AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
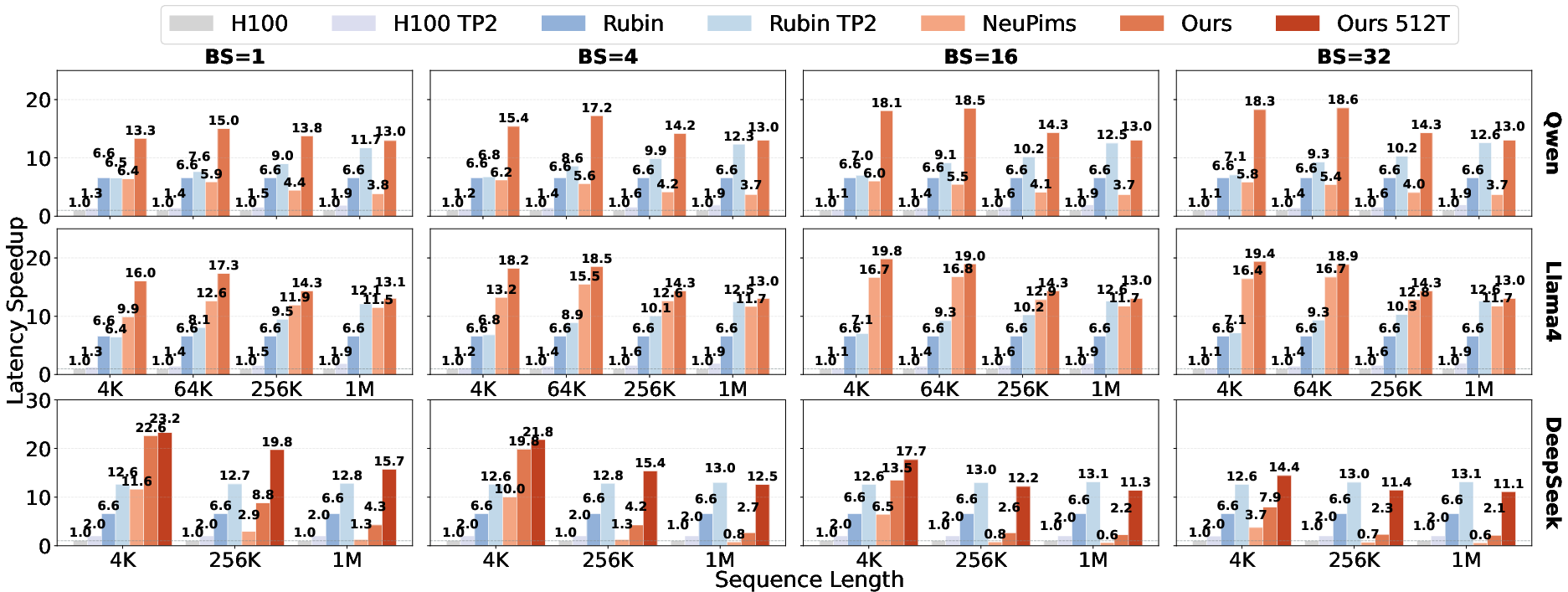
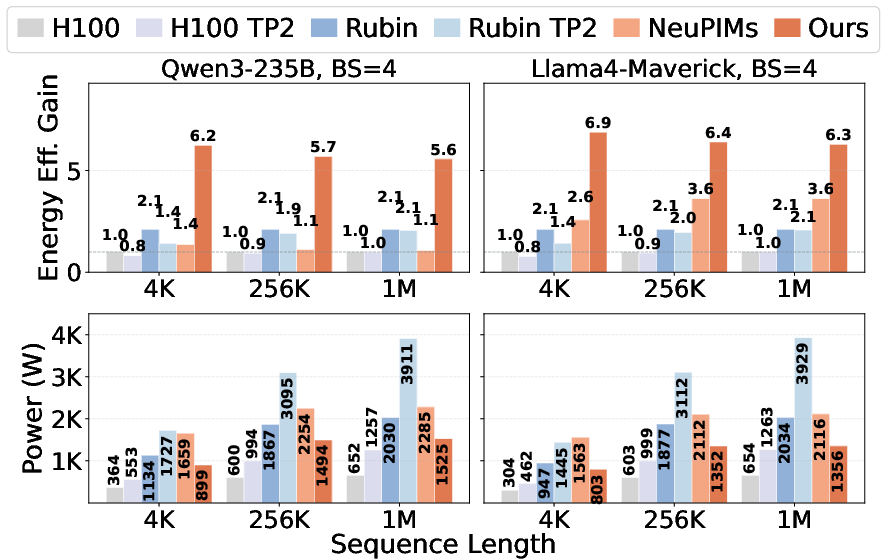
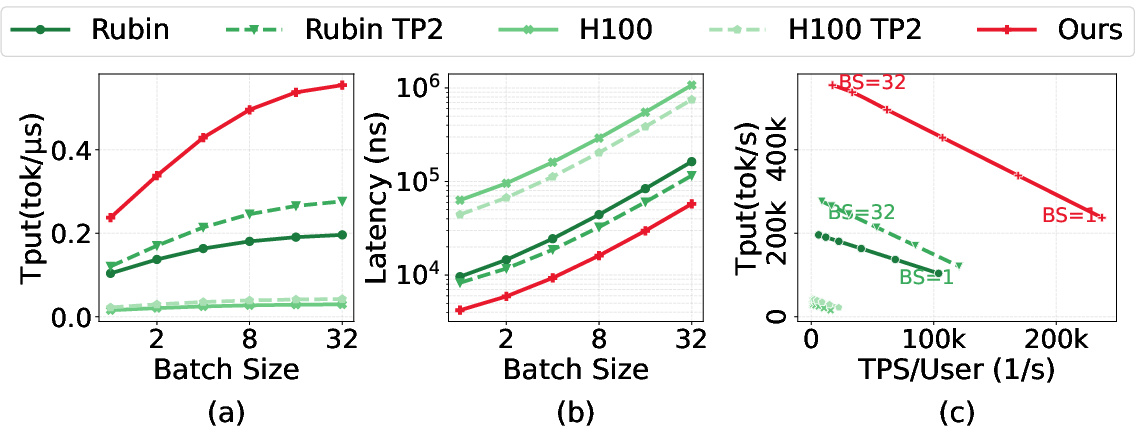
Abstract: All current LLM serving systems place the GPU at the center, from production-level attention-FFN disaggregation to NVIDIA's Rubin GPU-LPU heterogeneous platform. Even academic PIM/PNM proposals still treat the GPU as the central hub for cross-device communication. Yet the GPU's compute-rich architecture is fundamentally mismatched with the memory-bound nature of decode-phase attention, inflating serving latency while wasting power and die area on idle compute units. The problem is compounded as reasoning and agentic workloads push context lengths toward one million tokens, making attention latency the primary user-facing bottleneck. To address these inefficiencies, we present AMMA, a multi-chiplet, memory-centric architecture for low-latency long-context attention. AMMA replaces GPU compute dies with HBM-PNM cubes, roughly doubling the available memory bandwidth to better serve memory-bound attention workloads. To translate this bandwidth into proportional performance gains, we introduce (i) a logic-die microarchitecture that fully exploits per-cube internal bandwidth for decode attention under a minimal power and area budget, (ii) a two-level hybrid parallelism scheme, and (iii) a reordered collective flow that reduces intra-chip die-to-die communication overhead. We further conduct a design-space exploration over per-cube compute power and intra-chip D2D link bandwidth, providing actionable guidance for hardware designers. Evaluations show that AMMA achieves 15.5X lower attention latency and 6.9X lower energy consumption compared with the NVIDIA H100.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making LLMs answer faster when they have to look at very long inputs (up to about 1,000,000 tokens). Today, most systems use GPUs (graphics processors) at the center. But for the “attention” part of LLMs during decoding, GPUs aren’t a great match. The authors propose a new kind of chip called AMMA that puts memory, not the GPU, at the center. Instead of big compute chips, AMMA uses many high-speed memory stacks that also have small processors built right next to the memory. This makes reading data fast and reduces the waiting time that slows GPUs down.
