- The paper introduces a BEV-driven DSL that reduces complex 3D indoor scene generation to efficient 2D layouts using hierarchical sub-layouts.
- It demonstrates improved spatial fidelity with near zero-collision rates and high satisfaction of atomic scene requirements across various tasks.
- The SG-Agent framework employs closed-loop refinement and synthetic training to iteratively correct errors and optimize scene generation.
SpatialGrammar: A Domain-Specific Language for LLM-Based 3D Indoor Scene Generation
Motivation and Limitations of Existing Representations
Automated generation of 3D indoor scenes from natural language is central to VR, gaming, and embodied AI. Existing methods involving LLMs frequently employ either geometric scene formats (e.g., raw 6-DoF object coordinates) or verbose programmatic representations (e.g., JSON, Python scripts), both of which hinder efficient spatial reasoning and constraint enforcement. The lack of a spatially intuitive, compact, and verifiable representation introduces persistent issues: frequent spatial errors, object collisions, and unreliable satisfaction of complex language constraints.
SpatialGrammar directly addresses these deficiencies by proposing a DSL anchored in Bird's-Eye View (BEV) layouts, combined with deterministic compilation to valid 3D geometry. This approach encodes geometric and physical priors as part of the representation itself, facilitating both generative efficiency and downstream verifiability.

Figure 1: The LLM agent generates complete 3D indoor scenes, including furniture layout and wall structure, by writing in our proposed SpatialGrammar DSL.
SpatialGrammar Language Design: BEV-Driven DSL and Hierarchical Structures
SpatialGrammar comprises two interlocked DSLs: LLMSLI for object/furniture arrangements and LLMSLB for architectural elements. The key insight is dimensionality reduction—projecting 6-DoF object poses into a 2D BEV grid, with gravity alignment and enforced grid-based object placement. This representation eliminates the need for LLMs to predict metric heights or arbitrary 3D positions, instead focusing generation on efficient 2D placements with explicit yaw-angle control and optional fine-tuning for object scale.
