) used in sensing: derive direct QGP priors for such functionals to avoid heuristic squaring/transformations and study the induced noise models.
- Provide a principled treatment of observation noise models beyond Gaussian (Bernoulli/binomial for projective outcomes, heteroscedastic shot noise), including likelihoods and inference schemes compatible with QGPs.
- Analyze high-dimensional parameter-index sets t∈Rd: characterize kernel expressivity, sample complexity, and curse-of-dimensionality behavior for QGPs, and propose scalable anisotropic or additive kernel constructions aligned with the physics.
- Investigate kernel and prior designs that encode additional symmetries (e.g., translation invariance, conservation laws) directly into the QGP to improve generalization and reduce data requirements.
Practical Applications
Below we outline practical, real-world applications enabled by the paper’s “quantum Gaussian processes” (QGPs) framework—Bayesian, kernel-based learning models tailored to quantum dynamics (notably provable and scalable for matchgate/free-fermionic evolutions). Each item notes relevant sectors, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Scalable surrogate modeling for quantum experiments (prediction/extrapolation after limited access to the device)
- Use case: After a short calibration/data-gathering phase on a quantum device that implements (or approximates) free-fermionic (matchgate) dynamics, build a QGP to predict expectation values for new states or parameters without rerunning the experiment. Particularly useful for predicting long-time dynamics or parameter sweeps from few training points.
- Sectors: Quantum hardware & software; R&D labs.
- Tools/workflows:
- Kernel-estimation circuits (e.g., Bell-basis overlap measurements) + classical GP toolkits (GPyTorch, GPflow) with a “matchgate kernel” backend.
- Integration with Qiskit/Cirq/PennyLane for state preparation and measurement orchestration.
- Assumptions/dependencies:
- The unknown unitary is well-modeled by a prior with known symmetries (e.g., matchgates) and the observable has significant weight in a low-order Majorana sector B_m with min{m, n−m} ∈ O(1).
- Reliable shot budgets to estimate overlaps and observables; stable device across the brief training phase.
- Data-efficient phase diagram learning on quantum simulators
- Use case: Reconstruct order parameters and identify phase boundaries in many-body models (e.g., bond-alternating XXX or XXZ chains) from only one or a few ground-state samples; combine sector-wise matchgate kernels if observables span multiple sectors (e.g., B2 ⊕ B4).
- Sectors: Materials & condensed matter (academia/industry), quantum simulation.
- Tools/workflows:
- “Phase Diagram Assistant” pipeline: (1) prepare selected points (e.g., key phases/extrema), (2) estimate matchgate kernel entries, (3) regress the landscape with QGP, (4) iteratively refine via active learning.
- Assumptions/dependencies:
- Access to ground states (via quantum simulators or classical solvers) and measurements in the relevant B_m sectors.
- Informative training points (e.g., states in plateau/ordered regions) to induce strong inductive bias.
- Uncertainty-aware classification of quantum phases
- Use case: QGP classification to label phases using very few training points (e.g., one per phase), with calibrated uncertainty around transition regions; latent GP often correlates with order parameters and provides interpretability.
- Sectors: Materials discovery, quantum simulation (academia/industry).
- Tools/workflows:
- QGP classifier with a matchgate kernel on relevant B_m sector(s); uncertainty thresholds for robust phase labeling near critical regions.
- Assumptions/dependencies:
- Finite-size effects imply soft transitions; confidence-aware decision rules are necessary around critical points.
- Correct prior/symmetry choice is essential; otherwise generalization degrades.
- Bayesian optimization (BO) of quantum experiment knobs with QGP surrogates
- Use case: QGP-guided BO for nonconvex, expensive objective landscapes with few parameters—e.g., tuning state-preparation angles, pulse durations, or Hamiltonian parameters—to maximize/minimize an observable or figure of merit.
- Sectors: Quantum control & calibration (hardware/labs), quantum software.
- Tools/workflows:
- “QGP-BO” module that couples matchgate kernels with standard acquisition functions (UCB, EI) and experiment control software for closed-loop optimization.
- Assumptions/dependencies:
- Each function evaluation is costly; BO success depends on well-calibrated uncertainty from the GP and informative prior/kernel.
- Objective is derived from expectation values compatible with the prior (e.g., observables in low B_m).