Key objectives in simple terms
The paper tries to:
- Cut the time it takes for the “attention” step in LLMs when handling very long inputs (like books or long conversations).
- Use the huge speed of modern memory more effectively, instead of relying on tons of compute that sits idle.
- Design a chip where many memory units work together smoothly without wasting time sending data back and forth.
- Figure out the best balance between how much compute each memory unit should have and how fast they should talk to each other.
- Show that this approach can be much faster and more energy-efficient than today’s top GPUs.
How they approach it (with everyday analogies)
Here are the main ideas, with simple explanations:
- Why GPUs struggle: Imagine a kitchen with lots of cooks (compute) but only a few small pantries and narrow hallways (memory bandwidth). If the dish needs constant trips to the pantry, most cooks stand around waiting. That’s “memory-bound” work. Decode-time attention is like that—limited by how fast you can fetch data, not by how many cooks you have.
- Put memory at the center: AMMA replaces big GPU compute chips with 16 high-bandwidth memory stacks. Each stack has a small processor right under it (near-memory processing, or PNM). That’s like putting many pantries around the kitchen, each with a small prep station, so getting ingredients is quick and local.
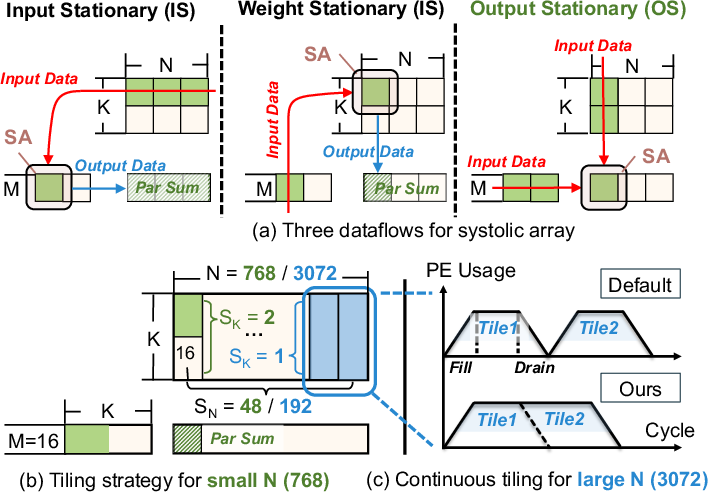
- Many small “compute tiles” instead of a few big ones: The chip uses many tiny compute blocks called systolic arrays (think of them as small “conveyor belts” that pass numbers around). Because the attention step processes small batches during decoding, lots of small belts stay busy better than a few huge belts that would sit half empty.
- No big last-level cache (LLC): GPUs use a large cache to reuse data and keep compute units busy. But here, the data doesn’t get reused much, so the cache wastes power. AMMA drops it and uses that space and power for useful work.
- Smart data passing instead of heavy caching: A lightweight, two-level crossbar inside the chip helps share the small pieces of data that do need to be shared (like the current “query” vector), without re-reading from memory.
- Better “dataflow” and “tiling”: The way numbers move through the conveyor belts is carefully chosen (called output-stationary dataflow). The chip chops big math problems into just-right tiles so all belts stay busy. It even “pipes” tiles so when one tile finishes draining, the next starts filling immediately—like using the same lane for both exiting and entering in a timed way to avoid empty gaps.