For hierarchical scene expression (e.g., objects atop tables, items on bookshelves, chessboard arrangements), LLMSLI recursively attaches local BEV grids to parent object faces through a sub-layout system. Each sub-layout operates over a local frame anchored to the chosen face (top, bottom, sides), and recursive frame composition yields the complete world-space placement. This mechanism naturally expresses hierarchical, stacked, and supported configurations.
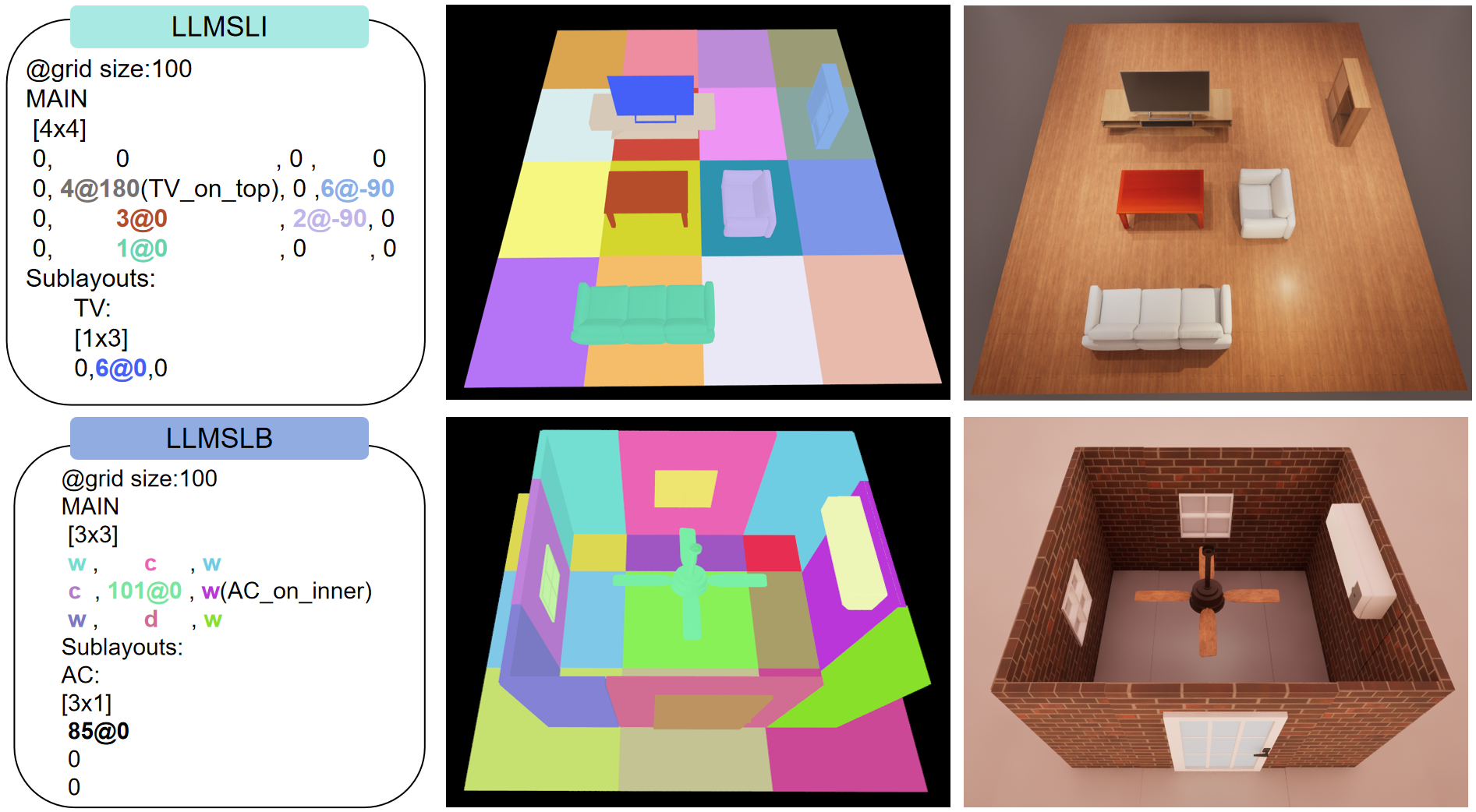
Figure 2: Each row shows DSL code (left), semantic intermediate representation (middle), and final render (right). Top: LLMSLI places furniture on a BEV grid with a sub-layout attaching a TV onto the stand. Bottom: LLMSLB defines walls and openings, with a sub-layout mounting an air conditioner on the wall.

Figure 3: Sub-layout examples for hierarchical scene control with chessboards, office desks, and refrigerators.

Figure 4: Modular asset composition via sub-layouts, e.g., multi-layered bookshelf with items placed on shelf surfaces.
The LLMSLB extension leverages the same BEV abstraction, expressing walls, doors, and other structure-centric elements in a grid that captures architectural topology. Wall-mounted or ceiling-attached objects are handled as sub-layouts anchored to the relevant surface.
Agentic Generation and Closed-Loop Refinement: The SG-Agent Workflow
The SpatialGrammar framework is instantiated in SG-Agent, a tool-augmented agent that operates in a closed feedback loop. Generation proceeds via the following cycle:
- User prompts specify desired scenes or edits in natural language.
- The agent generates DSL code using language capabilities and scene context.
- The SpatialGrammar compiler deterministically produces intermediate 3D geometric layouts.
- The Draft Engine provides real-time visualization, physics-based collision checks, and semantic/asset renders.
- Compiler and engine feedback (symbolic and visual) are used by the agent to iteratively revise the DSL, correcting spatial, semantic, and syntactic errors.