- Probe-state optimization in quantum sensing (variational magnetometry) under tight query budgets
- Use case: Optimize probe-state parameters to maximize sensitivity (e.g., to small field changes) using very few evaluations; suitable for fixed-budget protocols where optimization consumes the same resource used for sensing.
- Sectors: Quantum sensing & metrology (industrial metrology, defense, R&D).
- Tools/workflows:
- QGP-BO for sensitivity objectives built from matchgate kernels (e.g., B2 for magnetometry), orchestration with lab hardware to evaluate sensitivity proxies, early stopping when acquisition peaks stabilize.
- Assumptions/dependencies:
- Dynamics approximated by matchgates (e.g., non-interacting or weakly interacting regimes); sensitivity objective can be constructed from expectation values or their derivatives.
- Environmental stability over short optimization windows.
- Faster, uncertainty-aware variational circuit training (as a surrogate-guided optimizer)
- Use case: Use QGP-BO as a principled query-efficient driver to navigate rugged PQC loss landscapes, reducing circuit evaluations and avoiding premature convergence to local optima.
- Sectors: Quantum software & algorithms.
- Tools/workflows:
- Drop-in optimizer backend for variational frameworks (Qiskit Runtime, PennyLane, TensorCircuit) that alternates between GP-updates and targeted circuit evaluations.
- Assumptions/dependencies:
- Most effective when the circuit family or induced dynamics have known symmetries (e.g., in fermionic or structured ansätze). Outside provable regimes, the matchgate kernel is a heuristic that often performs well but loses formal guarantees.
- Education and training in Bayesian quantum machine learning
- Use case: Course modules and lab exercises demonstrating physics-informed inductive biases and uncertainty quantification for quantum data.
- Sectors: Academia, workforce development.
- Tools/workflows:
- Open-source notebooks that simulate QGP kernels, regression, classification, and BO on quantum-state datasets; compare “right vs wrong” priors to teach inductive bias.
Long-Term Applications
- Expanded QGP families for interacting/open-system dynamics
- Use case: Derive provable, scalable QGPs beyond matchgates (e.g., interacting spin models, open quantum processes with symmetries), broadening applicability across quantum platforms.
- Sectors: Quantum hardware/software, quantum science.
- Tools/products:
- Libraries of “physics-kernels” mapped to Lie algebras/Lie groups beyond SO(2n), with automated verification of scalability conditions.
- Assumptions/dependencies:
- New theory for moment operators and kernel scalings; practical circuits for overlap estimation in broader symmetry classes.
- Tomography-lite device characterization with uncertainty
- Use case: Replace parts of full process tomography with QGP surrogates to predict device responses on relevant state submanifolds and observables, with confidence intervals.
- Sectors: Quantum hardware manufacturing, QA/compliance.
- Tools/workflows:
- “QGP Characterizer” that learns device response surfaces under constrained priors during factory test; uncertainty thresholds for pass/fail.
- Assumptions/dependencies:
- Appropriate prior selection reflecting device symmetries; robust overlap/observable estimation under realistic noise.
- Automated exploration of large many-body phase spaces
- Use case: Active-learning-driven exploration (“Phase Hunter”) that proposes next experiments for quantum simulators (cold atoms, trapped ions, superconducting qubits) to map complex phase diagrams with minimal samples.
- Sectors: Materials discovery, chemistry, energy materials.
- Tools/workflows:
- Closed-loop: (1) QGP regression with physics kernels, (2) acquisition over parameter space, (3) state prep + measurement, (4) update, iterate.
- Assumptions/dependencies:
- Access to tunable quantum simulators; efficient preparation/measurement in targeted B_m sectors; scalable kernel estimation.
- Advanced quantum sensing in healthcare, geophysics, and navigation
- Use case: QGP-BO for pulse-sequence and probe-state design in NV-center magnetometry, atomic magnetometers, or NMR-like platforms (e.g., optimizing sensitivity, SNR, or spatial resolution subject to hardware constraints).
- Sectors: Healthcare (biomagnetism/MEG-scale sensors), geoscience (magnetic anomaly detection), navigation (field-based).
- Tools/workflows:
- Co-design of pulse sequences and probe states with QGP surrogates; safety-aware acquisition functions for clinical/field constraints.
- Assumptions/dependencies:
- Ability to approximate relevant dynamics within (or extend kernels beyond) free-fermionic regimes; robust calibration and drift management; regulatory approval in medical settings.