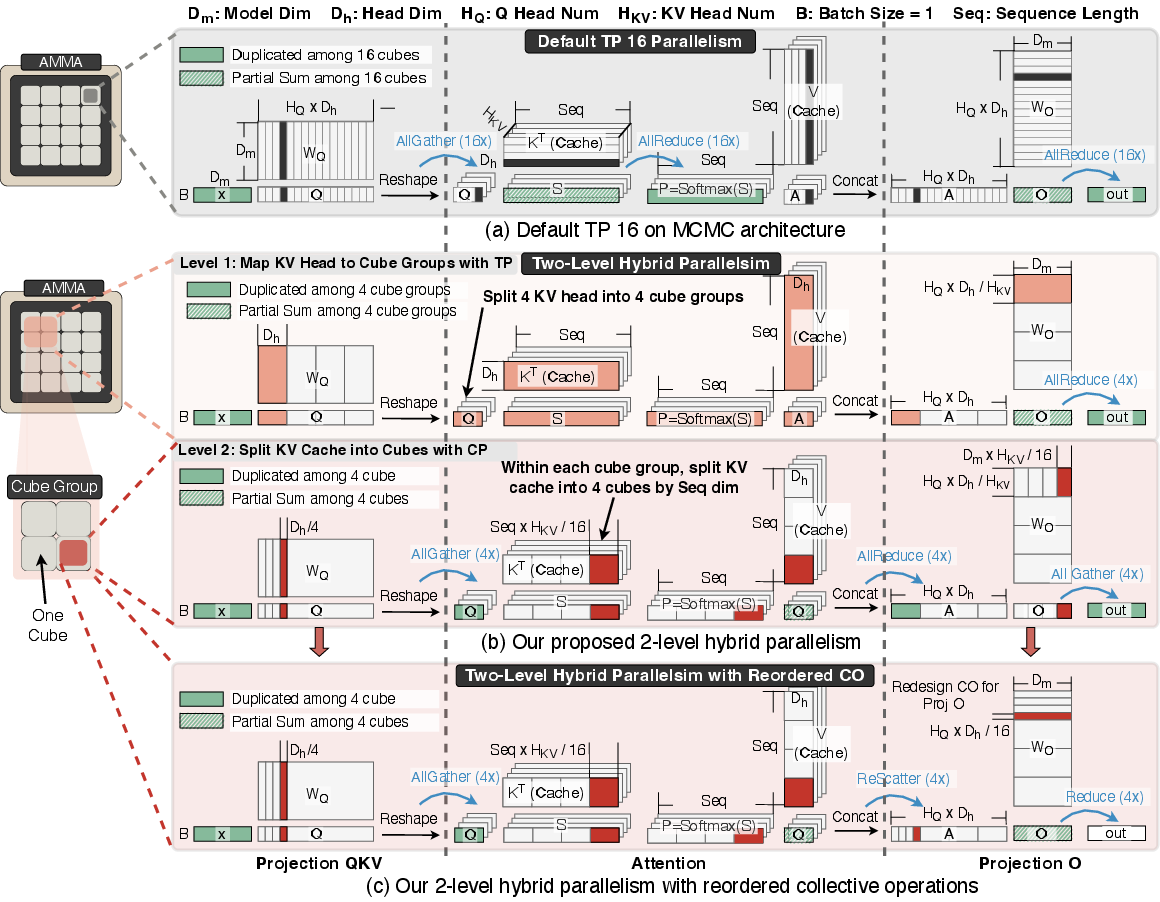
- Two-level teamwork across the 16 memory stacks:
- Level 1 (between groups): Split work by “heads” (attention heads). Each group of 4 stacks takes responsibility for a subset of heads so they can work independently most of the time.
- Level 2 (within each group): Split the long sequence (the timeline of tokens) across the 4 stacks. Each stack handles a chunk of the long history and then combines results with its neighbors. This keeps communication local and fast.
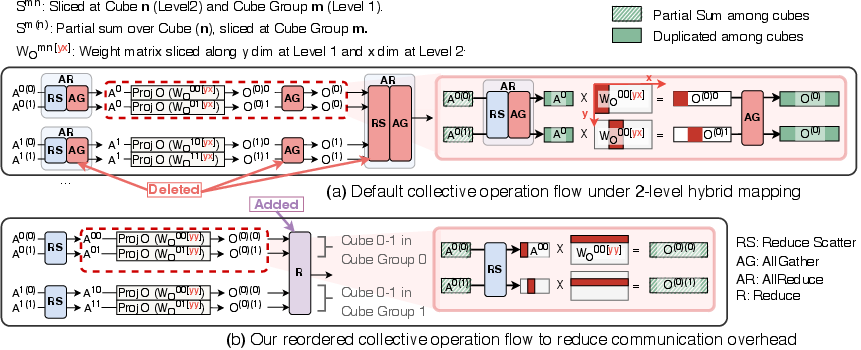
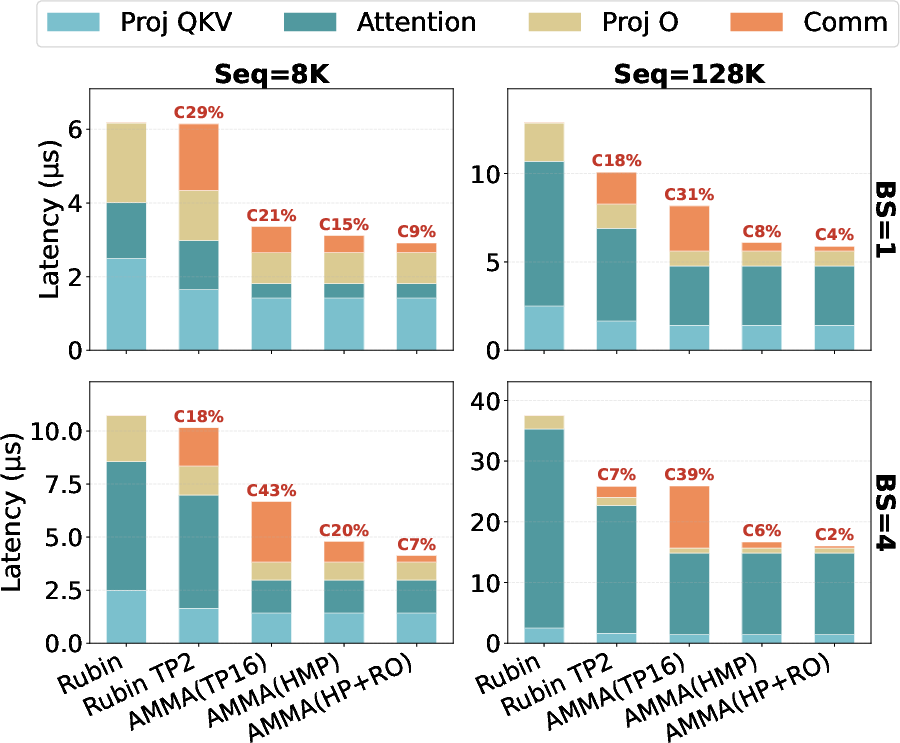
- Fewer, smarter “group operations”: When several chips must combine their partial answers, they usually do expensive “AllReduce” or “AllGather” steps (imagine many study groups merging their notes over and over). The authors reorder the steps so they combine only what’s needed, in fewer rounds, and send to one place, not to everyone. They also prove this reordering is mathematically correct by using a version of softmax that can be combined across chunks and the fact that linear layers can be moved before summing.
- How they tested: They used simulators for the tiny conveyor belts (systolic arrays) and for the network between chips, and also profiled real GPUs. They compared AMMA with NVIDIA’s H100 and projected future GPUs, looking at latency and energy.
Main findings and why they matter
- Much faster and more efficient: AMMA cuts attention latency by about 15.5 times and reduces energy use by about 6.9 times compared to an NVIDIA H100. That’s a big improvement, especially for long contexts where users feel every delay.
