- The paper introduces PARA, which uses spectral analysis via SVD to reassign non-uniform ranks in LoRA adapters for efficient model compression.
- It employs QR decomposition to limit SVD to the latent subspace, drastically reducing computational overhead while keeping accuracy degradation under 1%.
- PARA enables flexible one-to-many deployment, adapting fine-tuned models to various hardware constraints and multi-tenant settings without retraining.
Post-Optimization Adaptive Rank Allocation for LoRA: A Technical Analysis
Motivation and Problem Statement
Parameter-Efficient Fine-Tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) have become the de facto approach for adapting large-scale pretrained models, especially under hardware and sample efficiency constraints. LoRA introduces low-rank update matrices enabling efficient adaptation, but conventional usage imposes a uniform rank across all layers. This static allocation is agnostic to the heterogeneous intrinsic dimensionality requirements of different layers and results in considerable parameter inefficiency and redundant computation. Existing adaptive-rank solutions typically require complex architectural modifications, additional regularization, or significant training-time overhead, further increasing the hyperparameter and deployment complexity.
Methodology: PARA Framework
The paper introduces Post-Optimization Adaptive Rank Allocation (PARA), a data-free, post-hoc, spectral analysis-based compression framework for LoRA adapters. The guiding principle is that model layers exhibit widely varying spectral importance in their learned updates, as revealed by Singular Value Decomposition (SVD). PARA applies SVD to the fine-tuned adapter weights, pooling all singular values across the network and then allocating rank to each layer according to a single global threshold.
Following adapter training with a sufficiently high uniform rank (over-parameterization phase), PARA efficiently prunes the adapter by retaining only those singular value components (directions) above the threshold. The threshold can be set in two ways: target average rank (γ-PARA) or by preserving a given fraction of the overall spectral energy (ε-PARA). Critically, this permits automatic, non-uniform allocation of capacity—layers with higher spectral energy receive more parameters, while inconsequential layers may be completely zeroed out.
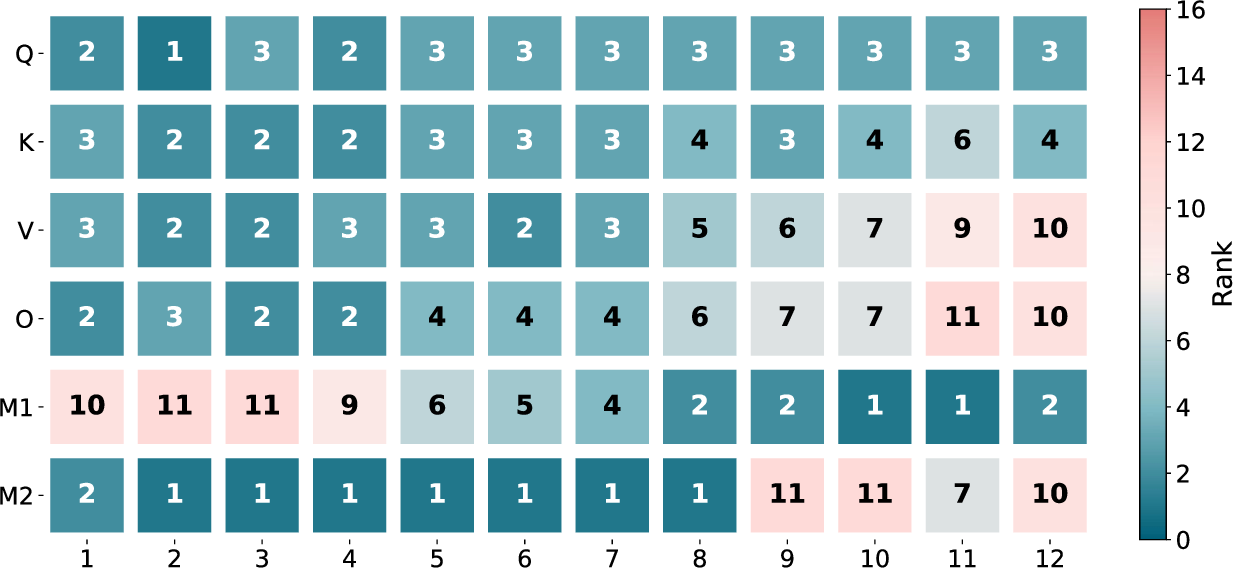
Figure 1: Rank distribution across layer types and depth on a LoRA trained at rank 16 on the Food 101 Image Classification task and compressed by PARA to an average rank of 4. PARA automatically allocates ranks based on spectral importance.