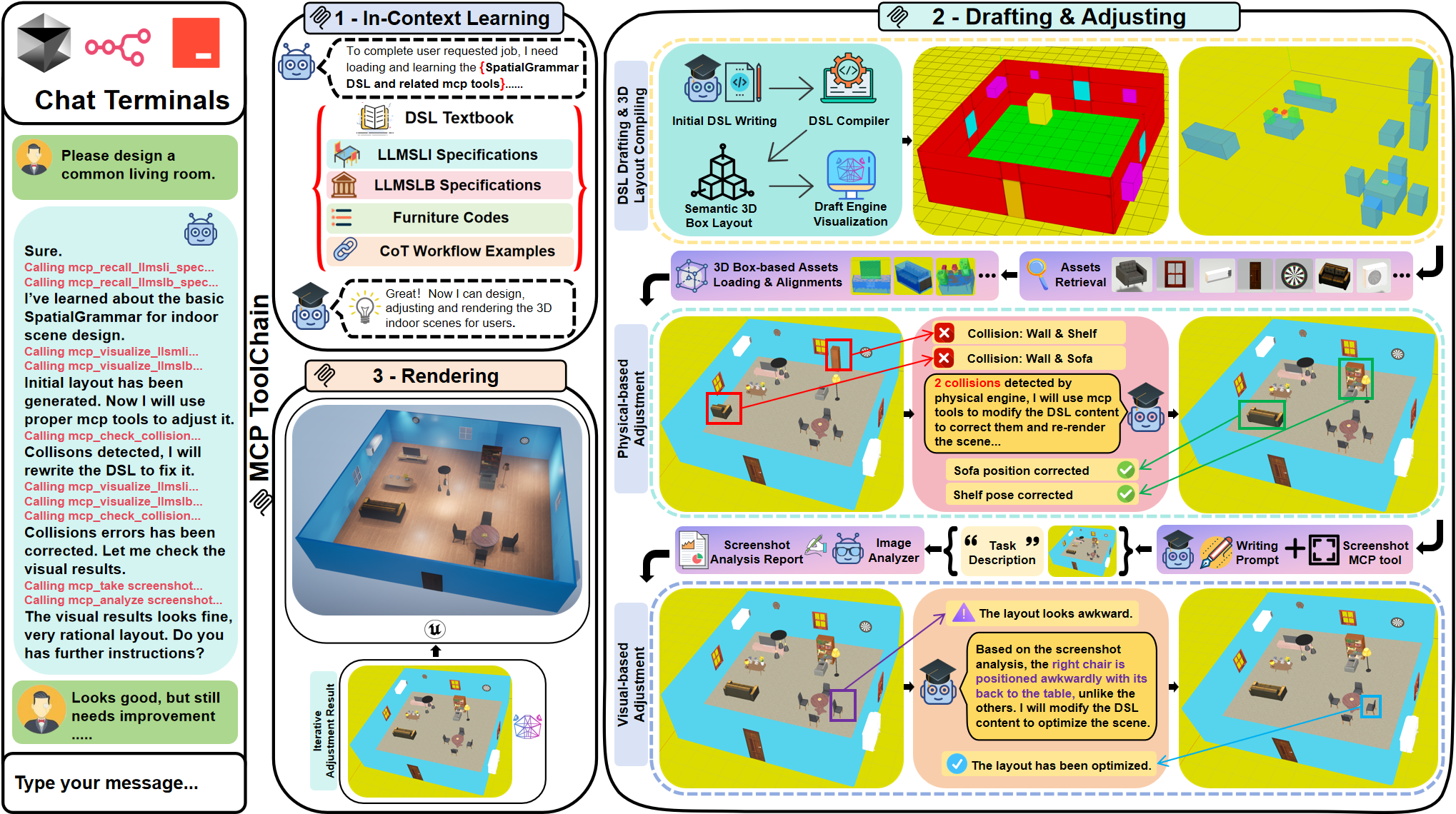
Figure 5: Overview of the SpatialGrammar agentic workflow from chat-driven prompts to validated 3D scene code and rendering.
SG-Agent supports memory-based context, enabling full conversational scene editing over multiple refinement turns. Modular asset integration utilizes retrieval mechanisms adaptable to both numeric (curated vocabulary) and open-vocabulary identifiers.
Compiler-Driven Synthetic Training and Error Chain Preference Optimization
SpatialGrammar’s deterministic compiler underpins a fully synthetic, self-sufficient SLM training regimen. The 104M-parameter SG-Mini model is trained across three stages: pre-training, SFT, and DPO—with all data generated by the programmatic engine and validated for scene correctness, collision-freedom, and syntactic soundness.
Crucially, the Error Chain method synthesizes realistic negative samples for DPO, chaining together multiple error types (semantic, spatial, collision, syntax) to mimic plausible LLM failure modes and drive robust error discrimination.
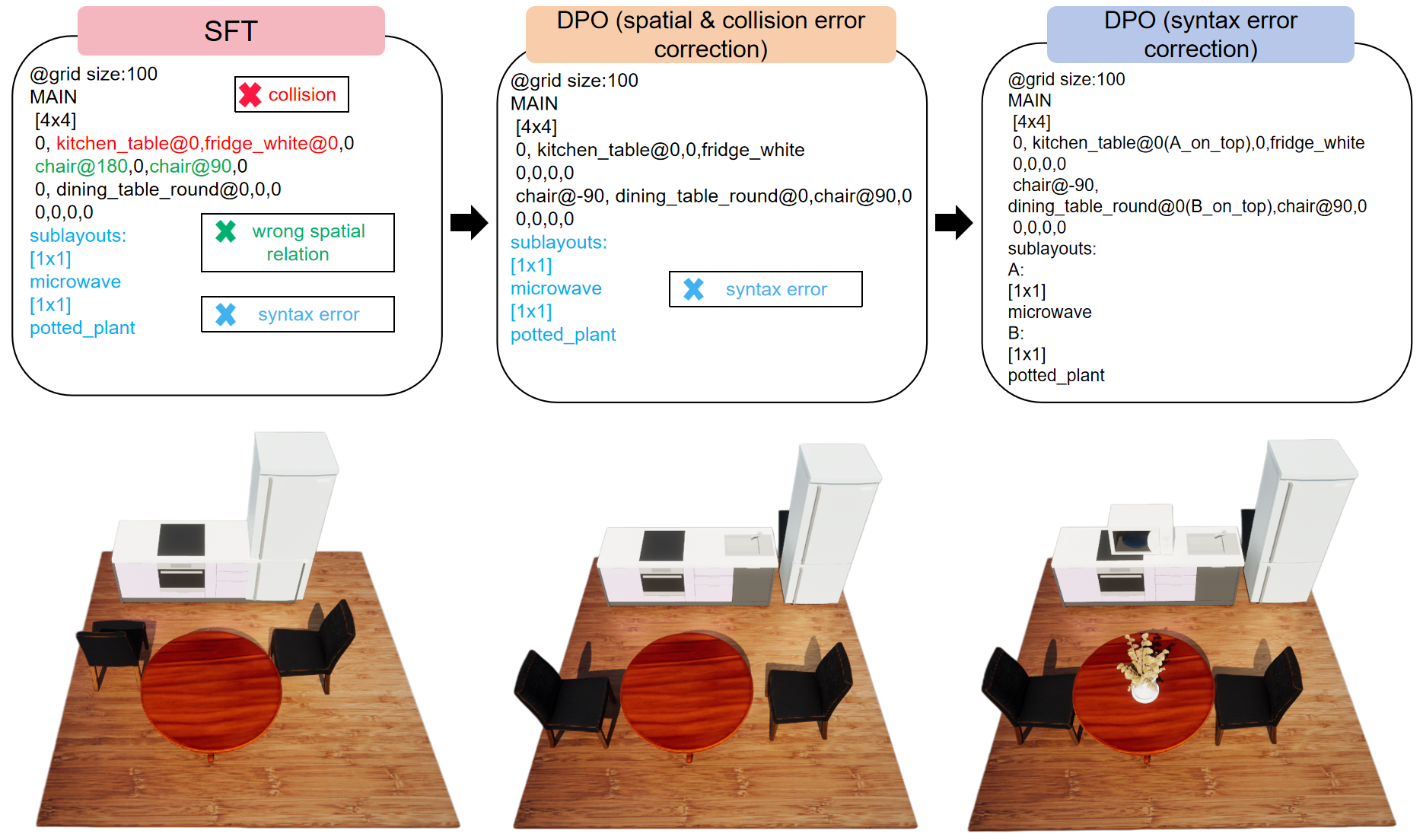
Figure 6: Qualitative example of DPO training effects: injecting different error types progressively corrects collision, spatial, and syntax errors.
Quantitative and Qualitative Evaluation
Experiments span five scenario types: single-object placement, multi-object layouts, multi-turn conversational editing, hierarchical (nested) placement, and architectural generation. Metrics include:
- DRFR (Decomposed Requirements Following Ratio): Fraction of atomic requirements satisfied.
- CR_obj (%): Object-level collision rate.
- CLIP Score: Visual-semantic alignment.
- GAS/HAS: Automated and human aesthetic ratings.
Key Numerical Findings:
Scenarios demanding conversational scene building demonstrate SG-Agent’s capacity for context retention and incremental updates (Figure 8). SG-Mini, while not agentic, sustains strong single-shot performance due to the structured, model-friendly representation and preference-driven training.

Figure 8: Contextual memory-based iterative scene refinement by the agent, evolving wall structure into a complex 3D scene.