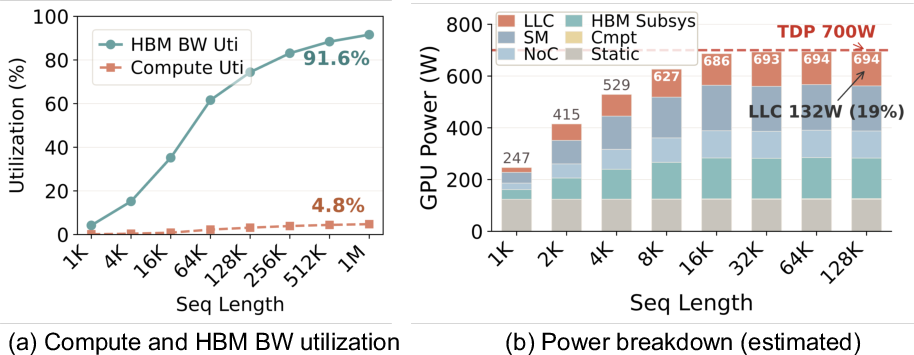
- GPUs waste power on this task: The paper shows that for long-context attention, GPUs often hit high power use even when their compute units are mostly idle. Large caches and on-chip networks burn power without helping much. AMMA avoids that by focusing on memory bandwidth and simple, targeted compute.
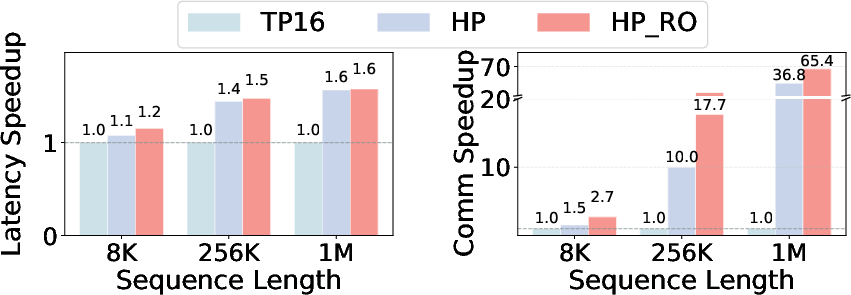
- Communication is often the bottleneck: Instead of letting data ping-pong across a big GPU system, AMMA keeps most data local and shrinks the number and size of “everyone-talks-to-everyone” steps. This is crucial when context lengths reach hundreds of thousands to a million tokens.
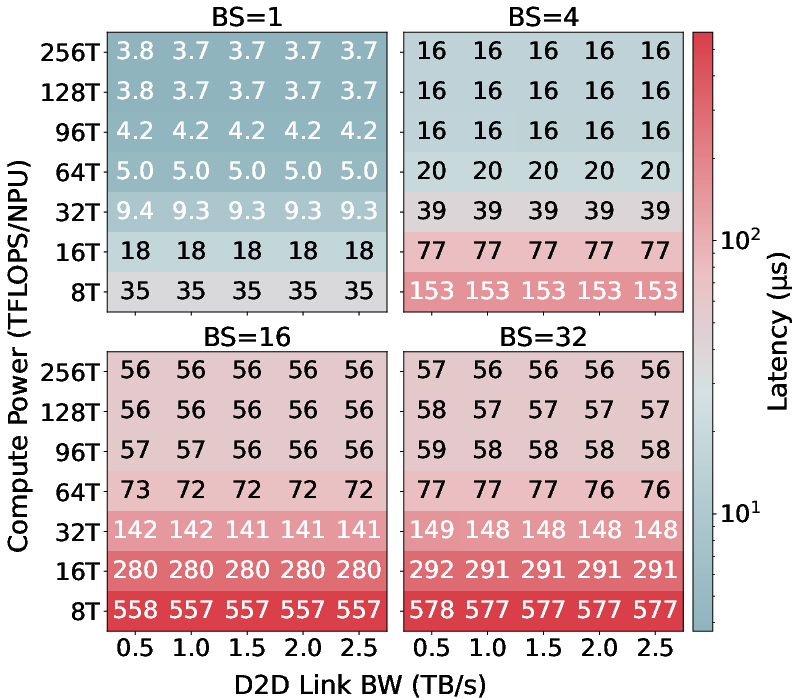
- Practical design guidance: They explore how much compute per memory stack is actually useful and how fast the links between stacks should be. This helps future chip designers make better trade-offs.
What this could mean going forward
- Better user experience for long inputs: Reading long documents, doing complex reasoning, or acting as smart agents often needs huge context windows. AMMA makes those experiences much snappier.
- Lower data center power: If attention gets faster and uses less energy, running big models at scale becomes more sustainable and cheaper.
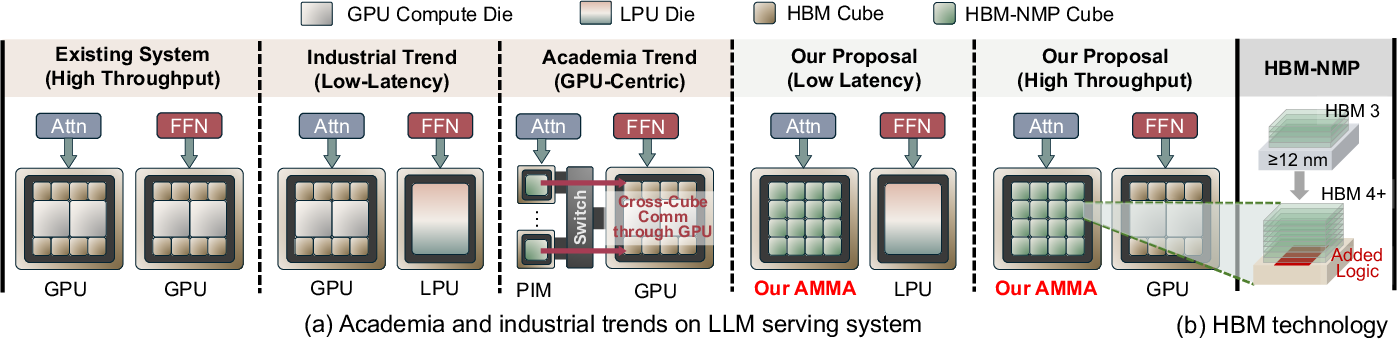
- New kind of AI hardware: The paper suggests a shift from “GPU-centric” to “memory-centric” for certain AI tasks. AMMA can pair with other specialized chips (like LPUs for feed-forward layers) so each part of the model runs where it’s happiest. This points to a future of mixed, specialized chips that work together.
- Inspires further research: By showing that near-memory compute with smart parallelism and communication can beat GPUs for long-context attention, the paper opens the door to more designs that treat memory as a first-class citizen, not just a storage add-on.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, structured list of concrete gaps and open questions the paper leaves unresolved. Each point highlights what is missing or uncertain and can guide follow-on research.