To ensure computational efficiency, PARA does not materialize the full adapter weight matrix to perform SVD. Instead, it leverages the intrinsic low-rank structure of LoRA updates, using QR decomposition to limit SVD to the latent subspace, drastically reducing computational cost to O((d1+d2)r2+r3) from O(d1d22), with d1, d2 typically in the thousands and r≪d1,d2.
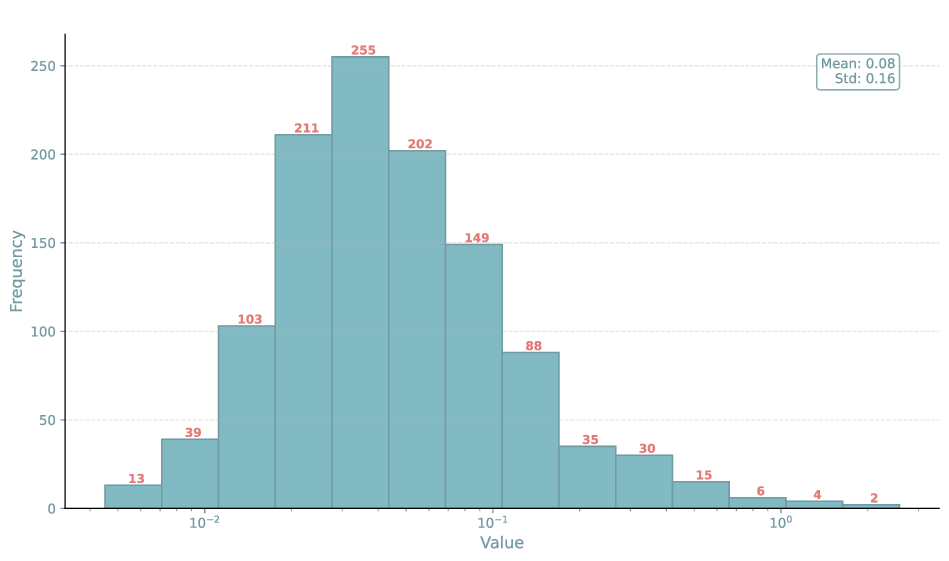
Figure 2: Distribution of singular values from a LoRA of rank 16 trained on the Food-101 image classification dataset, highlighting the truncated long tail and dominance of a few key directions in spectral energy.
Analysis of the singular value spectra (Figure 2) reveals highly skewed distributions: a handful of principal directions dominate, while the majority of spectrum is near-zero, corroborating that the effective rank is much lower than the LoRA configuration during training.
Theoretical Justification and Optimality
PARA’s pruning policy draws upon the Eckart-Young-Mirsky theorem, which guarantees (in the Frobenius norm) that truncation via SVD yields the optimal low-rank approximation. The loss-minimizing property directly translates to minimal information loss when discarding low-spectral-energy directions. This makes singular values a model-intrinsic, significance-aligned proxy for pruning, obviating the need for Fisher Information or gradient-based parameter scoring.
Empirical comparison to Fisher-Pruning validates that PARA's data-free spectral criterion achieves parity with computation-intensive, second-order loss-based sensitivity estimates.
