- The paper introduces GramSR, which conditions the diffusion model on dense visual features rather than text for improved image super-resolution.
- Using a three-stage LoRA protocol, GramSR optimizes the balance between pixel accuracy, semantic detail, and texture realism, achieving state-of-the-art results.
- GramSR's visual conditioning and modular training enhance performance metrics like PSNR, SSIM, and perceptual quality, outperforming previous SR methods.
GramSR: Visual Feature Conditioning for Diffusion-Based Super-Resolution
Introduction
"GramSR: Visual Feature Conditioning for Diffusion-Based Super-Resolution" (2604.25457) presents a technical advancement in the application of diffusion models (DMs) for single-image super-resolution (SR), explicitly addressing shortcomings associated with existing approaches that utilize text-based conditioning. Standard practice in diffusion-based SR leverages text prompts for conditioning, which are intrinsically limited by their high-level semantic nature and lack of precise, spatially aligned guidance. GramSR redefines the architecture by replacing this modality with dense visual feature conditioning, extracted from the low-resolution (LR) input using a frozen DINOv3 visual transformer encoder. Additionally, the authors introduce a three-stage, sequential LoRA (Low-Rank Adaptation) training protocol to disentangle and optimally balance pixel-level fidelity, semantic enrichment, and texture realism. The inclusion of Gram matrix alignment, computed from DINOv3 features, enables explicit regularization of texture statistics. The implications for both theoretical modeling of the SR problem and practical, real-time image restoration are consequential.
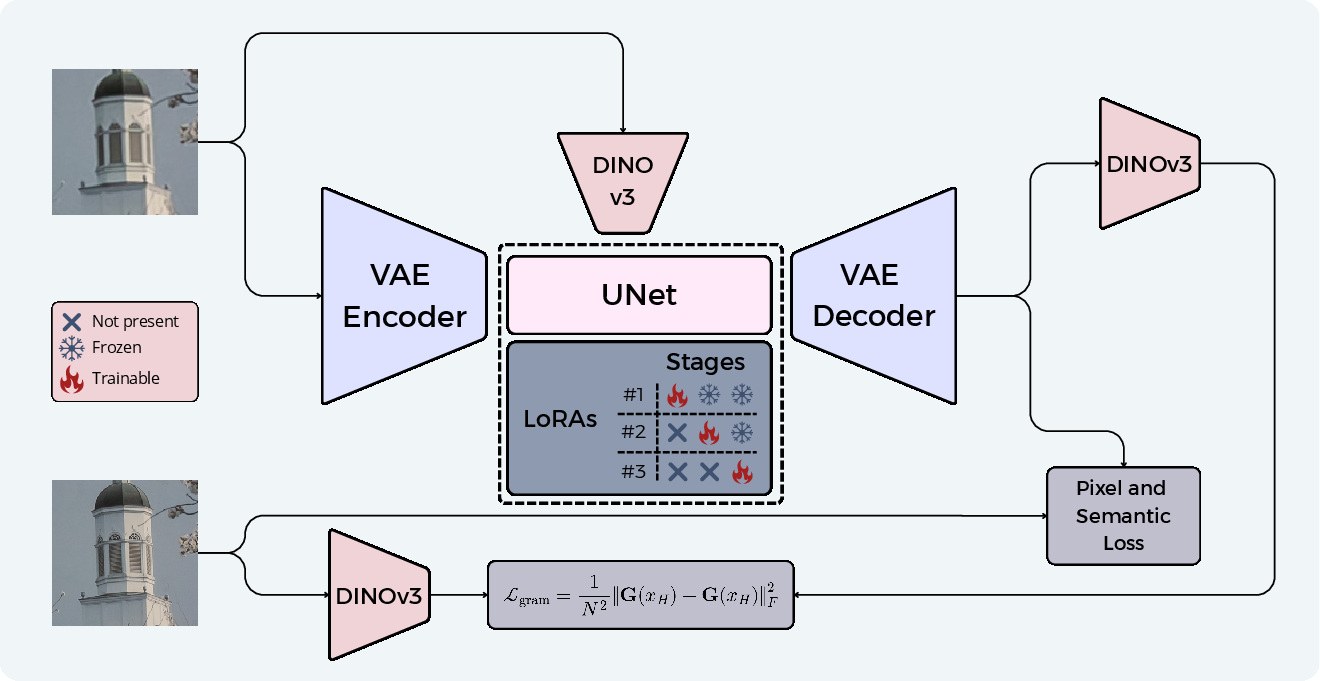
Figure 1: Overview of the GramSR pipeline, illustrating visual feature extraction via DINOv3, frozen VAE-based latent space translation, and three staged LoRA modules for pixel, semantic, and texture control.