Architectural feasibility and hardware realism
- Thermal feasibility of dense PNM beneath HBM stacks is unquantified: no thermal/signal-integrity co-simulation, heat paths, or DRAM error-rate impacts from logic activity at 2 GHz under 16 cubes are provided.
- Power numbers are inconsistent and incomplete: the table lists AMMA “TDP 1440 W” while later stating “15 W/cube, 240 W/chip,” and does not sum HBM cube power (≈75 W/cube) plus PNM to a package-level budget or show cooling requirements.
- Area budgeting on the HBM logic die is not shown: floorplan, timing closure, and wirelength for “96×(16×16) SAs + two-level crossbar + DMA + vector units + PHY/MC” at ≤5 nm are not quantified.
- D2D link assumptions lack validation: UCIe 3.0 latency (≈15 ns/hop) and per-link bandwidth (≈1.5 TB/s) are assumed without pin-count, bump pitch, energy/bit, crosstalk, and interposer routing analysis for a 4×4 mesh across 16 HBM stacks.
- No reliability analysis under high activity: ECC coverage for logic-die SRAMs, D2D links, and crossbar; DRAM timing/refresh interactions with near-logic switching; error propagation through re-ordered collectives are not addressed.
- Yield and manufacturability of a 16‑cube, on-interposer multi-chiplet are not discussed (assembly yield, test strategy, spare lanes/links, rework for faulty cubes).
- Power delivery network design is unaddressed: package PDN impedance, droop under bursty traffic, and DRAM/PNM co-supply constraints remain open.
Microarchitecture and dataflow details
- SA and crossbar design space is only partially explored: no alternatives (e.g., 8×32, 32×16 SAs), crossbar radix/segmenting, buffer size trade-offs, or wire/arbiter power models are reported.
- Two-level crossbar scalability and congestion are unmodeled: arbitration latency, backpressure, and worst-case contention when broadcasting queries and reducing partials are not evaluated.
- OS dataflow choice lacks sensitivity analysis: break-even regions vs IS/WS under varied M/K/N, head counts, and tiling; dynamic dataflow switching policies are not explored.
- Continuous tiling scheduling hazards are unaddressed: detailed DMA timing, double-buffer sizing beyond the 200 ns assumption, and stall behavior under HBM bank conflicts are not analyzed.
- HBM access/placement policy is unspecified: KV/weight mapping to channels/banks/vaults, row-buffer locality, bank-group conflicts, and refresh effects are not modeled.
Parallelism and collectives
- Collective algorithms and offload are unspecified: ring vs tree vs pipelined Reduce/AllReduce within groups, hardware assist on the logic die, and sensitivity to hop distance and contention are not reported.
- Reordered collective’s numerical stability under low precision is not evaluated: the online softmax with FP8/KV quantization and accumulation across cubes may be unstable at 1M tokens without explicit scaling/error analysis.
- Weighted Reduce implementation details are missing: how αn factors (m, ℓ statistics) are maintained in FP formats, fused into reductions, and their overhead on D2D bandwidth/latency.
- Sensitivity to different head configurations is incomplete: performance/communication behavior for MQA (HKV=1), extreme GQA group sizes, or MLA variants with different sharing ratios is not quantified.
- Group sizing/topology remains an open design knob: the 2×2 per-head sub-mesh is fixed; optimal group shape/size under different D2D bandwidths, mesh diameters, and link failures is not explored.
- Multi-request concurrency and isolation are not handled: how groups are time- or space-multiplexed across requests, QoS, fairness, and interference on shared D2D/NoC are unstudied.
Scope of functionality and software stack
- End-to-end serving integration is not quantified: latency/throughput impact of attention–FFN disaggregation (hand-off to LPUs/GPUs), inter-package links (CXL/NVLink/PCIe), and scheduling across devices is absent.
- Prefill and non-attention ops are excluded: the implications for total E2E latency, operator fusion (e.g., RoPE, RMSNorm, residual adds), and whether PNM vector units suffice for those ops remain unclear.
- Programming model and compiler toolchain are not described: kernel API, graph partitioning, tiling codegen, collective scheduling, and runtime orchestration across cubes are missing.
- Memory capacity planning is not shown: per-layer KV cache and weight footprints at 1M context for large models, placement across 16 cubes, eviction/spilling policies, and multi-tenant sharing strategies are unspecified.
- Host interface and system integration are open: how the chip connects to servers (UCIe/CXL/PCIe), coherency/protocol support, and software drivers/runtime libraries are not defined.
- Security/isolation are unaddressed: memory protection between requests/tenants across cubes, side-channel resistance in shared crossbars/links, and secure reset/zeroization of KV state.
Evaluation methodology and baselines
- Results are incomplete and partly projected: Rubin performance is extrapolated by scaling H100 rather than measured or cycle-accurate simulated; AMMA is evaluated with ScaleSim/AstraSim without RTL/physical models.
- Baseline optimizations are unclear: whether GPU baselines use state-of-the-art attention kernels (Flash-/Paged-/SDPA variants), KV quantization, L2 bypass, or NVLink-Switch collectives is not stated.
- UCIe and D2D traffic models are optimistic: no modeling of protocol overheads, credits, retries, or adapter buffering; latency/bandwidth under contention and realistic packetization are not assessed.
- Numerical accuracy is not evaluated: FP8/INT formats for Q/K/V, projections, and accumulations; impact of reorder on perplexity/accuracy for long-context benchmarks is missing.
- Workload coverage is narrow: detailed results for 1M-token contexts are not shown; sensitivity to batch size (1–32), head dimensions, and multiple models (GQA, MLA) is incomplete or truncated.
- Energy accounting excludes important components: link energy/bit for D2D, crossbar/NoC power, and DRAM refresh; discrepancies between NVML-based GPU measurements and modeled AMMA power are not reconciled.
Robustness and future scalability
- Fault tolerance and graceful degradation are open: behavior under cube/link failures, re-routing on the mesh, redundancy, and dynamic re-sharding of KV/weights are not addressed.
- Scalability beyond 16 cubes is unproven: package/reticle limits, diminishing returns from additional bandwidth vs collective overheads, and alternative topologies (torus, folded-Clos) remain unexplored.
- Adaptivity to workload variation is missing: policies for changing group sizes, tiling, or dataflow at runtime based on sequence length, batch size, or head counts; DVFS/power-gating strategies are not proposed.
- Extensibility to emerging attention variants is uncertain: sliding-window/streaming attention, block-sparse/retrieval-augmented attention, or SSMs/hybrid architectures may require different dataflows/collectives not assessed.