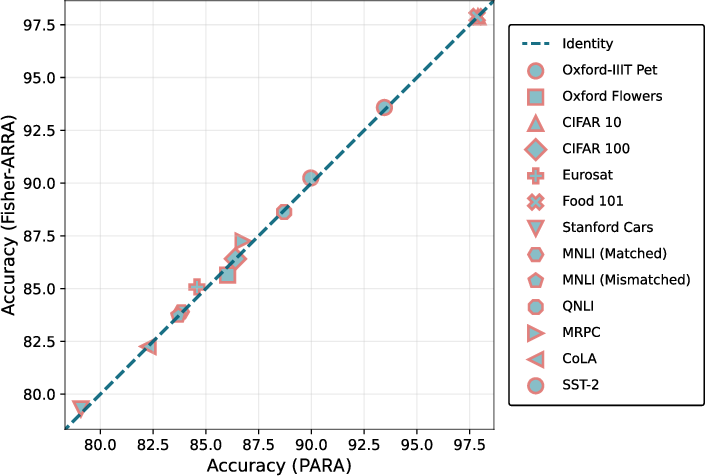
Figure 3: Scatter plot comparing PARA and Fisher-PARA accuracies across image classification and natural language understanding datasets; points align closely to the diagonal, demonstrating near-equivalent loss from both approaches.
Experimental Evaluation
Image Classification
PARA demonstrates strong performance across canonical image classification benchmarks (e.g., CIFAR-10/100, Eurosat, Oxford Flowers, Stanford Cars, Food-101) with SigLIP2 Base vision backbone. With aggressive compression (average rank 4 from initial rank 16), PARA achieves parameter reductions of 75–90% while consistently surpassing uniform-rank LoRA, AdaLoRA, SoRA, DoRA, and GoRA, with negligible (<1%) top-1 accuracy degradation. In several settings, PARA-compressed models even outperform their full-rank counterparts due to denoising effects inherent in spectral pruning.
Natural Language Understanding
On standard GLUE benchmarks (MNLI, SST-2, CoLA, QNLI, MRPC) using RoBERTa Base, PARA again yields superior or state-of-the-art performance at matching or substantial compression relative to baselines, including alternatives employing training-time adaptivity.
Commonsense & Mathematical Reasoning
Using Gemma3-4B (IT) as the frozen LLM trained on Commonsense-170k and MetaMathQA, PARA achieves top-tier metrics on tasks such as BoolQ, HellaSwag, PIQA, SIQA, ARCs, and MATH/GSM-8K, outperforming all rank-adaptive baselines.
Multi-Rank Deployment and Dynamic Serving
A key strength of PARA is its enablement of “one-to-many” deployment: a single, high-capacity LoRA parent can be post hoc compressed to any desired footprint at inference, with each child adapter benefiting from adaptive spectral rank allocation tailored to contemporary hardware constraints. This allows seamless adaptation to multi-tenant regimes and efficient runtime adapter swapping.
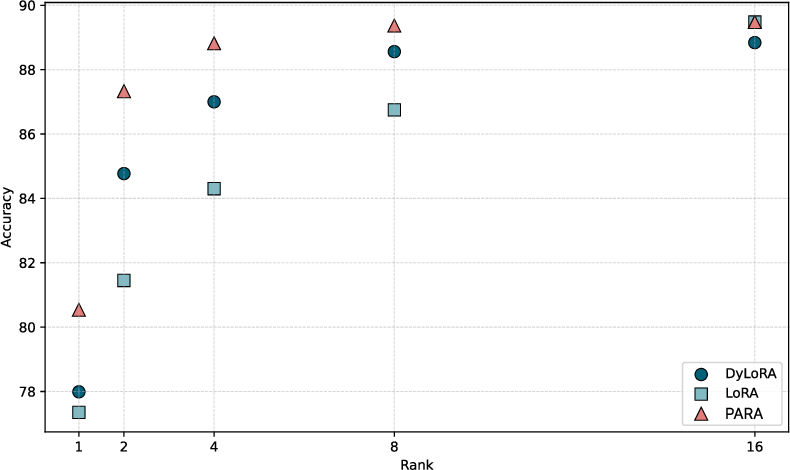
Figure 4: Scatter plot showing PARA’s superior accuracy at a given compressed rank compared to DyLoRA and natively trained LoRA across image classification benchmarks.