- Uncertainty-quantified optimization for large-scale quantum networks and controls
- Use case: Calibrate couplers, routing parameters, and control pulses in modular quantum architectures with QGP-BO for rapid convergence and fewer hardware cycles.
- Sectors: Quantum computing infrastructure.
- Tools/workflows:
- Hierarchical QGP surrogates that exploit subsystem symmetries; multi-objective BO for balancing fidelity, cross-talk, and energy costs.
- Assumptions/dependencies:
- Scalability of kernel estimation across modules; extension of kernels to realistic noise/crosstalk models.
- Standards and policy for uncertainty-aware quantum ML
- Use case: Establish benchmarks and reporting standards for uncertainty-quantified quantum learning (e.g., calibration of kernel estimators, shot budgets, confidence intervals), improving reproducibility and risk management.
- Sectors: Standards bodies, funding agencies, regulatory stakeholders.
- Tools/workflows:
- Metric suites for sample efficiency and robustness; checklists for symmetry-prior specification and validation.
- Assumptions/dependencies:
- Community consensus and cross-platform testing; alignment with broader AI/ML assurance frameworks.
- Consumer and industrial sensor calibration
- Use case: In the longer term, apply QGP-based calibration and drift prediction to compact quantum or quantum-enhanced sensors (e.g., chip-scale magnetometers) in industrial or consumer settings.
- Sectors: Consumer electronics, industrial IoT.
- Tools/workflows:
- Lightweight on-device QGP surrogates updated from periodic calibration data; uncertainty-aware maintenance triggers.
- Assumptions/dependencies:
- Maturation and commoditization of quantum-grade sensors; simplified measurement protocols compatible with resource constraints.
Notes on cross-cutting assumptions:
- Success hinges on selecting “the right prior for the right problem”—i.e., enough structural knowledge (group/symmetry class of dynamics and observable sector) to define an informative kernel.
- Scalability requires observables concentrated in low-order Majorana sectors (or analogous subspaces for other groups), and efficient overlap/observable estimation circuits with manageable shot budgets.
- Outside provable regimes, the framework remains a strong practical heuristic—empirically effective but lacking formal guarantees.
Glossary
Gaussian processes: A non-parametric Bayesian framework used for regression, classification, and optimization. "In this work we take a step in that direction by turning to Gaussian processes, a non-parametric Bayesian framework used for regression, classification, and optimization."
Matchgate: A type of quantum circuit derived from the representation of the Lie group , characterized by transformations that can be expressed as quadratic Hamiltonians. "We then show that matchgate, or free-fermionic, evolutions give rise to provable and scalable quantum Gaussian processes."
Quantum Gaussian processes: A Bayesian framework for learning from quantum systems that uses priors over unknown quantum transformations. "Here we introduce quantum Gaussian processes, a Bayesian framework for learning from quantum systems through priors over unknown quantum transformations."
Hilbert-Schmidt (HS): A measure of proximity between operators, defined as the trace of their product. "The collection of random variables forms a Gaussian process with covariance measured by the Hilbert-Schmidt kernel."
Kernel: In the context of Gaussian processes, a function that measures similarity between input points, crucial for defining the covariance structure of the process. "The key ingredient in this framework is sufficient knowledge to define an informative prior through its corresponding quantum kernel."
Fidelity kernel: A specific type of kernel measuring fidelity or similarity between quantum states. "We find that the kernel entries follow the structure of the fidelity kernel."
Bayesian optimization: An optimization framework that uses a surrogate probabilistic model, typically a Gaussian process, to identify an optimum by balancing exploration and exploitation. "Using Bayesian optimization, the QGP efficiently pinpoints the optimal parameters."
Reproducing kernel Hilbert space (RKHS): A mathematical framework within which Gaussian processes can be defined, ensuring properties like positive definiteness of kernels. "These processes are naturally suited to be modeled within reproducing kernel Hilbert spaces, making them compatible with Gaussian processes."
Free-fermionic: A computational model where particles obey Fermi-Dirac statistics and are invariant under transformations in specific symmetry groups. "We prove the model's applicability to free-fermionic systems, showing scalability and validity."
Unitary group : The group of all unitary matrices, crucial for describing transformations in quantum mechanics. "Our framework considers unitary stochastic processes within the unitary group ."
Collections
Sign up for free to add this paper to one or more collections.