Practical Applications
Immediate Applications
These applications can be pursued with current or near-term hardware/software stacks (e.g., HBM3/HBM3e GPUs, NVSwitch/NVLink clusters, existing serving frameworks) by adopting AMMA’s mapping, scheduling, and system-design insights without waiting for purpose-built AMMA silicon.
- Topology-aware, low-latency serving for long-context LLMs on current GPU clusters
- Sector: Software/AI infrastructure, cloud
- What: Adopt AMMA’s two-level hybrid parallelism (grouped TP + local CP) and reordered collectives within NVSwitch/NVLink GPU subgroups to cut cross-fabric latencies and remove redundant AllGather/AllReduce in output projection.
- Tools/workflows:
- Inference framework plugins for vLLM/TGI/DeepSpeed-Inference to:
- Partition KV heads into tightly coupled GPU subgroups (e.g., 4–8 GPUs under one NVSwitch island).
- Split the sequence locally within subgroups (CP) while constraining collectives to the local island.
- Reslice output-projection weights along the input dimension and apply softmax-weighted ReduceScatter + point-to-point Reduce (reordered collective flow).
- Runtime policy that packs requests by topology to maximize local collectives and avoids spanning islands.
- Assumptions/dependencies: NVSwitch/NVLink topologies with fast intra-group collectives; model weights can be resliced; framework support for collective reordering; benefits depend on subgroup fabric quality and batch sizes.
- Kernel-level optimizations for attention on existing tensor-array accelerators
- Sector: Software, semiconductors (TPU/NPU vendors), academia
- What: Implement output-stationary (OS) dataflow and continuous tiling for small-M GEMMs in attention kernels to improve systolic-array utilization and reduce SRAM traffic.
- Tools/workflows:
- Custom CUTLASS/XLA kernels that:
- Prefer many small arrays over few large arrays (virtual partitioning) for decode attention.
- Pipeline “drain of tile i” with “fill of tile i+1” to hide fill/drain bubbles.
- Microbenchmarks to auto-tune k-splitting (split K just enough to saturate arrays, then stop).
- Assumptions/dependencies: Hardware supports flexible tiling/virtual partitioning; kernels have control over dataflow scheduling; performance gains larger at small batch sizes and long sequence lengths.
- Serving-system disaggregation policies: attention offload to memory-centric nodes (prototype with current hardware)
- Sector: Cloud, enterprise IT
- What: Pilot a heterogeneous serving pipeline that routes attention-heavy decode phases to bandwidth-optimized nodes (e.g., HBM-rich, compute-light GPUs/NPUs) while FFN/MoE stays on LPUs/GPUs.
- Tools/workflows:
- Scheduler that separates prefill (compute-bound) and decode (memory-bound) phases, routing them to different pools.
- KV-cache affinity and pinning to decode nodes to reduce movement.
- Assumptions/dependencies: Sufficient network bandwidth/latency between pools; orchestration that can pipeline token-level stages; minimal kernel launch overheads.
- Hardware architecture guidance for near-term chiplet designs
- Sector: Semiconductors
- What: Use the paper’s design-space guidance (per-cube compute vs D2D bandwidth, preference for crossbar over LLC, small SAs) to inform next iterations of multi-die packages (e.g., GPU+HBM, NPU chiplets).
- Tools/workflows:
- Early-stage floorplanning allocating area/power from LLC/large register files to small SAs and two-level crossbars for memory-bound kernels.
- UCIe-based interposer planning emphasizing low-hop sub-meshes for collectives.
- Assumptions/dependencies: Thermal headroom under stacked DRAM; availability of robust D2D PHY/LINK IP; product timelines aligned with HBM3e/HBM4 ramp.
- Improved energy accounting and datacenter capacity planning for long-context workloads
- Sector: Cloud, sustainability/ops
- What: Update capacity planning and SLA models using the finding that GPUs hit near-TDP even on memory-bound attention, with large static/NoC/LLC power components.
- Tools/workflows:
- Token/Joule metrics in scheduling; power-aware placement and bin-packing that caps simultaneous long-context decoders per host.
- Assumptions/dependencies: Access to telemetry (NVML/SM performance counters) and the ability to enforce power-aware scheduling.
- Domain-specific deployments benefiting from lower latency in long contexts (using existing infra with mapping tweaks)
- Sector:
- Healthcare: cross-visit EHR summarization and longitudinal reasoning
- Finance: compliance and surveillance across long trade/chat logs
- Legal: e-discovery over massive document sets
- Software engineering: code assistants over multi-repo monoliths
- Education/knowledge management: long-horizon tutoring and personal knowledge bases
- What: Apply subgrouped mapping + reordered collectives to reduce response times for million-token contexts with current clusters.
- Assumptions/dependencies: Tolerable increase in memory overhead for KV-cache; frameworks support context sharding and collective tuning; privacy/compliance constraints met through on-prem or VPC deployment.
Long-Term Applications
These require new silicon or ecosystem maturation (HBM4 with advanced logic dies, multi-HBM PNM integration, UCIe 3.0-class packaging, new compilers/runtimes), but are grounded in the paper’s architecture and results.
- AMMA “Attention Processing Unit” (APU) as a standalone memory-centric accelerator
- Sector: Semiconductors, cloud/AI infrastructure
- What: Fabricate AMMA-class devices (e.g., 16 HBM4 PNM cubes on-package) delivering ~15× lower decode-attention latency and ~7× energy reduction versus contemporary GPUs for million-token contexts.
- Products/workflows:
- APU PCIe/CXL cards or on-board modules paired with LPUs/GPUs; D2D UCIe mesh across cubes; firmware exposing attention kernels as first-class ops.
- Runtime that pipelines: APU handles attention; LPU handles FFN/MoE; NIC streams tokens; KV cache pinned to APU.
- Assumptions/dependencies: HBM4 availability with ≤5 nm logic dies; thermal/EMI management under stacked DRAM; UCIe-class low-latency D2D; compiler and driver stack; supply chain for many HBM cubes.
- Disaggregated, heterogeneous LLM serving platforms (APU + LPU/GPU)
- Sector: Cloud, hyperscalers, OEMs
- What: Production systems where request phases are routed dynamically across device types (attention to AMMA APUs, FFN/MoE to LPUs, prefill to GPUs) to minimize end-to-end latency and cost.
- Tools/workflows:
- Latency-aware schedulers; KV-cache residency management; cross-device token streaming with minimal synchronization using reordered collectives.