Ablations and Additional Insights
Local vs. Global Pruning comparisons confirm that PARA's global spectral threshold significantly outperforms uniform rank assignment, especially at high compression rates. Analysis also shows that PARA’s automatic allocation emphasizes functionally critical layers (greater spectral energy) while pruning away redundancy.
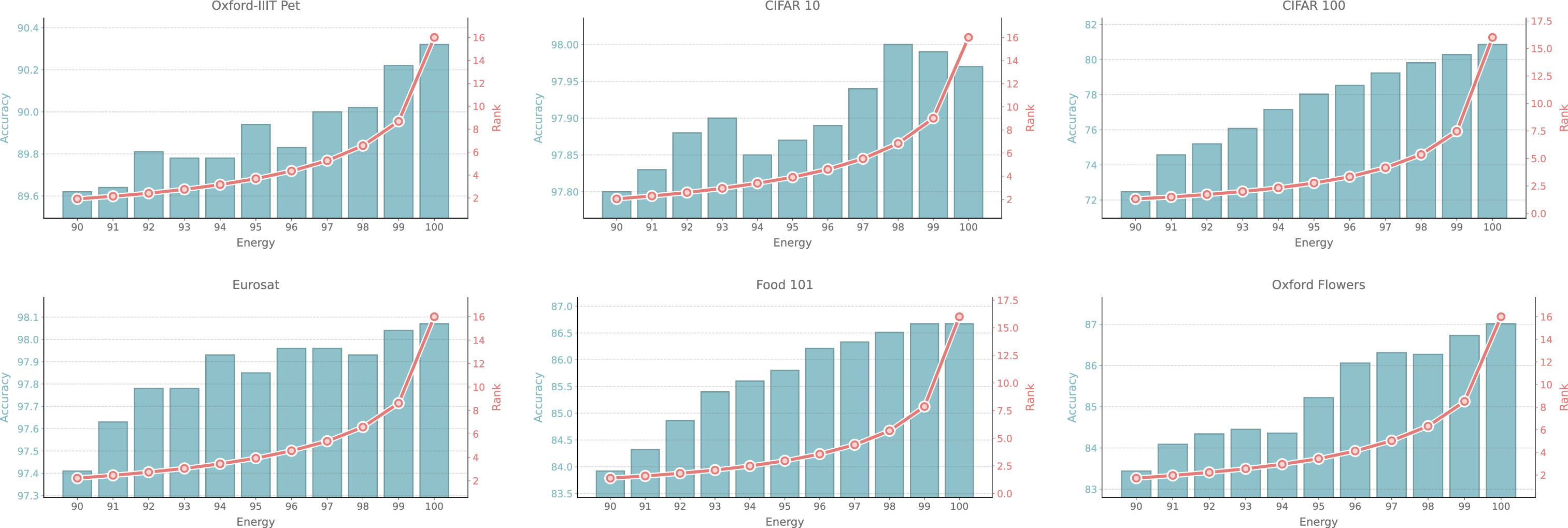
Figure 5: Accuracy vs rank during energy-based compression further evidences that extremely aggressive pruning can be performed with little loss in performance up to the critical energy threshold.
Distributional analysis of singular values across datasets further underscores the universality of the adaptation spectrum’s sparsity, indicating broad applicability for PARA in diverse architectures and domains.