Methodology
Visual Feature Conditioning
GramSR proposes to condition the diffusion denoiser not on text tokens, but on dense, spatially precise visual embeddings. The dense features are extracted using a pre-trained, frozen DINOv3 Vision Transformer (ViT). These features, capturing patchwise information from the LR input, are projected via an MLP adapter to generate the conditioning signal for the denoising U-Net. This architectural decoupling between the generative SR model and the conditioning path ensures preservation of alignment between the conditioning context and spatial structure, addressing the disconnect observed in text-based approaches.
Three-Stage LoRA Adaptation
To effectively isolate and balance the distinct requirements of perceptual quality, structure, and texture in the generated outputs, GramSR employs three LoRA modules, each trained and activated in succession:
- Pixel-Level LoRA: The first module, trained with a standard ℓ2 loss, is focused on minimizing distortion induced by quantization or sensor noise, directly optimizing for metrics such as PSNR and SSIM.
- Semantic-Level LoRA: The second module incorporates LPIPS and classifier score distillation (CSD) losses, optimizing for perceptual quality and semantic plausibility, while maintaining the gains of the pixel-level module.
- Texture-Level LoRA: The final module introduces a Gram matrix loss, operating on DINOv3 features, enforcing the consistency of second-order feature statistics and promoting the synthesis of authentic textures.
Each LoRA module is sequentially frozen upon completion of its respective training stage, ensuring non-destructive integration and enabling interpretable, independent control during inference via adjustable scaling weights.
Experimental Results
GramSR's efficacy is benchmarked on synthetic (DIV2K) and real (RealSR, DRealSR) datasets. The method achieves state-of-the-art performance in one-step diffusion-based SR, as evidenced by improvements across fidelity (PSNR, SSIM) and perceptual (LPIPS, DISTS, FID) metrics. On RealSR, GramSR achieves 26.81 dB PSNR, 76.68% SSIM, and a marked reduction in LPIPS (23.05) and FID (100.71) compared to the next-best method, PiSA-SR [sun2025pixel], which achieves 25.48 dB PSNR, 74.15% SSIM, and 26.72 LPIPS.
Qualitative analysis on real-world images reveals GramSR's capacity to faithfully reconstruct high-frequency textural details and complex structures, avoiding the oversmoothing and loss of realism observed in previous systems.

Figure 2: Visual comparison on RealSR; GramSR demonstrates superior texture recovery and structure preservation compared to SinSR, OSEDiff, and PiSA-SR.
Ablation Studies
Comprehensive ablations validate the contributions of each architectural innovation:
- Visual Conditioning: Replacing text with DINOv3-based visual conditioning yields consistent improvement in both distortion and perception metrics across all datasets.
- Texture-Level LoRA: The introduction of the Gram matrix-based LoRA enhances texture realism and perceptual quality, as measured by LPIPS and FID.
- Three-Stage Training Protocol: Ablations on training strategies demonstrate that sequential and modular LoRA adaptation outperforms alternative joint or merged schemes, both in absolute distortion measures and in perceptual statistics.
The model demonstrates strong generalization across various visual backbones as conditioning sources, with frozen DINOv3-B providing the most effective trade-off between representation capacity and spatial detail.
Implications and Future Directions
The approach repositions the role of conditioning in diffusion-based SR from high-level, modally mismatched textual supervision to informative, spatially aligned visual priors, resulting in significantly enhanced detail synthesis. This is theoretically significant for generative modeling of inverse problems: it suggests that the semantic/fidelity trade-off can be further disentangled with more direct and expressive conditional signals, underscoring the limitation of language supervision even in vision tasks.
Practically, GramSR's one-step inference and modular guidance decomposition are impactful for real-time image restoration, enabling user-controllable optimization of specific attributes: degradation removal, perceptual detail, and textural realism. Moreover, the method's flexibility with respect to conditioning backbone indicates adaptability to new domains and hybrid supervision regimes.
Areas for future exploration include:
- Adaptive, dynamic weighting of the triple LoRA branches via task- or image-aware policies.
- Investigation of visual feature conditioning in other inverse problems (e.g., deblurring, inpainting).
- Incorporation of domain-specific visual encoders in non-natural image settings (medical, remote sensing).
- Expansion to multi-modal conditioning, combining visual features with sparse human input or low-level cues.
Conclusion
GramSR establishes a new technical direction in diffusion-based SR by substituting text-based conditioning with spatially aligned visual features and by modularizing the SR objective via staged LoRA adaptation, including explicit texture alignment through Gram matrix statistics. The method demonstrably improves the balance between fidelity and perception-oriented metrics, with superior empirical performance in real-world scenarios. This work represents a paradigm shift towards more interpretable and controllable diffusion-based restoration models, and it lays the groundwork for future research on conditioning strategies and modular architecture optimization in generative image recovery.