- Assumptions/dependencies: High-throughput, low-latency interconnects (CXL 3.x, NVLink-C2C, on-board fabrics); standardized APIs across devices; robust fault isolation.
- Compiler and runtime ecosystem for memory-centric accelerators
- Sector: Software tooling, academia
- What: A compiler that automatically:
- Chooses OS dataflow and continuous tiling parameters;
- Partitions weights/activations for the two-level crossbar;
- Reslices W_O and generates reordered collectives with online-softmax metadata;
- Co-optimizes per-cube compute vs link contention.
- Assumptions/dependencies: IR extensions for collectives with weighted reductions; hardware counters to drive auto-tuning; integration with PyTorch/XLA.
- KV-cache appliances and memory-centric inference services
- Sector: Cloud/enterprise SaaS
- What: Deploy AMMA-based nodes as “KV-cache + attention” services backing multi-tenant LLM gateways.
- Products/workflows:
- Caching tiers that retain multi-session contexts; APIs for pinning/retrieving long histories; billing by token-in-cache plus token/Joule.
- Assumptions/dependencies: Multi-tenant isolation and QoS on APUs; secure memory partitioning; data governance/compliance.
- Long-context training and fine-tuning accelerators
- Sector: AI research/academia, foundation model labs
- What: Extend AMMA to accelerate attention in long-context pretraining/fine-tuning (e.g., million-token documents, video-text, multi-modal sequence models).
- Tools/workflows:
- Integrate online/ring softmax with backprop; optimizer sharding that avoids sequence-length-dependent collectives; hybrid pipelines mixing compute-bound and bandwidth-bound phases.
- Assumptions/dependencies: Backward-path kernels for memory-centric arrays; optimizer states placement; training stability at million-token contexts.
- Domain-specific appliances for latency-critical, long-horizon reasoning
- Sector:
- Healthcare: bedside agents with large, persistent patient memory
- Finance/security: real-time SIEM and fraud detection over long sequences
- Robotics/autonomy: long-horizon planners with large internal scratchpads
- What: On-prem or edge racks integrating AMMA APUs for sub-100 ms token latencies at million-token contexts.
- Assumptions/dependencies: Ruggedized thermal solutions; deterministic QoS; domain certifications (HIPAA, SOC2, ISO 26262, etc.).
- Standards and policy evolution for energy-efficient AI acceleration
- Sector: Policy, standards bodies, sustainability
- What:
- Promote metrics like tokens/Joule and memory-bandwidth efficiency in procurement and reporting;
- Encourage UCIe-class interoperable chiplet ecosystems for AI;
- Incentivize memory-centric accelerators for workloads proven memory-bound.
- Assumptions/dependencies: Consensus on benchmarks for long-context LLMs; lifecycle assessments for chiplet-heavy packages; alignment with data center energy regulations.
- Research trajectories opened by memory-centric architectures
- Sector: Academia
- What:
- Co-design of attention mechanisms that better exploit OS dataflow and crossbar sharing;
- New million-token benchmarks and simulators (ScaleSim/AstraSim models) for fair comparisons;
- Exploration of other memory-bound primitives (e.g., KV routing, retrieval scoring, sparse attention) on PNM-enabled HBMs.
- Assumptions/dependencies: Open models with long-context configs; shared trace repositories; funding for prototyping PNM logic on advanced nodes.
Notes on feasibility dependencies across applications:
- HBM4 with advanced logic dies (≤5 nm) is a key enabler for full AMMA hardware; interim benefits are achievable via software mapping and kernel optimizations on existing clusters.
- UCIe 3.0-class D2D links and low-hop topologies are critical to realize local collectives; performance degrades if forced to span high-latency fabrics.
- Thermal budgets under stacked DRAM constrain per-cube compute; microarchitectural choices (no LLC, small SAs, two-level crossbars) mitigate this but require careful co-design.
- Workload fit matters: the largest gains occur for decode attention at small batch sizes and very long contexts; compute-bound prefill or large-batch inference benefit less.
Glossary
- AllGather: A collective communication operation that gathers data chunks from all participants so everyone ends up with the complete set. "Even with a suitable parallelism strategy, the conventional attention flow requires multiple rounds of AllReduce and AllGather, whose cumulative latency becomes a significant bottleneck"
- AllReduce: A collective operation that reduces (e.g., sums) data across devices and broadcasts the result back to all of them. "Even with a suitable parallelism strategy, the conventional attention flow requires multiple rounds of AllReduce and AllGather"
- Arithmetic intensity: The ratio of computational work (FLOPs) to data movement (bytes), indicating whether a workload is compute- or memory-bound. "The roofline analysis in~\autoref{fig: 3_roofline} confirms this mismatch. The arithmetic intensity of the attention kernel falls far below the GPU's compute-to-bandwidth ratio"
- AstraSim: A network- and system-level simulator for modeling and analyzing collective communication performance. "For multi-cube performance, we use AstraSim~\cite{astrasim,astrasim2}"
- CACTI: A tool for modeling cache and memory access latency, area, and power. "using NVML~\cite{nvidia_nvml} for measurement and CACTI~\cite{muralimanohar2009cacti} for modeling"
- Context parallelism (CP): Distributing work by splitting the sequence dimension so different devices handle different context shards. "forcing context parallelism (CP) along the sequence dimension"
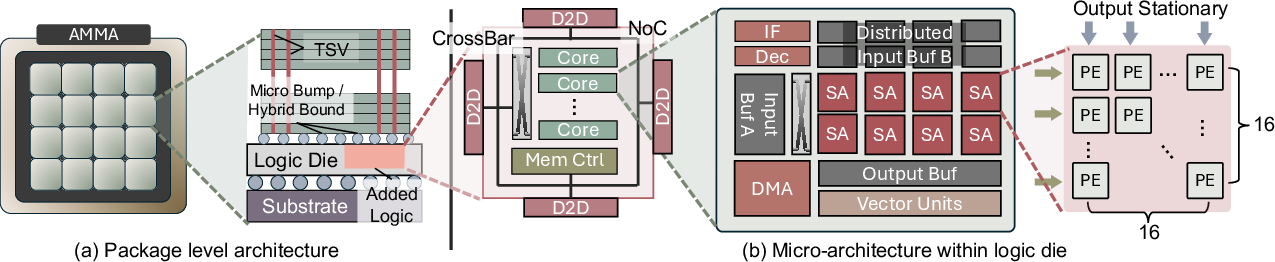
- Crossbar: A switching fabric that connects multiple inputs to multiple outputs for data sharing or aggregation. "We replace it with a two-level crossbar that broadcasts shared inputs and collects partial outputs across the 96 SAs"
- Die-to-die (D2D) links: High-speed interconnects that directly connect separate dies within a package. "The 16 cubes form a 2D mesh, with each cube connected to up to four neighbors via die-to-die (D2D) links"
- DMA engine: Hardware that moves data between memory and on-chip buffers without burdening compute units. "The DMA engine streams data directly from HBM into per-core buffers"