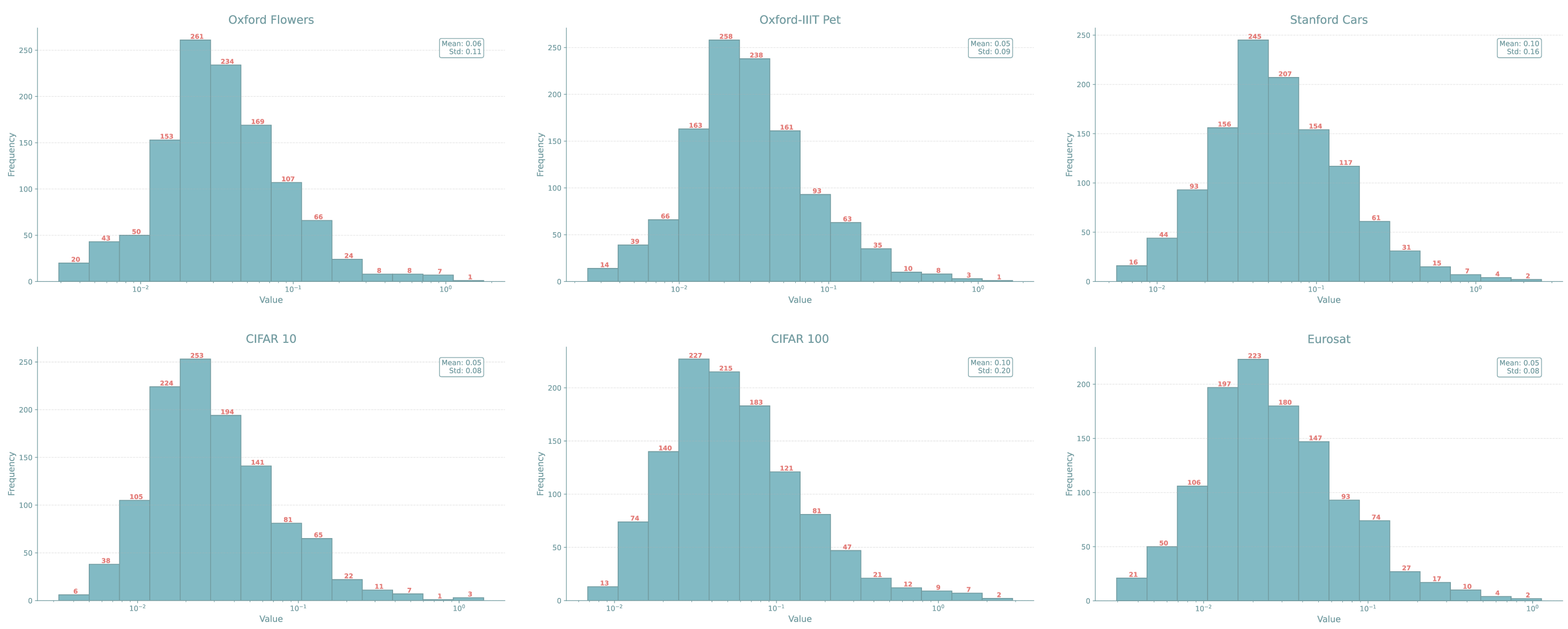
Figure 6: Distribution of singular values in LoRAs trained on different image classification datasets reveals the highly skewed spectral structure exploited by PARA.
Implications and Future Directions
The PARA approach establishes a new paradigm in adapter-based fine-tuning: decoupling optimization from deployment via data-free, post-optimization spectral pruning. This fundamentally alters the workflow—“Train First, Tune Later”—allowing practitioners to postpone adapter sizing decisions until deployment, adapt rapidly to new hardware constraints, and minimize both retraining and hyperparameter search.
Practically, this facilitates multi-tenant production settings, reduces VRAM and storage consumption, and supports on-the-fly per-tenant constraint satisfaction. Theoretically, PARA’s spectral redistribution opens avenues for both more principled subspace exploration and downstream robustification.
Future research may explore:
- Layer-type-specific spectral dynamics for further custom allocation strategies;
- End-to-end integration with SVD-initialized (e.g., PiSSA, MiLoRA) or quantized (e.g., QLoRA) pipelines;
- Automated energy threshold selection via reward-based or Bayesian methods;
- Hierarchical adapter architectures leveraging PARA for modularity and composition.
Conclusion
PARA introduces a rigorously justified, computationally efficient, and empirically superior solution for post-training compression and deployment of LoRA adapters. By shifting the complexity from the training phase to a mathematically grounded, spectral-analysis-driven post-processing step, PARA offers a compelling, scalable framework for both research and production, resulting in compact, high-performing, and hardware-adaptive parameter-efficient adapters (2604.27796).

