- The paper introduces a zero-shot framework that uses text shuffling and perplexity differences to distinguish machine-generated from human text.
- It leverages statistical density estimation and ensemble voting to achieve robust performance across 8 domains and 18 languages with extremely low false positive and negative rates.
- Evaluations reveal superior resilience against adversarial attacks while achieving efficient inference with smaller proxy models.
Luminol-AIDetect: Perplexity-Based, Zero-Shot Machine-Generated Text Detection via Text Shuffling
Introduction and Motivation
The increasing sophistication of LLMs has rendered the distinction between machine-generated text (mgt) and human-generated text (hgt) non-trivial, particularly in high-stakes domains such as academic integrity, social discourse, and misinformation defense. While numerous detectors exist, their efficacy is undermined by the rapid co-evolution of generators and detectors, and by their reliance on model-specific artifacts or heavy computational requirements. The Luminol-AIDetect framework posits that model-agnostic, statistically robust signals, rooted in the structural disparities between mgt and hgt, provide a more sustainable foundation for detection.
Central to this approach is the hypothesis that autoregressive LLMs, despite producing fluent and locally coherent text, exhibit global structural fragility relative to human authors. Disrupting text coherence via randomized shuffling disproportionately increases perplexity for mgt versus hgt, suggesting that measuring the differential impact of shuffling on perplexity yields a generalizable detection signal.
Methodology
Luminol-AIDetect operationalizes this hypothesis through a four-stage framework: (1) randomized text shuffling, (2) extraction of scalar perplexity-based features, (3) distributional fitting for each domain and feature, and (4) ensemble-based prediction via density estimation.
Text Shuffling and Perplexity Features
Given input text d, a single-pass shuffling procedure is applied: sentences are permuted within paragraphs, and words are permuted in single-sentence paragraphs, preserving higher-level organization. A fixed, independent, small decoder LLM computes perplexity for both d and its shuffled version dshuf. Scalar features (sum, difference, ratio, log-ratio, percent change) are then extracted from this (original, shuffled) perplexity pair.
Statistical analysis demonstrates that for all considered domains, the distributions of these features are significantly separable between hgt and mgt, validating their discriminative utility (Figure 1).
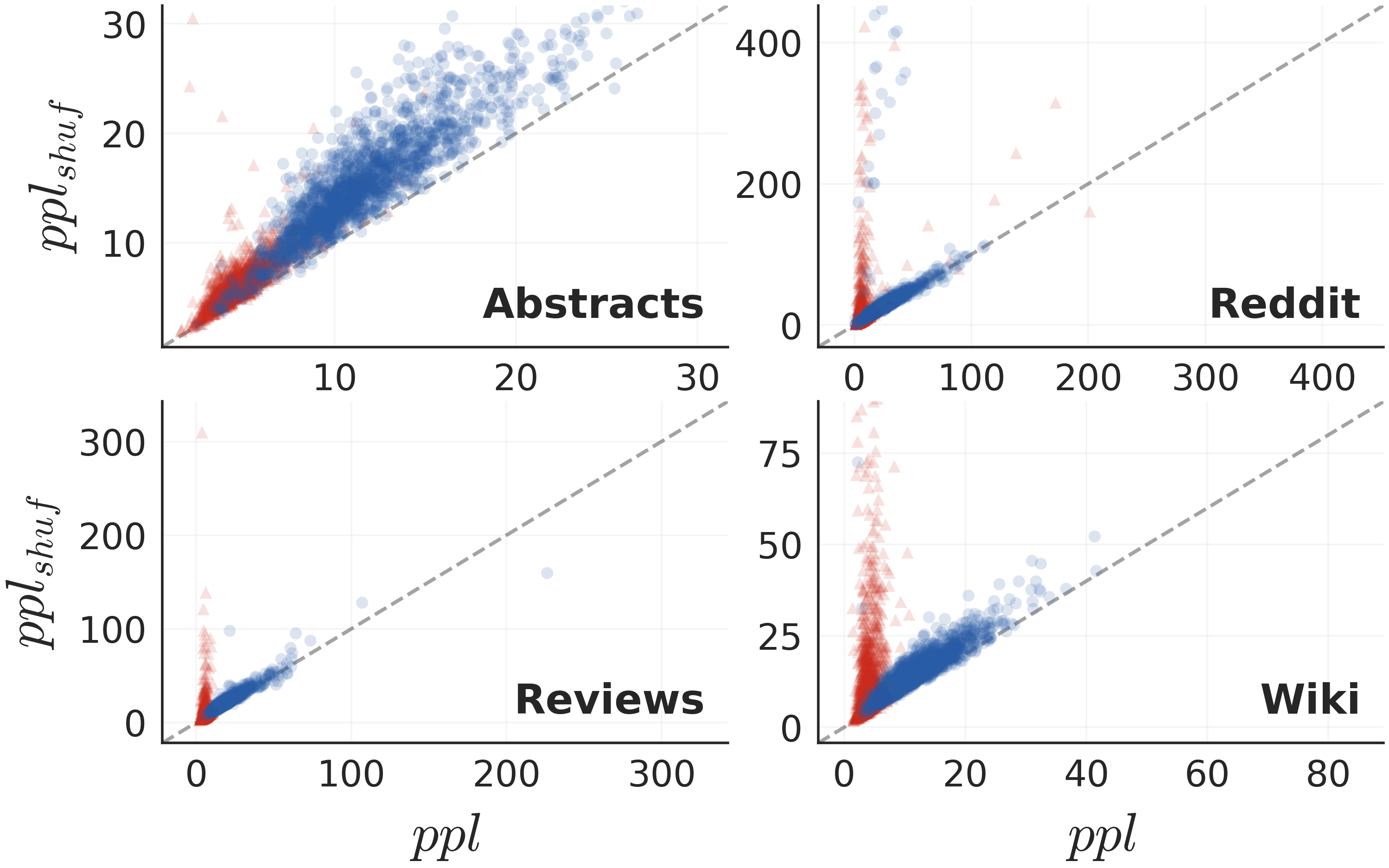
Figure 1: Text vs. shuffled-text perplexities on hgt (blue) and mgt (red) instances, for various domains, showing stronger dispersion in mgt after shuffling.