Figure 9: Architectural generation results showing wall shape control and structural detail.
Implications, Limitations, and Prospects
The introduction of SpatialGrammar has several notable implications:
- Practical: The DSL framework enables efficient and error-resilient pipeline integration for VR content creation, interior design tools, and autonomous agent training environments, significantly lowering the barrier for achieving physically plausible, editable 3D scenes from high-level user intent.
- Theoretical: Encoding physical priors within the generation representation itself demonstrably enhances spatial reasoning and constraint satisfaction in LLM-driven systems, supporting the design of future AI models that leverage domain-specific, programmatic abstractions as integral scaffolding.
- Scalability: The compiler-based synthetic training regime circumvents the bottleneck of annotated datasets, generalizing to other structured generation modalities and lowering resource requirements for specialized SLM deployment.
Challenges for future work include scaling the compositional expressivity for highly irregular, non-gravity-aligned layouts, expanding sub-layout grammars to accommodate arbitrary containment, and coupling DSL generation with vision-language feedback for open-domain scene realism and photorealistic asset selection.
Conclusion
SpatialGrammar provides an effective, model-friendly DSL for 3D indoor scene generation, encoding geometry and physics as part of the representation and leveraging deterministic compilation for verifiable constraint enforcement. SG-Agent achieves state-of-the-art results in spatial fidelity and editability via closed-loop agentic feedback, while the SG-Mini SLM demonstrates that competitive scene generation is possible with orders-of-magnitude fewer parameters through compiler-driven synthetic data and error chain preference learning. This framework sets a robust foundation for further research at the intersection of LLMs, structured program synthesis, and interactive, multimodal environment creation.
(2604.27555)