- FlashAttention: An attention algorithm that uses tiling and online normalization to reduce memory traffic while preserving exactness. "FlashAttention~\cite{flashattention} shows from a temporal perspective that attention can be computed incrementally"
- FP8: An 8-bit floating-point format often used to improve throughput and reduce memory bandwidth in ML workloads. "GQA attention demands only 32\,FLOPs/byte at FP8~\cite{gqa}"
- GEMM: General Matrix–Matrix Multiplication, a core linear algebra operation used in neural network layers. "integrating data loading, GEMM, GEMV, and die-to-die communication"
- GEMV: General Matrix–Vector Multiplication, often used when multiplying a matrix by a single (or few) vectors. "integrating data loading, GEMM, GEMV, and die-to-die communication"
- Grouped-query attention (GQA): An attention variant where multiple query heads share a smaller number of key–value heads to reduce memory footprint. "Grouped-query attention (GQA)~\cite{gqa} reduces the KV head count"
- HBM (High Bandwidth Memory): A 3D-stacked memory technology providing very high bandwidth via wide interfaces. "HBM bandwidth is nearly saturated at over 90\% utilization"
- HBM PHY: The physical layer interface circuitry responsible for signaling between logic and HBM stacks. "The logic die hosts the HBM PHY and memory controller"
- HBM4: The fourth-generation HBM standard with higher speeds and design changes enabling richer logic-die integration. "HBM4 and beyond adopt advanced logic dies, enabling sophisticated PNM integration on the base logic die"
- Hybrid-bonding pads: Direct copper-to-copper bonding interfaces used to connect stacked dies with fine pitch and low parasitics. "DRAM dies sit atop the logic die and are connected through micro bumps or hybrid-bonding pads"
- Hybrid parallelism (two-level): A combined mapping strategy (here TP across head groups and CP within groups) to reduce communication scope and latency. "We design a two-level hybrid parallelism scheme that maps attention across distributed cubes"
- Input-stationary (IS): A systolic-array dataflow where input activations remain stationary while other operands stream through. "WS streams , IS streams , and OS streams "
- KV cache: Stored keys and values from previous tokens used during autoregressive decoding for efficient attention. "reading their keys and values from a stored KV cache of size per layer"
- Last-level cache (LLC): The final on-chip cache level before main memory; large but relatively slow and power-hungry. "The LLC consumes significant power yet contributes little"
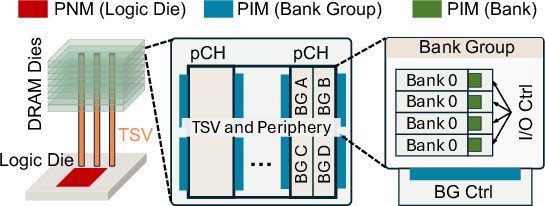
- Logic die: The base die under an HBM stack that houses controllers, PHY, and possibly near-memory compute logic. "Processing near memory (PNM) integrates compute units into the logic die"
- LPU: A specialized low-latency processing unit used to accelerate specific neural network components (e.g., FFN layers). "offloading FFN layers to dedicated LPUs"
- Mixture of Experts (MoE): A model architecture that routes inputs to different expert sub-networks to improve capacity and efficiency. "FFN (MoE) layers on separate GPU pools for independent scaling"
- Network-on-Chip (NoC): The on-chip interconnect network that links cores, caches, and I/O within a die. "each cube contains 12 compute cores, a memory controller, and four D2D ports, all connected through NoC"
- NVLink: NVIDIA’s high-speed interconnect for GPU-to-GPU and GPU-to-accelerator communication. "AttAcc connects 8 GPUs and 64 PIM devices together via NVLink"
- Output-stationary (OS): A systolic-array dataflow where partial outputs remain stationary while inputs/weights stream through. "We choose OS for AMMA because it is the only dataflow that suits our long-context, small- regime"
- Processing in memory (PIM): Placing compute units inside memory arrays/dies to exploit internal bandwidth and reduce data movement. "Processing in memory (PIM) places arithmetic units directly on DRAM dies"
- Processing near memory (PNM): Integrating compute on the logic die near memory stacks, enabling richer functionality without reducing capacity. "Processing near memory (PNM) integrates compute units into the logic die"
- Reduce (collective): A collective operation that aggregates data (e.g., sums) from multiple devices into one destination. "we replace the cross-group AllReduce with a point-to-point Reduce to the single destination cube"
- ReduceScatter: A collective that reduces data across devices and scatters disjoint result partitions back to them. "the intra-group AllReduce (ReduceScatter followed by AllGather)"
- Ring Attention: A multi-device attention algorithm that composes partial results across devices arranged in a ring topology. "Ring Attention~\cite{ring_attention} extends the same principle from the spatial perspective"
- Roofline analysis: A performance model relating achievable FLOPs to memory bandwidth and arithmetic intensity. "The roofline analysis in~\autoref{fig: 3_roofline} confirms this mismatch"
- ScaleSim: A simulator for systolic-array accelerators used to model compute throughput and dataflow. "we model each HBM-NMP cube using ScaleSim~\cite{scalesim}"
- Systolic array (SA): A grid of simple processing elements that perform regular, pipelined MAC operations for matrix math. "We instead deploy 96 systolic arrays"
- Tensor Parallelism (TP): Splitting model parameters (e.g., attention heads) across devices so each computes a shard in parallel. "Tensor Parallelism (TP), the standard multi-GPU approach for latency reduction"
- Through-silicon via (TSV): Vertical electrical connections through stacked dies enabling high-bandwidth 3D integration. "By co-locating compute with individual banks or bank groups, PIM bypasses the TSV bus bottleneck"
- Topology-aware parallelism: A strategy that maps work to hardware based on physical connectivity to reduce communication hops. "A topology-aware parallelism strategy that confines communication locally is needed"
- UCIe 3.0: A standardized chiplet interconnect protocol for high-bandwidth, low-latency die-to-die communication. "following the UCIe~3.0 protocol"
- Weight-stationary (WS): A systolic-array dataflow where weights remain stationary while inputs/outputs stream through. "WS streams , IS streams , and OS streams "
Collections
Sign up for free to add this paper to one or more collections.