Density Estimation and Model Fitting
For each domain and feature, the method fits parametric distributions (selected via bootstrap Kolmogorov-Smirnov tests) independently to hgt and mgt samples. Across domains, Burr and Gamma are the most consistently selected families. These fitted, statistically interpretable repositories then serve as reference at inference—no training or finetuning is performed, and the approach is thus zero-shot.
Inference and Decision Logic
For a new sample, the text is shuffled and perplexities/features are computed. Domain-specific fitted densities are queried to obtain likelihood under mgt and hgt distributions for each feature. Implausibility checks reject OOD samples. Feature-wise mgt probabilities are ensembled via majority voting, with configurable tolerance for uncertainty, yielding the final class prediction.
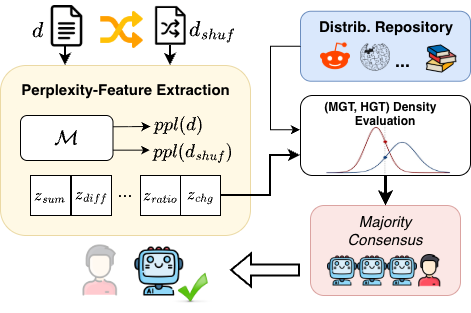
Figure 2: Luminol-AIDetect at inference: shuffling, perplexity computation, density evaluation, and ensemble-based classification.
Empirical Evaluation
Luminol-AIDetect is evaluated on RAID (multi-domain, 8 domains, 11 generators, 11 attack types) and MULTITuDE (18 languages) benchmarks. Comparison is made to leading zero-shot detectors (Binoculars, Fast-DetectGPT) and classical metric-based approaches (Log-Likelihood, Rank, Entropy, GLTR, Log-Rank, LRR).
Multi-Domain Detection
Across domains, Luminol-AIDetect achieves average FPR of 0.001±0.001, outperforming Binoculars ($0.005$) and Fast-DetectGPT ($0.017$) by substantial factors in FPR. FNR is also lowest in the majority of domains: 0.031±0.054, with best performance pooled in less conventional genres (Reddit, Poetry).
Adversarial Attack Robustness
Luminol-AIDetect exhibits strong resilience to 11 adversarial attacks, maintaining near-zero FPR and lowest mean FNR across most attacks. Notably, character-level attacks (homoglyphs, zero-width spaces) that cripple competitors are almost fully mitigated. Paraphrasing and synonym-based attacks attenuate the shuffling-perplexity signal for all detectors but Luminol-AIDetect's FNR remains lowest.
Multilingual Generalization
On MULTITuDE, spanning 18 languages (8 language families, 5 scripts), Luminol-AIDetect delivers FPR 0.000±0.001 and FNR 0.087±0.128. Alternative detectors collapse, particularly for non-Latin scripts and morphologically rich languages, a consequence of their tokenizer/model dependencies and non-transferable inductive biases.
Efficiency Analysis
In contrast to contemporary detectors that are computationally expensive due to token-level perturbation and full-vocabulary aggregation (O(TVCM) per text), Luminol-AIDetect restricts to observed tokens, eliminating the vocabulary-dependent cost. Moreover, it operates with smaller proxy models (e.g., GPT-Neo 2.7B vs. 7B), improving inference speed and memory use.
Limitations and Future Directions
- Proxy Model Sensitivity: The magnitude of the perplexity-under-shuffling signal may vary across proxy scorers, potentially affecting decision boundaries in the absence of calibration.
- Extremely Short Inputs: Very short texts challenge all statistical detectors; Luminol-AIDetect shows relative robustness but this remains an open research direction, possibly necessitating alternative perturbation strategies.
- Semantics-Preserving Attacks: High-level paraphrasing remains challenging due to reduced differential in perplexity dispersion post-shuffling.
Theoretical and Practical Implications
Luminol-AIDetect advances the case for operational, zero-shot, model-agnostic mgt detection grounded purely in the statistical properties of text coherence—as measured via shuffling-induced perturbations in perplexity. Practically, it enables scalable deployment scenarios where model provenance is unknown or closed, and computational resources are constrained. Theoretically, it suggests that the architectural constraints of autoregressive LLMs encode persistent statistical regularities that can be reliably exploited, independent of further alignment or finetuning.
This work opens avenues for detection methods robust to both adversarial perturbation and cross-lingual distributional shift, and suggests new lines of research into generative architecture-invariant diagnostic signals.
Conclusion
Luminol-AIDetect demonstrates that coherence-disrupting shuffling, combined with perplexity-based statistical modeling, yields a highly effective, scalable, and model-agnostic signal for mgt detection. Its resilience across domains, attacks, and languages, alongside its efficiency and non-reliance on black-box fingerprinting, marks a significant step toward robust, real-world deployment. Progress on the detection of extremely short and semantically-rich adversarial samples remains crucial for closing the residual gaps in operational reliability.
Reference: "Luminol-AIDetect: Fast Zero-shot Machine-Generated Text Detection based on Perplexity under Text Shuffling" (2604.25860)

